
2026 年 4 月初,Andrej Karpathy 在社交平台上抛出一个想法:如果让 LLM 把自己的全部知识编译成一张可查询的图谱会怎样?他没写一行代码,只是描述了一个场景:你所有的笔记、文档、阅读记录被 LLM 消化后,变成一张你可以提问的地图。48 小时后,Graphify 出现了。
不是 Karpathy 本人写的。开源社区看到这个理念,两天交付了第一个可用版本。到今天,这个项目已经长到了 59.5k Stars,覆盖 33 种编程语言和 60 多种文件格式,能在 30 多个 AI 编程助手平台上运行。核心逻辑很简单:把你的代码库、文档、PDF、甚至视频全部抽成一个知识图谱,然后让 AI 编程助手直接查这张图,而不是在文件系统里盲目 grep。
但我翻完 Issue 区和几篇社区评测之后,发现一个问题。这个项目的 README 画了一张非常漂亮的饼,真正落地的时候有几块地方烤糊了。这篇文章想讲清楚一件事:Graphify 到底解决了什么,哪些场景它确实值这个 Star 数,哪些场景你可能高估了它。
为什么它跟其他代码索引工具不一样
Graphify 做的最聪明的一件事是没有把自己定位成代码分析器。它的输入范围大到离谱。
代码文件走 tree-sitter AST 解析,完全本地、零 API 调用,你的源码从头到尾不出机器。这一步是确定性的:同一个代码库跑两次,结果一模一样。但有意思的不是代码处理,是它把文档、PDF、图片、视频也塞进了同一张图谱里。PDF 里的架构图被 LLM 提取出”这是三层架构”,视频里的技术演讲被 faster-whisper 转成文本再提取概念,Office 文档里的需求描述和代码中的实现直接建立关联。
这不是传统意义上的代码索引工具。CodeGraph 和 GitNexus 的战场在纯代码领域,它们更快、更准、更省 Token。Graphify 的独特位置是多模态融合:当你的项目不只是代码,还包含几十份设计文档、产品规格、会议记录和架构图的时候,只有它能把这些东西串成一张图。
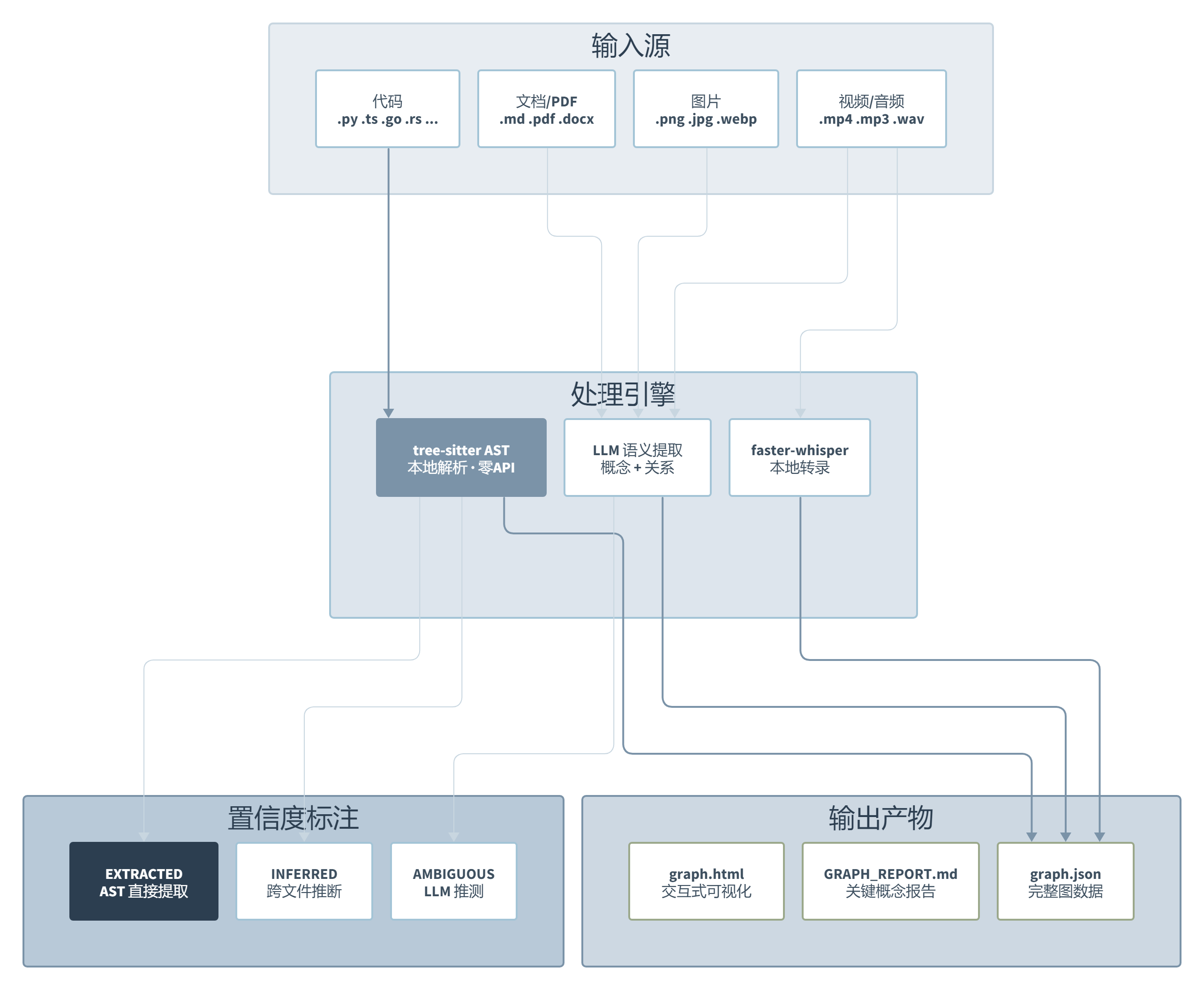
这张架构图的关键信息在中间那条分叉线:代码走本地 AST 解析(左侧,确定性、零成本),文档和多媒体走 LLM 语义提取(右侧,非确定、有成本)。这个设计决定了 Graphify 的准确度上限,代码相关的东西你可以信,LLM 推断的部分要打个折扣。后面会具体展开。
另一个让我意外的设计是置信度标注系统。每个节点关系被标记为 EXTRACTED、INFERRED 或 AMBIGUOUS。这不是花架子。当你查询”谁调用了这个函数”时,AST 直接提取的关系标 EXTRACTED,跨文件同名函数推断的标 INFERRED,LLM 从文档里猜出来的标 AMBIGUOUS。你不需要是图计算专家,看一眼标签就知道哪条边靠谱、哪条边只是”可能有关系”。
这种透明度在 AI 工具里不多见。大部分工具要么藏着掖着不告诉你它猜了多少,要么给你一个黑盒置信度分数让你自己悟。Graphify 的三级标注虽然粗糙,但足够诚实。诚实到你可以根据标注类型决定要不要信任这条关系,这在生产环境里比一个 0.87 的置信度分数有用得多。
除此之外,Leiden 社区检测算法是另一个被低估的设计。它能自动发现代码库中的聚类结构,哪些模块自然地聚在一起,哪些文件之间存在隐藏的耦合。配合 Mermaid 架构图导出,你可以直接拿到一张完整的调用流图,不需要手动画。
数据好看,但实际用起来什么感觉?
装起来不难,坑也摆在明面上
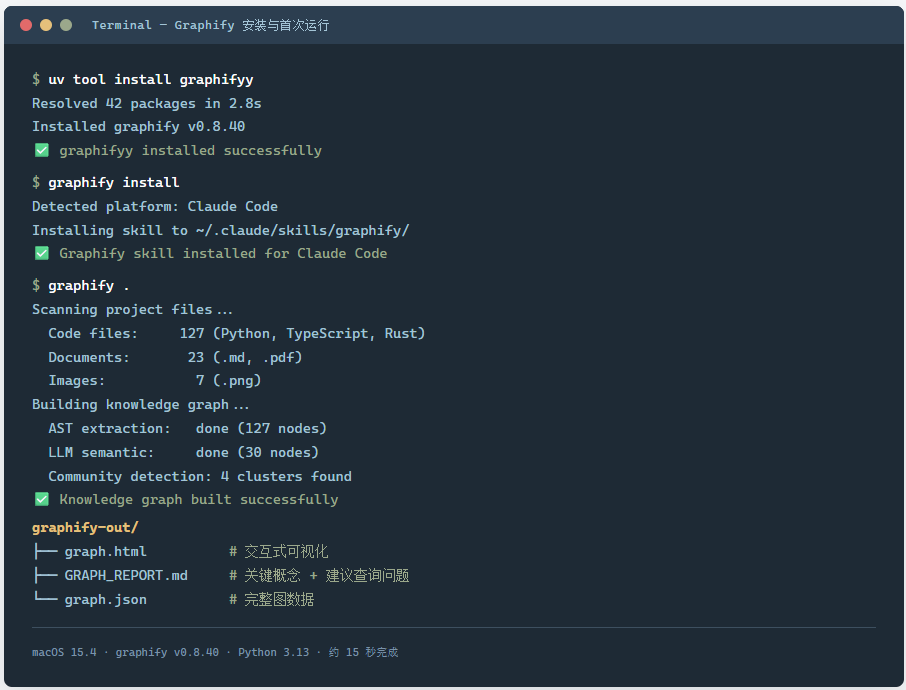
Graphify 的安装比 README 看起来多一个步骤,PyPI 包名这关必须先过。你装的是 graphifyy(双 y),但 CLI 命令叫 graphify。
uv tool install graphifyy
graphify install
需要 PDF 解析、视频转录或 MCP 服务器的,加对应的 extra:
uv tool install "graphifyy[pdf,video,mcp]"
装完之后,在项目根目录跑 /graphify .。Windows PowerShell 用户注意用 graphify .,因为 / 在 PowerShell 里是路径分隔符。等它跑完,graphify-out/ 下会出现三个文件:graph.html(交互式可视化)、GRAPH_REPORT.md(关键概念和推荐查询问题)、graph.json(完整图数据)。
看起来三步搞定。但 Issue 区暴露了三个常见的卡点。
- 第一个坑:PyPI 名字。
pip install graphify会装到一个完全不同的包,社区里不少人因为这个卡了半小时。记住双 y 就没事。 - 第二个坑:大项目的首次索引时间。中小型项目(几百个文件)秒级完成,但如果在一个几万文件的项目里跑,文档部分要走 LLM 语义提取,时间和 API 费用都会显著上升。建议先用
--no-viz跳过可视化生成,先看GRAPH_REPORT.md确认图谱质量,再决定要不要渲染交互式 HTML。 - 第三个坑:多语言混合项目。如果你同时有 Python、TypeScript 和 Rust 代码,它们之间的跨语言调用基本不会被正确解析。这不是 bug,是静态分析的天花板。Issue #572 跟踪了这个问题,但目前没有时间表。
装了感觉不错,但并不是所有项目都适合。
什么时候用,什么时候别用
Graphify 不是银弹。它的价值高度依赖你的项目特征。
| 场景 | 典型用户 | 优势 | 局限 |
|---|---|---|---|
| 中小型单语言项目 | 个人开发者、小团队 | 图谱准确度高,构建速度快 | 大项目性能衰减明显 |
| 文档密集型项目 | 技术写作、开源维护者 | 多模态融合,文档与代码天然关联 | LLM 推断有幻觉风险 |
| 快速上手陌生代码库 | 新入职、接盘侠 | 交互式可视化 + AI 问答,比 grep 直观 | 大型项目需 –no-viz 跳过渲染 |
| AI 编程助手上下文增强 | 高频 AI 编程用户 | 省去 Agent 逐文件搜索的 Token 消耗 | 超大图谱 JSON 加载有性能瓶颈 |
不适合的场景也很明确:
-
你需要精准的依赖分析做重构决策。Graphify 的静态解析加上 LLM 推断,在动态语言(Python 的 __import__、JS 的require)上准确度不够,基本靠猜。这种情况用 CodeGraph 或 GitNexus 更合适。 -
你在做 Monorepo 管理。Graphify 目前没有跨子项目的作用域隔离,同名函数会被错误合并。Issue #569 跟踪了这个问题,但修复日期未定。 -
你的项目超过 10 万行代码。社区反馈在超大仓库上有性能衰减,HTML 可视化超过 5000 节点会拒绝渲染。
不过文档密集型的项目里,Graphify 几乎没有替代品。CodeGraph 和 GitNexus 都是纯代码工具,Understand-Anything 的 LLM 管道倒是也处理文档,但它更偏可视化学习而非 AI Agent 检索。如果你手头有几十份产品规格、技术规范和会议记录要和代码一起被 AI 理解,Graphify 是目前唯一的选择。

这张对比图把 Graphify 和三个主要竞品的技术定位差异说清楚了。核心结论一句话:Graphify 在多模态输入和语言覆盖上遥遥领先,但在检索速度和 LLM 成本上落后于纯代码方案。选哪个取决于你的项目里代码和文档的比例。
不过选工具不能只看功能对比,维护者的状态也决定了你能不能长期依赖它。
社区的温度
Graphify 的社区数据确实亮眼,但 Bus Factor 是一个值得注意的信号。
| 指标 | 数据 | 说明 |
|---|---|---|
| Stars | 59.5k+ | 截至 2026 年 6 月,增长曲线陡峭 |
| Forks | 6.2k+ | 二次开发和定制化需求旺盛 |
| 核心维护者 | 1 人(safishamsi) | Bus Factor 偏高,但有 YC S26 商业支撑 |
| Open Issues | 90+ | 活跃度高,含多个 P0 级准确度问题 |
| 协议 | MIT | 完全开源可商用,v3 起从非商业许可切换 |
| 提交活跃度 | 757 commits (v8) | 最近 24 小时内有新提交,迭代速度极快 |
维护者 Safi Shamsi 一个人的 Bus Factor 确实让人捏把汗,但背后有 graphifylabs.ai 商业实体和 YC S26 的加持,短期内存续风险不高。更大的问题是 Issue 区的质量分布:90 多个 open issues 里有不少是结构性问题。短名函数冲突(#895 的 init/run/get 神节点膨胀)、跨语言查询上下文缺失(#572)、Monorepo 作用域隔离缺失(#569),这三个问题如果不解决,Graphify 在企业级场景的上限就被锁死了。
来自知乎的一篇社区评测直接给出了一个我基本认同的判断:理念不错、社区火但产品有硬伤。这个评价不算苛刻。59.5k Stars 里有相当比例是”这个 idea 太酷了”的情绪投票,不是”我在生产环境用过了”的质量投票。但积极的一面是,社区修复速度确实不慢。Issue #895 的 dedup.py 修复、#791 的 post-commit hook 内存泄漏修复都是几天内合并的。这个响应速度在单维护者项目里算顶尖了。
社区的数据只是外部信号。真正决定这个项目能不能长期用的,是它的技术底子到底有多扎实。
说实话,我的判断有点复杂
花了半天翻完 Graphify 的代码结构、Issue 列表和社区评测之后,我的判断比开始时复杂了很多。
一开始我被 59.5k Stars 和”48 小时交付”的故事吸引了。这种从理念到产品的速度在开源社区极其罕见,上一次有这种势能的项目大概还是 llama.cpp。但深入之后,我意识到 Graphify 吃掉了一个很大的饼,嚼得还不够细。多模态融合这个概念很美,但执行上存在系统性的准确度缺陷,不是多加几个 tree-sitter 语法或者调优几个 prompt 能解决的。
Graphify 目前的真实定位不是”AI 编程的生产力引擎”,而是”项目知识库的快速索引层”。如果你把它当成一个帮你快速理解陌生代码库的工具,它做得不错。如果你指望它替代 CodeGraph 做毫秒级的符号检索,或者指望它做精准的跨文件依赖分析,你会发现自己高估了它。
一个有意思的趋势是,Graphify 的路线图上有一个关联项目叫 Penpax,定位是”始终在线的数字孪生”,覆盖会议、浏览器、邮件等全工作场景。这说明 Safi 的野心远不止代码图谱,他想要的是个人知识管理的基础设施。如果这条路能走通,Graphify 的价值将远超现在的代码分析工具。但那是未来,不是现在。
另外一个更现实的判断:如果你的主要痛点是”AI Agent 在代码库里翻文件太慢了”,Graphify 不是唯一解,甚至不是最优解。CodeGraph 在纯代码检索上更快更准,GitNexus 在影响分析上更深。Graphify 的不可替代性只存在于一个场景:你需要把代码和非代码内容融合成一张图的时候。这个场景在今天的 AI 编程工作流里还不是主流需求,但随着多模态模型的成熟,它会越来越重要。
资源地址
| 资源 | 地址 |
|---|---|
| GitHub | https://github.com/safishamsi/graphify |
| 官方网站 | https://graphifylabs.ai |
| PyPI | https://pypi.org/project/graphifyy/ |
聊完了,该干嘛
如果你手头有一个几百到几千文件的中型项目,代码和文档混在一起,想给 AI 编程助手装个”地图”,直接装。一条 uv tool install graphifyy 就能跑起来,MIT 协议没任何商业限制。
如果你在做大型 Monorepo 或者需要精准依赖分析,先别冲动。跟踪 Issue #569 和 #572 的进展,等作用域隔离和跨语言查询稳定了再做决定。现在这个阶段,Graphify 在这些场景下的表现还不到”能用”的标准。
但如果你想的是一个更大的问题:你的个人知识、项目记录、设计文档、会议笔记能不能被组织成一张 AI 能查询的图。Graphify 是目前开源生态里离这个目标最近的答案。它还不够完美,但方向是对的。