

如果你用过 cc-switch,你对”换后端”这件事应该不陌生。cc-switch 干的事很专一:把 Claude Code 的流量转发到 OpenRouter 或 DeepSeek,轻量、够用。同类项目里,DeepClaude 走协议桥接路线,Cline 和 Aider 各自是独立的 Agent 体系。
free-claude-code 的位置跟它们都不一样。你不需要换 Agent,不需要学新的快捷键,不需要接受另一种交互模式。它只是在 Claude Code 和 Anthropic 的 API 之间插了一个代理层,然后让你自己决定代理的另一端接的是什么——可以是 NVIDIA NIM 的免费额度,可以是 DeepSeek 的低价 API,可以是本地 Ollama 跑的 7B 小模型,也可以三者混合调度。
换个说法:cc-switch 是单通道分线器,DeepClaude 是协议翻译器,free-claude-code 是带管理界面的智能路由器。三种东西在解决同一个痛点的不同深度,但方案的半径差了一个数量级。17 个提供商后端、Anthropic Messages API 和 OpenAI Responses API 双协议、按 Opus/Sonnet/Haiku 三档分层路由——这些不是噱头,是当你真正把 AI 编码工具当生产力依赖时才会开始在意的东西。
说白了,这篇文章想讲明白一件事:当”免费 Claude Code”在 HackerNews 和知乎上吵了几百楼之后,真正值得关注的不是能不能白嫖,而是开源社区把 AI 编码工具从厂商绑定里解耦出来的技术路径,现在走到哪一步了。
为什么让我多看了两眼
先讲最硬的数据。17 个提供商按三个维度分类:NVIDIA NIM 走免费额度,每分钟 40 次请求,注册不需要绑信用卡;OpenRouter 聚合几百个模型,其中一批打了 :free 标签;DeepSeek 和 Kimi 走国内性价比路线,价格比 Anthropic 低一个数量级;Ollama、LM Studio、llama.cpp 走本地零成本,前提是本机显卡扛得住。这个覆盖面意味着你可以从纯免费一路搭到企业级推理,路径不中断。
但让我真正停下来细看的不是数量,是分层路由这个设计。Claude Code 内部把不同复杂度的任务映射到不同模型档位:Opus 档处理重推理,Sonnet 档管日常编码,Haiku 档做轻量补全。free-claude-code 让每档各自指向不同的后端。.env 里写 MODEL_OPUS=nvidia_nim/moonshotai/kimi-k2.5 处理复杂任务,MODEL_HAIKU=lmstudio/unsloth/GLM-4.7-Flash-GGUF 本地跑轻量补全。这种精细化的成本调度,在同类项目里是独一份。
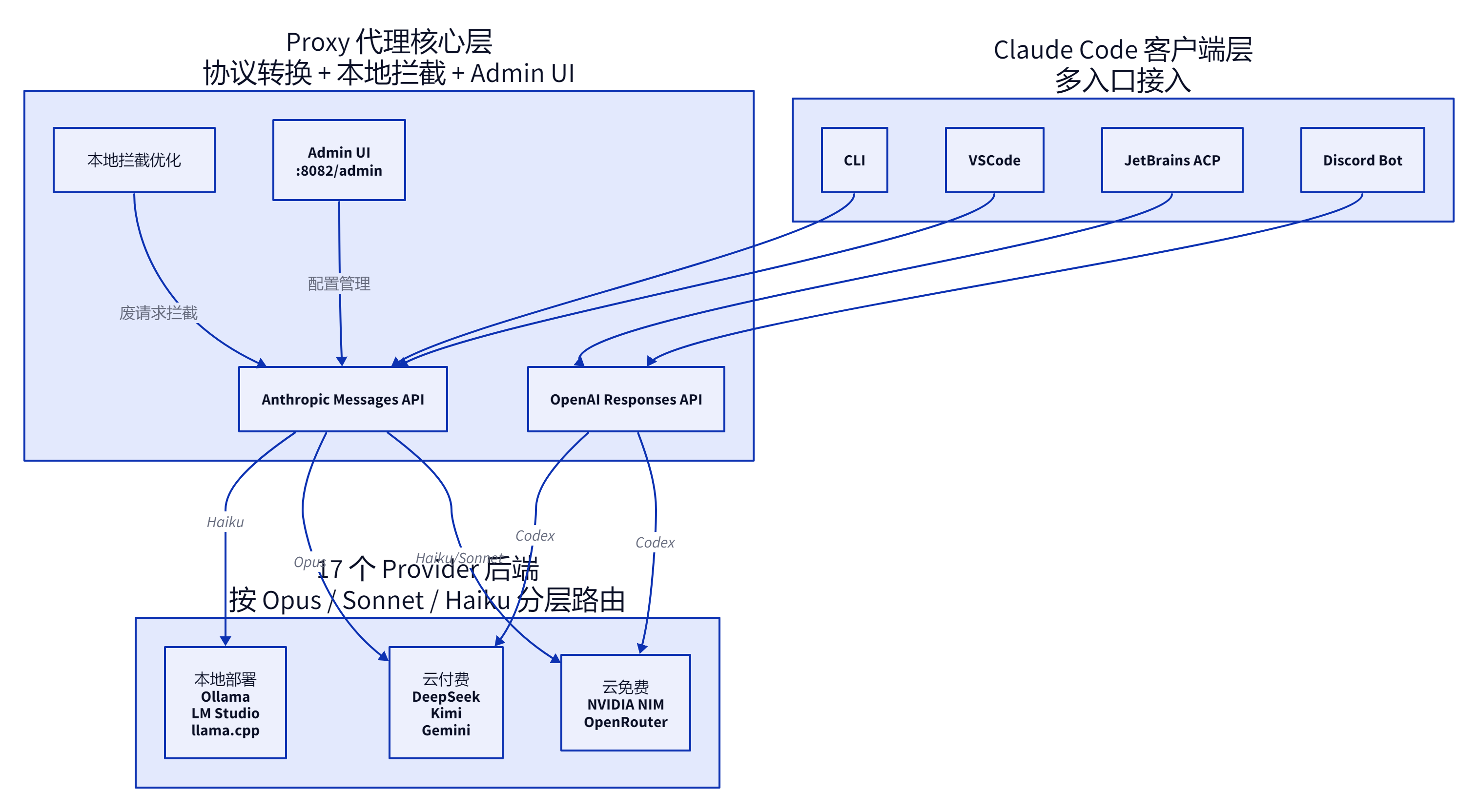
这个代理的三层结构其实很干净。最上层是 Claude Code 的多个入口,CLI、VSCode 扩展、JetBrains ACP、Discord 机器人,一个不少。中间是代理核心,负责 Anthropic Messages API 和 OpenAI Responses API 的双协议转换,本地拦截筛选掉探测网络、生成标题这类废请求。最下层是 17 个提供商,按云免费、云付费、本地三类分组,Opus/Sonnet/Haiku 各自路由到不同后端。整个架构的设计思路是”解耦但不重建”。
另一件事是 Admin UI。大多数同类代理工具把配置塞在环境变量或 YAML 文件里,改个 API key 要开编辑器、重启服务。free-claude-code 在 http://127.0.0.1:8082/admin 提供了一个本地 Web 界面,可视化配后端、选模型、看请求日志。开源代理类项目里有 UI 的屈指可数——这个细节让它跟同类拉开了明显的体验代差。
还有一个容易被跳过的亮点:本地拦截优化。Claude Code 跑起来会产生大量”废请求”,探测网络可达性、自动生成对话标题、检测文件路径,这些请求根本不需要过 API。代理直接拦在本地响应,省了调用次数和延迟。这不是那种写在 README 第一行的 headline feature,但它直接影响你用 NVIDIA NIM 免费额度时的实际体验,40 次每分钟的限额里有效请求占比能高出一截。
技术栈选了 Python 3.14 加 FastAPI 加 ASGI,用 uv 做包管理。代码结构是典型的 FastAPI 项目布局:server.py 是 ASGI 入口,providers/ 管各后端适配,messaging/ 管 Discord 和 Telegram,core/ 负责协议转换。扩展一个新后端只需继承 BaseProvider 或 OpenAIChatTransport,在 provider registry 注册就行。这个架构的直接好处是,即使 Anthropic 明天改了 API 格式,改动范围被锁在 core/ 目录内。
跑起来试试
推荐用 uv tool install 安装,不用克隆仓库:
uv tool install git+https://github.com/Alishahryar1/free-claude-code.git
fcc-init
free-claude-code
fcc-init 会自动在 ~/.config/free-claude-code/.env 生成配置文件,省了手动 cp .env.example .env 这一步。另一种方式是克隆仓库手动跑,适合想改源码或自己加 provider 的开发场景。
安装环境有个硬门槛:Python 3.14。不是因为作者任性,是项目代码用到了 3.14 正式版的 except X, Y 语法。3.13 用户需要先执行 uv python install 3.14 装好解释器。这算是当前入门最大的摩擦点,毕竟 3.14 才出几个月,大部分开发者的默认环境还在 3.12 附近。
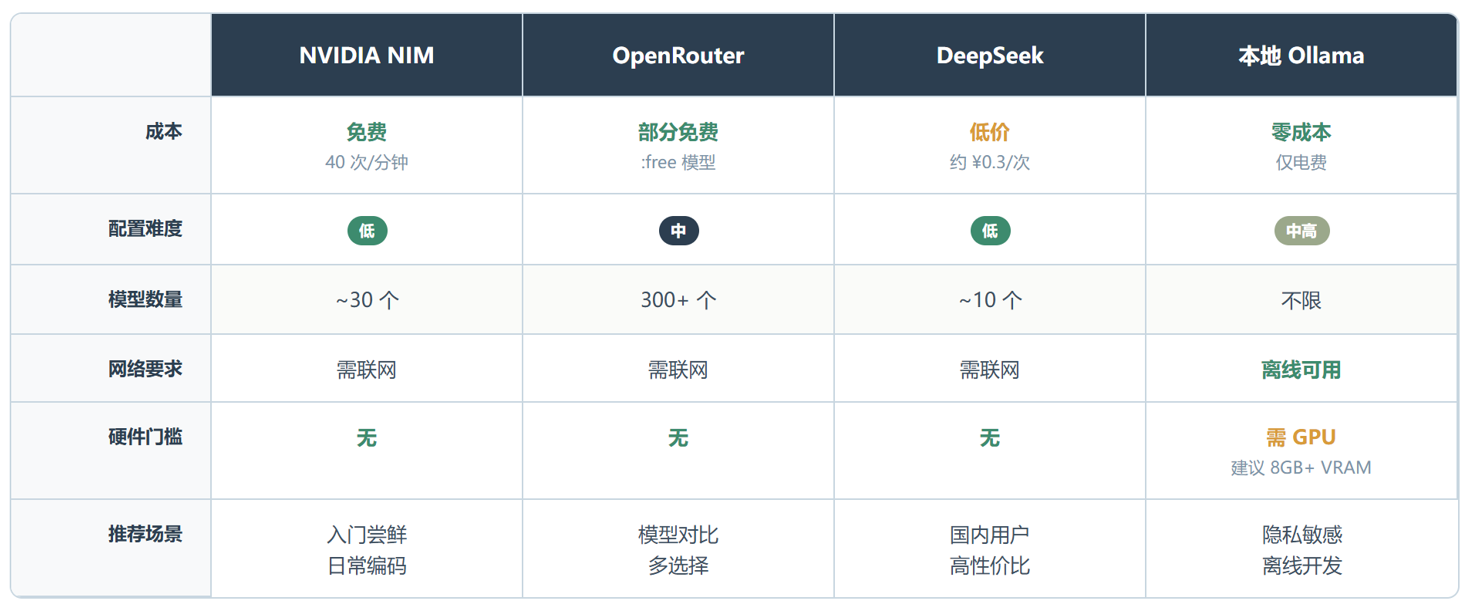
四种方案在成本、配置难度和适用场景上的差异很明显。NVIDIA NIM 成本为零但速率受限,OpenRouter 选择最多但免费模型质量参差不齐,DeepSeek 性价比高但要付费,本地 Ollama 方案完全离线但吃显卡。我的建议是从 NVIDIA NIM 入手跑通链路,再按自己的场景选最合适的组合配置。
配置后端很简单。以 NVIDIA NIM 为例,去 build.nvidia.com 注册拿 key,在 .env 里填两行:
NVIDIA_NIM_API_KEY="nvapi-你的key"
MODEL="nvidia_nim/z-ai/glm4.7"
启动代理后开两个终端,一个跑服务一个跑 Claude Code:
# 终端 1:启代理
uv run uvicorn server:app --host 0.0.0.0 --port 8082
# 终端 2:跑 Claude Code
ANTHROPIC_BASE_URL="http://localhost:8082" claude
VSCode 扩展的话,Settings 搜 claude-code.environmentVariables 加两行环境变量就行。整个过程中不需要改 Claude Code 的任何一行代码。
常见卡点有两个。一是 NVIDIA NIM 的 40 次每分钟速率限制,密集编码时偶尔撞墙,本地拦截优化能部分缓解但没法根治。二是 OpenRouter 上 :free 标签的模型质量方差极大,deepseek-r1-0528:free 在中小型项目里表现尚可,gpt-oss-120b:free 在大型代码库里的输出可能会让你想砸键盘。这两个坑在 Issue 区都能找到相关讨论。
什么时候用,什么时候别用
| 场景 | 典型用户 | 优势 | 局限 |
|---|---|---|---|
| 日常编码加小项目 | 个人开发者、学生 | NVIDIA NIM 免费额度,零成本上手 | 复杂跨文件重构能力有差距 |
| 本地离线环境 | 安全敏感企业、内网 | 数据不出本机,可接入 Ollama | 需要中高配显卡 |
| 多模型混合调度 | 深度用户、架构师 | 按任务档位分后端,成本精细控制 | 配置复杂度上升 |
| 开源尝鲜和探索 | 开源维护者、技术受众 | CLI/VSCode/JetBrains 全平台 | 模型能力与原版 Claude 有明显差距 |
不适用的情况同样明确。做严肃的生产级项目,尤其在大型代码库上搞跨文件深度重构的时候,原版 Claude 的模型能力和稳定性优势不是代理能弥补的,差距在模型本身。如果只有集成显卡加 8GB 内存,本地模型方案基本不可用,依赖云端后端又受速率限制。还有一类就是想要开箱即用零配置的用户,Python 3.14 环境、Anthropic API 请求模型的理解、至少一个 provider 的 API key 配置,每一步都有学习成本。
和同类项目的选型逻辑也值得说清楚。cc-switch 更轻量、接入成本更低,但只支持有限几个后端。DeepClaude 在协议转换上更专注,适合已有 DeepSeek API key 的用户。Aider 和 Cline 是完整的 Agent 体系,不完全是替代关系,它们自带一套交互模式。free-claude-code 保留了 Claude Code 原生的交互体验,只在模型层做了替换。选哪个取决于你是想换工具本身,还是只想换模型。
社区怎么样了
| 指标 | 数据 | 说明 |
|---|---|---|
| Stars | 约 21,000(2026 年 6 月) | 12 个月内从 0 到 21k |
| 核心维护者 | 1 人 | Bus Factor = 1,最大风险点 |
| 贡献者 | 23 人 | 活跃但集中在周边而非核心 |
| Open Issues | 84 | 中高水平,需关注 |
| 协议 | MIT | 商业友好 |
Stars 的增长曲线有点意思。2025 年 10 月破千,12 月破五千,2026 年 3 月破万,6 月到两万一。这个增速在 AI 开源项目里属于第一梯队,很大一部分动力来自 Claude Code 源代码泄露事件引发的关注潮。增长快当然是好事,但社区里有大量围观群众而非深度用户,从 Issue 讨论的质量能看出来,高价值的技术讨论不多,大部分是配置求助帖。
Bus Factor 等于 1 是绕不开的隐患。Alishahryar1 一个人的代码贡献占了绝大多数,提交频率高但节奏完全依赖个人。23 个贡献者里主要在搞小修小补和文档完善,核心代码的决定权高度集中。这不是说项目一定会死,但如果作者因为任何原因停更三个月,大概率进入实质停滞。和 cc-switch 比,free-claude-code 的代码量大得多、架构更复杂、单人维护的压力也更大。
知乎上一篇分析写得挺准:”坦率的讲,这个项目不是让你完全替代付费版 Claude Code 的方案。真要做严肃的生产项目,原版 Claude 的稳定性和模型能力还是有优势的。”这也是社区的主流共识,这是一个扩容方案,不是替代方案。搞清楚这一点才能正确地用它,而不是期望它做到超出设计边界的事情。
在 Reddit 和 HackerNews 的相关讨论里,开发者的关注点逐渐从”能不能用”转向了”怎么用好”。有人用 NVIDIA NIM 跑日常编码,效果接近原版 Claude 的八成;有人用 DeepSeek 做代码补全,发现 Sonnet 级别的任务质量波动较大。这些分散的反馈拼在一起,恰好验证了一个判断:体验的上限不是代理本身决定的,是后端模型决定的。
值不值得跟
在 Issue 区和 commit 历史里泡了一阵后,最大的感受是:这个项目解决的问题,比它看起来要重要得多。
表面上是”让 Claude Code 变免费”。实际上是在做一件事:把 AI 编码工具的客户端和后端解耦。Claude Code 是好产品,交互界面流畅、工具集成可靠、Agent 工作流成熟。但它的商业模式把这三样东西和 Anthropic 的推理服务强行绑定。free-claude-code 证明了 Claude Code 的交互层和工具层是可以独立于模型层的价值,你可以保留前者,替换后者。这件事的意义超越了”省几百块钱月费”,它是一个架构示范。
但社区健康度的 Maintenance 维度拿了零分这件事不能视而不见。84 个 open issue,没有正式 GitHub Release,接近一千天无版本发布。客观地说这有点冤枉,项目用的是 uv tool install 分发方式,GitHub Release 不是它的标准流程。但一个有 21k Stars 的项目缺乏结构化的版本管理和 changelog,对想用在生产或团队环境的人来说,依然是个没法绕过去的问题。你没法确定哪个 commit 是稳定版,每次 uv tool upgrade 都是盲升。
趋势判断上,Stars 增速已经从峰值回落,上个月周增五千多,这个月大概率降一半。但 PR 合并速度仍然稳定,6 月中旬三天合了五个 PR。这说明社区热度在退潮,核心维护质量没有下降。比较理想的状态是半年内核心维护者从一人扩展到两三人,否则 84 个 open issue 会逐渐从临时摩擦变成长期技术债。
有一个反直觉的观察:free-claude-code 最有价值的输出可能不是代码本身,而是它公开验证了一个假设——Anthropic Messages API 是可以通过三方代理自由路由的。如果 Anthropic 未来开放官方的自定义后端接口,这个项目就是那个推了一把的力量。即使它最终被官方方案替代,它 21k Stars 的过程已经是一个足够清晰的信号:开发者社区用脚投票,选择了后端自由。
资源地址
| 资源 | 地址 |
|---|---|
| GitHub | https://github.com/Alishahryar1/free-claude-code |
| NVIDIA NIM | https://build.nvidia.com |
| OpenRouter | https://openrouter.ai |
说到最后
如果你每个月在 Claude Code 上花超过两百块,或者你手里有一块能跑 7B 加模型的显卡,这件事值得你花一个下午试试。从 NVIDIA NIM 免费额度入手,零成本跑通整个链路,再决定要不要深配分层路由。如果只是想尝鲜,装好 uv、跑一句 uv tool install、填两行 .env,十分钟内你就能在 Claude Code 的界面上用 Kimi K2 或者 DeepSeek。

整个上手路径其实就三步:安装 uv 工具链,配置一个免费或低价的模型后端,启动代理服务然后正常用 Claude Code。每步的复杂度都不高,但加起来需要你对终端操作和 API 配置有一定的熟悉度。
如果你在做生产环境的技术选型,关注两个指标:核心维护者数量有没有从一人增加到两人以上,以及 GitHub Release 或稳定的版本标记机制是否出现。这两点决定了这个项目能不能从聪明的个人工具变成靠谱的团队依赖。
“免费 Claude Code”这个词再往后半年可能就不新鲜了。真正留下来的,是把客户端和后端解耦掉的思路。你用的工具界面不变,你选的模型后台可变。这件事一旦成为共识,改变的不是一个项目的命运,是整个 AI 编码工具的分发方式。而 free-claude-code,大概率会是那个被发现用来写了第一页历史的地方。