


这是一篇从零开始的自动化实战教程。我们用 SOLO(Work 模式)+ 飞书多维表格,搭建了一套“全自动作品采集系统”,支持论坛投稿自动抓取、AI 自动打标签、数据自动写入多维表格,最终形成一个可筛选、可排序、可统计的赛事作品集和数据大盘。小白也可以跟着复刻。
从一个痛点开始
「SOLO X 脉脉挑战赛」的参赛作品,都是通过在 TRAE 官方社区发帖提交。随着参与人数越来越多,赛事运营的同学就遇到了三个头疼的问题:
-
看不过来:新提交的作品帖淹没在海量帖子里,很难及时发现
-
找不到:想看某个行业或角色的作品?在社区里翻半天也找不全
-
没数据:一共投了多少作品?哪些作品最火?完全没有可视化的数据大盘
我们想过搭一个在线作品集网站,但从开发到部署到上线,耗时太长。我们需要的是一个更快、更轻量的方案。
这时候我们想到了「飞书多维表格」:它本身就支持筛选、排序、统计、可视化看板,天然适合做作品集展示。
而且,既然这次比赛就是用 SOLO 创作应用的,那为什么不用 SOLO 来搭这个系统呢?
说干就干!最终,这套系统帮我们自动采集了 3400+ 个参赛作品,并且一直在稳定运行。
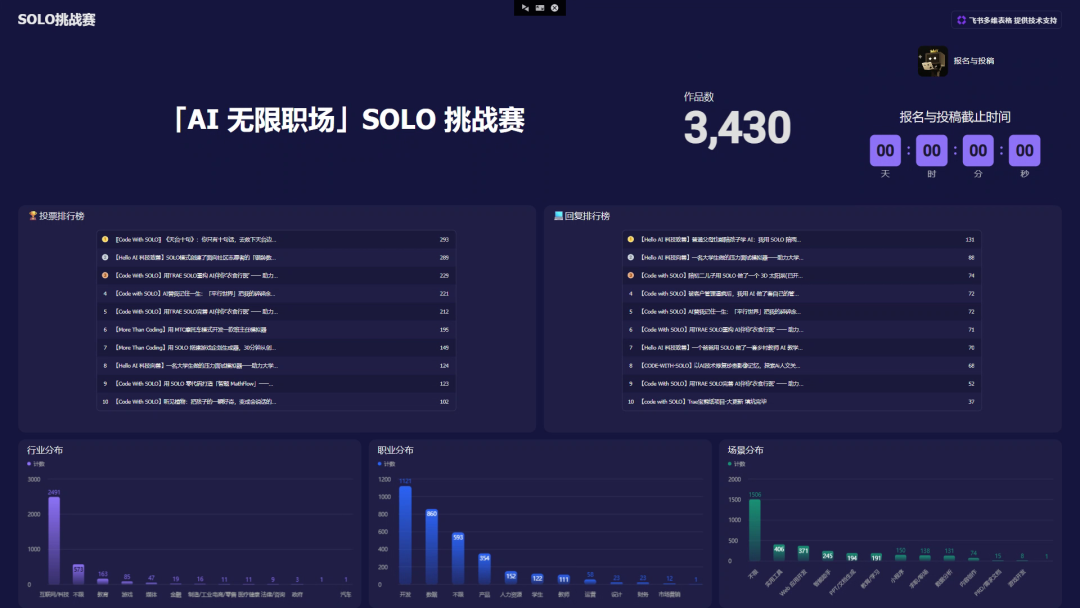
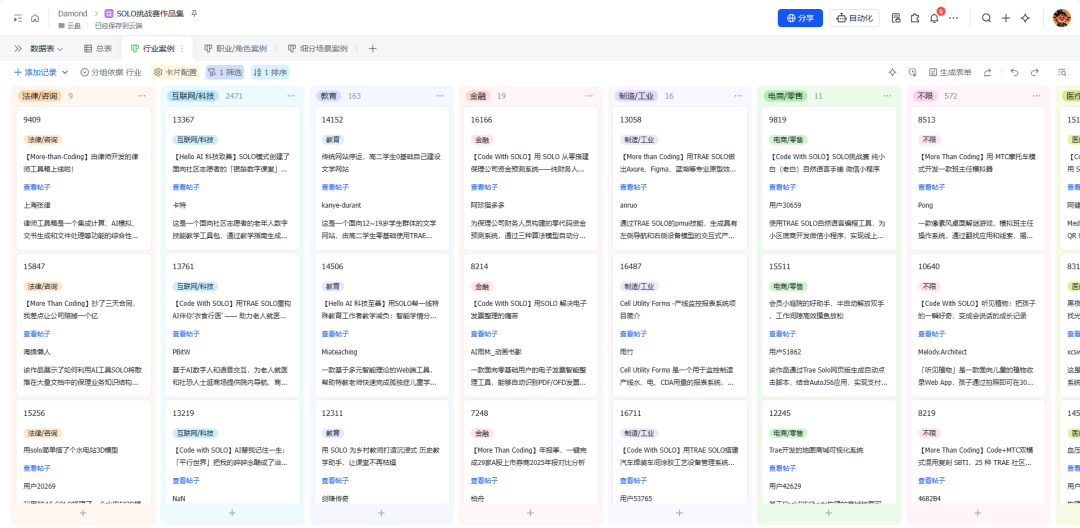
5 步搞定全自动作品集
第一步:和 SOLO 聊需求,让 AI 帮你梳理方案
针对这个任务,我选择的是 Work 模式。因为我需要 AI 帮我创建项目文件、配置飞书应用、部署到服务器,这些都不需要写复杂的代码框架,更多是“帮我做这件事”的指令式交互。
打开 SOLO,切换到 Work 模式,我输入了第一句话:/plan “论坛作品地址” 通过飞书多维表格定时更新获取链接论坛作品信息,写入多维表格 。
SOLO 帮我梳理了规划开发的需求:
-
自动采集:从 TRAE 论坛(forum.trae.cn)自动获取所有参赛作品帖
-
智能分析:AI 自动分析每个作品,提取行业、职业、技能类型等标签
-
多维展示:同步到飞书多维表格,支持筛选、排序、统计
-
全自动化:定时任务自动同步,无需人工干预
接着我又补充了几个关键需求:
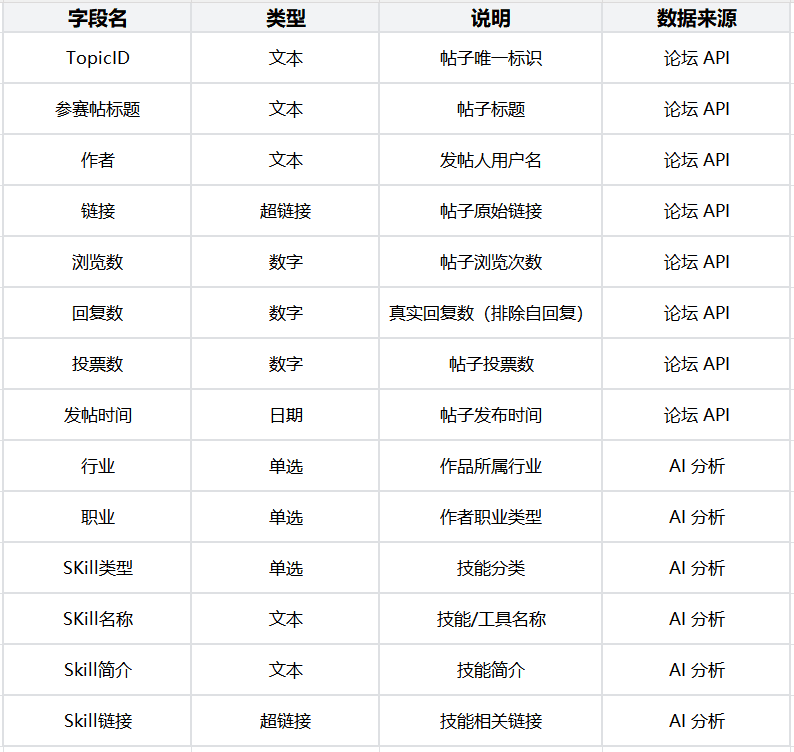
每个作品需要采集标题、作者、链接、浏览数、回复数、投票数、发帖时间。AI 分析出行业、职业、Skill类型、Skill名称、Skill简介、Skill链接。
SOLO 帮我把这些需求整理成了字段设计,这就是后来多维表格的 14 个字段。
第二步:配置飞书应用
这一步是整个项目的基础。没有飞书应用,就无法写入多维表格。
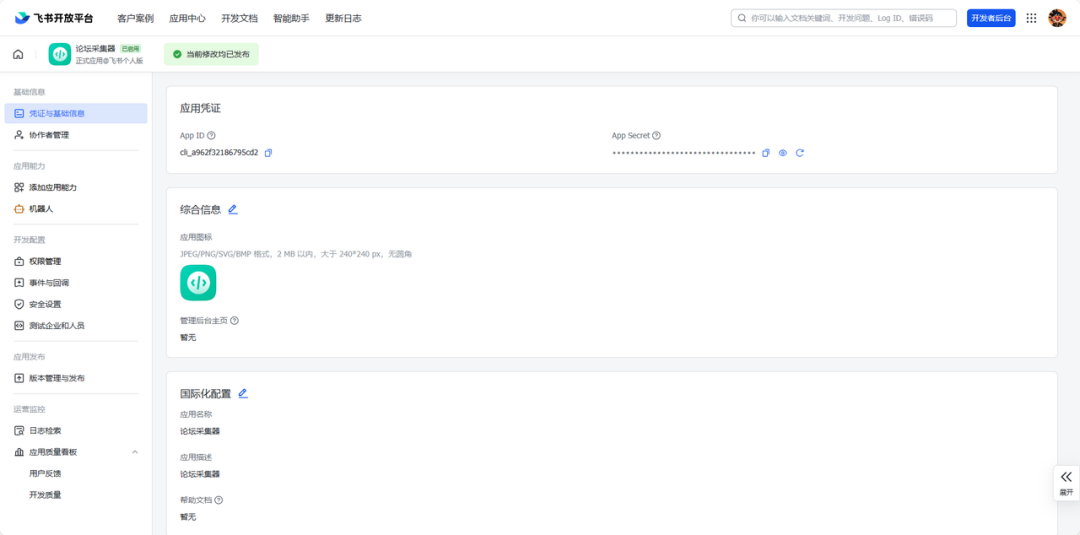
2.1 创建飞书应用
-
打开 飞书开放平台,登录账号
-
点击「创建应用」,选择「自建应用」
-
填写应用名称(比如”作品集采集”),上传图标
-
创建完成后,进入应用详情页
2.2 获取凭证
在应用详情页,找到「凭证与基础信息」:
-
App ID:应用的唯一标识
-
App Secret:应用的密钥(注意保密!)
这两个值后面配置代码时会用到。
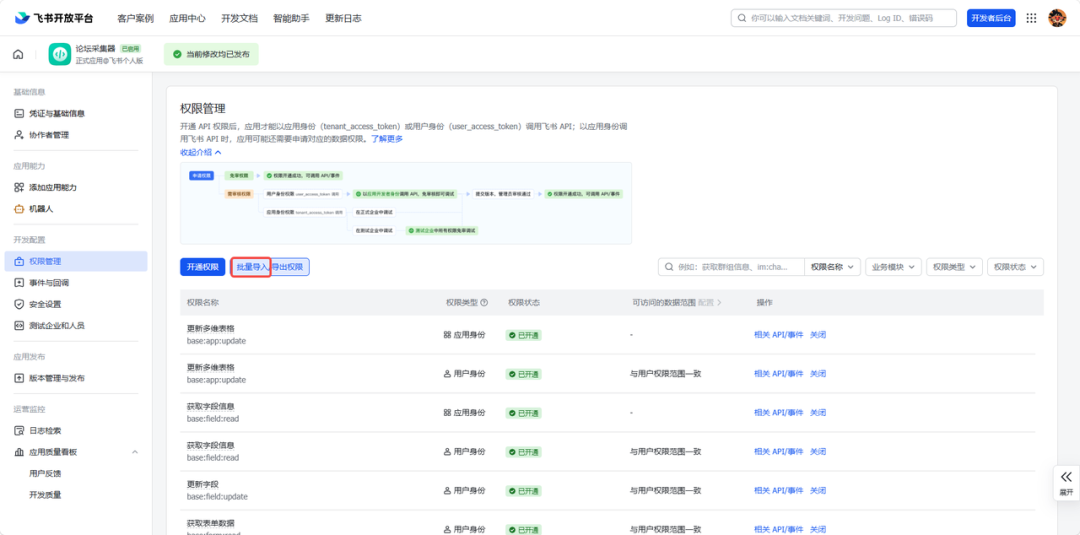
2.3 开通权限
在「权限管理」中,搜索并开通以下权限:
{
"scopes": {
"tenant": [
"base:app:update",
"base:field:read",
"base:form:update",
"base:history:read",
"base:record:create",
"base:record:delete",
"base:record:read",
"base:record:retrieve",
"base:record:update",
"base:table:read",
"base:table:update",
"bitable:app",
"bitable:app:readonly",
"im:resource"
],
"user": [
"base:app:update",
"base:field:read",
"base:field:update",
"base:form:read",
"base:form:update",
"base:history:read",
"base:record:create",
"base:record:delete",
"base:record:read",
"base:record:retrieve",
"base:record:update",
"bitable:app",
"bitable:app:readonly",
"im:resource"
]
}
}
2.4 发布应用
权限配置完成后,点击「版本管理与发布」→「创建版本」→「申请发布」。如果是企业内部应用,管理员审批通过后即可使用。
⚠️ 注意:应用发布后才能正常调用 API。如果发布前就想测试,可以先在”可用范围”中添加自己。
2.5 获取多维表格信息
打开你的飞书多维表格,从 URL 中提取两个关键信息:
-
App Token:URL 中 /base/ 后面的那串字符
-
Table ID:URL 中 table= 后面的那串字符
例如 URL 为 https://my.feishu.cn/base/ABCDEF123?table=tblXYZ789,则:
App Token = ABCDEF123 Table ID = tblXYZ789
第三步:飞书多维表格配置
我们前面聊了“基础配置,采集论坛数据,数据提取,AI智能分析,数据写入多维表格”,这里我们需要完成最后环节【多维表格配置】
3.1 多维表格字段配置
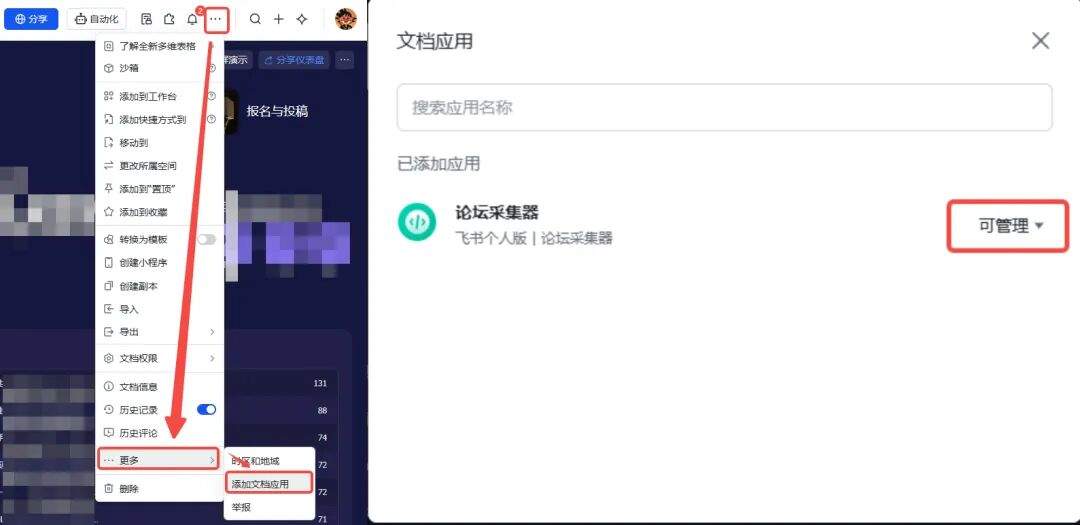
3.2 多维表格添加应用
飞书多维表格添加上面发布的飞书应用,实现数据可以写入多维表格
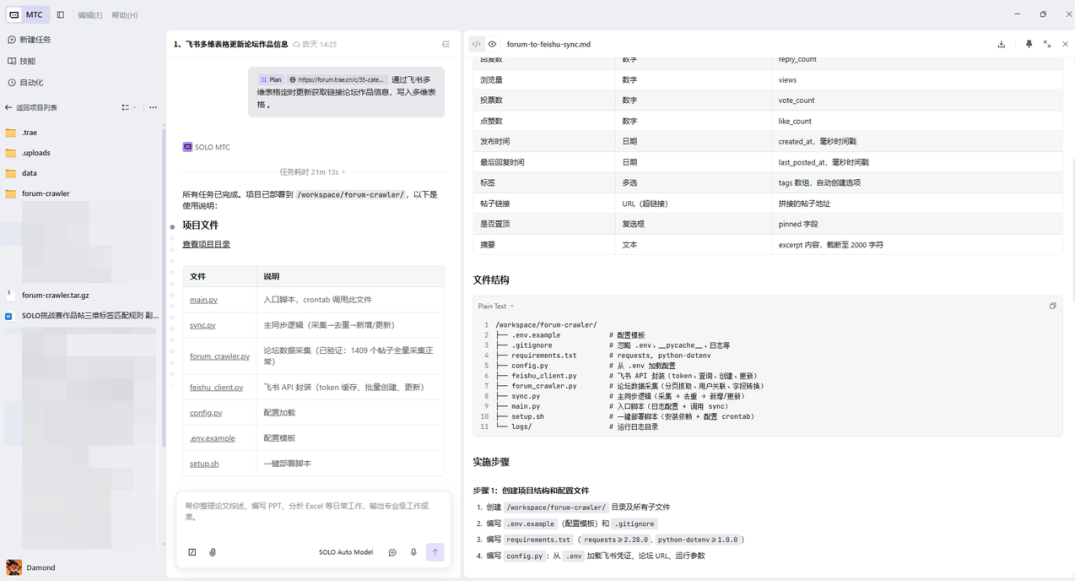
第四步:用 SOLO 开发采集服务
4.1 创建项目及代码【一句话完成开发】
SOLO,我继续对话:
根据以上plan最终规划方案,执行项目代码开发,实现论坛数据采集和飞书多维表格同步。
SOLO 自动帮我生成了完整的项目结构及代码,每个文件各司其职:
forum-crawler/├── config.py # 配置文件(代码配置)├── feishu_client.py # 飞书API客户端├── forum_crawler.py # 论坛数据采集├── ai_analyzer.py # AI智能分析├── sync.py # 增量同步逻辑├── main.py # 主入口├── .env # 环境变量(敏感信息:API密钥、密码等)└── requirements.txt # 依赖包
4.2 读懂项目文件内容和作用
4.2.1 配置文件config.py 与.env 是什么?
-
config.py,用于代码配置,通用配置项(URL、字段映射、常量等)调用敏感信息
-
.env,敏感信息存储
import os
from dotenv import load_dotenv
load_dotenv()
# 飞书凭证
FEISHU_APP_ID = os.getenv("FEISHU_APP_ID")
FEISHU_APP_SECRET = os.getenv("FEISHU_APP_SECRET")
FEISHU_APP_TOKEN = "**************"# 多维表格TOKEN
FEISHU_TABLE_ID = "***************"# 多维表格TABLE_ID
# 论坛 - 采集地址
FORUM_BASE_URL = "https://forum.trae.cn"
FORUM_CATEGORY_URL = "https://forum.trae.cn/c/37-category/37.json"
# 运行参数
LOG_FILE = os.getenv("LOG_FILE", "logs/sync.log")
LOG_LEVEL = os.getenv("LOG_LEVEL", "INFO")
REQUEST_TIMEOUT = int(os.getenv("REQUEST_TIMEOUT", "30"))
RATE_LIMIT_DELAY = float(os.getenv("RATE_LIMIT_DELAY", "0.1"))
# AI 配置(DeepSeek API,兼容 OpenAI 格式)
AI_BASE_URL = os.getenv("AI_BASE_URL", "https://api.deepseek.com/v1")
AI_MODEL = os.getenv("AI_MODEL", "deepseek-chat")
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY", "")
AI_TIMEOUT = int(os.getenv("AI_TIMEOUT", "60"))
# 字段映射配置
# TopicID, 行业, 职业, SKill类型, SKill名称, Skill简介, Skill链接如有, 参赛帖标题, 链接, 作者, 浏览数, 回复数, 投票数
FIELD_MAPPING = {
"topic_id": "TopicID",
"title": "参赛帖标题",
"author": "作者",
"link": "链接",
"views": "浏览数",
"replies": "回复数",
"votes": "投票数",
"industry": "行业",
"profession": "职业",
"skill_type": "SKill类型",
"skill_name": "SKill名称",
"skill_intro": "Skill简介",
"skill_link": "Skill链接如有",
}
4.2.2 飞书 API 客户端作用?
feishu_client.py 是飞书 API 的封装,核心功能:调用飞书接口实现数据传输
获取3.2配置文件的飞书配置内容提供飞书接口验证身份 清空多维表格现有数据记录
3. 批量传输最新论坛结果数据到多维表格
class FeishuClient:
def __init__(self, app_token, table_id):
self.app_token = app_token
self.table_id = table_id
def _get_token(self):
"""获取 tenant_access_token"""
# 使用 App ID + Secret 获取 Token
def batch_create_records(self, records):
"""批量创建记录,每次最多500条"""
def delete_all_records(self):
"""清空表格所有记录"""
关键点: 批量写入每次最多 500 条,超过需要分批 失败时需要指数退避重试(1秒→2秒→4秒)
4.2.3 论坛数据采集了啥?
通过 forum_crawler.py 采集论坛数据,基于官方论坛是 Discourse 开发的,提供了 JSON API格式,我们可以轻松解析提取想要的内容
# 获取帖子列表url = "https://forum.trae.cn/c/*****/26.json"response = requests.get(url)data = response.json()# 返回: {"topic_list": {"topics": [...]}}
采集逻辑: 4. 分页获取所有帖子(每页30条) 5. 解析 JSON 包,提取数据:帖子的标题、作者、浏览数、回复数、投票数 6. 计算真实回复数(排除作者自回复)
4.2.4 AI 智能分析有那些规则?
对每个帖子调用 AI API,提取结构化标签:
赛事运营同学根据大赛的标准:清晰梳理AI智能分析作品的定义标准Prompt,对AI返回可控数据的提供约束范围:
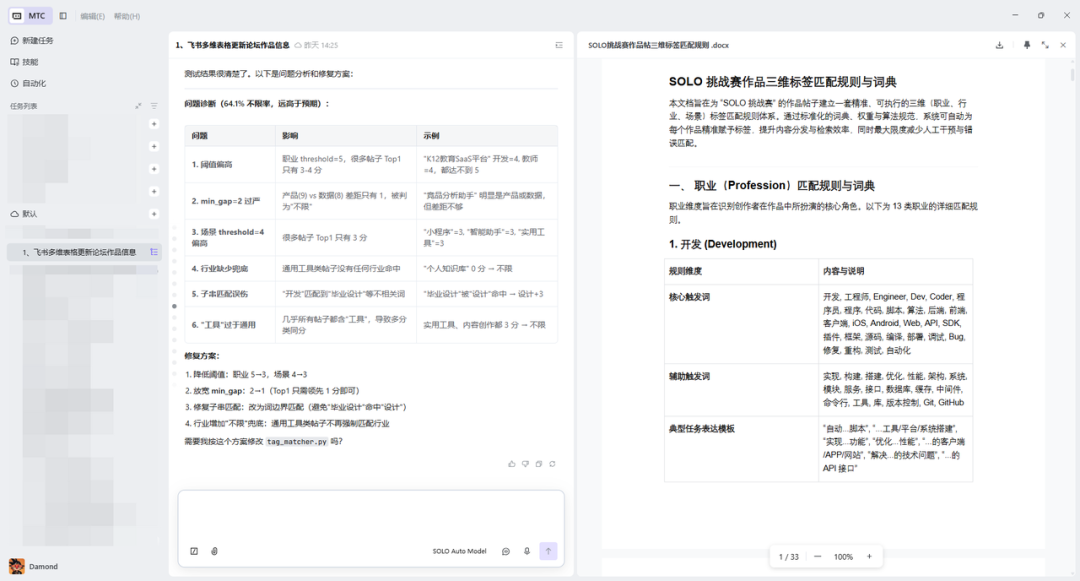
💡 小贴士:给 AI 的 Prompt 中要明确指定分类选项,这样 AI 返回的结果才能直接写入多维表格的单选字段。
4.2.5 增量同步机制怎么实现?
为了避免每次都全量分析,我们采用了增量同步:
每次同步流程:1. 获取论坛所有帖子2. 计算每个帖子的内容指纹 MD5(title + excerpt)3. 与本地缓存比对- 指纹相同 → 跳过(内容未变)- 指纹不同 → 重新AI分析- 新帖子 → AI分析 + 写入缓存4. 将需要更新的记录写入飞书
缓存存储在 ai_cache.json 文件中,结构如下:
{
"topic_12345": {
"hash": "abc123def456",
"行业": "互联网/科技",
"职业": "开发",
"SKill类型": "开发工具",
"SKill名称": "XXX工具",
"Skill简介": "一个XXX的工具",
"Skill链接": "https://..."
}
}
第五步:部署到服务器
本地测试通过后,需要部署到服务器实现长期运行。
由于 Work 模式并不支持直接远程服务器部署,我们需要手动上传项目包,执行一下解压安装,运行操作!
5.1 服务器环境准备
# 安装 Python 3sudo apt update && sudo apt install python3 python3-pip -y
# 安装依赖pip3 install requests python-dotenv --break-system-packages
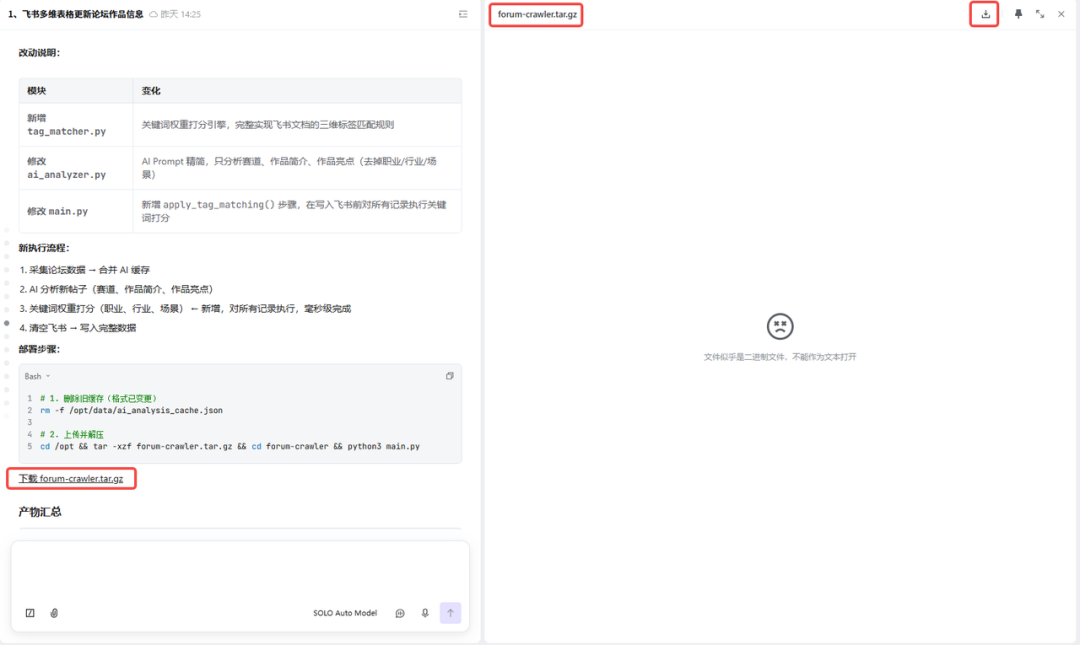
5.2 上传项目文件并解压
将整个 forum-crawler/ 目录上传到服务器:
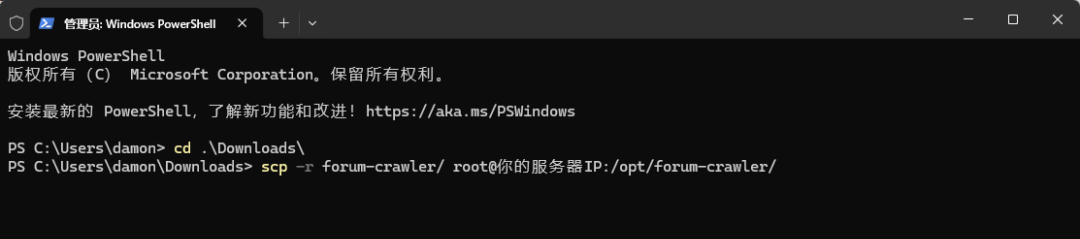
# 方法1:使用 scpscp -r forum-crawler/ root@你的服务器IP:/opt/forum-crawler/# 方法2:使用 gitgit clone 你的仓库地址 /opt/forum-crawler
我这边按照方法1进行简单介绍:
下载项目文件包到本地电脑文件夹📂download 通过Windows PowerShell执行终端上传⏫操作
登录Linux服务后台,执行解压项目文件包
cd /opt && tar -xzf forum-crawler.tar.gz
5.3 配置环境变量
在服务器上创建 .env 文件:
cd /opt/forum-crawlernano .env
填入实际的配置值:前面准备的飞书应用 FEISHU_APP_ID 和 FEISHU_APP_SECRET、AI API_KEY 填写进去。
FEISHU_APP_ID=cli_xxxxxxxxFEISHU_APP_SECRET=xxxxxxxxxxAI_API_KEY=sk-xxxxxxxxxx
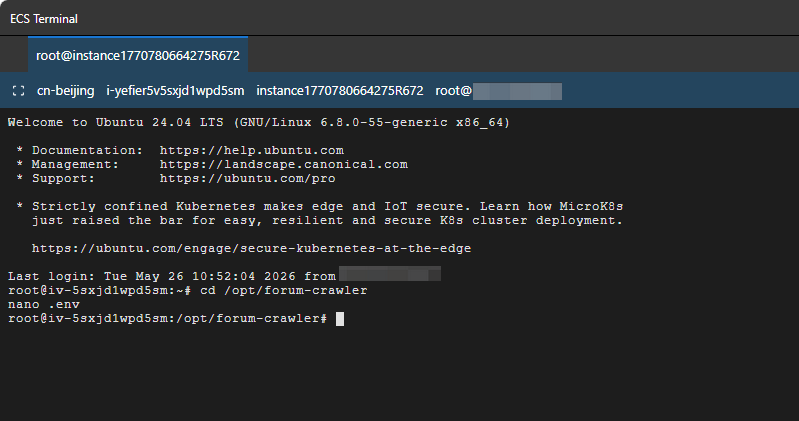
完成编辑后:按ctrl+x 退出,按Y保存
5.4 首次运行测试
cd /opt/forum-crawlerpython3 main.py
观察日志输出,确认: 论坛数据采集成功 AI 分析正常返回 飞书多维表格写入成功
5.5 设置定时任务
crontab -e
添加定时任务(每小时执行一次):
0 * * * * cd /opt/forum-crawler && /usr/bin/python3 main.py >> /opt/forum-crawler/logs/cron.log2>&1
💡 小贴士:定时任务的日志输出到文件,方便排查问题。建议定期清理日志文件,避免磁盘占满。
最终成果
以下为 TRAE 论坛数据流转蓝图

经过以上步骤,最终实现了:
3400+ 参赛作品自动采集 14个 字段的结构化数据 每小时 自动同步更新 AI 智能 标签提取(行业、职业、技能类型) 增量同步,只处理新增和变更内容 7×24 小时 自动运行,无需人工干预
踩坑实录
开发过程中踩了不少坑,挑最典型的 5 个分享给大家,希望帮你少走弯路:
问题1:字段名称一致性问题
现象:写入飞书时报错 FieldNameNotFound 原因:代码中用了英文字段名(如 username),但飞书表格创建的是中文字段名(如 用户名) 解决:统一使用中文字段名,和飞书表格保持完全一致
问题2:字段格式一致性问题
现象:写入超链接字段时报错 原因:超链接字段直接传了 URL 字符串,但飞书要求特定格式 解决:超链接字段使用 {“link”: “https://…”, “text”: “查看帖子”} 格式
问题3:资源规划合理性问题
现象:每次同步都调用 AI 分析所有帖子,API 费用很高 解决:实现增量分析,只对新增或内容变更的帖子调用 AI,缓存未变更的分析结果
问题4:Rate Limit 限流
现象:请求频率过高被飞书 API 限流 解决:实现指数退避重试机制(1秒→2秒→4秒→8秒),每次请求之间增加延迟
问题5:全量同步效率低
现象:3400+ 帖子每次全量处理需要很长时间 解决:增量同步 + 分页获取 + 并发处理,只处理变更的数据
写在最后
如果把最核心的经验浓缩成几句话,就是下面这 6 条:希望能帮助大家在做类似项目时少走弯路:
-
先梳理需求,再动手开发 — 和 SOLO 对话时把需求说清楚,包括字段名、字段类型、数据来源、目标位置
-
飞书配置是第一步 — 先创建应用、开通权限、发布应用,然后再写代码
-
增量思维 — 不要每次全量处理,用缓存和指纹比对实现增量更新
-
错误处理要完善 — API 调用会失败,必须有重试机制和日志记录
-
先本地测试,再部署服务器 — 确保本地跑通后再上传到
-
Work — Work 展现的意图理解能力和规划能力超强。