
我第一次看到这个 Skill 的时候差点划走了。YouTube 字幕提取,听起来像是那种”做出来很容易、用起来没人需要”的功能。52k 下载量摆在那,显然我的判断是错的。
YouTube 上每天有超过 100 万小时的视频被上传。长篇访谈、技术讲座、产品发布会,多数人没时间看完。更常见的场景是,你搜到一个 45 分钟的视频,只想确认某个关键数据,却被迫从头拖进度条。YouTube Watcher 干的就是这件事:把视频字幕提取出来,变成一份可以直接丢给 AI 分析的纯文本。
不少人对 AI 看视频的理解还停留在多模态识别阶段,但字幕其实是一条被严重低估的捷径。绝大多数有价值的 YouTube 内容都有字幕,无论是手动上传的 CC 字幕还是 YouTube 自动生成的机器字幕。YouTube Watcher 抓住了这个信息密度最高的载体。
说真的,这篇文章不是在安利一个新奇玩具。我想拆清楚这个 52k 下载量背后,一个只有 1 个依赖项、不到 50 行 Python 代码的 Skill,为什么能成为 ClawHub 上 Data & APIs 分类的头部项目。
环境准备
环境准备比大多数人预想的简单。整个 Skill 只依赖一个外部工具:yt-dlp。这个工具是 youtube-dl 的活跃维护分支,Linux/macOS 的包管理器基本都收录了。Windows 用户去 GitHub Releases 下载一个 exe 丢到 PATH 里就行。
如果你在 macOS 上,Homebrew 一条命令搞定:
brew install yt-dlp
Linux 用户用系统包管理器或 pip 安装都行,注意 pip 安装后要确认 yt-dlp 的二进制路径在 PATH 里。Windows 最省心的方式是 winget install yt-dlp.yt-dlp,不需要手动配环境变量。
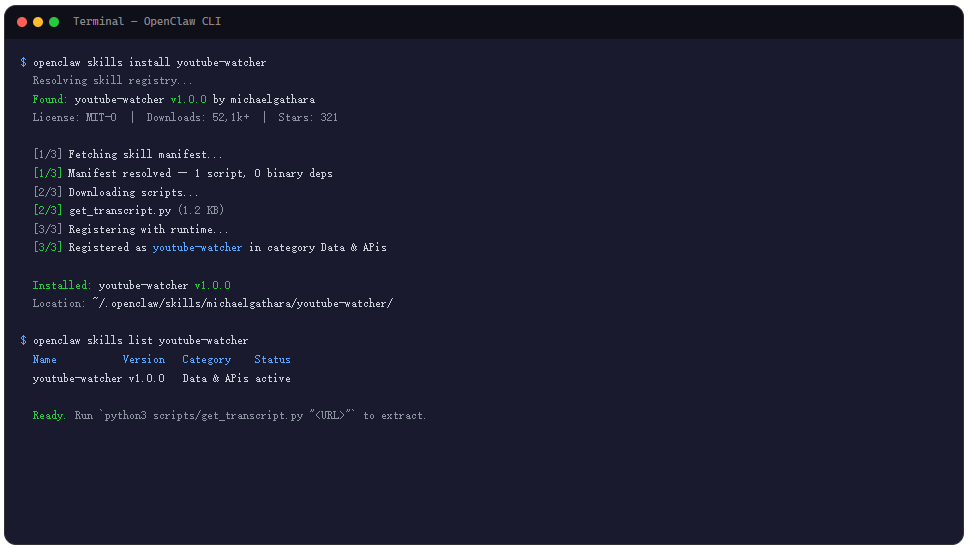
yt-dlp 装好之后,Skill 本身用 OpenClaw CLI 一行命令拉下来:
openclaw skills install youtube-watcher
装完后怎么确认一切就绪?随便找一个有字幕的视频,跑一下 Skill 自带的脚本:
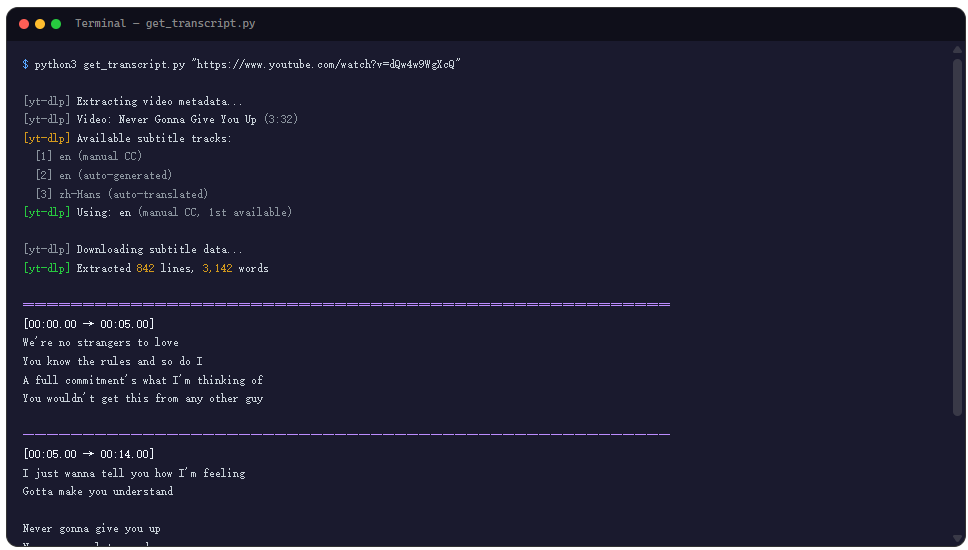
python3 {baseDir}/scripts/get_transcript.py "https://www.youtube.com/watch?v=dQw4w9WgXcQ"
如果能返回一大段文本,说明通了。如果报错,大概率是 yt-dlp 不在 PATH 里,或者是 URL 格式不对。注意 URL 必须是完整的视频链接,纯视频 ID 不认。
操作流程
YouTube Watcher 的流程简单到可以用一句话说完:给一个 YouTube URL,返回视频的完整字幕文本。但这句话背后有几个值得展开的细节。
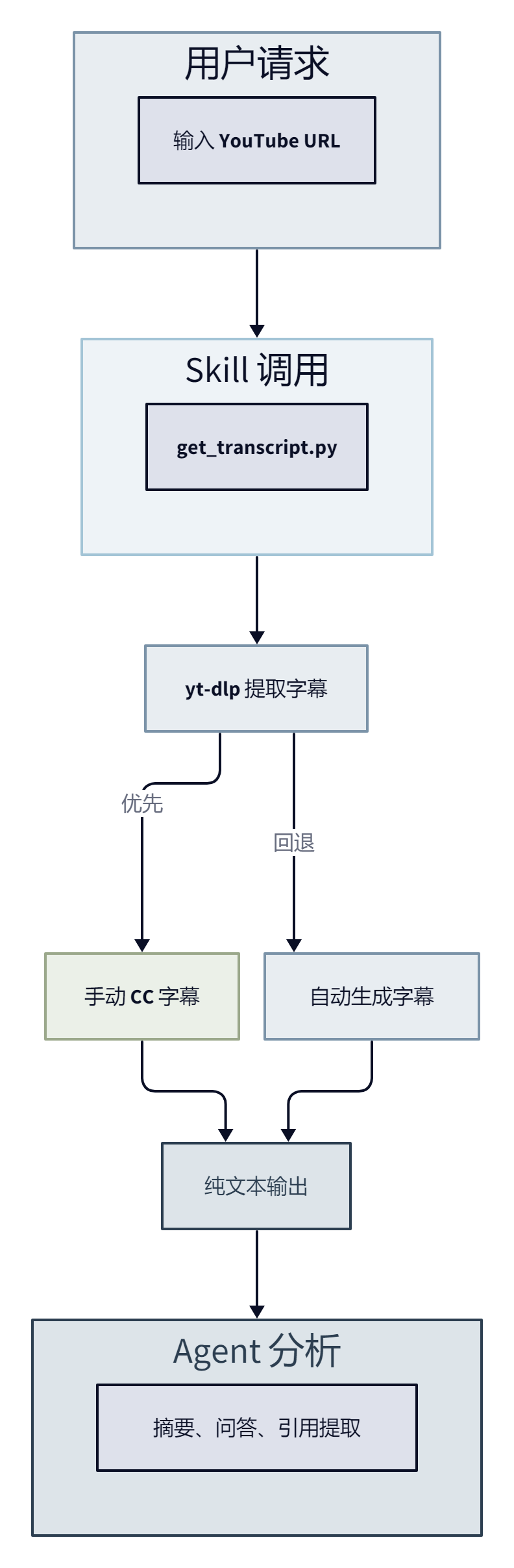
完整的工作链路是三步。第一步,OpenClaw Agent 收到用户请求后,调用 get_transcript.py 脚本,传入视频链接作为参数。第二步,脚本内部调起 yt-dlp,自动检测视频是否带有字幕轨道,优先选择手动上传的 CC 字幕,没有就退回到 YouTube 自动生成的字幕。第三步,把提取到的纯文本返回给 Agent,Agent 根据用户意图做进一步的摘要、问答或分析。
关键环节在第二步的字幕优先级选择。yt-dlp 面对一个字幕源丰富的视频时,会同时看到多个轨道:手动上传的中文字幕、自动生成的英文字幕、甚至自动翻译的字幕。Skill 脚本目前没有做语言偏好过滤,输出的是 yt-dlp 默认选择的第一个可用字幕。对中文用户来说,如果视频有手动上传的中文字幕,优先被选中,否则很可能拿到英文自动字幕。
注意一个容易被忽略的限制。如果视频没有任何字幕,脚本会直接报错退出,不会尝试调用语音识别或其他 fallback 方案。53k 下载量里有多少人卡在了这一步,社区没有统计数字,但从 yt-dlp 仓库的 Issues 来看,纯音乐视频、直播回放和无字幕旧视频是主要的失败案例。
关键设计
YouTube Watcher 有一个让很多同类方案相形见绌的设计选择:它不把 yt-dlp 打包成 Python 依赖,而是要求用户自行安装到系统 PATH。
这个决定乍一看很反直觉。为什么不直接 pip install yt-dlp 写进依赖声明里,让安装过程完全自动化?从文档和社区反馈推断,设计者 Michael Gathara 在权衡了两件事:维护成本和跨平台兼容性。
yt-dlp 的 pip 安装在某些环境(特别是 arm64 macOS 和 Windows)下需要额外编译依赖,而系统包管理器安装的方式避免了这个问题。更关键的是,yt-dlp 本身更新非常频繁,每周至少一个 Release。如果把版本锁死在 Skill 里,字幕提取的稳定性会随 YouTube 的反爬策略变化而快速退化。放在系统 PATH 里,用户自己保持 yt-dlp 最新版本,Skill 永远用的是最新版。
另一个有意思的设计点是脚本本身极简。核心逻辑几乎就是一行 subprocess.run(['yt-dlp', '--write-auto-subs', ...]) 加上输出过滤。没有缓存层、没有重试逻辑、没有错误恢复。这看起来像是偷懒,但对于一个专注于”胶水层”定位的 Skill 来说是合理选择。重试和缓存这种事情应该交给上游的 Agent 框架去做,Skill 的职责就是做好一件事然后退出。
但极简的代价也很明显。没有语言选择参数意味着你没法指定”我要中文字幕”,对于多语言字幕的视频只能接受默认选择。如果将来版本迭代,加上 --sub-lang 参数支持,这个 Skill 的实用性会上一个台阶。
使用场景
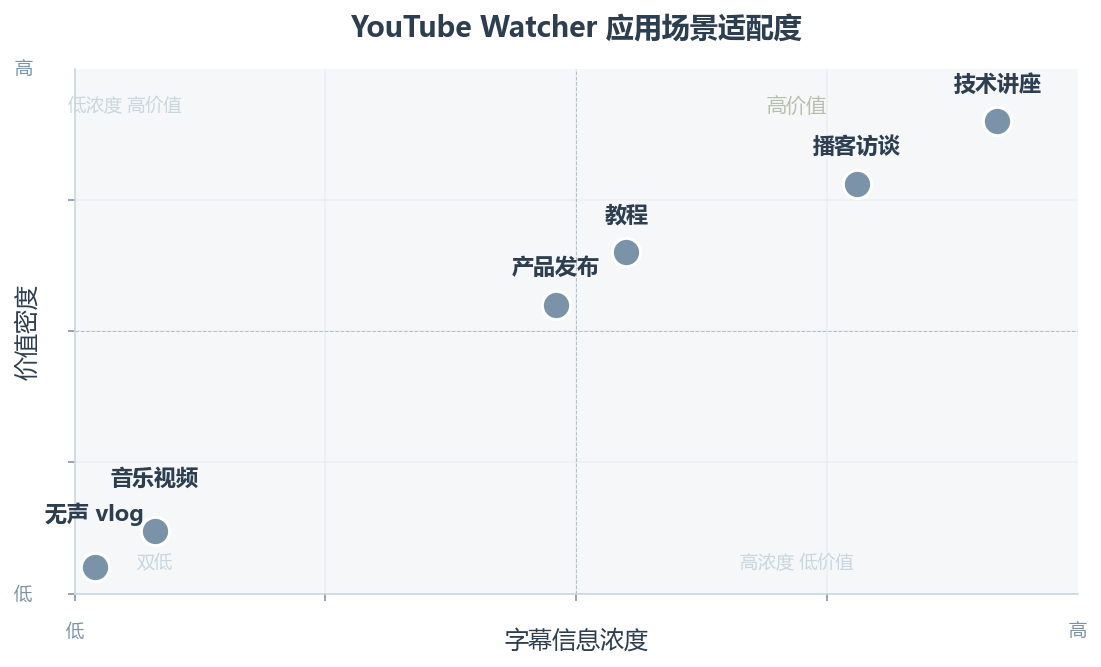
YouTube Watcher 最典型的应用场景不是”看完一个视频”,而是”跳过视频直接拿到信息”。这个定位决定了它最擅长的是信息密集型、时长较长、字幕质量较高的内容。
技术讲座和会议演讲是黄金场景。一个 40 分钟的 GTC 主题演讲,提取出字幕文本后可以直接让 Agent 做结构化摘要:演讲者的核心论点、关键数据、新发布的产品特性。从社区讨论看,不少用户把它和笔记工具串在一起,自动生成会议纪要。
深度访谈和播客类内容也适配得很好。长对话中往往散布着零散的金句和观点,手动做笔记基本不可能全覆盖。字幕文本作为输入后,让 Agent 按话题分段、提取关键引用、标注时间节点,效果比纯音频方案好一个量级。
不太适合的场景也值得说清楚。纯音乐视频、无声的 vlog、或者画面信息密度远高于语音的内容,比如 UI 设计教学或代码实战,字幕本身提供的信息有限。这种情况下,YouTube Watcher 只能给你到语音内容这一层,画面上的操作步骤需要额外的人工或视觉 AI 补齐。
还有一个容易被忽视的用途:信息验证。当你看到一个被引用爆炸的数据需要确认来源时,不需要跳转到视频拉进度条找那句话,让 Agent 直接搜字幕文本,几秒钟给出原文和上下文,比人工定位快得多。
洞察与反思
YouTube Watcher 让我重新审视一个问题:AI Agent 时代的工具应该长什么样。
过去我们做 YouTube 字幕工具,思路是搞一个独立的应用,带 GUI、支持格式选择、多语言翻译、搜索高亮,恨不得把所有功能塞进去。YouTube Watcher 走了完全相反的路:它不提供任何用户界面,不做任何格式转换,甚至连输出美化都懒得做。它只干一件事,然后把原始文本交给 Agent。
这种极简设计套在 Agent 生态里反而是优势。Agent 不需要一个带 20 个按钮的字幕管理器,它只需要一段干净的文本输入。任何额外的解析、搜索、翻译、摘要,都是 Agent 自己的事。这正是 PromptOS 架构哲学里”让 Prompt 解决问题,让工具回归原子化”的落地案例。
另一个值得注意的信号是 52k 下载量背后的增长动力。YouTube Watcher 发布于 2026 年 3 月,三个月做到 52k,平均每月 17k。这个速度在 ClawHub 的 Data & APIs 分类里是跑在最前面的几个项目之一。它的增长不是因为功能多,恰恰是因为功能少。功能少意味着学习成本低、故障面小、兼容性强。
但这种极简也埋了一个隐患。如果 YouTube 改变了字幕存储格式或反爬策略,Skill 本身没有应对能力,所有修复压力都在 yt-dlp 的开发团队身上。从安全和可维护性的角度,它是寄生在 yt-dlp 的快速迭代能力上的。这种模式在 yt-dlp 维护活跃的阶段靠谱,一旦 yt-dlp 进入维护低潮,YouTube Watcher 的稳定性会同步塌陷。目前来看这个风险还不紧迫,但不该被忽视。
资源地址
| 资源 | 地址 |
|---|---|
| ClawHub | https://clawhub.ai/michaelgathara/youtube-watcher |
| OpenClaw 文档 | https://docs.openclaw.ai/clawhub/ |
| yt-dlp 项目地址 | https://github.com/yt-dlp/yt-dlp |
总结
YouTube Watcher 的核心价值不在技术复杂度,而在定位精准。它清楚地知道自己该做什么、不该做什么,把字幕提取这一件事做到了”一行命令、零配置、一次通过”的程度。
对于日常需要大量处理 YouTube 内容的人来说,把它挂到自己的 Agent pipeline 里是一个几乎零成本的效率增益。你不再需要为了一个 30 秒的数据点在视频里拖进度条,让 Agent 读字幕、找答案、给出结论,整个过程在几秒内完成。
但它不是一个万能工具。无字幕的视频它处理不了,多语言字幕的选择缺乏灵活性,稳定性完全依赖 yt-dlp 的持续维护。如果你面对的视频内容绝大多数都有字幕,YouTube Watcher 是最直接的解决方案;如果经常处理无字幕或纯视觉内容,需要搭配其他多模态方案一起使用。
装好 yt-dlp 和 OpenClaw CLI 之后,找一个你最近想了解但没时间看完的技术演讲,用 YouTube Watcher 提取字幕,让 Agent 根据字幕文本回答三个你真正关心的问题。如果三次都答对了,把它加到你的日常工作流里。
FAQ
Q: 这个 Skill 需要付费吗? A: 不需要。MIT-0 许可证,完全免费开源。唯一的依赖 yt-dlp 也是开源的。
Q: YouTube 自动生成的字幕准确率够用吗? A: 英文自动字幕的准确率在 90% 以上,中文自动字幕稍低但基本可用。如果视频有人工上传的 CC 字幕,Skill 会优先使用,准确率更高。
Q: 和直接对着视频做语音识别有什么区别? A: 字幕提取是直接从 YouTube 的 API 拉取已有文本数据,不涉及音频处理。速度更快、资源消耗更低,但局限是依赖视频本身有字幕轨道。
Q: 能指定提取哪种语言的字幕吗? A: 当前版本(v1.0.0)不支持语言选择参数。如果有手动上传的中文字幕会优先选中,否则默认选择 yt-dlp 返回的第一个可用轨道。多语言场景下这是一个明显的限制。
Q: 没有字幕的视频怎么处理? A: YouTube Watcher 处理不了这种情况。你需要搭配其他方案,比如用 yt-dlp 下载音频后本地跑 whisper 做语音识别。