

代码库大到一个团队要干两个月,它一天跑完。这不是科幻,是 Claude Fable 5 在 Stripe 5000 万行 Ruby 代码上的真实战绩。Anthropic 把原本只给少数机构的 Mythos 级能力公开了,代价是价格翻倍、6 月 23 日后从订阅里踢出去单独收费。它到底强在哪,普通人用不用得起,上手试完这篇给你盘清楚。
这到底是什么
Claude Fable 5 是 Anthropic 于 2026 年 6 月 9 日发布的第五代大模型,被官方定位为 Mythos 级,这是 Anthropic 模型家族的最高等级,之前只通过 Project Glasswing 向少数网络安全和关键基础设施机构开放。Fable 5 是首次把这个级别的能力大规模推给普通用户和开发者。
跟 Claude Opus 4.8 那种“更强更准的聊天模型”不同,Fable 5 的定位更激进:它是一个为长时间异步 Agent 任务设计的底座。官方明说它不是优化单轮问答的,而是给 Claude Code、Agent 工作流准备的。它能在无人监督的情况下连续跑数天,自己规划子任务、自己检查进度、自己修正错误。
安全机制也做了分层。Fable 5 和同步发布的 Mythos 5 共享同一底层模型,但 Fable 5 加了安全分类器,当你问网络安全、生物化学、模型蒸馏等高风险问题时,系统自动切到 Opus 4.8 来响应。超过 95% 的对话不会触发这个开关,但偶尔会有误判。
官网:https://www.anthropic.com/claude/fable
到底强在哪
前面说了它是给 Agent 准备的底座,那具体到各项能力上,Fable 5 到底比前代强了多少?来看几组硬数据。
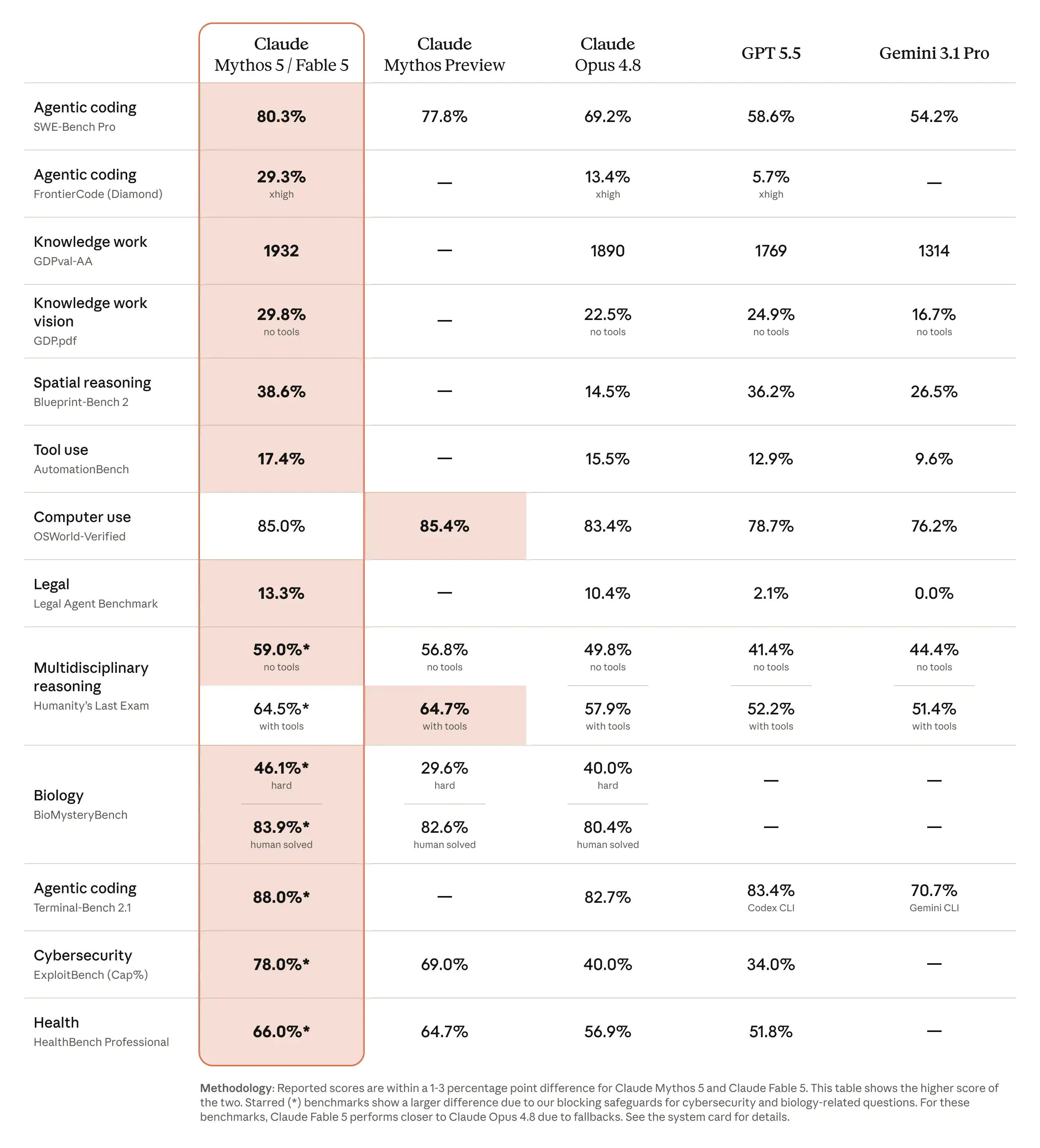
软件工程能力是这个模型最炸裂的卖点。 在 SWE-bench Verified 上拿到 95%,SWE-Bench Pro 拿到 80.3%,不仅碾压 Opus 4.8 的 69.2%,也把 GPT-5.5 的 58.6% 和 Gemini 3.1 Pro 的 54.2% 远远甩开。更直观的案例:Stripe 用它处理一个 5000 万行 Ruby 代码库的全量迁移,一天跑完,而人工团队原先预估要两个多月。
知识工作也刷新了天花板。 在 Hebbia 金融基准测试上拿了最高分,Hex 的 AI 研究负责人说它是第一个在他们核心分析基准上突破 90% 的模型,比 Opus 高出整整 10 个百分点。文档推理、图表解读、多步骤问题解决,每一项都有两位数级别的提升。
视觉能力成了新 SOTA。 能从复杂科学图表里精确提取数值,仅靠截图就能还原一个 Web 应用的完整源码。更夸张的是,只靠游戏画面、没有额外信息,它通关了《宝可梦火红》。在《杀戮尖塔》测试里,给它文件级持久内存后,性能是 Opus 4.8 的三倍。
长任务不掉链子。 沃顿商学院教授 Ethan Mollick 让它开发一个叫 Concord 的研究工具,模型先写了 19 页设计文档,然后连续工作 9 个半小时完成开发。这在以前的 Claude 上是不可想象的,之前的模型跑着跑着就容易偏航。
跟竞品的关键能力差距,一个表就看清楚了:
从零开始试
功能听着很猛,但用起来门槛高不高?作为 API 驱动的大模型,Fable 5 的上手路径和一般 SaaS 产品不太一样。
注册 Anthropic 账号本身不复杂,Google 登录即可。关键区别在接入方式:普通用户通过 claude.ai 网页端就能用,开发者走 API(platform.claude.com),企业走 Bedrock 等云市场。如果你是 Claude Pro 或 Max 订阅用户,6 月 22 日前 Fable 5 直接包含在套餐里,打开模型选择器就能切过去。
第一次用 Fable 5 的感觉很微妙。简单的问答场景里,它和 Opus 4.8 的区别不太明显。但如果扔给它一个复杂任务,比如要求按接口文档写一个完整的 REST API 服务、包含认证和测试用例,差距立刻拉出来了。
Fable 5 不会直接给你糊一段代码交差。它会先拆分任务结构,列出技术选型理由,然后分步骤实现。中间遇到不确定的地方,它会自己写测试验证,而不是停下来问你。这一点跟 Opus 4.8 那种“走到一半等你指路”的行为模式完全不同。
但也有让人皱眉的地方。Token 消耗是真的猛。我在 Pro 套餐下跑了一个中等复杂度的项目重构任务,大概两小时就用掉了当天的额度。如果你习惯把 Opus 当免费劳动力随便用,切换到 Fable 5 的体验会让你肉疼。
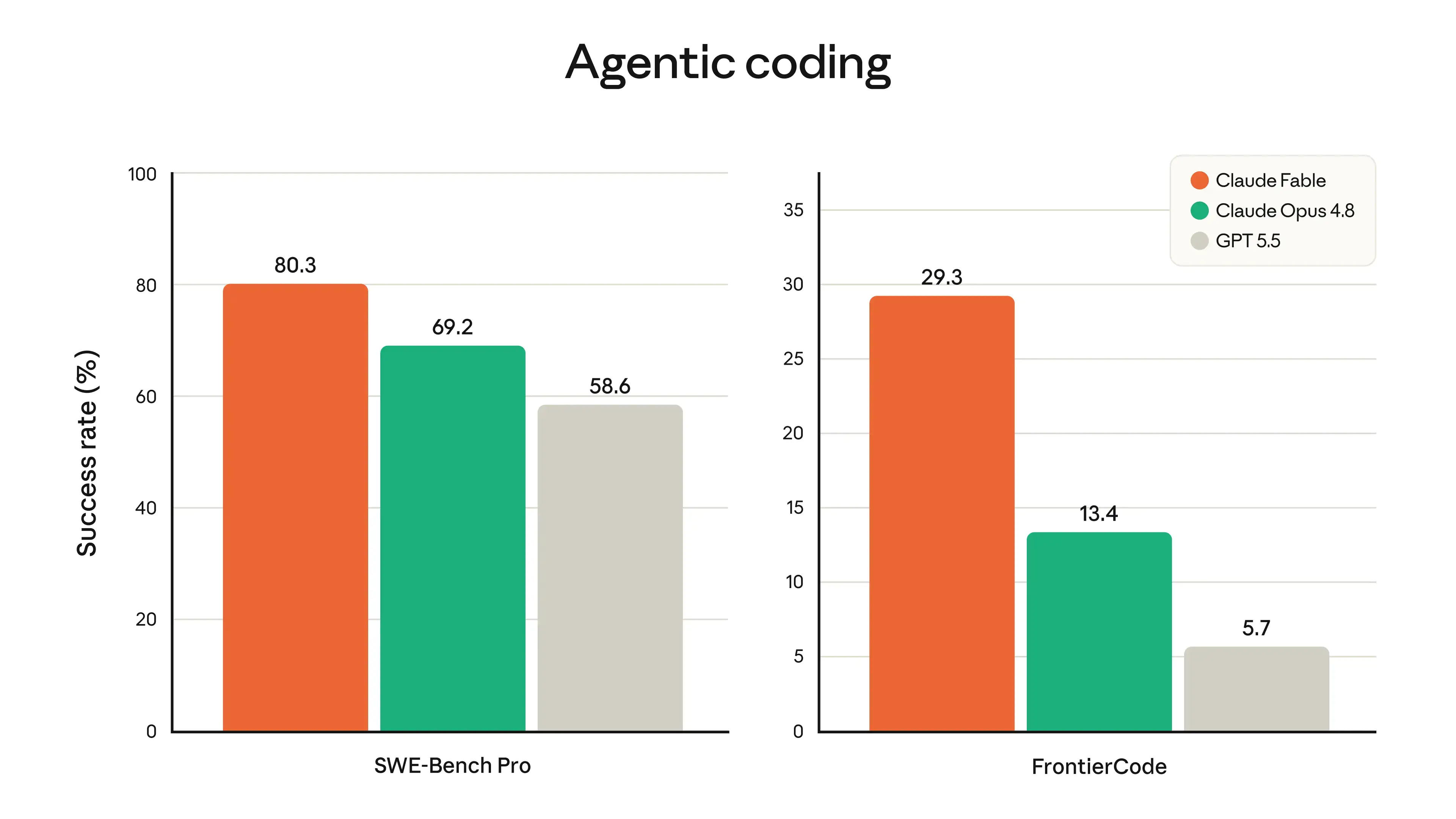
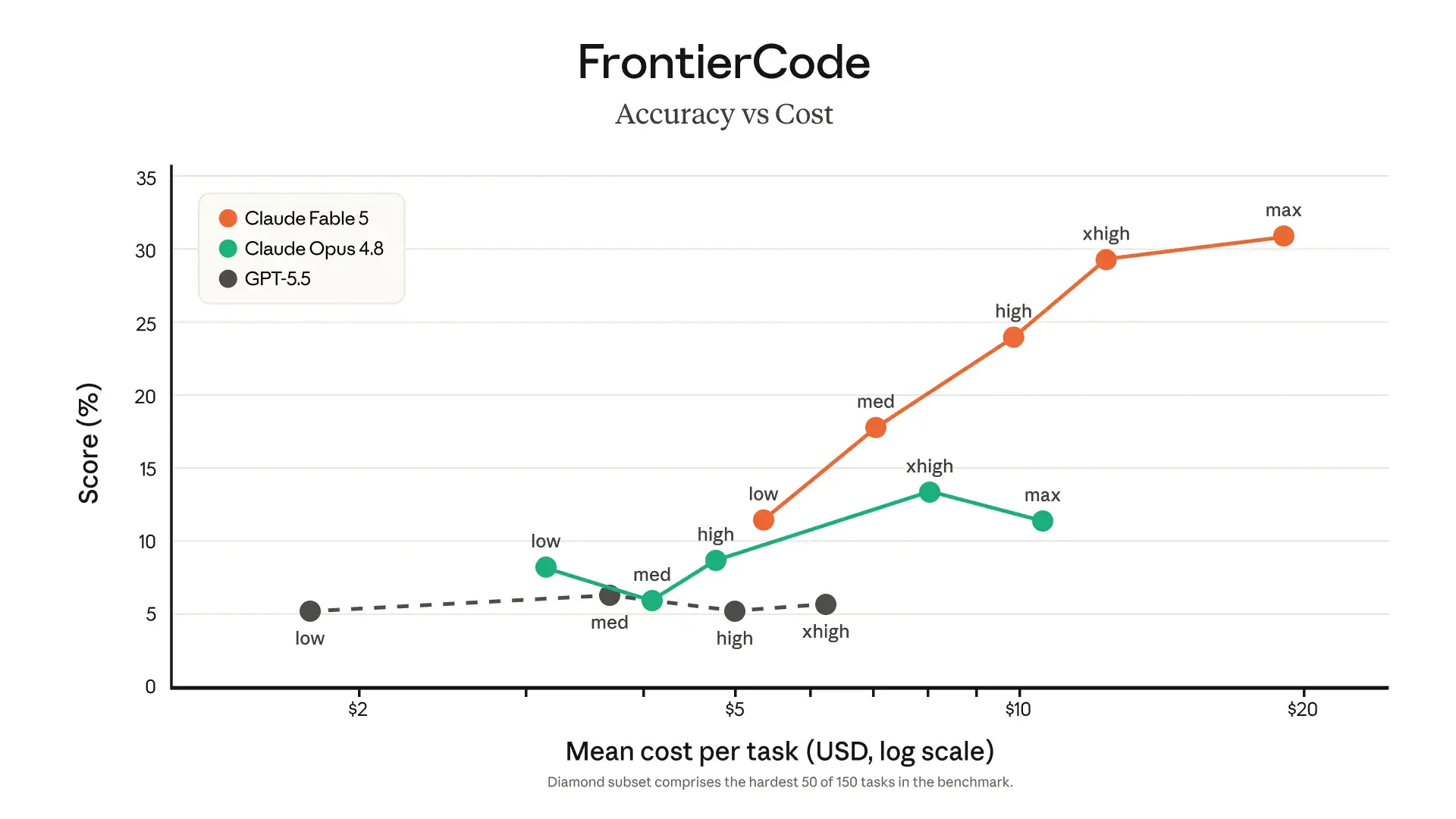
使用技巧
基础用法就是选模型、发指令,但真想榨干 Fable 5 的价值,有些技巧一般人不仔细挖根本不知道。
很多人不知道还有这些进阶用法:
-
给持久化记忆文件:Fable 5 对文件级记忆的利用效率远超 Opus。在项目开始时扔给它一个 MEMORY.md,让它自己维护更新,任务跑偏的概率大幅下降。官方测试里,这在《杀戮尖塔》场景中让性能提升了三倍。 -
拆分子Agent而不是自己全干:Fable 5 支持在 Claude Code 里委派子 Agent。一个大项目不要全丢给它一个人干,先让它写拆分计划,再逐个委派子 Agent 执行,最后让它 merge 结果。效率比单线程跑高出一大截。 -
让它自己写测试验证自己:这是 Fable 5 独有的能力。让它写完代码后自动生成测试用例、自动跑、自动修复失败的 case。以前这个闭环需要几个不同模型配合,现在一个模型就能全链路跑通。 -
用 Prompt 缓存省 Token:Fable 5 的输入 token 比 Opus 贵一倍,但 Prompt 缓存打一折。重复使用的系统提示词、项目文档,全部加缓存,实际开销能压到接近 Opus 的水平。
和同类比怎么样
数据上确实猛,但 AI 模型这个赛道现在卷到什么程度了?跟几个主要竞品放在一起比一比才能下判断。
当前顶级模型赛道基本是三家分晋:Anthropic 的 Fable 5、OpenAI 的 GPT-5.5、Google 的 Gemini 3.1 Pro。三者定位其实已经开始分化了:
| 对比维度 | Claude Fable 5 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|
| 核心定位 | 长时间Agent底座 | 通用对话+多模态 | 多模态+长上下文 |
| 输入价格 | $10/MTok | $5/MTok | $3.5/MTok |
| 输出价格 | $50/MTok | $30/MTok | $10.5/MTok |
| SWE-Bench Pro | 80.3% | 58.6% | 54.2% |
| 自主Agent | ✅ 多天连续 | ❌ 有限 | ❌ 有限 |
| 安全分流 | 有(回退Opus 4.8) | 无 | 无 |
Fable 5 的定位很清晰:它不是最便宜的,不是最全能的,但它是目前唯一一个能当真·长时间 Agent 底座用的模型。GPT-5.5 更像一个面面俱到的超级助手,什么都能干但深度有限。Gemini 3.1 Pro 靠低价和多模态打差异化,但在复杂推理和自主 Agent 上明显落后。
如果你买模型是用来聊天、写文案、做 PPT,Fable 5 多付的一倍价格可能不值。但如果你用它跑 Claude Code、做自主 Agent 开发、处理大规模代码库,这个溢价是有回报的,SWE-Bench 上 21.7 个百分点的领先太硬了。
真实用户怎么说
数据漂亮是一回事,真正用起来口碑怎么样?发布不到 24 小时,社区里的声音已经相当分化。
赞美的一方主要来自开发者和企业用户。Andrej Karpathy 第一时间上手后的评价是“跟去年 Claude 4.5 的升级属于同一级别,是一次真正的跃迁式进步”。Cursor 的 CEO Michael Truell 说 Fable 5 在 CursorBench 上是目前最强模型,“解锁了此前无法企及的长时间跨度问题”。Stripe 那位用 Fable 5 一天完成两个月代码迁移的工程师更直接,把这叫职业生涯中最震撼的 AI 体验。
但吐槽的声音同样不小,而且集中在同一个点:钱。大量 Pro 和 Max 订阅用户发现,Fable 5 的 Token 消耗速度远超预期。有人在社交媒体上算了一笔账:以前用 Opus 4.8 一个月随便跑,换成 Fable 5 后跑三个长任务额度就见底。6 月 23 日之后还要额外买 usage credits,普通用户的愤怒可以理解。
安全分流机制也引发了一些怨言。有用户反馈自己问了一个合法的代码审计问题,因为是安全相关领域,被自动切到了 Opus 4.8,虽然回答没问题,但多花了时间而且没法用 Fable 5 更强的推理能力。Anthropic 承认规则偏保守,说后续会逐步优化。
多维评分
评价有赞有踩,那从专业维度给它一个量化分数。
| 维度 | 星级 | 一句话解读 |
|---|---|---|
| 功能完整性 | ⭐⭐⭐⭐⭐ | 软件工程+知识工作+视觉+Agent,四维全能 |
| 易用性 | ⭐⭐⭐⭐☆ | API接入标准,但Token管理门槛高于竞品 |
| 性价比 | ⭐⭐⭐☆☆ | 能力翻倍但价格也翻倍,6月23日后更贵 |
| 创新性 | ⭐⭐⭐⭐⭐ | 首个公开Mythos级模型+安全分流架构 |
| 稳定性 | ⭐⭐⭐⭐☆ | 长任务持续性好,但分流误判偶尔影响体验 |
| 推荐度 | ⭐⭐⭐⭐☆ | 重度开发者和Agent用户必试,轻度用户观望 |
综合评分:8.4 / 10
优点和槽点
优势
-
Agent 时代真正的底座:市面上唯一能连续自主工作数天的大模型,不是一小时的 Demo 玩具 -
软件工程断层领先:SWE-bench 双料冠军,5000 万行代码一天迁移的真实案例没有人能复制 -
Token 效率提升:虽然单价贵,但完成任务所需的总 Token 数比 Opus 少,长任务 ROI 反而更高 -
安全架构有诚意:不是一刀切拒答,而是降级到安全模型处理,既不放任也不阉割
不足
-
6 月 23 日后定价模式剧变:从订阅制踢出去单独收费,对习惯了固定月费的用户是重大冲击 -
Token 消耗不可控:长任务场景下用量远超预期,Pro 套餐用户大概率不够用 -
安全分流误判:规则偏保守,部分合理请求被降级处理,影响体验 -
数据留存 30 天:对合规敏感的企业用户来说是硬伤,需要评估是否能接受
适合谁用
优点缺点都摆在这了,那这东西到底最适合谁?
-
重度 Claude Code 用户:如果你已经在用 Claude Code 做日常开发,Fable 5 是直接升级。代码质量、任务持久性、自主修复能力都有质的提升。唯一的顾虑是预算,如果你月费已经花到上限,先算算账再切。 -
AI Agent 开发者:Fable 5 是目前唯一能支撑真正多天自主 Agent 的公开模型。Cognition、Replit、Hex 这些公司已经在用它搞下一代产品了。如果你在开发 Agent 框架或工具链,这基本是必测底座。 -
处理大型代码库的团队:50 万行以上的代码库迁移、重构、多模块联调,Fable 5 的效率是 Opus 的几倍。团队规模越小,这种效率差越大,因为它真的能干人干的活,不只是辅助。 -
科研和高复杂度知识工作者:分子生物学假说、金融交易分析、多文档交叉推理,这些场景下 Fable 5 的能力是前代模型不可比的。Mythos 5 的蛋白设计案例是 10 倍加速,Fable 5 虽然被加了护栏,但在非受限领域同样强势。 -
轻度用户和预算敏感的开发者:如果你主要是聊天、写文案、做简单代码补全,Opus 4.8 甚至 Sonnet 就够用了。Fable 5 多付的一倍价格在你的场景里几乎体现不出来。等它重新纳入订阅或者价格下调再考虑。
多少钱
产品和用户需求对上了,来看看钱包受不受得了。
| 计费项 | 价格 | 对比 Opus 4.8 |
|---|---|---|
| 输入 Token | $10 / 百万 | 2x |
| 输出 Token | $50 / 百万 | 2x |
| Prompt 缓存 | 输入 1 折 | 相同优惠 |
| 美国境内推理 | 1.1x | — |
订阅用户的免费窗口:6 月 9 日到 6 月 22 日,Pro($20/月)、Max($200/月)、Team、按席位计费的企业版里直接包含 Fable 5。6 月 23 日起,Fable 5 从这些套餐中移除,继续使用需要消耗 usage credits,也就是按量付费。Anthropic 说如果容量允许会延长免费期,以后也想把 Fable 5 重新放进订阅套餐,但目前没有时间表。
坦白讲,定价策略是这次发布最大的争议点。能力确实炸裂,但先用免费窗口培养依赖再踢出去单独收费的路数容易让用户不爽。对于重度使用者,建议先算一笔账:你现在的月 Token 消耗量是多少,按 Fable 5 的价格翻一倍能不能接受。如果能,果断上;不能,Opus 4.8 依然是个不错的备胎。
常见问题
有些点看完评分和定价你可能还想细问,挑几个最常被提到的直接答。
Q1:Fable 5 和 Mythos 5 到底什么区别?
A1:同一底座,不同权限。 Fable 5 加了安全分类器,高风险领域触发后回退到 Opus 4.8;Mythos 5 在部分高风险领域解除了限制,仅限 Glasswing 合作方使用。
Q2:6 月 23 日后怎么继续用 Fable 5?
A2:需要消耗 usage credits,按 Token 量计费。 如果之前是 Pro/Max 订阅用户,价格从包月变按量,预算不好预估。建议在免费窗口内评估自己的用量再决定。
Q3:Fable 5 比 Opus 4.8 强多少?
A3:软件工程强约 15-20%,长任务强 2-3 倍。 但简单问答场景差异不大,复杂代码和 Agent 任务才能拉开差距。别为日常聊天多付一倍钱。
Q4:支持中文吗?
A4:支持,中文能力随基座模型提升而提升。 能用但不如英文自然——这基本是所有海外大模型的通病,Fable 5 也没跳出这个规律。
Q5:数据安全吗,会不会被拿去训练?
A5:30 天留存但不用于训练。 Anthropic 声明流量数据保留 30 天用于安全监控,不用于模型训练。但对合规要求严格的企业可能还是不够。
Q6:安全分流会影响正常使用吗?
A6:95% 的会话不受影响。 触发条件集中在网络安全、生物化学、模型蒸馏三类,普通编程和知识工作不涉及。偶尔有误判,Anthropic 说在优化。
Q7:Fable 5 能用 Claude Code 的所有功能吗?
A7:可以,而且表现远超 Opus。 多 Agent 委派、自我测试验证、多天连续运行这些高级功能在 Fable 5 上才真正可用。
Q8:和 GPT-5.5 比选哪个?
A8:做 Agent 和复杂开发选 Fable 5,通用场景选 GPT-5.5。 SWE-Bench 差距 21.7 个百分点不是小数字。但不做开发的话,GPT-5.5 更便宜且覆盖更广。
Q9:Pro 套餐用 Fable 5 够不够?
A9:大概率不够。 实测一个中等复杂度项目几小时就能耗尽 Pro 额度。重度用户建议直接上 Max 或者预购 usage credits。
Q10:Fable 5 以后会降价吗?
A10:短期不会,Anthropic 甚至说这是“低于 Mythos Preview 一半的价格”。 未来可能重新纳入订阅套餐,但降价空间不大——能力提升和价格提升是同步的。
所以到底值不值得
Claude Fable 5 不是一个面向所有人的产品,Anthropic 也没打算让它面向所有人。它是给那些真正需要“AI 替你干活而不是帮你干活”的人准备的,代码库大到需要团队级工时才能搞定、Agent 任务复杂到以前的模型跑一半就跑偏、知识工作深到需要模型自己查资料自己验证。
如果你是这类人,Fable 5 是目前市面上唯一的选择,没得选。多付的一倍价格换来的效率提升,在复杂场景下是值的。
但如果你只是用 AI 写写邮件、聊聊方案、做做代码补全,Fable 5 对你来说就是相同体验、双倍开销。6 月 23 日前趁免费窗口体验一下就够了,没必要着急掏钱。