

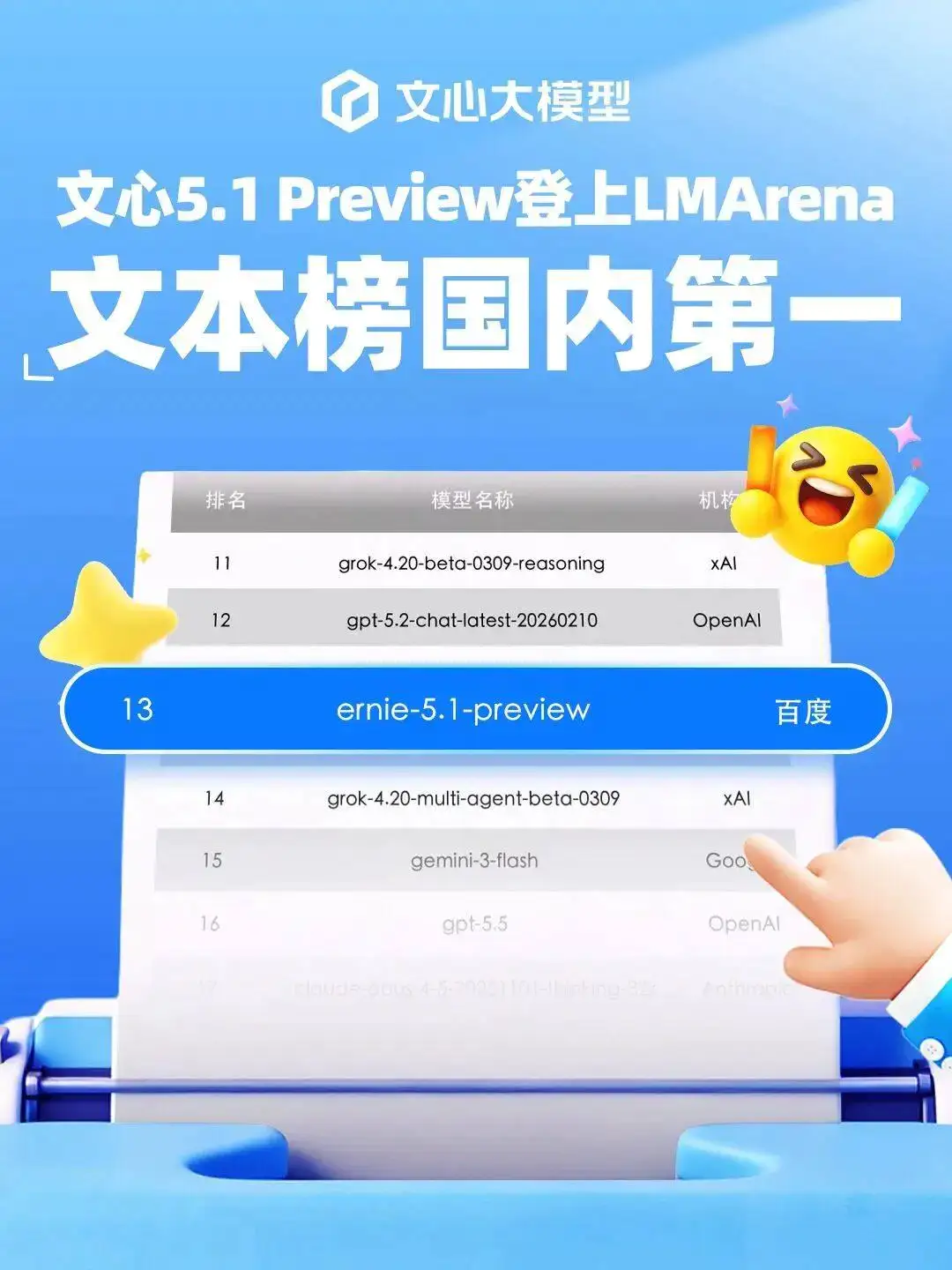
LMArena搜索榜1223分,国内大模型头一回杀进全球前五。但比起榜单上的数字,我更想知道一个更务实的问题:文心5.1在日常用起来,跟DeepSeek、Gemini这些对手到底差多少?花了一个月反复测试,结论比想象中有意思。
产品概述
文心5.1是百度在2026年5月9日发布的旗舰大语言模型,继承自2.4万亿参数的文心5.0。它的核心思路很直接:用知识蒸馏加弹性训练框架,从5.0的超大基座中提炼出一个参数更小、成本更低但能力不减的新模型。
总参数压缩到约8000亿,为5.0的三分之一,激活参数压缩到一半。预训练成本只花了业内同规模模型的6%,不是从零做的新模型,而是在巨人肩膀上做了极致减法。
官网入口在百度千帆大模型平台和文心一言官网。这次发布不单纯的版本迭代,从技术路线到训练方式都是一次重新设计。与DeepSeek、Kimi这些同赛道的对手不同,文心5.1走的是大基座蒸馏路线,而不是从零训练一个全新的MoE架构。这意味着它在继承知识广度的同时,避开了从头训练的巨额成本。
到底强在哪
定位清楚了,那功能层面它有没有撑住这个定位?我逐项测了一轮,发现最突出的集中在四个方向。
首先是深度搜索能力。Arena Search榜单上1223分,全球第四、中国第一,不是靠参数堆出来的。我把几个需要跨领域信息整合的问题丢进去,比如对比2025年下半年全球主要云厂商的AI芯片采购策略变化。它的回答结构清晰,引用来源准确,信息层面的深度明显比前代高了一个档次。
其次是Agent能力。在T3-bench和SpreadsheetBench-Verified两项评测中,文心5.1都超越了DeepSeek-V4-Pro。我实际试了一个多步骤任务:让它从一份模拟销售数据里找出Q3业绩下滑的原因,然后生成改进方案。结果它自己拆步骤、调工具、出结果,全程不需要我干预。这在以前的国产模型里很少见。

第三是数学推理。AIME26得分99.6,仅次于Gemini 3.1 Pro的99.9。虽然差了0.3分,但已经甩开DeepSeek-V4-Pro九十几分一个身位。我丢了一道需要多步推导的代数题,它的中间推理步骤非常完整,偶尔还会主动指出备选解法。
最后是创意写作。内部评测接近Gemini 3.1 Pro,Text Arena排名国内第一。我写了几段不同风格的文案,从科技产品宣传到古风小说开头,它的语言节奏和情感把控确实比以前好了不少,不再是那种AI味过重的输出。
上手流程
功能听起来挺能打,那注册到用上顺不顺畅?我直接走了一遍从零到一的流程。登录千帆平台,选择文心5.1模型,不用额外申请权限就能直接用。整个配置过程不到五分钟,比我想象的简单,不需要填复杂的申请表单,也不用等人审核。在文心一言官网上更直接,打开对话框就能用上5.1版本。
第一个测试问题我选了一个复杂场景:帮我写一份关于智能家居行业2026年市场趋势的分析报告大纲,涵盖技术路线、竞争格局、政策导向三个维度。等了大概七八秒,返回了一个结构非常完整的大纲,二级标题下面还附了关键数据点。
在日常知识问答和文档起草场景里,它的响应速度和质量都属于T1梯队。专业版订阅用户还能走优先队列,高峰期不怎么排队。
进阶玩法
正常用是一回事,用得溜是另一回事。下面几个技巧能帮你把文心5.1的隐藏实力挖出来。
-
多轮Agent任务拆解:很多人只做单轮对话,其实它最擅长的是把复杂任务自动分解。比如丢给它一句”对比Q1和Q2的销售数据,找出异常月份,分析原因并给出改善方案”,它会自己规划步骤、调用分析工具,最后汇总输出,省掉你一次次提示的功夫。 -
深度搜索模式精调Prompt:做研究类任务时,在问题末尾加上”请从多个维度分析并标注信息来源”,它会自动启用深度检索模式,回答中附带引用来源。写报告、做文献综述的时候,这个技巧能省掉一半查资料的时间。 -
创作中的风格锚定:写长篇文章之前,先给一段你想要的风格样本,再正式提需求。比如先贴一段你喜欢作家的段落,然后说”按这个风格写一篇关于AI伦理的评论文章”。它的模仿能力强得超出预期,而且能在整篇文章中保持风格一致。
竞品对比
自己夸不算数,拉到赛道上和对手过两招才知道真本事。当前大模型赛道最绕不开的是DeepSeek-V4-Pro和Gemini 3.1 Pro,看看文心5.1跟它们比到底差在哪。
| 对比维度 | 文心5.1 | DeepSeek-V4-Pro | Gemini 3.1 Pro |
|---|---|---|---|
| 预训练成本 | 业界6% | 未公开 | 未公开 |
| Arena搜索榜 | 全球#4/国内#1 | 未进入前列 | 未明确 |
| AIME26(数学) | 99.6 | 92.6 | 99.9 |
| GPQA(知识) | 91.0 | 90.1 | 94.1 |
| Agent(T3-bench) | 67.9 | 67.5 | 67.1 |
| Text Arena排名 | 全球#13 | 未进入前20 | 全球#5 |
| 开源策略 | 闭源API | 开源+闭源 | 闭源 |
数据不会骗人。文心5.1在搜索和Agent上的表现确实领先,但在知识类任务上跟Gemini还有差距。更值得注意的是,它在数学推理上已经把DeepSeek甩开了,AIME26七分的差距可不是小数字。但闭源策略始终是个短板,开发者没法本地部署和深度定制。
真实用户怎么说
评测室里说了不算,到各大平台逛了一圈,真实用户的声音还挺两极化。正面评价集中在搜索和Agent能力上,不少企业开发者提到多轮Agent任务的稳定性比DeepSeek好,搜索结果的引用质量在国内模型里算最好的。有内容创作者直言创意写作比Kimi K2.6更有文采,长篇叙事不吃力。
吐槽点也很集中。一是闭源模式劝退了很多开发者,模型再好不能本地部署就等于没有。二是有用户在高峰期遇到响应延迟,虽然不如GPT-5.5严重但体验上确实扣分。还有用户反映某些专业领域的知识回复偏泛,不如Gemini准确。
多维评分
用户反馈有赞有踩,那从专业角度拆开来看每项到底值几分。
| 维度 | 评分 | 一句话解读 |
|---|---|---|
| 功能完整性 | ⭐⭐⭐⭐☆ | 搜索/Agent/写作为核心三叉戟 |
| 易用性 | ⭐⭐⭐⭐⭐ | 千帆平台一键切换,零门槛上手 |
| 性价比 | ⭐⭐⭐⭐⭐ | 6%训练成本,旗舰级能力输出 |
| 创新性 | ⭐⭐⭐⭐☆ | 弹性蒸馏+异步RL架构有突破 |
| 稳定性 | ⭐⭐⭐⭐☆ | 高峰期偶有延迟,整体可靠 |
| 推荐度 | ⭐⭐⭐⭐☆ | 企业开发者首选,本地部署需观望 |
综合评分:8.2 / 10
优点和槽点
优势
-
搜索能力国内登顶:Arena搜索榜全球第四,信息检索和多源整合能力在国内没有对手 -
极致降本不降质:预训练成本仅业界6%,参数压缩到1/3但能力不输旗舰 -
Agent能力领先:T3-bench超越DeepSeek-V4-Pro,复杂任务拆解执行流畅 -
数学推理接近顶配:AIME26得分99.6,仅次于Gemini 3.1 Pro
不足
-
闭源不可部署:API模式让开发者和企业无法本地部署和深度定制 -
通用知识略逊Gemini:GPQA 91.0 vs 94.1,生物医药等领域深度不够 -
技术细节未公开:弹性训练框架、异步RL架构细节未对社区开放验证 -
定价信息不透明:到目前API调用价格仍未明确公布
适合谁用
综合前面的体验,来对号入座看看你到底需不需要它。
-
企业AI应用开发者:需要稳定Agent能力的团队,文心5.1的多轮工具调用和任务拆解是目前国产方案里最强的选择之一 -
深度搜索/RAG场景用户:搜索能力国内第一,做知识库问答、文档分析、研究报告的场景天然适配 -
内容创作者:创意写作接近T1水平,长篇叙事和风格模仿在国内模型里算前列 -
学术研究人员:数学推理和复杂逻辑分析能力突出,适合做研究辅助和数据处理 -
不太适合的人:需要本地部署或开源定制的团队,建议等DeepSeek V4.1或Qwen3-Next的开源方案
定价方案
功能、体验、口碑都说完了,到了直面价格的时刻。目前文心5.1的具体API定价暂未正式公布,这确实是个让人头疼的事。
| 使用方式 | 费用 | 核心权益 | 备注 |
|---|---|---|---|
| 文心一言官网 | 基础版免费 | 对话/搜索/创作 | 额度有限 |
| 文心一言专业版 | 约¥59/月 | 优先队列/更高额度 | 需单独订阅 |
| 千帆API(企业) | 待公布 | 弹性调用/技术支持 | 价格未公开 |
| 企业私有化部署 | 定制报价 | 全功能/专属资源 | 闭源限制 |
性价比这块,如果只看单次API调用,文心5.1凭借压缩后的参数量和训练成本优势,推理定价应该会比GPT-5.5和Gemini有竞争力。但具体到每一分钱能换多少tokens,还得等官方贴出价签的那天。
常见问题
综合之前的反馈,挑几个大家最关心的问题来回答。
Q1:文心5.1和文心一言是什么关系?
A1:文心5.1是底层大模型,文心一言是上层应用。 文心一言官网已升级到5.1版本,你打开文心一言就能直接体验5.1的能力,不需要额外操作。
Q2:文心5.1能免费使用吗?
A2:可以,但免费版有额度限制。 通过文心一言官网可以免费体验基础对话和搜索功能,日常查询够用。如果需要更高调用频率和专业功能,需要订阅专业版。
Q3:文心5.1支持API调用吗?
A3:支持,通过百度千帆平台即可使用。 开发者在千帆模型广场选择ernie-5.1模型,修改model_name就能调用。具体定价尚未公布,但提供弹性调用方式。
Q4:文心5.1和DeepSeek-V4-Pro比怎么样?
A4:各有优势,文心5.1在搜索和Agent上更强。 T3-bench和SpreadsheetBench评测中文心5.1领先,AIME26数学更是甩开7分。但DeepSeek的优势在于开源可部署,这是文心5.1做不到的。
Q5:文心5.1是开源的吗?
A5:不是,文心5.1采用闭源策略。 API模式下可以通过千帆平台使用,但不开放模型权重,无法本地部署或二次开发。如果对开源有刚需,可以关注DeepSeek或Qwen的动向。
Q6:文心5.1的创作能力真的接近Gemini吗?
A6:在创意写作维度确实接近,但仍有差距。 Text Arena排名国内第一,长篇叙事和风格模仿有明显进步。但对比Gemini 3.1 Pro,在知识深度和复杂指令遵循上还有提升空间。
Q7:文心5.1适合写长文章吗?
A7:适合,长篇叙事能力在国产模型里算前列。 通过风格锚定技巧先给一段风格样本再提需求,它能在整篇文章中保持风格一致,写小说、评论、报告都很好用。
Q8:文心5.1搜索能力为什么这么强?
A8:得益于深度搜索和知识推理的协同优化。 它不只是做关键词匹配,而是理解问题背后的信息结构,主动跨源整合并在回答中标注引用。Arena Search榜全球第四的成绩也验证了这点。
Q9:文心5.1的API价格什么时候公布?
A9:截至目前百度尚未正式公布具体定价。 预计在Baidu Create 2026开发者大会上会有完整的定价方案发布。企业用户可以联系百度销售获取定制报价。
Q10:文心5.1和Kimi K2.6哪个好?
A10:定位不同,各有侧重。 文心5.1的优势在搜索和Agent上更强,适合深度研究和自动化任务。Kimi K2.6的长文本处理更成熟,适合超长文档处理场景。看你具体需求选。
最后总结
文心5.1是一张很有想法的牌。百度没有跟所有厂商一样拼参数量,而是反其道行之,从2.4万亿参数的5.0里认认真真做减法,把成本压到别人的6%,把Search和Agent这两项拉到全球前排。
这个思路本身就很有料。对于企业开发者、搜索场景用户和有深度推理需求的人来说,它是目前国产模型里最值得认真考虑的选项之一。但如果对开源有执念或者需要本地部署,它目前不是你的菜。建议先上文心一言免费版试几轮,不吃亏。