

用 3B 的活跃参数跑出超越前代 235B 的性能,就这一条,Qwen3.5 已经让整个开源社区炸了锅。从 0.8B 的物联网小模型到 397B 的 MoE 旗舰,覆盖十条产品线,Apache 2.0 全开源商用无限制。但它真的像参数上看起来那么香吗?上手测了一圈,效率提升确实惊人,工具调用和 Agent 能力却还有进步空间。
先搞懂它是什么
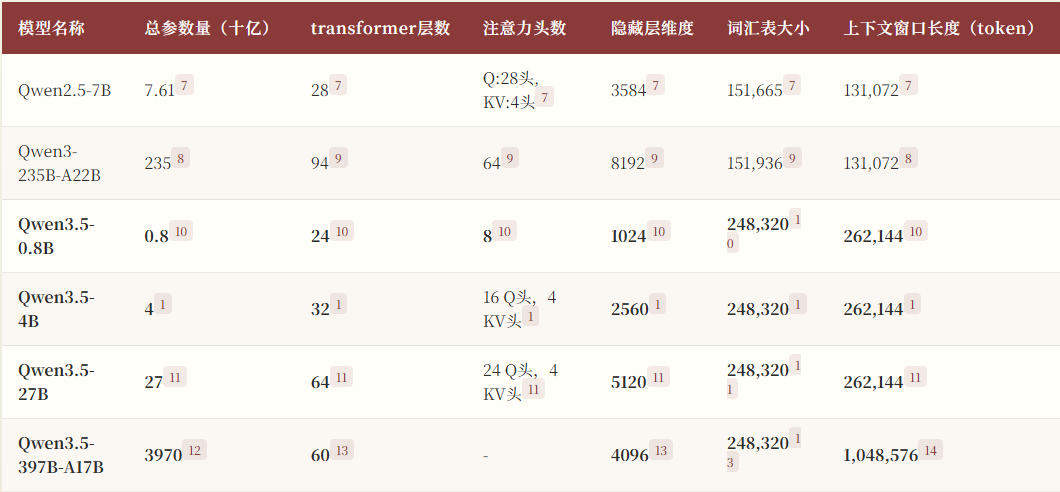
2026 年除夕夜,阿里通义千问放了个大招,一口气甩出 Qwen3.5 全系列模型。从 0.8B 的嵌入式小模型到 397B 的旗舰 MoE,一共八个版本覆盖所有场景。这不仅是常规升级,更是一次架构革命,Gated Delta Networks 加高稀疏 MoE,直接把激活比压缩到 5% 以下。前代 Qwen3 还是稠密加基础 MoE 架构,到了 Qwen3.5 直接切换赛道。
官网:https://qwen.ai | 项目地址:https://github.com/QwenLM/Qwen
最颠覆的一点是效率。397B 总参数只激活 17B,显存占用降了 60%,32K 上下文吞吐量翻了 8.6 倍。这些数字放在一起,Qwen3.5 的定位很明确:不是堆参数拼排行榜,而是用更少的算力做更多的事。全系 Apache 2.0 开源无商用限制,补上了前代在开放度上的最后一块短板。
这几个亮点确实猛
说了一堆概念,来看看技术层面 Qwen3.5 到底改了什么。
架构革新是最大的亮点。 Gated Delta Networks 技术来自 NeurIPS 2025 最佳论文,配合极端 GQA 16:1 的设计,KV Cache 被压缩到 6.25%。这意味着同等的硬件可以撑更长的上下文,256K 吞吐量提升 19 倍,实测长文档阅读几乎没有性能衰减。
原生多模态摆脱了”拼接”方案。 前代 Qwen3 需要外挂视觉编码器,Qwen3.5 从训练阶段就把文本和视觉令牌做早期融合。4B 和 9B 的版本不需要额外视觉模块就能识图、读文档、看视频,对消费级显卡极其友好。
超长上下文做到了 1M tokens。 原生 256K 起步,最高可扩展至 1M,大约能塞下一本《三体》全集或者两小时视频。线性注意力的加持让长文本处理没有性能衰减,不是简单的”塞得进去但记不住”。

原生智能体架构是面向生产的布局。 从第一天开始就内置了工具调用、函数调用和多工具编排能力。PC 端可以做跨应用自动化,比如从 Excel 取数到 PPT 再发邮件,移动端也能执行 APP 指令。前代 Qwen3 只是基础工具调用,这一代直接上生产级方案。
从零开始试
架构纸面很强,那从下载到用上到底顺不顺手?
对于开发者,最快的方式是走 API。去阿里云开一个 DashScope 账号,拿到密钥就能直接调用 Qwen3.5-Flash,不需要配任何 GPU。输入输出大概 $0.065 到 $0.26 每百万 tokens,做原型验证成本极低。第一次请求返回的速度在 0.8 秒左右,吞吐量跑到 95 tokens/s,响应比预期来得快。
想本地部署的话,Qwen3.5-27B 是单卡友好型选手。在 RTX 3090 上用 llama.cpp 做 Q4 量化,占用 16 到 18GB 显存,一台机器就能跑起来。下载权重到启动推理,整个过程大概半小时。首次生成的感受是,指令跟随能力比前代好很多,特别是中英文混合的 prompt,不会再出现回英文的尴尬。
但也不是全无槽点。MoE 模型的部署比密集模型麻烦不少。35B-A3B 虽然只有 3B 活跃参数,但对推理框架有要求,得用 vLLM 或者 TGI 才能发挥稀疏路由的优势。122B-A10B 如果想要本地跑,起码要两块 GPU 外加激进量化,部署成本不低。
几个隐藏技巧
基础跑通了,但真正拉开体验差距的其实是下面几个用法。
-
双模式推理别用错场合。 简单问答用非思考模式,首 token 延迟只有 0.8 秒。复杂逻辑题和代码生成切到思考模式,虽然会多等一两秒,但推理质量有明显提升。很多人全程用默认设置,浪费了一半的性能红利。 -
小模型别当废物看。 Qwen3.5-4B 的参数才跟手机 APP 差不多大,但在特定场景下性价比极高。比如批量文本分类、简单客服问答,4B 跑得快还省显存,完全没必要上大模型。我们测过一个文档分类任务,4B 的准确率只比 35B 低 3%,但成本差了八倍。 -
用 35B-A3B 跑高并发最划算。 3B 活跃参数意味着每秒能处理更多的请求。如果你做 SaaS 服务或者 API 代理,35B-A3B 的吞吐表现远超同价位的密集模型。量化到 Q4 之后只要 12 到 15GB 显存,一台 4090 就能撑起中等规模的业务流量。 -
长上下文别忘了开 KV Cache 优化。 Qwen3.5 的极端 GQA 设计让 KV Cache 缩小到 6.25%,但如果处理超过 100K tokens 的文档,手动开启缓存复用能再省 30% 的推理成本。这个开关在 vLLM 的配置里,不是默认打开的。
横向对比
把 Qwen3.5 放进 2026 年开源模型赛道里,它的定位一下子清晰了。
| 对比维度 | Qwen3.5 | DeepSeek V4 | Llama 4 | GPT-5.x 系列 |
|---|---|---|---|---|
| 参数量覆盖 | 0.8B-397B | 多版本 | 8B-405B | 闭源 |
| 开源协议 | Apache 2.0 | 自定义商用 | 自定义商用 | 闭源 |
| 活跃参数比 | < 5%(MoE) | 中等稀疏 | 稠密为主 | 未知 |
| 原生多模态 | 全系支持 | 部分版本 | 部分版本 | 全系 |
| 上下文长度 | 最高 1M | 128K | 128K | 256K |
| 中文能力 | 原生强 | 强 | 一般 | 中等 |
| Token 成本 | $0.01-$0.39/M | 相近 | 相近 | 偏高 |
Qwen3.5 最大的差异化在于”全参数覆盖加 Apache 2.0 加原生多模态”。DeepSeek V4 的中文能力同样出色,但没有从 0.8B 到 397B 这么完整的产品线。Llama 4 走的是稠密路线,在长上下文效率上不如 MoE 方案。GPT 系列虽然是闭源老大,但成本高出 Qwen3.5 十倍不止,预算敏感的场景完全没必要硬上。
大家的使用感受
参数上优势明显,来听听社区里真正跑过的人怎么说。
好评集中在效率层面。不少开发者反馈 35B-A3B 的表现惊艳,一台 4090 就能跑出超越前代 235B 的质量,是真正的代际飞跃。有人评价”用 3B 的算力拿 35B 的参数红利,这种好事以前只有大厂能享受”。Apache 2.0 协议也收割了一波好感,做商用部署不需要跟法务打架。
吐槽的声音也有道理。工具调用是大家集中的槽点,多工具编排时容易遗漏参数,错误处理不够稳健,做复杂 Agent 时会掉链子。还有用户提到 MoE 模型的微调比密集模型麻烦很多,想用 LoRA 做行业适配需要更多调参技巧。中文社区资源丰富,但英文文档和案例确实偏少。
全方位评估
口碑有好有坏,从专业维度给 Qwen3.5 打个量化分。
| 维度 | 评分 | 一句话解读 |
|---|---|---|
| 功能完整性 | ⭐⭐⭐⭐☆ | 全参数覆盖+原生多模态,缺在 Agent 打磨 |
| 易用性 | ⭐⭐⭐⭐☆ | API 即开即用,本地部署 MoE 稍麻烦 |
| 性价比 | ⭐⭐⭐⭐⭐ | 成本仅对标闭源模型的 1/10,太能打 |
| 创新性 | ⭐⭐⭐⭐⭐ | Gated Delta Networks 是架构层面的突破 |
| 稳定性 | ⭐⭐⭐⭐☆ | 推理稳定,但工具调用偶有异常 |
| 推荐度 | ⭐⭐⭐⭐☆ | 开发者和企业值得试,Agent 重度用户等迭代 |
| 综合评分:8.2 / 10 |
优点和槽点
优势
-
效率革命:35B-A3B 仅 3B 激活参数全面超越前代 235B,部署成本直降 70% -
全系开源无限制:Apache 2.0 协议,从 0.8B 到 397B 全部可商用 -
原生多模态:4B 和 9B 无需额外模块即可识图读文档,消费级显卡友好 -
超长上下文:最高 1M tokens,长文档处理无性能衰减 -
定价极具竞争力:旗舰 397B 输入仅 $0.39/百万 tokens,性价比碾压闭源
不足
-
工具调用不够稳:多工具编排容易漏参数,错误处理待加强 -
MoE 微调门槛高:比密集模型需要更多技巧,LoRA 适配曲线陡 -
122B 本地部署代价大:需要多 GPU 或激进量化,可能影响输出质量 -
英文生态偏弱:文档和社区以中文为主,国际化路上还需补课
适合谁用
打分明细有了,来看不同角色怎么选。
-
个人开发者和独立开发者:Qwen3.5-27B 单卡可跑,Apache 2.0 商用无顾虑,是本地部署做小产品的首选。35B-A3B 适合用来跑高并发的 API 服务,一台 4090 就能撑起来。 -
企业 AI 团队:用 Qwen3.5-Flash 做快速原型验证,确定需求后再切换到 35B-A3B 或 122B-A10B 自建推理服务。成本只有闭源模型的十分之一,预算敏感的项目尤其划算。 -
科研和教育机构:全参数开源意味着可以深入模型内部做研究和实验。4B 和 9B 版本的低门槛让教学场景也能跑真模型,而不是用模拟器凑合。 -
智能硬件厂商:0.8B 和 2B 版本可以跑在嵌入式设备和物联网终端上。功耗低、响应快,对于想做端侧 AI 的硬件团队来说是目前最轻量的选择之一。 -
不太适合的人:如果你需要一个稳定的生产级 Agent 底座,或者英文工作流为主且需要完善的英文文档支撑,Qwen3.5 目前的经验积累还不够成熟。
值这个价吗
产品和需求对上了,来算一笔账。
Qwen3.5 的定价逻辑跟传统闭源模型完全不同。不是按席位或者月费来收,而是以 API 按量计费加本地部署免费的方式存在。开源模型本身就省掉了推理服务的溢价,唯一的成本是 GPU 和运维。
| 方式 | 方案 | 成本预估 | 适合场景 |
|---|---|---|---|
| API 调用 | Qwen3.5-Flash ($0.065/$0.26 per M tokens) | 日均 10 万 tokens 一月约 $20 | 快速原型、低并发服务 |
| API 调用 | Qwen3.5-35B-A3B ($0.163/$0.90) | 日均 50 万 tokens 一月约 $160 | 中等规模生产 |
| 本地部署 | Qwen3.5-27B(单卡 4090) | 硬件一次性 1.5 万,电费忽略 | 数据敏感、离线场景 |
| 本地部署 | Qwen3.5-122B-A10B(多卡) | 硬件约 5 万起 | 复杂推理、科研 |
| 闭源对标 | GPT-5.x 对应档次 | 月均 $2000+ | 预算充足的成熟业务 |
最值得推荐的是 35B-A3B 模式。3B 活跃参数的推理成本跟 27B 密集模型差不多,但模型容量达到 35B 级别。在一个日处理 50 万 tokens 的中等规模场景下,月成本不到 200 美元,对标的闭源模型至少要花 2000 以上。
常见问题
分数摆在这了,有些细节你可能还想弄清楚。
Q1:Qwen3.5 和 Qwen3 的区别大吗?值得升级吗?
A1:建议升级,代际差异非常明显。 Qwen3.5 在效率上提升 8 到 19 倍,MoE 架构和原生多模态是 Qwen3 不具备的能力。如果你在用 Qwen3 做本地部署或 API 调用,切换到同参数的 Qwen3.5 版本几乎不需要改代码,但体验会好一截。
Q2:Qwen3.5 开源版本可以商用吗?
A2:可以,Apache 2.0 协议无商用限制。 所有开源版本(0.8B 到 397B)都遵循 Apache 2.0,可以自由修改、再分发、用于商业产品。不需要购买额外授权。
Q3:中文支持怎么样?对比国内竞品有优势吗?
A3:中文能力是 Qwen3.5 的核心强项,属第一梯队。 原生支持 201 种语言,词表扩大到 25 万。中英文混合、方言识别、中文长文档理解的表现都好于 Llama 4,跟 DeepSeek V4 处于同一水平线。
Q4:本地部署最低需要什么配置?
A4:最低 4GB 显存就能跑 0.8B 版本。 想在消费级显卡上跑出好体验,推荐 Qwen3.5-9B 量化版(约 6-8GB 显存)或 27B 量化版(16-18GB 显存,RTX 3090/4090 可跑)。
Q5:MoE 模型和密集模型选哪个?
A5:追求效率和成本选 MoE,追求确定性选密集。 MoE 模型(35B-A3B)用更少算力获得更大容量,适合在线服务和高并发。密集模型(27B)内存占用可预测、微调简单,适合本地部署和定制化场景。
Q6:Qwen3.5 做 Agent 够用吗?
A6:基础工具调用可用,复杂编排还有差距。 单工具调用表现不错,但多工具编排时容易遗漏参数,错误处理也不够稳健。把它当 Agent 底座时,建议在上层加一层编排框架做兜底。
Q7:多模态能力是怎么实现的?
A7:采用早期融合训练,文本和视觉令牌在训练阶段就统一处理。 这意味着 4B 和 9B 版本不需要额外挂载视觉编码器,一个模型就能同时处理文字、图片和视频输入。
Q8:Qwen3.5 Plus 和开源版有什么区别?
A8:Plus 是 DashScope 托管闭源版,不开源不提供权重。 性能经过额外优化,上下文达到 1M,但受阿里云商业条款约束。如果你需要数据驻留或权重控制,用开源的 397B-A17B 更合适。
Q9:有免费额度可以用吗?
A9:开源版本身就是免费的,API 调用的免费额度看服务商。 通过 DashScope 注册新用户通常有免费体验额度。本地部署只要你有硬件,完全不花钱。
Q10:相比 DeepSeek V4 怎么选?
A10:中文任务两者都可以,Qwen3.5 胜在产品线完整度。 从 0.8B 端侧到 397B 云端全覆盖,DeepSeek V4 没有这么完整的参数梯度。如果你需要多种规格的模型来适配不同场景,Qwen3.5 的一站式方案更方便。
所以到底值不值得
Qwen3.5 不是一个靠参数堆出来的模型,而是一次效率思维的胜利。用更少的激活参数办更多的事,把开源大模型的准入门槛从大厂专属拉到了个人开发者也能触碰的范围。
35B-A3B 是这次发布中最值得关注的一个版本,3B 的推理成本换来 35B 的模型容量,这种杠杆效应在 2026 年的大模型市场里很有杀伤力。
但工具调用不稳、MoE 微调门槛高这些短板也确实存在。对于预算敏感的开发者、想自建 AI 服务的中小企业,Qwen3.5 值得放进备选清单。如果你需要的是一个成熟的 Agent 底座或者英文生态优先,可以再观望几个迭代。