
让 AI 自己操作浏览器,这事听起来很酷。但真正做过的人都知道,坑比想象中多得多。CSS 选择器在动态页面里一碰就碎,等页面加载的时间比执行任务本身还长,一个登录状态丢了就得从头再来。
Agent Browser 是 Vercel Labs 专为 AI Agent 设计的无头浏览器 CLI 工具,在 ClawHub 上以 Skill 形式发布,方便集成进 OpenClaw 工作流。它的核心思路很直接:别再让 AI 去猜 CSS 选择器和 XPath 了,给它一套确定的、像门牌号一样的元素引用系统。
116K 的下载量,GitHub 上 27K+ star 的原生项目——这不是一个小众实验。从社区的反馈来看,Agent Browser 确实踩中了浏览器自动化在 AI 时代的一个关键痛点。
说真的,这篇文章不是要给你读一篇官方文档。我会从它的核心技术机制拆起,讲清楚 Ref 引用系统为什么比传统选择器更适合 AI,顺带聊一下架构里那些让人意外的设计取舍。读完你应该能判断这东西适不适合你自己的场景,而不是被下载量数字带着走。
环境准备
Agent Browser 的安装路径有两条。如果你已经用上了 OpenClaw,直接在终端跑一行 openclaw skills install agent-browser-clawdbot 就够了,ClawHub 会自动处理依赖和版本匹配。这条路径适合已经在 OpenClaw 生态里的人,门槛几乎为零。
没有 OpenClaw 的话也不麻烦。Agent Browser 底层是 Vercel Labs 的开源 CLI 工具,一行 npm 全局安装就能搞定,然后执行 agent-browser install 下载 Chromium 浏览器内核。整个过程大概三分钟,前提是你网络没问题。
需要注意的是 Linux 环境。如果你在服务器上用,安装时记得加 --with-deps 参数,它会自动补全系统依赖库。很多人在这一步卡住,报一串看不懂的 .so 文件缺失错误,其实就是没装这些底层依赖。我在社区的 issue 里看到不止一个人在这里绕了十分钟。
安装完跑一个 agent-browser open https://example.com 确认环境就绪。如果能正常打开页面,再跑 agent-browser snapshot -i --json 看到带 ref 标签的 JSON 输出,你的环境就通透了。全程不需要额外配置,比 Puppeteer 的 setup 步骤少一半。
操作流程
Agent Browser 的核心操作循环出奇地简单:打开页面、拍快照、用 ref 操作元素、页面变化后重新拍快照。这个循环听起来像废话,但它背后有个非常关键的假设:AI 不需要一次性理解整个页面结构,它只需要在每一步操作前知道当前页面有哪些可交互元素。
snapshot 命令是整个流程的心脏。加 -i 参数只输出可交互元素,加 --json 输出结构化数据,两个参数一起用相当于给 AI 递了一份”当前页面操作菜单”。输出里每个按钮、输入框、链接都会被自动分配一个 ref 编号,比如 @e2 代表第二个可交互元素,@e3 是第三个。
{
"success": true,
"data": {
"snapshot": "...",
"refs": {
"e1": {"role": "heading", "name": "Example Domain"},
"e2": {"role": "button", "name": "Submit"},
"e3": {"role": "textbox", "name": "Email"}
}
}
}
拿到 ref 之后的操作就很简单了:click @e2 点按钮,fill @e3 "your@email.com" 填表单,press "Enter" 敲回车。这些命令的语法一致性很高,AI 不需要写复杂的 Playwright 脚本,直接生成 CLI 命令就行。

但别高兴太早,这里有个坑。页面 DOM 发生重大变化后(比如单页应用的路由跳转),之前拍下来的 ref 会失效。社区反馈里提到最多的问题就是这个:AI 拿了一个旧的 ref 去操作,结果啥也没发生。解决方案是每次页面有明显变化后重新拍快照,这个习惯需要主动培养,官方不会帮你自动处理。
好在 Agent Browser 的等待机制补上了这个短板。wait --load networkidle 等网络请求全部完成,wait --text "登录成功" 等特定文案出现,这两个命令基本能覆盖绝大多数页面状态同步的需求。实际使用中,在 click 或 fill 之后紧跟一个 wait 命令,是减少 ref 失效最有效的办法。
关键设计
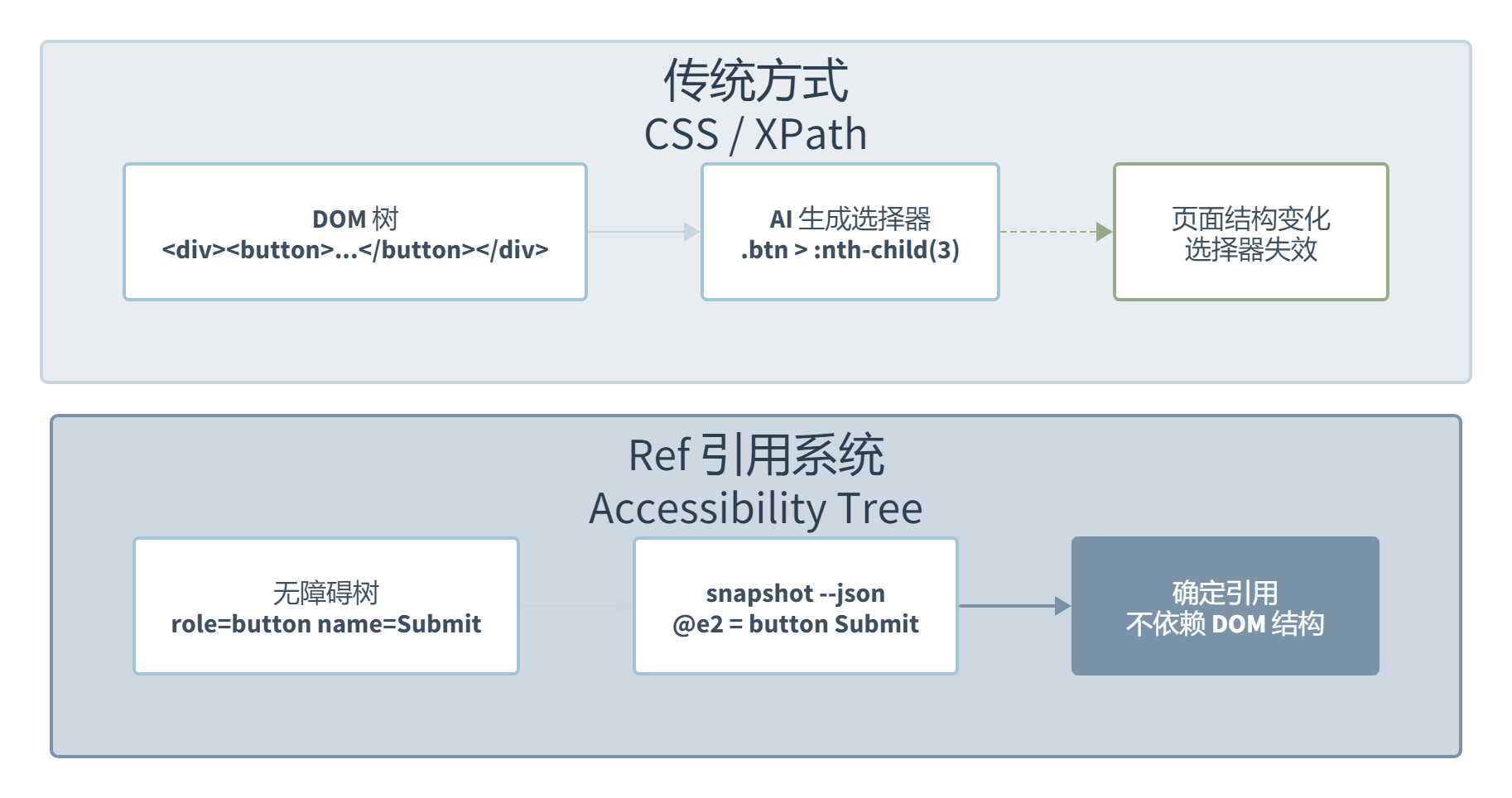
Ref 引用系统是整个工具的灵魂,也是最值得拆解的设计。传统浏览器自动化的做法是让 AI 去生成 CSS 选择器或者 XPath,比如 .login-form > button:nth-child(3) 这种。但 AI 生成这种选择器的准确率很低,页面稍微改一下结构就挂了。Vercel 的选择是反过来:不要求 AI 理解 DOM,而是让工具主动告诉 AI 页面上的每个元素叫什么。
这个设计有个很有意思的隐含前提:浏览器自动化里,人类操作其实也是”看到什么点什么”,而不是检查 DOM 结构后再操作。AI 只是缺少这个”看”的能力,snapshot 就是在帮 AI”看”。从无障碍树(Accessibility Tree)提取可交互元素,这一步相当于给 AI 装了一双眼睛。
另一个值得注意的设计是 Client-Daemon 架构。Rust 写的 CLI 客户端只负责命令解析和 socket 通信,Node.js 的 Daemon 进程常驻后台管理浏览器实例。这意味着第一次命令启动 Daemon 需要大约 500 毫秒,但后续命令通过 Unix Socket 直连,延迟不到 10 毫秒。对比每次启动新 Puppeteer 进程的方式,这个架构在频繁交互场景下能省下大量时间。
不过话说回来,Agent Browser 的跨浏览器支持确实是个明显短板。底层依赖 Playwright 引擎,理论上能跑 Chromium、Firefox、WebKit,但核心的 Screencast 和 CDP 输入注入只支持 Chromium。如果你的场景需要多浏览器兼容测试,这个工具目前还不够用。另外它的 Ref 消歧机制——遇到同名按钮时自动加 [nth=1] 后缀——虽然能用,但在密集表单场景下会让 ref 编号变得难以追踪,这可能是后续版本需要优化的方向。
使用场景
AI Agent 驱动的 Web 自动化是 Agent Browser 最核心的使用场景。想象一个场景:AI 需要自动登录某个 SaaS 平台,查询一批数据,导出 CSV,然后发邮件。传统方案需要写一整套 Playwright 脚本,还得处理登录态、异常重试、页面等待这些琐碎逻辑。Agent Browser 的做法是把每一步拆成独立的 CLI 命令,AI 只需要按顺序生成指令,snapshot 自动告诉它每一步该操作哪个元素。
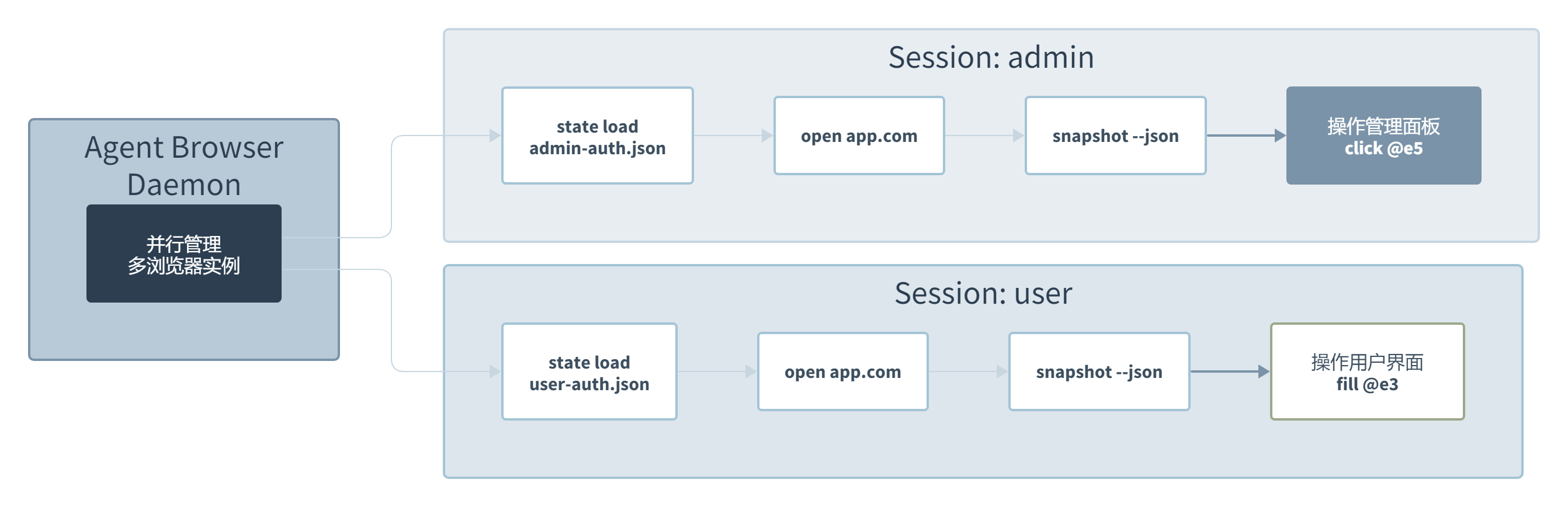
多会话隔离是另一个让人眼前一亮的场景。通过 --session 参数,你可以同时跑两个独立的浏览器实例,各自维护自己的 Cookies 和登录状态。比如一个管理员账号和一个普通用户账号并行操作,验证权限控制策略是不是真生效了。这种场景在传统工具里需要启动两个独立的浏览器进程,Agent Browser 用同一套命令体系就能搞定。
从社区的实际使用案例来看,数据抓取也是高频场景。Agent Browser 支持 get text、get attr、get html 等命令,配合 JavaScript 执行能力,能从动态页面里提取结构化数据。不过这里需要实话实说:对于单纯的静态页面抓取,它并不比 Playwright 或 Puppeteer 更高效。它的优势体现在场景需要 AI 自主决策的时候——比如 AI 识别出一个分页按钮,自动判断要不要点下一页。
不适合的场景也值得说清楚。如果你只是做简单的自动化测试脚本,不涉及 AI 自主决策,Playwright 的 API 更成熟,社区资源也更丰富。Firefox 和 WebKit 的多浏览器兼容测试目前也不是 Agent Browser 的强项。还有就是对 GUI 有执念的人:这个工具从头到尾都是命令行驱动的,如果你习惯了 Selenium IDE 那种录制回放的操作方式,上手会有适应成本。
洞察与反思
Agent Browser 让我想得最多的不是它的技术实现,而是它选择的设计原则:不求全面,只求在 AI 操作浏览器这个特定场景下做到极致。Ref 引用系统、Client-Daemon 架构、Scoped Headers 的按域名隔离认证、AI 友好的错误提示,这四个设计决策每一个都是为 AI Agent 量身定制的。这种”先搞清楚谁在用、他需要什么”的设计思路,在开源工具里其实不多见。
换个角度想,Agent Browser 的成功(27K+ star 在 Vercel 原生仓库)说明了一个趋势:AI 时代的开发工具,不再是”暴露最多的 API 就赢”,而是”让 AI 最容易理解和使用就赢”。从 CSS 选择器到 ref 引用,从启动新进程到常驻 Daemon,这两个设计变化都是同一个方向的体现:把工具的使用门槛从”人类开发者”降到”AI Agent”。
但它也有一个让我不太舒服的地方。Snapshot 机制本质上是在用无障碍树的语义信息做元素定位,这在结构规范的页面上很好用,但遇到无障碍标注缺失的页面(而这类页面在互联网上比比皆是),ref 的准确性和覆盖率就会打折扣。从架构推断,这个问题在短期内不会有根本性的解决方案,因为它的上限取决于网页本身的可访问性标注质量。
Agent Browser 作为一个底层工具已经很成熟了,但在 ClawHub 上以 Skill 形式发布这件事更有意思。它说明了一个正在发生的产品趋势:基础能力层(Vercel Labs 的 CLI)和应用集成层(ClawHub Skill)正在分离。未来越来越多的 AI 工具会走这条路,底层开源协议的信任 + 上层平台的分发和集成,这种模式可能比单一的大一统产品更有生命力。
资源地址
| 资源 | 地址 |
|---|---|
| ClawHub 页面 | https://clawhub.ai/matrixy/agent-browser-clawdbot |
| Vercel Labs 仓库 | https://github.com/vercel-labs/agent-browser |
| ClawHub 文档 | https://docs.openclaw.ai/clawhub/ |
总结
如果你做的事需要 AI 自己操作浏览器,Agent Browser 目前是最接近”开箱即用”的选择。它的 Ref 引用系统解决了传统选择器在 AI 场景下的核心痛点,Client-Daemon 架构在频繁交互中能省下可观的时间。但 Chromium 独占和 snapshot 机制对页面标注质量的依赖,是你在选择之前必须认真评估的两个限制。
Agent Browser 更大的价值不在工具本身,而在于它示范了一种”为 AI 设计工具”的思路。不是把人类的 UI 和 API 改一改塞给 AI,而是从 AI 的视角重新设计交互方式。这个思路如果扩散开来,会重塑我们做工具开发的很多基本假设。
在你的 OpenClaw 里跑 openclaw skills install agent-browser-clawdbot,装好后挑一个你常用的网站做个测试:用 snapshot -i --json 拍一张页面快照,然后尝试用 ref 定位并填写搜索框。看看实际的 ref 识别率,判断它在你自己的业务场景里到底能用到什么程度。
FAQ
Q: Agent Browser 和 Puppeteer/Playwright 的区别是什么?
A: 定位不同。Puppeteer 和 Playwright 是面向人类开发者的浏览器自动化框架,Agent Browser 是面向 AI Agent 的操作接口。核心差异在元素定位方式:前者需要你写 CSS 选择器或 XPath,后者通过快照自动生成 ref 引用。
Q: 必须用 OpenClaw 才能用 Agent Browser 吗?
A: 不用。你可以直接通过 npm 安装 Vercel Labs 的原生 CLI 工具独立使用。ClawHub Skill 只是多了一层集成封装,方便在 OpenClaw 工作流里调用。
Q: 页面结构变化后 ref 会失效,怎么处理?
A: 每次页面有明显变化后重新执行 snapshot -i --json 获取新的 ref。推荐在 click、fill 等操作后,先用 wait --load networkidle 确保加载完成,再重新 snapshot。
Q: 适合做爬虫吗?
A: 静态页面爬取不如直接用 Playwright 或 Requests 高效。但涉及需要 AI 自主判断的交互场景(动态分页、反爬绕过、多步骤表单),它的 ref 系统能显著降低自动化脚本的编写成本。
Q: ClawHub Skill 版本和原生 CLI 版本有什么差异?
A: 核心功能完全一致。Skill 版本额外提供了 OpenClaw 的一键安装、工作流编排集成和 ClawHub 社区的安全审计。如果你要深度定制或者在其他 Agent 框架里用,建议直接用原生 CLI。