

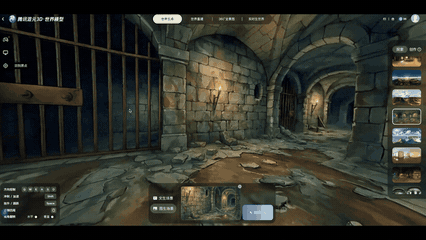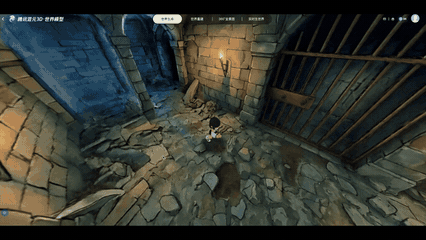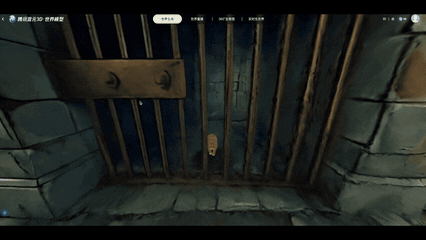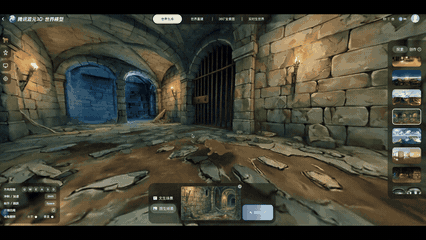
实机演示:输入“生成一个日式RPG风格的中世纪地牢”,即可生成一个3D空间资产
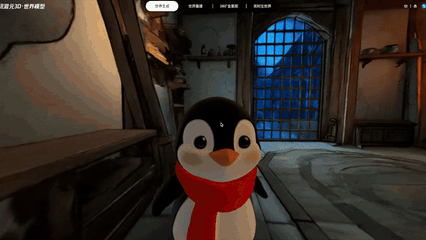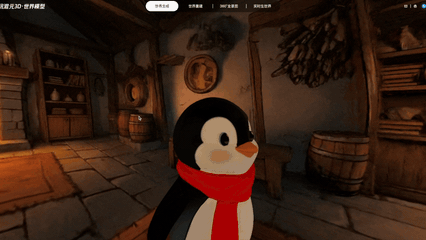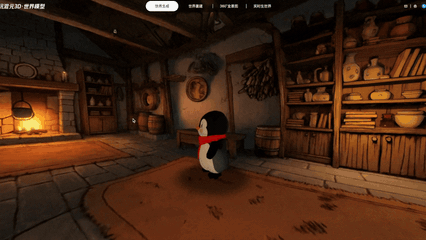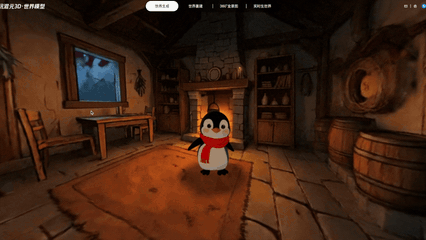
实机演示:输入“生成一个温馨的绘本风格小木屋”,游戏角色可以自由穿行在生成的3D场景中
上图所有内容均为3D文件,且全部由HY-World 2.0 AI大模型一键生成
支持多种模态输入,草图变地图、图片变空间
混元世界模型2.0支持文、图、视频多种输入。
输入一段文字或一张图片,模型即可精准解析复杂语义,一键生成风格多样的可漫游世界。相比较混元世界模型1.0,2.0的模型架构全面升级,画面精细度和真实感大幅提升。用户还可以自定义风格,按需生成真实风、漫画风、游戏风的3D空间。生成完成后,用户可以将资产导入到Unity、UE 等引擎、进行二次编辑,显著降低了游戏地图的创作门槛。


模型还支持角色模式,用户可以操作角色在街道、建筑、场景中自由探索,不限时间,具有物理碰撞,就像在游戏里一样。


以上图片内容均为3D文件,且全部由HY-World 2.0 AI大模型一键生成
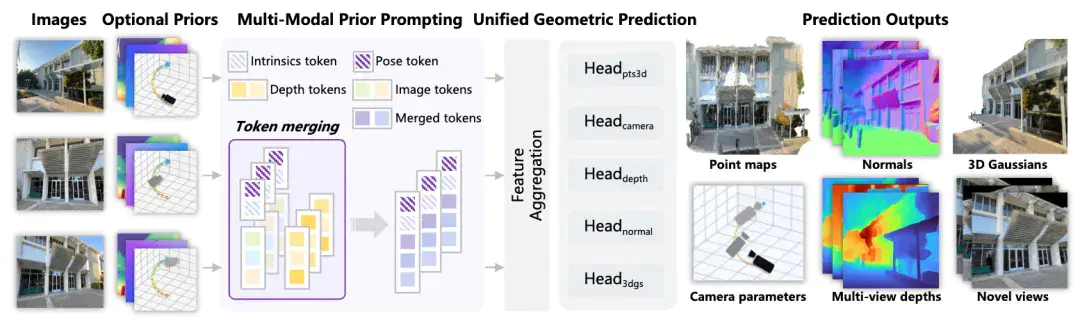
同时,世界模型2.0支持复刻真实3D场景,用户输入一段真实空间的视频或者多视角图片,模型就能构建出高精度的数字孪生空间。基于升级后的 WorldMirror 2.0 架构,模型支持任意尺寸图像与视频输入,一次性预测密集点云、多视角深度图、表面法线及相机参数 ,一次生成永久可复用。未来,室内装修预览、城市规划、文化遗产保护等场景,都可以基于这一能力实现快速构建和还原。

与其他世界模型相比,混元世界模型2.0在场景完整度(物体侧面和背面)以及对输入图片的遵循程度表现更优。混元生成的3DGS与Mesh的混合表征,也让用户能够开启角色模式进行有真实物体碰撞的交互。

以3D生成为主轴,统一空间理解、生成、重建
混元世界模型2.0以3D为主轴,通过统一空间理解、生成、重建的架构,实现了SOTA级的生成效果。
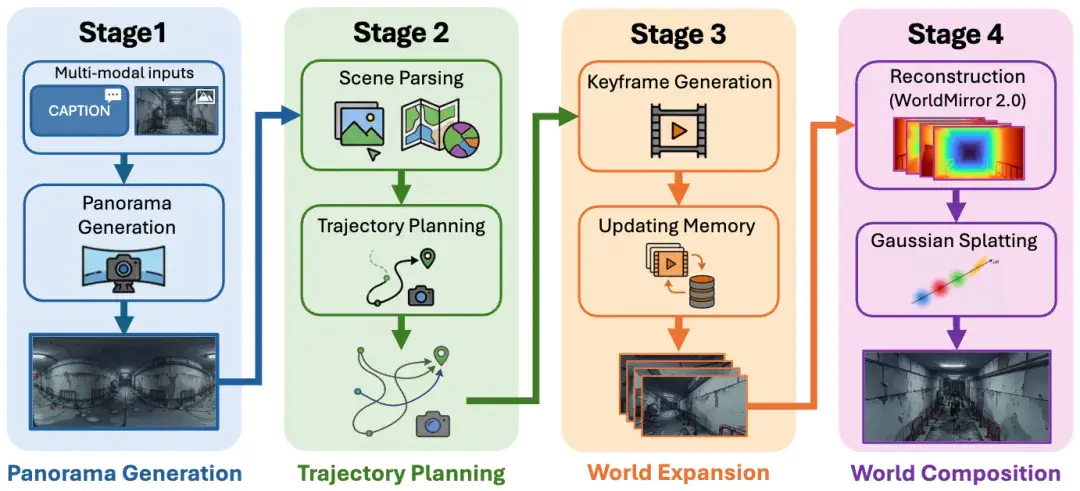
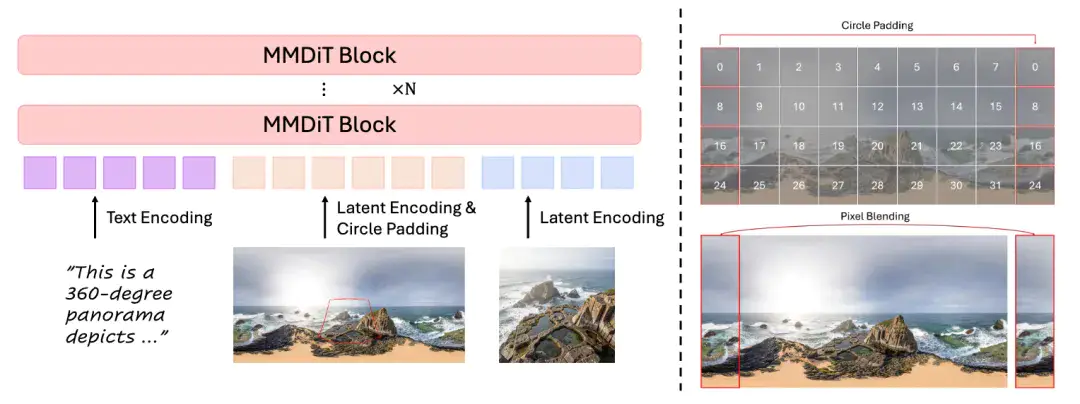
传统方法需要精确的相机参数才能生成全景图,但现实中这些参数往往拿不到。
HY-World 2.0 全新升级HY-Pano-2.0模型, 采用端到端隐式学习方案,让模型自己学会从普通图片到 360 度全景的空间映射,完全不需要任何相机元数。再配合团队的真实全景照片和 UE 引擎合成数据的混合训练策略,保证了生成质量和泛化能力。
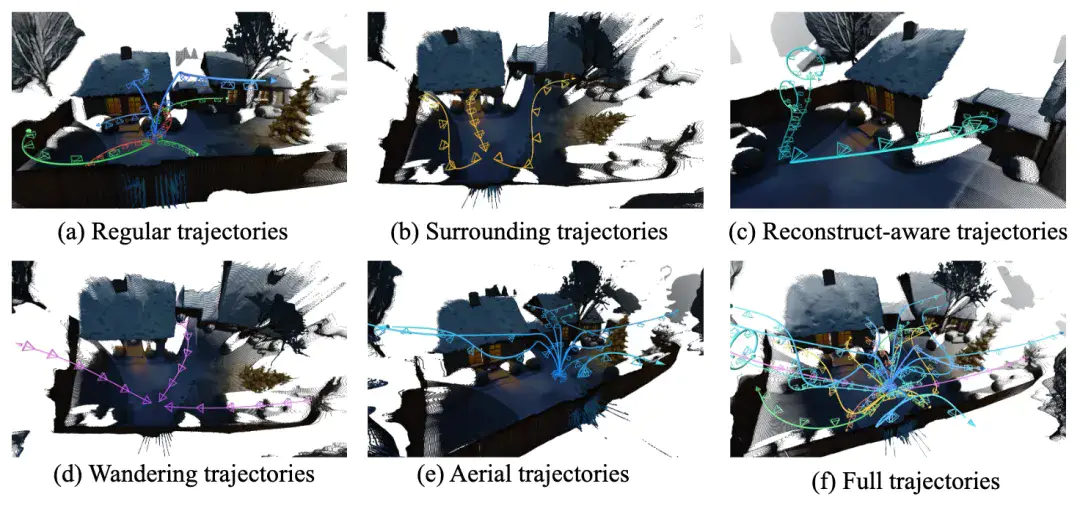
有了全景图,下一步是规划“怎么走”。
通过团队自研的空间Agent技术,结合VLM与游戏自动寻路算法常用的navmesh表征,让大模型能够理解空间语义,并智能规划出有意义的漫游轨迹,确保覆盖场景中最有价值的区域,同时避免穿墙、跑飞。模型会根据每个场景的不同语义,规划出“环绕物体”、“最大漫游”等五类运镜轨迹,这样搭配下一步的世界扩展模型,可以让用户在 3D 世界中的探索路径既自然又有趣。
沿着规划好的轨迹,模型通过视频生成技术不断“扩展”世界。
这一步的关键创新在于“精确的相机控制 + 细粒度视觉细节保持 + 空间一致性记忆机制”,这一套流程可以确保新生成的区域与已有区域在几何和视觉上完美衔接,不会“穿帮”。通过记忆力机制的设计以及体系化的中间训练和后训练,团队打造了目前业界最强的新视角生成(NVS)模型HY-WorldStereo。生成画面对输入相机的精准跟随,且多条运镜的生成结果保持空间一致不会有冲突;通过后训练算法的设计,使得保持快速生成的同时画面质量不会衰减。

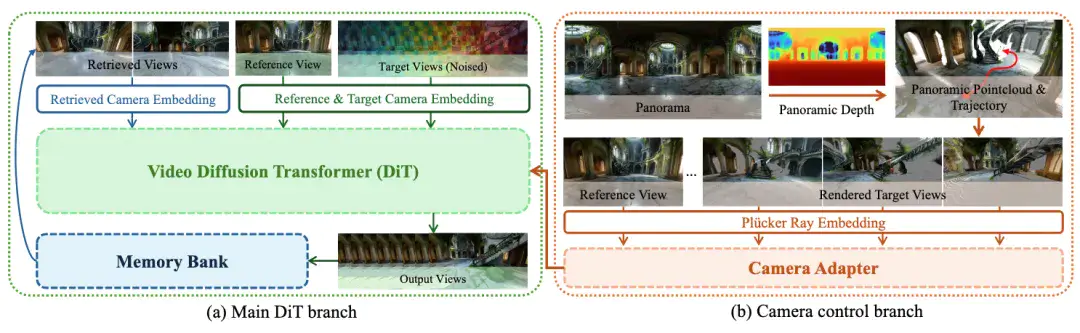
最后,将所有生成的片段通过HY-WorldMirror 2.0 整合为一个统一的、可交互的 3D 世界。使用定制的Depth alignment和自适应Mask gaussian场景优化算法,生成的场景采用 3D 高斯泼溅(3DGS)表示,同时可以转出高质量mesh,可以无缝导出到 Unity/UE 等主流游戏引擎,支持二次编辑和创作。
混元世界模型(HY-World 系列)自发布以来就在持续进化:从首个开源的3D世界模型 HY-World 1.0 ,到可实时在线交互的 HY-World 1.5 ,再到一键生成高质量完整3D空间资产的 HY-World 2.0,腾讯混元的3D世界模型正在一步步将“AI造世界”从概念变为现实。

-
申请体验:https://3d.hunyuan.tencent.com/sceneTo3D -
开源代码:https://github.com/Tencent-Hunyuan/HY-World-2.0 -
技术报告:
https://3d-models.hunyuan.tencent.com/world/world2_0/HY_World_2_0.pdf -
本文转载自@腾讯开源公众号,原文链接如下 -
https://mp.weixin.qq.com/s/T08aCUwiJo6u-aPjFdR0qA