
看到10.7k Stars的时候,我的第一反应很直接:又一个靠”对标ElevenLabs”上位的开源项目。GitHub上这类项目太多了,README写得天花乱坠,装完第一步就报错。
光看Star数我被骗了
但Voice-Pro不太一样。它把Whisper语音识别、多种TTS引擎、零样本语音克隆、Demucs人声分离、YouTube下载和实时翻译塞进了一个Gradio WebUI里。这不是”又一个TTS工具”,更像是一个语音AI的瑞士军刀。而且v3.2起完全开源(GPL-3.0),不再有付费墙。
这篇文章想聊的是一个更具体的问题:一个功能炸裂但维护已经暂停了的项目,现在还值不值得你花时间去装、去配、去折腾。我会把它的真实优势、已知的坑、社区的反馈都说清楚。
说白了就一句话:Voice-Pro是目前功能最全的开源语音AI集成方案,但它的”全”也恰恰是它最脆弱的地方。如果你有一张NVIDIA显卡,愿意折腾配置,它能帮你省下每月几十美金的SaaS订阅费。但如果你想要开箱即用,这篇文章可能会让你改主意。
打动我的几个地方
Voice-Pro最让我意外的是它的”全链路”设计思路。
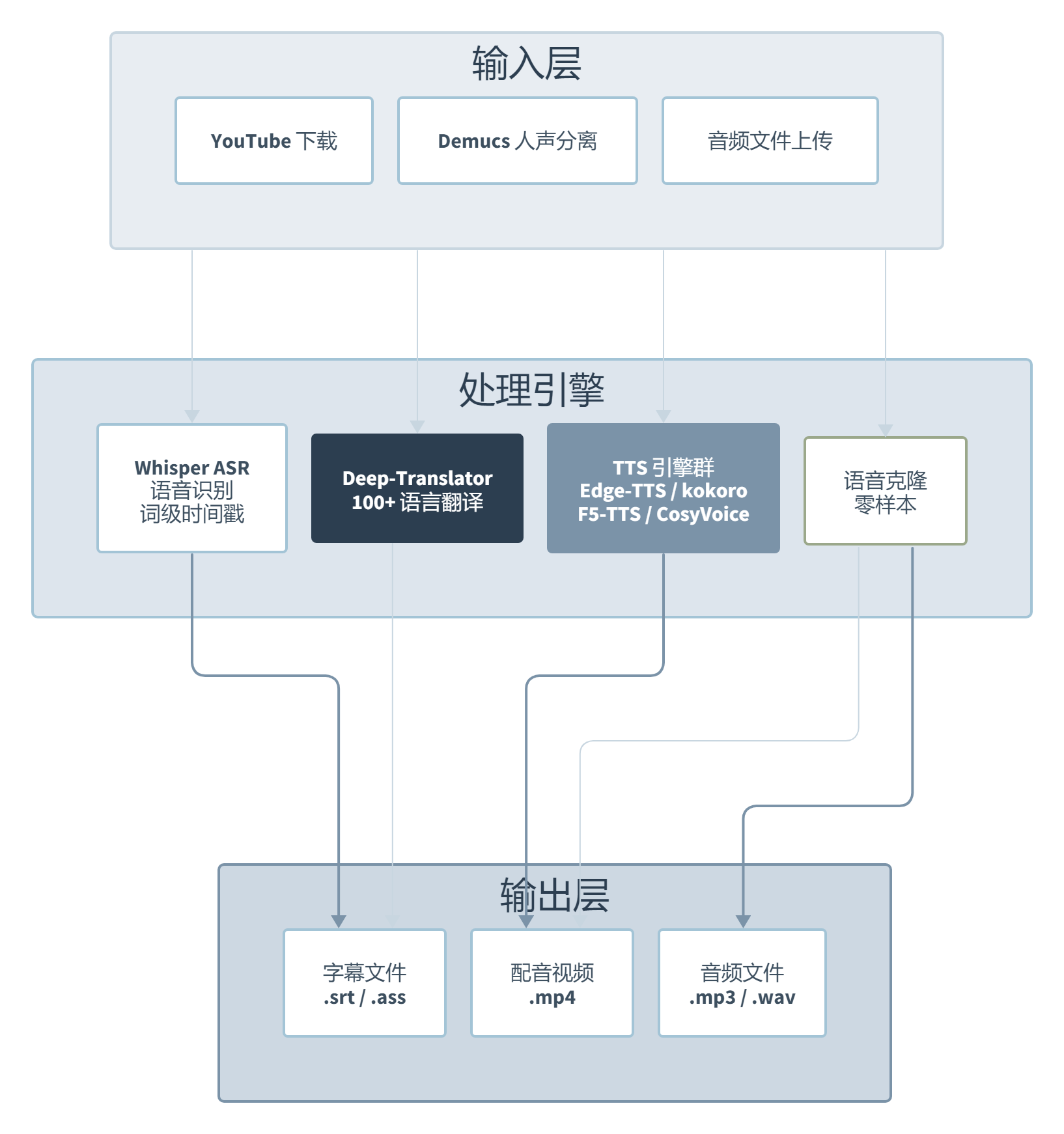
一般开源语音项目只做一件事:要么是TTS,要么是ASR(语音识别)。Voice-Pro把整个多媒体内容处理链条都塞进去了,YouTube下载、人声分离、语音识别、翻译、配音一条龙。这个设计在商业SaaS里不稀奇,但开源方案里这么干的,真的不多见。
技术栈的厚度也值得一说。它不只是挂了几个API,而是深度集成了多个SOTA模型。WhisperX做词级时间戳对齐,Edge-TTS覆盖100多种语言、400多个声音,还有F5-TTS和CosyVoice做零样本语音克隆。CosyVoice在HuggingFace TTS Arena上口碑相当不错,中文和跨语言克隆能力尤其突出。
另一个容易被忽略的点是它内置的参考声音库。50多个名人声音样本,从Joe Rogan到迪丽热巴,覆盖英中日韩四种语言。这是个看似细小但很聪明的设计,对于想快速体验语音克隆效果的新手来说,门槛直接降了一大截。不用自己准备参考音频,点一下就能听到效果。
不过我得说清楚:这些集成的”厚”也是双刃剑。每个模型都是重量级依赖,CosyVoice2-0.5B模型就要约9GB,首次安装可能需要一个多小时。这跟”一键安装”的体验差了不是一点半点。Issue区里关于安装失败的报告占了将近一半,这个后面细说。
价格对比是最有说服力的。处理60分钟视频的字幕、翻译和配音,商业SaaS如Descript或HappyScribe要35到48美元,Maestra也要近24美元。Voice-Pro的成本是零。如果你每个月处理几个小时的视频内容,省下来的订阅费够你升级显卡了。
但数据好看不等于能用得顺手。实际打开看看,上手到底什么感觉?
上手什么感觉
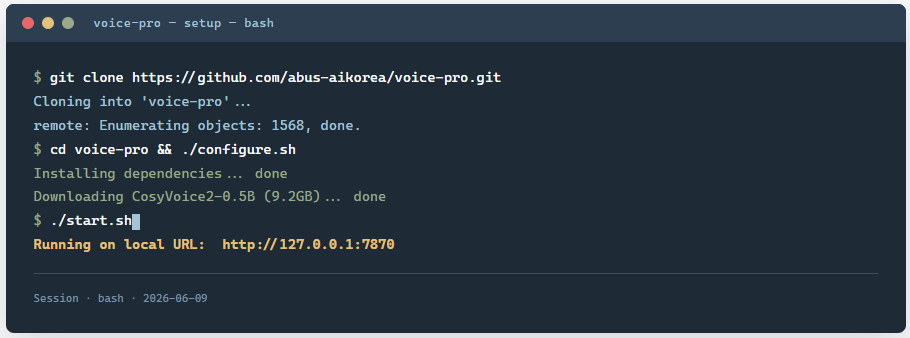
理论上看README,Voice-Pro的上手只要三步就能跑起来。
git clone https://github.com/abus-aikorea/voice-pro.git
configure.bat # 安装git、ffmpeg、CUDA环境
start.bat # 启动WebUI
实际上,第三步经常卡住。
Issue #85详细记录了一个典型场景:在Windows上使用CPU模式或AMD显卡时,依赖冲突让安装直接失败。
Issue #90则展示了Linux下pip/setuptools版本过高导致的4个安装bug,提交者甚至直接附上了修复方案。
两个Issue至今都是Open状态,没有任何维护者回复。
启动成功后(假设你成功了),浏览器打开 http://127.0.0.1:7870,一个Gradio风格的WebUI映入眼帘。四个标签页分别是Dubbing Studio、Whisper Caption、Translate、Speech Generation。对于用过Gradio的人来说一切很熟悉,但对于普通用户,这个界面的信息密度会让人有点不知所措。
“第一个Demo”的体验高度取决于你的硬件。RTX 3080以上、8GB VRAM的用户跑起来很流畅,但如果是4GB VRAM,CUDA out-of-memory会频繁出现。更麻烦的是RTX 5070这种Blackwell新架构显卡,直接报CUDA “no kernel image”错误。Issue #74和#75报告了这个问题,提交于2026年3月,至今无人解决。有用户留下了一句简短的评价:“Always get errors”,点出了很多人没说出口的痛点。
体验上的坑说清楚了。不过更关键的问题还没聊:什么样的场景和人群才真正适合这个项目?
什么时候用,什么时候别用
Voice-Pro最适合下面这三类人。如果你正好在其中,这个项目值得你花点时间折腾。
内容创作者 + NVIDIA显卡 → 用它做YouTube视频的多语言配音,成本从每月$30降到零
开源语音AI探索者 → 一个WebUI里对比多种TTS/STT引擎,省去逐个安装的麻烦
预算有限的翻译/字幕团队 → 100+语言字幕生成和翻译,商业方案的好几倍价格
但它也不适合很多人。如果你没有NVIDIA显卡,或者用的是AMD/Intel GPU,装都装不上去。如果你追求”开箱即用”的生产力工具,Voice-Pro的环境配置会让你怀疑人生。如果你只需要一个简单的TTS功能,装整个Voice-Pro等于用大炮打蚊子。
替代方案取决于你的需求。只需要TTS的话,kokoro(82M参数,Apache协议,极轻量)或者Edge-TTS单独部署已经足够。需要更专业语音克隆的,Fish Audio或CosyVoice 3.0在质量上可能更胜一筹。Voice-Pro的核心差异不是单项能力最强,而是”全都在一个界面里”的集成便利。这个差异值不值得你去折腾安装,自己掂量。
聊完了场景,该聊点现实的了——这个项目能跟多久?
社区怎么样了
截至2026年6月,Voice-Pro有10.7k Stars和1.6k Forks。对于一个韩国开发者团队的项目来说,这个数据相当亮眼。
| 指标 | 数据 | 解读 |
|---|---|---|
| Stars | 10.7k | 在语音AI工具中属于上游 |
| Open Issues | 36个 | 数量合理,但关键bug修复严重滞后 |
| Open PRs | 10个 | 社区贡献活跃,但合入速度几乎为零 |
| 维护状态 | 暂停 | README明确标注因WeConnect开发而暂停 |
| 核心贡献者 | 1-2人 | Bus Factor极低,单点风险极高 |
但Star数不能当饭吃。真正让我警惕的是维护状态。README中文版里白纸黑字写了:”由于WeConnect开发工作,Voice-Pro的开发和更新暂时无法进行。”这不是我猜的,是维护者自己说的。
一个10k Stars的项目,核心依赖更新跟不上、新GPU的CUDA问题修不了、社区PR堆在那没人合。开源代码是好事,但等于放弃了维护责任。如果我是技术选型者,这个消息比任何bug都让我更不安。
Issue区的氛围倒是很真实。有人热心地提交了详细的bug修复方案(#90带了4个fix),有人反复请求语言支持(印尼语、阿拉伯语、土耳其语的请求全部Open中),也有人直接摔下一句”Always get errors”就走了。从提交时间来看,2026年3月到6月的新Issue目前全部处于Open状态,没有任何维护者回复。这是个不容忽视的危险信号。
说完了数据,该聊聊我的真实看法了。这个项目,到底值不值得跟?
我的真实看法
从文档和社区反馈综合来看,我对Voice-Pro的核心判断是这样的:它是一个在正确方向上做了很大胆尝试的项目,但目前卡在了一个尴尬的阶段。功能足够好到让人兴奋,但维护状况差到让人犹豫。
Voice-Pro最独特的价值不是任何单项技术,而是它的集成厚度。在语音AI这个领域,大部分开源项目专精一项:要么做TTS,要么做ASR。Voice-Pro是为数不多的试图把整个多媒体内容处理管道统一到一个WebUI里的项目。这个方向是对的,内容创作者不需要十个不同的工具,他们需要一个能从头做到尾的工作站。
但它的最大风险也恰恰来自这个”厚”字。集成越多,依赖越多,出问题的概率越高。Whisper需要CUDA,F5-TTS需要特定版本的PyTorch,CosyVoice需要9GB的模型下载,ffmpeg需要在系统PATH里。任何一个环节出问题,整个链条就断了。这就是为什么Issue区安装失败的报告像复制粘贴一样反复出现。
趋势判断上,我比较悲观。v3.2是最后一个版本,维护者公开说重心已经转向WeConnect。10k Stars的项目如果没人维护,1到2年内就会因为依赖老化、新硬件不兼容而逐渐变得无法使用。除非社区能接过维护棒,但目前看不到这个迹象。
不过换个角度看,如果你现在有一套符合要求的硬件(RTX 30/40系列,8GB+ VRAM,Windows系统),装好v3.2版本后离线使用,它的功能并不会因为”维护暂停”而打折扣。CosyVoice不会因为没更新就变差,WhisperX也不会因为没人维护就识别不准。问题的关键是”能装得上”这个前提。
和ElevenLabs的对比有个微妙的点:ElevenLabs提供的是即用的SaaS体验,Voice-Pro提供的是免费但需自建的开源方案。两者的目标用户不完全重叠。如果你每周处理3个以上视频,Voice-Pro帮你省下的订阅费是实打实的。但如果你每月只用几次,折腾它的时间成本可能远超订阅费。
资源地址
| 资源 | 地址 |
|---|---|
| GitHub | https://github.com/abus-aikorea/voice-pro |
| 官方网站 | https://abus-aikorea.github.io/voice-pro/ |
| 中文README | https://github.com/abus-aikorea/voice-pro/blob/main/docs/README.zh.md |
以上是所有关键链接。分析聊完了,最后说点实际的:面对这样一个项目,你该做什么。
聊完了,你该干嘛
如果你有一张NVIDIA显卡,也不怕折腾配置,Voice-Pro是目前开源语音AI领域功能最全的集成方案。v3.2版本下载下来,照着中文README跑,装成功以后它能帮你省下不少SaaS订阅费。装不上的话也别死磕,Issue区里跟你同样遭遇的人不少,但不要指望维护者来救你。
如果你没有NVIDIA显卡,或者追求即装即用,别碰它。等社区出一个Docker镜像或者一键安装包再说。
如果只是想体验零样本语音克隆,试试CosyVoice或F5-TTS的独立版本就行,犯不着装整个Voice-Pro。如果你已经在用ElevenLabs且每月只用几小时,也不用换。SaaS的便利性就是它的价格。
FAQ
Q1:Voice-Pro可以商用吗?
A1:可以,但有代价。 GPL-3.0协议允许商用,但分发衍生作品时必须同样以GPL-3.0开源。如果你的产品是基于Voice-Pro二次开发的,整份代码都需要开源。这一点和Apache/MIT类协议完全不同,商业使用时务必和法务确认。
Q2:没有NVIDIA显卡能用吗?
A2:几乎不能。 README推荐CUDA 12.4加4GB以上VRAM。虽然文档提到了CPU模式,但Issue #85显示Windows下CPU/AMD GPU模式的依赖冲突严重,实际成功率很低。Mac用户也未经过充分验证。
Q3:和ElevenLabs比,语音克隆质量怎么样?
A3:有差距,但够用。 ElevenLabs在音色还原度和自然度上仍领先。Voice-Pro集成的F5-TTS和CosyVoice在中文和韩文上表现不错,但英语语音克隆的细腻程度不如商业方案。适合批量处理、非精修场景。
Q4:项目还维护吗?
A4:不维护了。 维护者在README中明确表示开发重心已转向WeConnect项目,Voice-Pro代码已全部开源并停止活跃开发。现有功能可用,但新bug不会修复,新GPU也不会适配。
Q5:安装要多久?
A5:顺利的话30到60分钟。 主要是首次运行时的模型下载。CosyVoice2-0.5B约9GB,加上其他模型,建议预留20GB以上存储空间和稳定网络。如果不顺利(如依赖冲突),时间不可控。
Q6:和GPT-SoVITS、CosyVoice独立版比,Voice-Pro的优势是什么?
A6:一站式集成。 GPT-SoVITS是纯语音克隆,CosyVoice独立版只是TTS引擎。Voice-Pro把它们和Whisper ASR、翻译、YouTube下载、人声分离整合在同一个WebUI里。单点能力可能不如专项工具,但管线整合的便利性是独特价值。
Q7:RTX 50系列显卡能用吗?
A7:目前不行。 Issue #74和#75报告了RTX 5070 Laptop GPU的CUDA “no kernel image”错误,Blackwell架构的CUDA内核尚未被项目的PyTorch版本支持。需要社区自行更新依赖后才能解决。