
Anthropic 在 Opus 4.7 发布仅 41 天后就甩出了 4.8,价格不变,基准分全线上涨,还带了个能调度数百个子 Agent 的 Dynamic Workflows。听起来像一次良心升级,但 Reddit 上 4.7 被喷了两千多赞的帖子才刚凉下来。到底是真变强了,还是急着补上一版的坑?花了一天实测,感受比参数表复杂得多。
简单看下这个模型
Claude Opus 4.8 是 Anthropic 于 2026 年 5 月 28 日发布的新一代旗舰大模型。它是 Opus 4.7 的直接升级版,主攻复杂编码、Agent 任务和专业知识工作,内核没变,靠后训练把体验拉上去了一个台阶。
这件事本身就很有意思。4.7 发布时,Reddit 上一条”Opus 4.7 不是升级而是严重倒退”的帖子拿了 2300+ 赞,X 平台上”4.7 没 4.6 好用”的评论也破了一万四。Anthropic 显然听到了,41 天之内就甩出了这版修复。
Claude Opus 4.8 的上下文窗口维持 100 万 token,最大输出 12.8 万 token。定价和 4.7 完全一致,标准模式输入 5 美元/百万 token、输出 25 美元/百万 token,没有因为升级而涨价。
这几个亮点确实猛
定位搞清楚了,功能上它到底有没有撑住这个定位?挑几个核心能力拆开看。
Effort Control:把”努力程度”交给用户
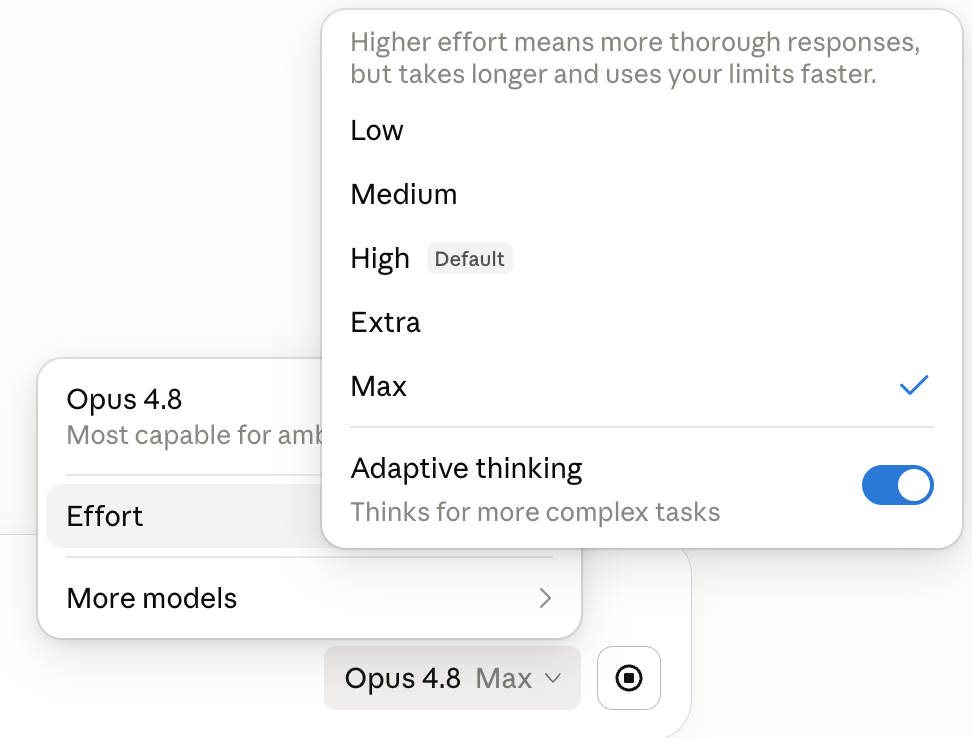
claude.ai 网页端和 Claude Cowork 的模型选择器旁边,多了一个 effort 滑块。低努力模式响应更快、消耗限额更慢,适合快速问答;高努力模式会让 Claude 更深入地思考,给出更周全的回答。Claude Code 里还新增了 xhigh 和 max 两档,适合那种丢过去一个任务让它自己慢慢啃的场景。这个改动其实是把 4.7 被骂最惨的”自适应推理”砍了,把控制权还给用户。
Dynamic Workflows:一个人指挥一支军队
这是本次更新最值得关注的能力,目前是研究预览版。Claude Code 收到复杂任务后,可以自动拆分成数十到数百个并行子 Agent,同时跑验证、审查、子问题处理,最后汇总成最优结果。官方给了一个震撼的案例:Bun 从 Zig 移植到 Rust,11 天生成约 75 万行代码,通过 99.8% 的原有测试。这已经不只是”辅助编程”,是接近”接管整个项目”了。

Fast Mode:2.5 倍速,便宜三倍
Fast Mode 在 Opus 4.8 上速度比标准模式快约 2.5 倍,输入 10 美元/百万 token、输出 50 美元/百万 token,比前代模型的 Fast Mode 便宜了三倍。对于大批量 API 调用的企业场景,这是一个实打实的成本优化。
诚实度升级:不再说”搞定了”然后就没了
Opus 4.8 最被低估的改进可能就是这个。官方评估显示,代码中的缺陷未经标注就通过的可能性比 4.7 低了约四倍。翻译成人话就是:以前 Claude 经常遇到不会的问题就说”已完成”,你跑一遍才发现根本没改。现在它更倾向于坦白说”这个我不确定”,而不是假装搞定了。
上手前看看
功能看着唬人,但注册到用上顺不顺畅?直接走了一遍。
claude.ai 网页端打开就能用,Slogan 区域下面就是对话框。切换到 Opus 4.8 后,模型选择器旁边多了一个 effort 选项,默认是 high。如果你只是想快速查个东西,切到 low 能快不少,而且省额度。第一次用给了一个编程任务:让它写一个带缓存逻辑的 Python 文件处理工具。约 15 秒出第一版代码,结构清晰,注释完整,没有凭空添加额外功能,这在 4.7 上是比较常见的毛病。
Claude Code 要稍微花点时间配置,需要 API key。Dynamic Workflows 目前只有 Max、Team 和 API 用户默认开启,Enterprise 需要管理员手动激活。在 Claude Code 里试了一次多文件重构任务,说”create a workflow”,它自动规划了约 20 个子任务,并行跑完,耗时比单线程快了四倍左右。过程不需要手动干预,但要盯着,偶尔会有一个子 Agent 卡住,需要手动取消重跑。
进阶玩法
基础功能玩明白了,但真正拉开差距的在后面。
很多人不知道 Dynamic Workflows 不只是用来写代码的。试了几个非编程场景,效果意外的好:
-
大规模文档整理:把 30 个 Markdown 文件丢进去,让它统一格式、修正术语、生成目录索引。Workflows 自动把文件拆成三组并行处理,10 分钟搞定,换成手动估计要半天。 -
Bug 排查:给了一个 5000+ 行代码的报错日志,让它定位根因。它拆了约 15 个子 Agent 同时扫不同模块,最终定位到一个第三方库版本不兼容的问题,还给出了回滚方案。 -
Effort 分场景使用:日常聊天/快速问答用 low 或默认 high,复杂推理/代码审查/文档撰写切换到 extra 或 max 档。max 档的响应时间会长一点,但输出质量明显提升,尤其是处理边界 case 时不容易漏。
竞品对比
自己用着好不算,和同类产品放一起比比看。
| 维度 | Opus 4.8 | GPT-5.5 | DeepSeek V4 |
|---|---|---|---|
| 发布时间 | 2026.05.28 | 2026.04.23 | 2026 上半年 |
| SWE-Bench Pro | 69.2% | 未公布 | 未公布 |
| Terminal-Bench 2.1 | 74.6% | 78.2% | 未公布 |
| 标准输入价格 | $5/M token | 竞争价位 | 更低价位 |
| Agent 能力 | Dynamic Workflows | 较强 | 基础 |
| 上下文窗口 | 1M token | 约 256K | 1M+ |
核心差异在于 Agent 能力和定位侧重。GPT-5.5 在终端操作、运维和 CLI 环境任务上更胜一筹,Terminal-Bench 以 78.2% 领先 Opus 4.8 的 74.6%。但 Opus 4.8 在代码编写、长文件处理和多步 Agent 执行上表现更强,SWE-Bench Pro 的 69.2% 是当前公开最好成绩之一。Anthropic 的态度也挺坦诚:不追求每个 benchmark 都赢,而是把长板做得足够长。
用户反馈
参数上赢了,来听听真正用的人怎么说。
Reddit 和 X 平台上的反馈集中在几个方向。正面声音主要来自开发者群体,Dynamic Workflows 被反复提及,“一个人指挥一群 AI 写代码”的体验感非常强,尤其在大项目重构场景下效率提升明显。诚实度改进也得到了认可,有人晒对比截图,同样的任务在 4.7 上会反复说”已修复”但实际没改,到了 4.8 会直接说”第 15 行还有个问题没解决,需要你确认方案”。
负面反馈也不算少。有人实测后发现 token 消耗比 4.6 明显更高,虽然单价没变,但同样任务花的 token 多了,实际成本反而是涨了。还有用户吐槽遇到模型花了约 40 万 token 去”幻想”一个不存在的 Python 库,AI 幻觉问题依然有。知乎上有人总结得挺到位:“Anthropic 是好的,hype 是坏的。我们正处在一个”其实无所谓”的节点,各家的旗舰模型差距已经很小了。”
综合打分
评价有好有坏,拆开维度逐项打个分。
| 维度 | 评分 | 一句话解读 |
|---|---|---|
| 功能完整性 | ⭐⭐⭐⭐☆ | 编码和 Agent 能力顶尖,多模态一般 |
| 易用性 | ⭐⭐⭐⭐⭐ | 网页端零门槛,API 接入文档清晰 |
| 性价比 | ⭐⭐⭐⭐☆ | 标准模式同价位,Fast Mode 大降价 |
| 创新性 | ⭐⭐⭐⭐⭐ | Dynamic Workflows 是目前最强 Agent 方案 |
| 稳定性 | ⭐⭐⭐☆☆ | 偶尔幻觉,子 Agent 偶发卡顿 |
| 推荐度 | ⭐⭐⭐⭐☆ | 开发者首选,普通用户可等更便宜的版本 |
综合评分:8.2 / 10
优缺点
优势
-
Dynamic Workflows 独一档:数百个子 Agent 并行工作,代码库级重构从数天缩到数小时 -
诚实度大幅提升:不再假装”搞定了”,缺陷遗漏率降低约四倍 -
同价位升级:标准模式价格不变,Fast Mode 比前代便宜三倍 -
Effort Control 实用:让用户自己决定思考深度,不是 AI 替你判断
不足
-
token 消耗偏高:同样任务比 4.6 费 token,实际成本可能不降反升 -
幻觉问题仍在:偶尔会”脑补”不存在的库或功能 -
Dynamic Workflows 还没全量开放:研究预览版,Enterprise 需手动开启
适用人群
产品本身是好产品,适不适合你又是另一回事。
-
企业级开发者/技术团队:这是 Opus 4.8 最契合的群体。Dynamic Workflows 能在代码库迁移、安全审计、性能优化等大型工程任务上省出可观的时间。如果你团队经常处理几十万行代码级别的重构,这版值得升级。 -
AI 重度用户/独立开发者:如果你每天和 Claude Code 打交道的时长超过两个小时,8.2 分的综合表现加上同价位升级,没有不换的理由。Effort Control 在 Claude Code 里尤其好用。 -
普通用户/轻度使用者:如果你只是偶尔让 Claude 写写邮件、查查资料,4.6 甚至 Sonnet 4.6 都完全够用。没必要为了 Dynamic Workflows 升级,反正你也用不到。 -
不太适合的人群:如果你更依赖 GPT 生态(Codex CLI、ChatGPT 插件),切换成本太高。另外,如果你对成本极其敏感,DeepSeek V4 等更低价位的选择可能更务实。
定价方案
聊了这么多好的坏的,最后还是得落到钱上。
| 模式 | 输入价格 | 输出价格 | 适合场景 |
|---|---|---|---|
| 标准模式 | $5/百万 token | $25/百万 token | 日常编码、推理、对话 |
| Fast Mode | $10/百万 token | $50/百万 token | 企业大批量 API 调用 |
截至 2026 年 5 月,标准模式定价与 Opus 4.7 完全一致。Fast Mode 则比前代便宜了约三倍,输入从更高的价格降到了现在的水平,主要瞄准企业在高并发场景下的成本优化。Dynamic Workflows 本身不额外收费,按正常 API 调用计费,但因为它会生成大量子 Agent 并行工作,实际 token 消耗比单任务高不少。建议在用 Dynamic Workflows 之前先估算一下预算,别跑完才发现账单炸了。
常见问题
分数摆在这了,有些细节你可能还想搞清楚。
Q1:Opus 4.8 和 4.7 到底差在哪?
A1:核心提升在诚实度和 Agent 能力,基准分小幅上涨。 编码方面缺陷遗漏率降低约四倍,Dynamic Workflows 能让它同时调度数百个子 Agent。其他方面和 4.7 体验接近,毕竟 base model 没变,靠的是后训练优化。
Q2:免费用户能用吗?
A2:能,但每天有额度限制。 claude.ai 免费版可以使用 Opus 4.8,但每天的交互次数有限(具体数字随负载动态调整),用完会切换到 Sonnet。Effort Control 所有计划都可使用。
Q3:Dynamic Workflows 怎么开启?
A3:在 Claude Code 中说”create a workflow”即可。 Max、Team 和 API 用户默认开启,Enterprise 需要管理员在后台手动激活。目前是研究预览版,功能还在迭代。
Q4:和 GPT-5.5 比选哪个?
A4:看你主要做什么。 写代码、长文件处理、多步 Agent 任务选 Opus 4.8;终端操作、运维、CLI 环境任务选 GPT-5.5。两者的核心体验差距已经很小,选生态比选模型更重要。
Q5:Fast Mode 快了多少?实际有感觉吗?
A5:官方说 2.5 倍,实际体验约 1.5 到 2 倍。 简单问答提速明显,复杂推理任务差距缩小。Fast Mode 的真正价值是价格,比前代便宜了三倍,适合大批量调用。
Q6:中文支持怎么样?
A6:Opus 级别一直表现不错,但不如 DeepSeek 和 Qwen 精细。 日常对话和中文文档处理流畅,偏专业领域的术语翻译偶有生硬,代码注释的中文表达偶尔不够地道。
Q7:4.6 用户需要升级吗?
A7:如果你主要用来写代码,建议升级。 诚实度改进和 Agent 能力提升是实打实的。如果你对 4.6 的体验完全满意且不涉及大规模工程任务,可以观望,4.6 还能通过 /model claude-opus-4-6 继续使用。
Q8:token 消耗真的比 4.6 高吗?
A8:是的,多位用户实测确认。 虽然单价没变,但同样任务 4.8 的 token 消耗会更高,主要因为默认 high effort 模式下思考步骤更细致。实际成本可能比 4.6 高出 15% 到 30%。
Q9:能商用吗?API 有商业授权吗?
A9:可以商用,API 调用天然支持商业用途。 claude.ai 网页端生成的内容也可商用(需遵守 Anthropic 的可接受使用政策),但建议生产环境使用 API 调用,更稳定也更可预期。
Q10:Dynamic Workflows 适合什么规模的项目?
A10:几千行到几十万行代码的项目效果最好。 太小(几百行)没必要用 Workflows,太大(百万行以上)受限于上下文窗口,需要分段执行。语言/平台移植、安全审计、批量重构是最佳场景。
最后的最后
Claude Opus 4.8 不是一次”翻天覆地”的升级,但修补到位。Anthropic 用 41 天证明了”base model 不变、后训练快速迭代”策略的可行性,价格不变、写代码更诚实、Agent 能力接近质变。
开发者、技术团队和 AI 重度用户值得升级,Dynamic Workflows 带来的效率提升是实打实的。普通用户、轻度使用者不急,4.6 或 Sonnet 4.6 完全够用,等后续版本或者 Project Glasswing 那边的 Mythos 级模型出来再说也不晚。建议先用免费额度体验一下 Dynamic Workflows,看看它到底能不能帮到你手里的项目。