
一个开源模型,自己读论文、写代码、跑实验,全程搞了 12 个小时,把一篇 ICLR 顶会论文成功复现了。这就是刚发布的 MiniMax M3,三项前沿能力集于一身,评测分数直接干翻了 Claude Opus 4.7。但开发者社区的反应却炸了锅,不是因为能力不行,而是定价策略在发布当天翻了车。
这是什么模型
MiniMax M3 是稀宇科技在 2026 年 6 月 1 日发布的新一代旗舰大模型。它的核心定位很直接,国内首个同时具备前沿编码能力、百万 token 超长上下文和原生多模态的模型。跟市场上大多数大模型不同,M3 不是在某一个维度上跟风,而是在编程、Agent 自主执行和多模态三条赛道上同时发力。
MiniMax 算不上大模型赛道的新玩家,此前 M1、M2 系列已经在开发者群体里积累了一定口碑。但 M3 这一代明显是奔着国际一线去的,发布当天官方就拿 SWE-Bench Pro、BrowseComp 等多项基准测试的成绩单,直接对标 Claude Opus 4.7 和 GPT-5.5。
官网:https://www.minimaxi.com | 模型页面:https://www.minimaxi.com/models/text/m3

到底强在哪
评测数据刷了一屏,但冷静下来看,M3 真正能打的牌主要集中在三张。
MSA 稀疏注意力,把长上下文成本打了下来。 大模型处理长文本有个老问题:上下文每翻 10 倍,计算量暴增 100 倍。M3 自研的 MSA 架构用了”索引加稀疏计算”的双分支方案,先让轻量索引快速筛出跟当前 token 相关的内容块,再对这些块做精确计算。
官方给的数据是,在 100 万 token 规模下,单 token 计算量仅为上一代的二十分之一,预填充阶段快了 9.7 倍,解码生成快了 15.6 倍。翻译成人话:以前跑一次百万级上下文分析得等半天,现在几分钟内就能出结果。
编程能力,不只是在刷榜。 SWE-Bench Pro 拿到了接近 Claude Opus 4.7 的水平,直接超越了 GPT-5.5 和 Gemini 3.1 Pro。但更让人印象深刻的不是分数,发布会的现场演示里,M3 花 12 小时独立复现了一篇 ICLR 2025 杰出论文的全部核心实验,全程自主完成 18 次 commit,产出 23 张实验图表。
另一个测试更狠:给它一个 FP8 GEMM 算子优化的任务,M3 连续跑了 24 小时,提交了 147 次 benchmark,硬件峰值利用率从 7.6% 干到了 71.3%,接近 10 倍加速。光凭这两项,说它是”不用发工资的科研助手”不算过分。
Agent 自主执行,从对话走向行动。 BrowseComp 自主信息检索评测中,M3 拿到 83.5 分,干掉了 Claude Opus 4.7 的 79.3。在 PostTrainBench,一个让模型自己当教练、给别的模型做训练的场景,M3 得分 37.1,虽然排在 Opus 4.7(42.4)和 GPT-5.5(39.3)后面,但作为国产模型能挤进全球前三,这个成绩单已经够硬了。
| 评测项目 | MiniMax M3 | Claude Opus 4.7 | GPT-5.5 | Gemini 2.5/3.1 Pro |
|---|---|---|---|---|
| BrowseComp 信息检索 | 83.5 | 79.3 | 84.1 | 76.5 |
| SWE-Bench Pro 编程 | 接近 Opus | 领先 | 被超越 | 被超越 |
| PostTrainBench 教练 | 37.1 | 42.4 | 39.3 | 未公开 |
| 上下文窗口 | 1M tokens | 200K tokens | 128K tokens | 1M tokens |
编程能力强的模型不缺,Agent 强的也有,多模态强的也不少。但三样同时拿得出手的,M3 是国产里第一个。
上手流程
功能参数看着唬人,实际用起来门槛怎么样?
目前 M3 的入口:API 直连、OpenCode 在线体验、Token Plan 订阅套餐,也可以桌面版及在线体验。OpenCode 是官方提供的在线 IDE,注册后直接选模型就能跑,限时免费。注册流程就是邮箱加验证码,一分钟搞定。首页界面就是标准对话窗口,左边能上传图片和代码文件,右边是输出区,整体跟 Cursor 或 GitHub Copilot Chat 的体验很像。
我用 OpenCode 试了一个经典场景:把一段 Python 爬虫代码扔进去,让它找出所有可能的效率瓶颈并优化。M3 先读了代码结构,然后逐段标注了可以异步执行的部分,最后输出了一份带注释的优化版代码。整个过程大概不到两分钟,优化的方案思路很清晰,不是那种粗暴的”把 for 循环改成列表推导式”,而是真的分析了哪些 IO 操作可以并发。
但有个小槽点:它改完之后默认不会在原文件上直接保存,得自己手动覆盖,对于习惯自动保存的人来说稍显割裂。
如果你走 API 接入,目前只开放了文本和多模态接口,语音和视频生成用的还是 MiniMax 家族的其他模型。API 的文档质量中规中矩,有完整的 curl 示例,但进阶用法比如流式输出和缓存策略的说明不够详细,新手可能得多踩几个坑。M3-highspeed 版本在 API 里已经上线,速度体感比标准版快约三分之一,推理结果完全一致。
进阶玩法
基础操作不复杂,但 M3 有几个真正值回票价的用法,很多人可能没注意到。
长文档全量分析,改代码不用挑挑拣拣。 M3 的 1M 上下文不是摆设。把一整个代码仓库的文件打包丢进去,告诉它”找出所有 SQL 注入风险并修复”,它能一次性扫完所有文件,不需要你手动拆成小块逐个提问。有开发者实测,把 15 万行的微服务项目扔给 M3,一次提问里就定位了 6 个真实的安全漏洞并给出了修复建议。对比用 128K 上下文的模型,同样的任务得拆成至少 5 轮对话,效率差距不是一点半点。
让 Agent 帮你跑马拉松式任务。 官方演示里的论文复现和算子优化属于极限展示,但日常开发里也能用,比如重构一个模块时,不需要一句一句指导,告诉它”把这个模块从 MySQL 迁移到 PostgreSQL,保持接口不变”,它能自主完成建表语句改写、ORM 代码适配、测试用例更新一整套流程。关键是要加一句提示”每个步骤结束后自我检查并记录日志”,触发它的自检逻辑后,成功率明显会高一个档次。
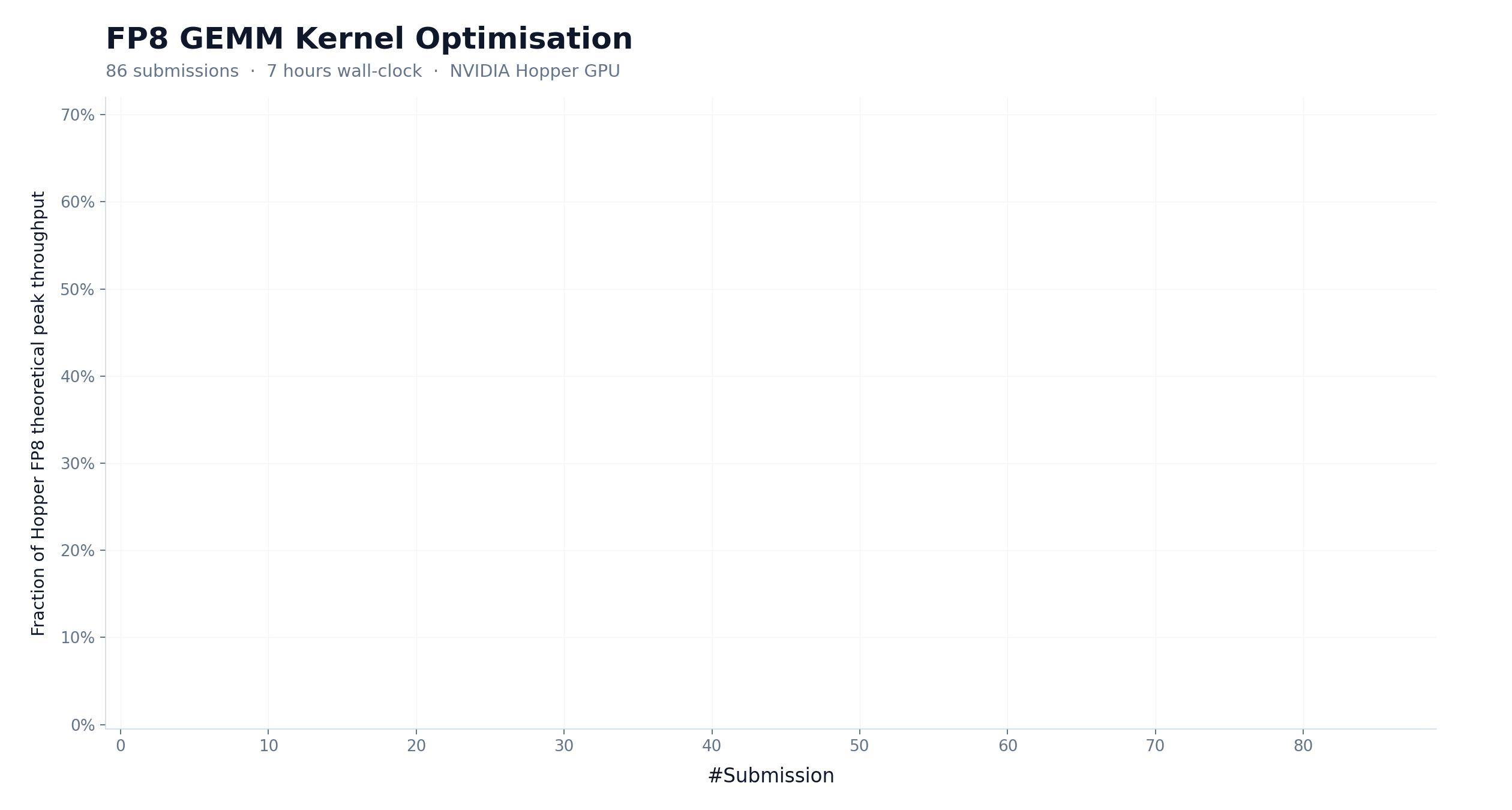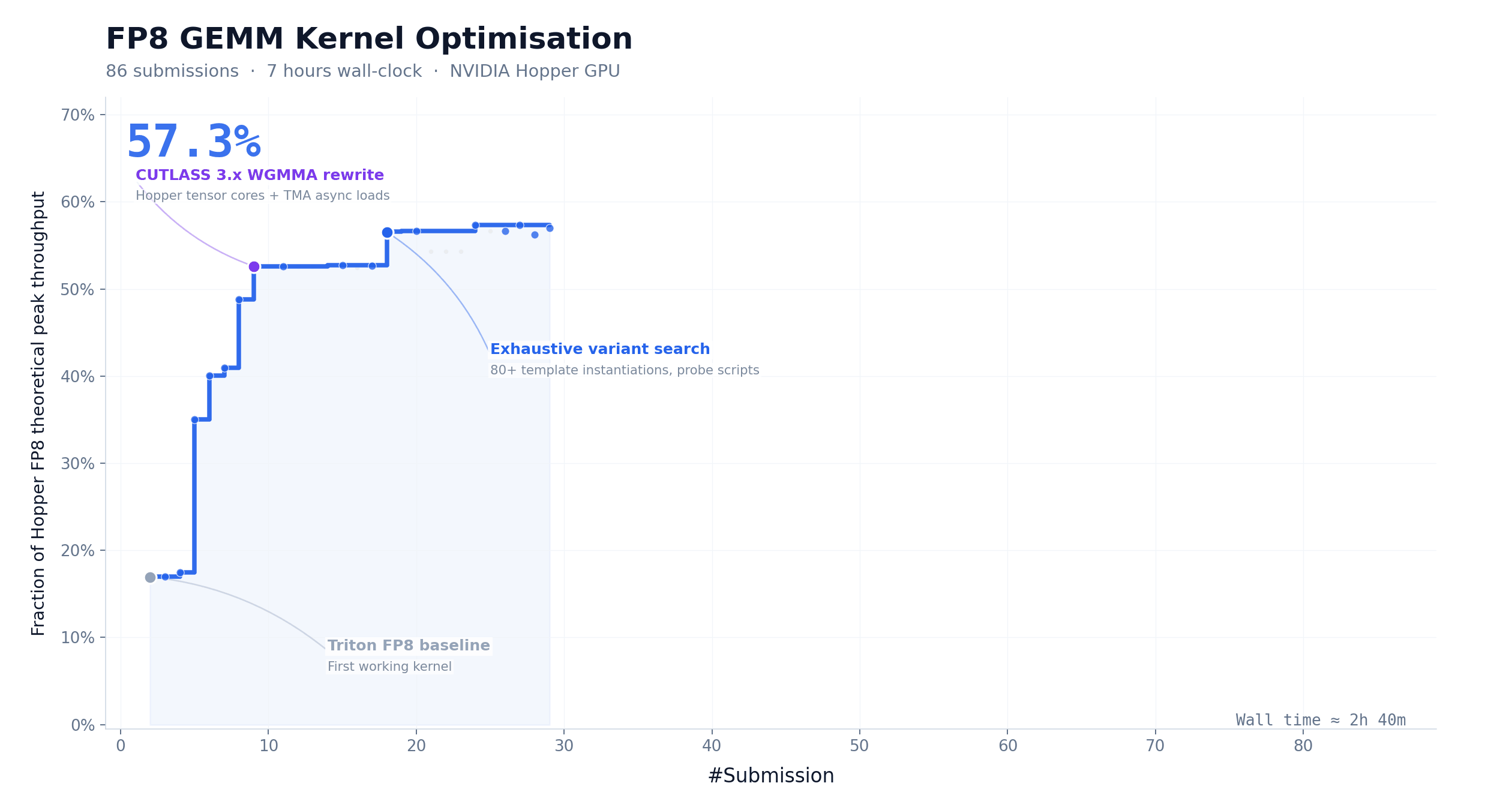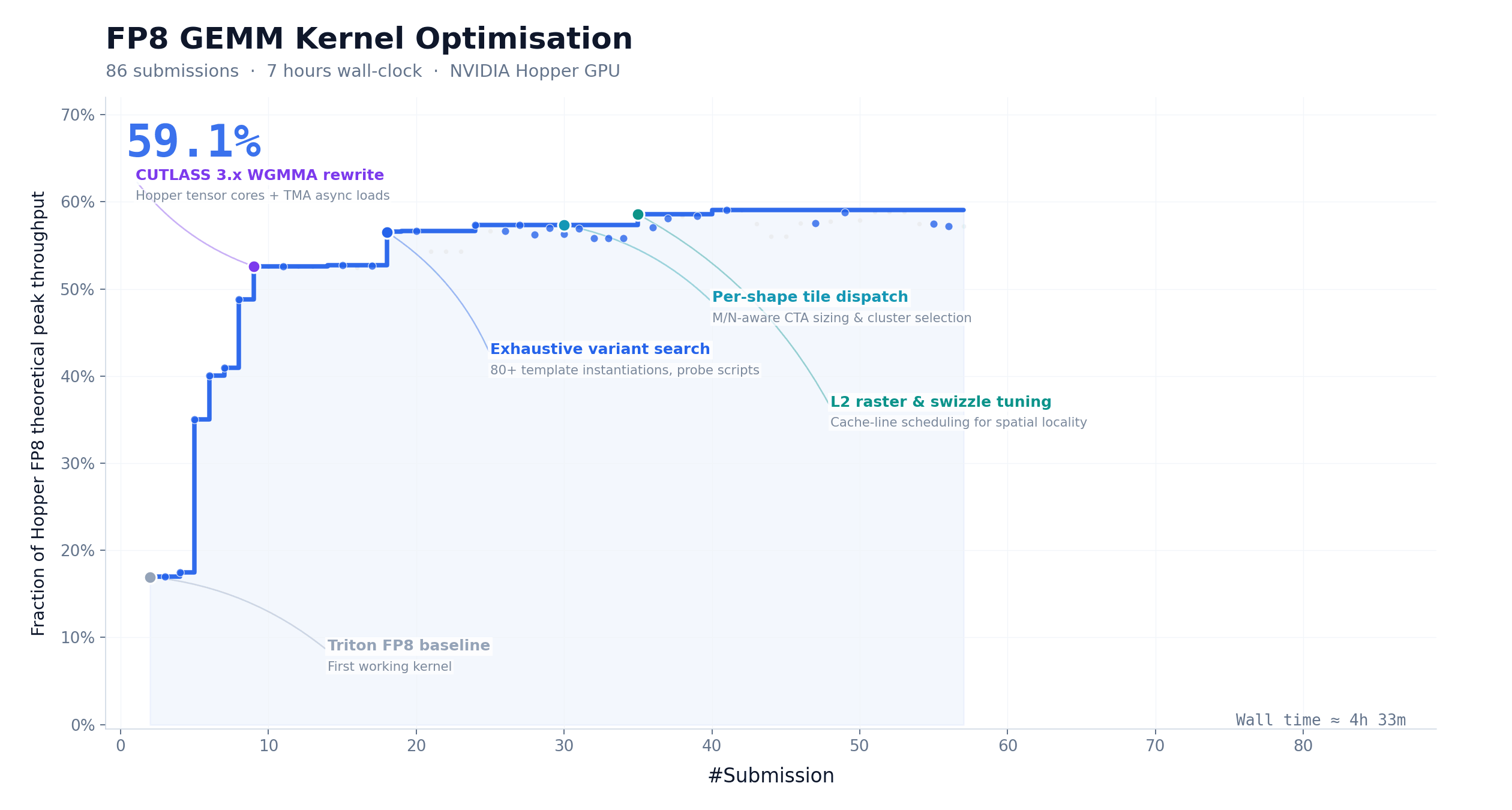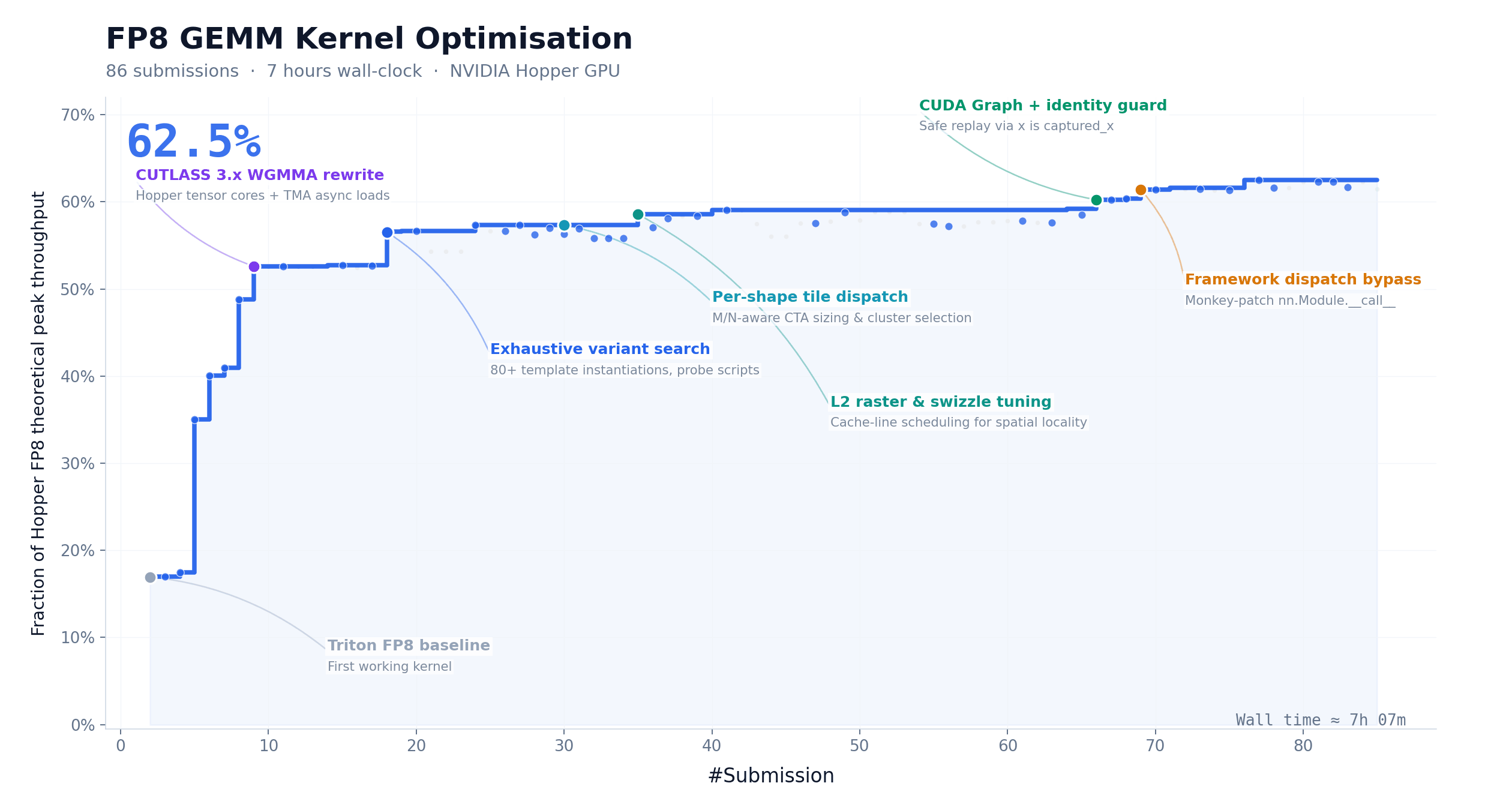
把 M3 当教练,帮新手模型快速上手。 PostTrainBench 的测试场景其实揭示了一个很有想象空间的用法:你可以让 M3 帮你为一个垂直领域的小模型生成训练数据、设计微调方案、迭代优化。虽然这套操作流程目前还没有封装成开箱即用的工具,但技术方向上已经跑通了。如果你的团队在折腾自己的领域模型,这一招能省掉大量人工标注和调参的时间。
竞品对比
评测分数跟 Claude Opus 4.7 五五开,那放现实场景里怎么选?
编程赛道现在是整个 AI 行业竞争最白热化的一块。OpenAI、Anthropic、Google 都有各自的编程专精模型,DeepSeek 因为性价比优势在国内开发群体里也有一席之地。M3 想在这个战场里抢蛋糕,靠的是三合一打法:开源 + 长上下文 + Agent 自主执行。
| 对比维度 | MiniMax M3 | Claude Opus 4.7 | GPT-5.5 | DeepSeek |
|---|---|---|---|---|
| 编程能力 | SWE-Bench Pro 接近 Opus | 顶尖,代码之王 | 仅次于前两者 | 强但差距明显 |
| 上下文窗口 | 1M tokens | 200K tokens | 128K tokens | 1M tokens |
| Agent 自主执行 | BrowseComp 83.5 | 79.3 | 84.1 | 基础可用 |
| 多模态 | 原生图文+视频 | 原生图文 | 原生图文 | 图文后加 |
| 开源 | 是(即将开源) | 否 | 否 | 是(部分模型) |
| API 输入价格 | 2.1 元/百万 tokens | 约 20 元/百万 tokens | 约 15 元/百万 tokens | 约 1 元/百万 tokens |
Claude Opus 4.7 在纯代码质量上仍然是最让人放心的选择,GPT-5.5 在 Agent 能力上略占上风,DeepSeek 的价格是碾压级别的。但如果你需要一个既能写得一手好代码、又有百万上下文、还能自己执行长线任务的开源模型,M3 是目前唯一的选择。它不是在跟对手比谁的单科成绩更高,而是在打一套组合拳。
用户反馈
数据漂亮归漂亮,发布第一天社区的风向就变了几次。
技术群里最先炸开的不是 M3 跑分有多高,而是有人发现 Token Plan 的计费模式从”按次”变成了”积分制”。原来的 Coding Plan 月费 49 块,限制并发但不限总调用次数,重度开发者一个月能跑三五十亿 token。新版 Plus 套餐同样是 49 块,但把总量锁死在 6 亿 token。按一位 CSDN 播主的实测算账,月消耗 30 亿 token 的老用户,实际成本从 49 元涨到了约 175 元,涨了 257%。
开发者论坛 Linux.do 上的相关帖子下,热评第一条就是”技术多牛都没用,钱包扛不住你就不是工具”。但同时也有不少人在理性讨论,有人指出 M3 百万上下文的单次调用消耗本身就比普通模型高,如果不限总量,平台大概率扛不住。“可以理解提价,但不能接受偷偷改规则”,这句吐槽几乎概括了大部分用户的情绪。
对轻度用户来说,49 块的 Plus 套餐确实够用,甚至可以说很划算,6 亿 token 覆盖日常编码、问答、多模态生成绰绰有余。但对于重度 Agent 开发者,这个额度简直像给跑车配了个五升油箱。目前社区的普遍建议是:轻度用户选套餐,重度用户走按量计费,有预算的话等开源后自己部署。
多维评分
吵归吵,拉开六个维度从头梳理一遍。
| 维度 | 评分 | 一句话解读 |
|---|---|---|
| 功能完整性 | ⭐⭐⭐⭐⭐ | 编程+Agent+多模态三项齐活,国产独一份 |
| 易用性 | ⭐⭐⭐⭐☆ | OpenCode 零门槛,API 文档中等但够用 |
| 性价比 | ⭐⭐⭐☆☆ | 轻度用户划算,重度开发者成本暴涨 |
| 创新性 | ⭐⭐⭐⭐⭐ | MSA 架构是底层突破,非应用层换皮 |
| 稳定性 | ⭐⭐⭐⭐☆ | 推理质量稳定,但订阅规则突变伤了信任 |
| 推荐度 | ⭐⭐⭐⭐☆ | 编程和 Agent 场景强推,价格等开源后再定 |
综合评分:7.8 / 10
技术层面给 8.5 分都不过分,但商业策略拉了后腿。如果后续定价能回归开发者友好路线,这个分数还有上涨空间。
优缺点
优势
-
MSA 架构颠覆长文本成本:百万 token 推理成本降至上一代的 5%,全球范围都算硬核突破 -
编程+Agent 真实力:SWE-Bench Pro 比肩 Claude,12 小时自主复现顶会论文证明不是 PPT 跑分 -
即将开源,自由度拉满:支持私有化部署和微调,对企业用户是不小吸引力 -
全模态统一入口:一个 API Key 搞定文本、代码、图像、语音,切换模型不用换账号
不足
-
定价策略暗改惹众怒:从不限量到严格限总量,老用户实际成本暴涨,信任损伤严重 -
额度跟能力严重不匹配:百万上下文配 6 亿 token 月额度,重度 Agent 场景半个月就耗尽 -
多模态生态还不完整:视频生成仍依赖家族其他模型,各模态之间的协同链路还没打通
适用人群
看完上面这些,大概能判断出自己属于哪一拨。
-
AI 应用开发者:如果你在折腾 Agent、RAG、或需要长上下文编程能力,M3 是目前国产里最值得试的。百万 token 窗口在代码库级别的分析和重构上,跟 128K 的差距是降维打击。 -
重度编程用户:每天跟代码打交道的工程师,尤其是接手大型项目、需要跨文件理解业务逻辑的,M3 的长上下文加成非常明显。但建议走按量计费渠道,套餐对重度用户不划算。 -
企业 AI 团队:计划做私有化部署或者基于开源模型微调垂直能力的团队,M3 的开源承诺让它比闭源竞品多了不少操作空间。等模型权重正式放出后,企业可以直接在自己的 GPU 集群上跑。 -
轻度体验用户:只想日常问问代码、写点文档、偶尔玩玩多模态,Plus 套餐 49 块一个月完全够用,甚至可以说是这个价位上功能覆盖面最广的选择。 -
不太适合:如果你对性价比极其敏感、且编程场景不复杂,DeepSeek 仍然是更务实的选择。如果你需要最顶级的纯代码质量且不在乎价格,Claude Opus 4.7 还是老大哥。
定价方案
价格是这次发布最大的争议点,把账算清楚比什么都强。
| 版本 | 月费 | 月度 token 总量 | 核心权益 | 适合 |
|---|---|---|---|---|
| Plus | ¥49 | 6 亿 | 全模态基础权益,3-4 Agent 并发 | 轻度用户 |
| Max | ¥119 | 18 亿 | 全模态含视频,4-5 Agent 并发 | 中度开发者 |
| Ultra | ¥469 | 55 亿 | 全模态不限量视频,6-7 Agent 并发 | 团队/重度用户 |
| API 按量 | 输入 ¥2.1/百万 token | 无上限 | 输出 ¥8.4/百万 token,缓存读取 ¥0.42/百万 token | 重度 Agent 开发 |
以上价格均为截至 2026 年 6 月 1 日发布的 512K 以下上下文定价,发布首周享受五折活动。超过 512K 上下文的定价尚未公布。
坦诚地说,如果只看 API 按量计费的单价,2.1 元/百万 token 在国产大模型里算中等偏上但没到离谱的分位。真正的矛盾出在订阅套餐,老用户习惯了不限量,突然被锁死总量,心理落差比实际账单更伤人。轻度用户不会被影响,但重度用户的真实成本翻了两到三倍,这就是社区炸锅的根源。如果 MiniMax 后续能推出一档”高额不限速”的开发者专属套餐,或者把 Plus 档的总量翻倍,信任危机大概率能缓解。
可能还想问
前面聊了这么多,还有些细节可能正好是你关心的。
Q1:M3 支持中文吗?
A1:支持,而且中文能力是原生级别的。 M3 的预训练数据中包含大规模中文语料,中文理解和生成质量跟英文处于同一水平线,不是后期翻译补丁式的多语言支持。
Q2:什么时候能开源部署?
A2:官方承诺 10 天内发布技术报告并开源模型权重。 届时将在 HuggingFace 和 GitHub 同时放出,支持 vLLM 等主流推理框架。前代 M2.7 的开源协议禁止商用,M3 是否会采用更宽松的协议目前尚不明确。
Q3:M3 和 Claude/GPT 比编程谁更强?
A3:纯代码质量上 Claude Opus 4.7 略胜一筹,M3 在长上下文和自主执行能力上反超。 处理小型代码片段两者差距不大,但涉及跨文件重构或需要自主 Debug 的复杂任务时,M3 的百万上下文优势明显。
Q4:Token Plan 和旧版 Coding Plan 到底差在哪?
A4:核心变化是从”限量不限次”变成了”限总量”。 旧版算次数不管单次消耗,新版按实际 token 消耗扣减积分。对单次使用量小的轻度用户影响不大,对每次都跑几十万 token 上下文的 Agent 开发者就是成本暴涨。
Q5:能处理视频和语音吗?
A5:M3 本身只支持文本和图像输入。 视频和语音能力需要调用 MiniMax 家族的其他模型(Video-01、Speech-01 等),通过同一个 API Key 和令牌池可以统一调度,但各模态之间目前是独立调用的。
Q6:OpenCode 免费多久?
A6:官方说法是”限时免费使用”,未公布明确截止日期。 推测会在开源的模型权重发布前后结束,或者转为跟 Token Plan 绑定的增值服务。
Q7:跟 DeepSeek 比有什么优势?
A7:M3 在编程上限、Agent 自主执行和多模态能力上全面领先 DeepSeek,但 DeepSeek 的价格优势短期内难以撼动。 如果你的需求超出纯文本生成且预算允许,M3 更值得试;如果只追求性价比,DeepSeek 依然能打。
Q8:API 稳定吗?有没有限流?
A8:发布初期 API 稳定性尚可,但限流策略在调整中。 Plus/Max/Ultra 三档各有不同的 Agent 并发限制,高峰期偶尔会出现排队。按量计费目前没有公开的硬限流上限,但也不代表可以无节制高频调用。
Q9:能用 M3 做商业化产品吗?
A9:API 接入的商业化用途完全合规,Token Plan 也有商用授权。 开源后能否商用取决于最终的开源协议,这是所有等开源的开发者都在盯的事情,目前可以确定的是私有化部署和微调是开放的。
Q10:M3-highspeed 版本和标准版有什么区别?
A10:推理速度更快,结果完全一致。 highspeed 版的输入和输出价格均比标准版高 50%,适合对延迟敏感的生产环境。日常开发和测试用标准版完全够用。
最后的结论
MiniMax M3 在技术层面是国产大模型到这个时间点最硬核的一次进化。MSA 架构不是工程上的小修小补,而是从底层解决了长文本推理的成本问题;编程和 Agent 能力的实测表现也证明了跑分背后有真功夫。
但一面登顶技术,一面暗改定价,这种割裂感是发布当天最大的遗憾。如果你是一个靠 M3 跑长上下文 Agent 任务的开发者,技术上的提升确实让人兴奋,但在账单上会先挨一刀。如果你是轻度用户或者之前没怎么碰过大模型编程,49 块一个月换来一套全模态工具链,值回票价绰绰有余。
建议先趁发布首周的五折窗口跑一遍核心工作流,实际感受下百万上下文的真实价值。如果效果好,等开源权重放出来后自部署,彻底摆脱配额焦虑。