

写个复杂点的工程代码,来回折腾好几个小时还没跑通?GLM-5.1 可能是来治这个病的。SWE-Bench Pro 直接跑到 58.4 分,把 GPT-5.4 和 Claude Opus 4.6 都压了一头。更夸张的是能干 8 小时长程任务不需要你盯着。MIT 协议全量开源,价格只有 Opus 的八分之一。但推理速度偏慢、复杂重构不如 Opus 稳,这些短板也得说清楚。
产品概述
GLM-5.1 是智谱 AI(Z.ai)在 2026 年 4 月发布的旗舰级开源大模型,也是业界首个能独立完成 8 小时级复杂工程任务的开源模型。智谱 AI 出身清华,2026 年初完成香港 IPO,这家公司在开源社区一直有存在感,这次 GLM-5.1 直接拿出 MIT 协议全量开源,算是对闭源巨头的一次正面对冲。
官网:https://bigmodel.cn | 项目地址:https://huggingface.co/Z-AI (需要网络支持)
它的核心差异在于:不是做一个更强的对话模型,而是瞄准了“工程级自主执行”这个方向。传统大模型你问一句它答一句,GLM-5.1 的设计逻辑是你说一个目标,它自己规划、拆解、执行、测试、修复,循环往复直到交付。200K 上下文窗口加 128K 最大输出,给这种长时间自主行为提供了足够的空间。
技术上基于 MoE 架构,总参数约 7450 亿,每 token 只激活 40B,所以虽然模型体量庞大,推理成本并没有跟着涨。全程在华为昇腾芯片上训练,也意味着从硬件到软件完全自主可控。对于有国产化需求的政企客户来说,这一点的权重远比跑分高。
到底强在哪
说了一堆概念,那它真正能打的技能有哪些?挑几个最能拉开差距的来看。
-
8 小时长程自治:这是 GLM-5.1 最破圈的能力。一个会话能自主运行最长 8 小时,单次调用超过 6000 次工具操作。官方演示里它在 8 小时内从零构建了一个完整的 Linux 桌面系统,包含窗口管理器、文件浏览器和终端工具。放到实际工程场景,相当于你把一个复杂需求丢给它,去吃个午饭回来,代码已经写好、测试通过、优化完了。 -
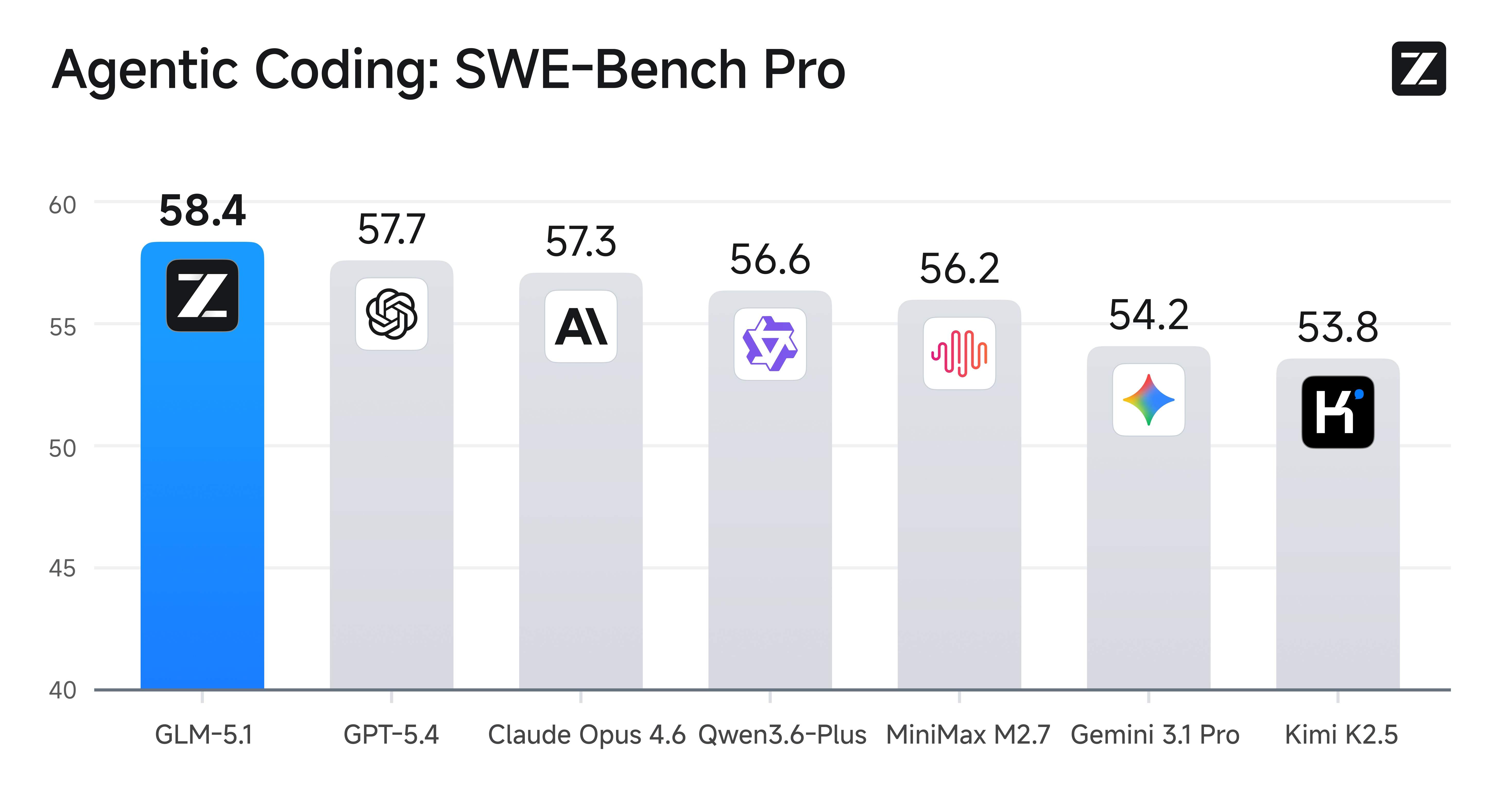
SWE-Bench Pro 全球第一:58.4 分的成绩,压了 GPT-5.4(57.5)和 Claude Opus 4.6(57.3)一头。SWE-Bench 评测的是真实软件工程能力,不是刷题式的代码填空,所以这个第一的含金量比较高。在编程评测框架下它的得分是 45.3,比前代 GLM-5 提高了近 10 分,涨幅接近 30%。
-
交叉思考模式(Interleave Thinking):传统推理模型通常是先思考完再回答,或者边想边答。GLM-5.1 的方式是“思考一步、执行一步、复盘一步”,形成一个闭环逻辑链。这种设计解决了一个老问题,长任务做了一半发现方向偏了,不会硬着头皮走到底,而是能自己纠正。 -
128K 超长输出:大多数模型的输出限制在 8K 到 16K,跑长任务常常被截断。128K 输出 token 意味着你让它生成整个项目的代码库骨架、或者写一份完整的技术文档,它不会在中间戛然而止。配合 200K 上下文,处理 15 万字以上的文档也不会丢失信息。 -
200K 上下文 + DSA 优化:引入 DeepSeek Sparse Attention 并做了针对性优化,长文本处理的计算成本降低了 20% 以上。不是简单的抄作业,智谱团队用自己的异步强化学习框架 Slime 做了深度适配,长窗口性能比直接用原版 DSA 更稳定。
上手体验
功能听起来够硬,那从注册到用起来到底顺不顺畅?智谱在兼容性上做了个聪明的选择:直接兼容 OpenAI 接口规范。你不需要学新的调用方式,把 model 参数从 gpt-4o 改成 glm-5.1 就能跑起来。
from zai import ZhipuAiClient
# 初始化客户端
client = ZhipuAiClient(api_key="YOUR_API_KEY")
# 创建聊天完成请求
response = client.chat.completions.create(
model="glm-5.1",
messages=[
{
"role": "system",
"content": "你是一个有用的AI助手。"
},
{
"role": "user",
"content": "你好,请介绍一下自己。"
}
],
temperature=0.6
)
# 获取回复
print(response.choices[0].message.content)
去 bigmodel.cn 注册账号,几步就完成了身份验证。然后去开发者后台领取新用户的 2000 万 tokens 免费额度,有效期 3 个月,够你把核心场景都跑一遍。SDK 支持 Python(zai-sdk)、Java 和直接 cURL 请求,最常见的 Python 环境里 pip install zai-sdk 就能开搞。
第一次请求选了典型的长代码生成任务:让模型写一个完整的 RESTful API 后端,包含用户认证、数据 CRUD 和文件上传。大概等了十几秒,返回的代码结构非常完整,目录分层清楚,异常处理到位,甚至还带了单元测试。对比之前用 GPT-5.4 跑同样的需求,GLM-5.1 在代码完整性上不输,但在首字响应速度上确实慢了一拍。
需要注意一点:如果你要用它的长程自治模式,建议启用流式输出(stream: true),不然等待时间会很明显。高峰期(14:00-18:00)token 消耗按 3 倍计算,非复杂的任务可以避开这个时段。
使用技巧
基础操作不复杂,但有些用法能让你省不少事。
-
长任务记得开 Thinking 模式:默认模式下的推理深度不如开启 thinking 参数。在 API 请求里加 "thinking": {"type": "enabled"},模型会启用 Interleave Thinking 循环,对复杂工程任务的完成度提升非常明显。实测同一个代码库重构任务,开与否的交付质量差了至少一个档次。 -
搭配 Claude Code / OpenCode 使用:GLM-5.1 深度适配了 Claude Code、Cline、Kilo Code 等主流编码工具。你只需要在这些工具的配置里把模型名改成 glm-5.1,就能以 Opus 八分之一的价格,获得接近 Opus 90% 以上的编码体验。对于日活高的开发者来说,每月成本从几百美元降到几十美元。 -
模型搭配降本策略:GLM-5.1 虽然便宜,但高峰期跑长了也不便宜。一个省钱的策略是:复杂工程任务交 5.1,日常代码补全和简单查询用 GLM-5-Turbo 甚至 GLM-4.7。通过上下文缓存(Cache)机制,重复对话的 token 消耗还能进一步降低。 -
私有化部署做量化:如果本地部署需求,直接用官方提供的 GGUF 量化版本。2-bit 量化版大约需要 220GB 内存,4-bit 版需要约 350GB。单卡 4090(24GB)启用量化勉强能跑,但体验最好的配置是 4 张 A100 或 8 张 H100。华为昇腾 NPU 部署也支持,国产化场景下这是个加分项。
竞品对比
GLM-5.1 的真正对手不是国内的开源模型,而是 GPT-5.4 和 Claude Opus 4.6 这两个闭源天花板。直接拉个表:
| 对比维度 | GLM-5.1 | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|---|
| SWE-Bench Pro | 58.4 🥇 | 57.5 | 57.3 |
| 持续工作时长 | 8 小时+ | ~2 小时 | ~3 小时 |
| 上下文窗口 | 200K | 128K | 200K |
| 最大输出 | 128K 🏆 | ~32K | ~64K |
| API 输出价格 | $4.40/M | $20.68/M | $34.40/M |
| 开源协议 | MIT 开源 | 闭源 | 闭源 |
| 中文能力 | 极强 🏆 | 优秀 | 良好 |
| 推理速度 | 44-70 tok/s | 快(首字 2.4s) | 中等 |
GLM-5.1 在三个维度上建立了自己的护城河:开源可商用、长程自治能力和中文表现。如果你在做一个需要私有化部署的产品,GPT 和 Claude 直接排除。如果你是做中文为主的开发任务,GLM-5.1 的语义理解更接地气。但在复杂多文件重构这类需要深度上下文理解的场景,Claude Opus 4.6 仍然更可靠,这不是跑分能体现的,是真实开发者社区反复验证过的结论。
和国内另一热门 DeepSeek V4 Pro 相比,GLM-5.1 在生成速度和产品完成度上占优,三天实际体验中它在设计类页面的输出质量更高,代码结构也更清晰,可维护性明显更好。DeepSeek V4 Pro 在技术细节的精细度上有长处,但目前还是预览版。
用户反馈
跑分归跑分,看看真正在用的开发者怎么说。在开发者社区逛了一圈,GLM-5.1 的讨论热度不低,声音也比较多元。
开发者正面反馈集中在长程任务的完成度上,有人用它跑了一个完整的数据库迁移工程,从分析表结构到生成迁移脚本到写入测试数据,全程没有中断,这在以前的模型上很难做到。另一个高频称赞的点是价格:一位独立开发者算了笔账,之前用 Claude Opus 写代码每个月花费近 200 美元,切换到 GLM-5.1 后降到 30 美元不到,体验打了八折但价格打了二折。
吐槽的声音主要集中在三点。一个是推理速度偏慢,长篇生成时等待感明显,有的用户调侃说”写代码一时爽,等输出等到心慌”。另一个是多文件重构场景下的稳定性,有人反馈在修改一个跨 20 多个文件的项目时,模型偶尔会出现逻辑断层,不如 Claude Opus 那种“盯住上下文稳住”的能力。还有用户对高峰期 3 倍额度收费表达了不满,认为这个设计有点”薅羊毛”。
整体而言,社区对 GLM-5.1 的态度是“够用但不够完美”,对于日常 90% 的编码任务,它是 Opus 的平替甚至更好;但那 10% 的高难度场景,暂时还离不开传统的闭源旗舰。
多维评分
别人说好说坏都不如量化一下,从几个核心维度给它打个分:
| 维度 | 评分 | 一句话解读 |
|---|---|---|
| 功能完整性 | ⭐⭐⭐⭐⭐ | 长程执行+超长输出,开源模型中独一档 |
| 易用性 | ⭐⭐⭐⭐☆ | API 兼容 OpenAI,上手快但配置参数略多 |
| 性价比 | ⭐⭐⭐⭐⭐ | 输出$4.40/M,仅为 Opus 的 1/8 |
| 创新性 | ⭐⭐⭐⭐☆ | 8小时自治是突破,但思路已有前例 |
| 稳定性 | ⭐⭐⭐☆☆ | 长任务偶尔逻辑断层,高峰期体验打折 |
| 推荐度 | ⭐⭐⭐⭐☆ | 开发者必试,高难度场景仍需 Opus 兜底 |
综合评分:8.5 / 10
评分说明:功能完整性和性价比给满分没有悬念,同价位没有第二个模型能跑 8 小时工程任务。扣分项主要在稳定性和创新性上:长程任务偶尔的逻辑断层是真实存在的痛点,而 Interleave Thinking 虽然做得好,但本质上还是基于已有的“思维链+自省”框架的深度优化,算不上颠覆式创新。
优缺点
优势
-
SWE-Bench Pro 全球第一:58.4 分超越 GPT-5.4 和 Claude Opus 4.6,工程任务表现硬核 -
8 小时长程自治:无需人工干预完成复杂工程闭环,解放开发者双手 -
MIT 协议全量开源:自由商用、私有部署,企业级无后顾之忧 -
极致性价比:输出价格仅为 Claude Opus 的 1/8,适合大规模调用 -
中文能力极强:语义理解和中文代码注释质量远超海外模型
不足
-
推理速度偏慢:44-70 tok/s,长任务等待感明显 -
复杂重构不如 Opus 稳:跨文件重构偶现逻辑断层 -
本地部署门槛高:至少 8 张 H100,个人开发者负担重 -
高峰期 3 倍计费:14:00-18:00 调用成本飙升
适用人群
前面说了这么多,来看看到底谁该用谁该观望:
-
开发者/全栈工程师:这是最核心的目标人群。日常写 API、做重构、写测试,GLM-5.1 能覆盖大部分编码场景,月费远低于进口旗舰。如果你用的是 VS Code 配合 Claude Code 或其他编码工具,替换模型名就能用。 -
AI 创业团队:需要私有化部署的企业级 AI 能力又预算有限。MIT 开源协议意味着你可以直接下载权重做二次开发,不用担心 API 涨价或被商业条款卡脖子。 -
企业技术团队(政企/信创):有国产化需求、需要在华为昇腾上部署的团队,GLM-5.1 是目前最成熟的开源选项。全程国产硬件训练,合规备案齐全。 -
学术研究人员:研究 LLM Agent、长程任务规划、代码生成等领域,这个模型的开源权重提供了绝佳的研究基座。 -
不太适合的人群:对响应速度有极严苛要求的实时场景(如在线客服),以及对复杂多文件重构稳定性要求极高的团队,建议仍保留 Claude Opus 作为备选。
定价方案
东西不错,来看看钱包答不答应。
| 方式 | 价格 | 说明 |
|---|---|---|
| API 输入 | $1.40/百万 token | 标准费率 |
| API 输出 | $4.40/百万 token | 标准费率,仅为 Opus 的 1/8 |
| 编码套餐 | $10/月起 | 兼容 Claude Code / Cline 等工具 |
| 免费额度 | 2000 万 tokens | 新用户福利,有效期 3 个月 |
| 高峰期附加费 | 3 倍额度消耗 | 14:00-18:00 生效 |
GLM-5.1 的定价策略非常务实:API 输出 $4.40/百万 token,直接对标 Claude Opus 4.6 的 $34.40,便宜了近 8 倍。即便算上高峰期 3 倍计费,也只有 Opus 的一半出头。$10/月的编码套餐更是把门槛拉到了极低,一个奶茶钱就能用上顶级开源模型的能力。
但高峰期计费是个不得不提的槽点。如果你每天下午集中跑任务,额度的消耗速度会明显加快。建议把批量任务安排在非高峰期,或者搭配 GLM-5-Turbo 做轻量查询,把 5.1 留给高难度的工程任务。
常见问题
除了上面聊的这些,你可能还有些细节想搞清楚。
Q1:GLM-5.1 和 GLM-5 到底差在哪?
A1:5.1 是全面升级版,尤其编程能力提升了 30%。 编程评测从 35.4 分飙升到 45.3,Slime 强化学习框架也做了升级,长任务稳定性和纠偏能力都远超前代。可以说 5 是架构验证版,5.1 才是真正能用的版本。
Q2:它支持图像或音频输入吗?
A2:目前只支持文本输入和文本输出,不支持多模态。 这是当前版本最明显的功能空缺。如果有多模态需求,需要等后续的 GLM-5.1V 版本。
Q3:MTK 协议开源意味着什么?
A3:全量权重开放,可自由商用、修改和再分发,没有任何附加限制。 对比 GPT 和 Claude 的闭源策略,这是它最大的差异化优势。企业可以下载权重做私有化部署,不用担心 API 变更或数据泄露风险。
Q4:本地部署需要什么配置?
A4:推荐配置为 8 张 H100 或 4 张 A100,单卡显存至少 48GB。 量化版可降低硬件需求,2-bit 版约需 220GB 内存,单卡 4090(24GB)启用量化勉强可跑。华为昇腾 NPU 也支持。
Q5:GLM-5.1 的编码套餐怎么用?
A5:订阅 $10/月的编码方案后,在 Claude Code、Cline 等工具中把模型名改为 glm-5.1 即可。 体验接近使用 Claude Opus,但成本降低 10-20 倍。是目前性价比最高的编码 AI 方案。
Q6:中文支持怎么样?
A6:中文理解和生成能力目前国产开源模型中第一梯队,远超 GPT 和 Claude。 中文代码注释、技术文档撰写、对话理解等方面都有着明显优势。
Q7:高峰期 3 倍计费到底是什么规则?
A7:北京时间 14:00-18:00 期间,API 调用的 token 消耗按标准费率的 3 倍计算。 该时段跑一个长任务,实际消耗相当于非高峰期的三倍。建议把批量任务安排在晚上或早间。
Q8:它适合替代日常的 GPT 或 Claude 吗?
A8:日常编码任务完全可以,90% 场景能达到 Opus 94%-97% 的性能水平。 但高难度复杂重构、架构决策等那 10% 的场景,建议仍保留传统闭源模型作为备选。
Q9:免费的 2000 万 tokens 够用多久?
A9:取决于使用强度。日常编码和对话的话,3 个月有效期基本够用。 如果主要用于长程工程任务,可能一个月就用完。到期后按标准费率计费。
Q10:SWE-Bench Pro 58.4 分是什么水平?
A10:当前全球最高分,超过 GPT-5.4(57.5)和 Claude Opus 4.6(57.3)。 但 SWE-Bench Verified 上 GLM-5.1 为 77.8%,Opus 4.6 为 80.8%,说明在更广泛的场景下仍有差距。
最后总结
GLM-5.1 是那种“重新定义赛道标准”的产品:它证明了一个开源模型可以在真实软件工程任务上超越最顶级的闭源对手。8 小时长程自治的能力在行业里没有对手,MIT 开源协议给了企业最大的灵活性,定价又把闭源巨头的溢价砍到了脚踝。
但它不是万能的。推理速度和复杂重构的稳定性仍然是明确的短板,不支持多模态也限制了应用场景。它最适合的场景是:你需要一个能长时间自主干活、成本可控、可以私有部署的编码助手。如果你满足这些条件,GLM-5.1 大概是当下最优解。
坦白说,GLM-5.1 最让人兴奋的不是跑分,而是一个信号,开源模型在工程能力上已经追平甚至局部超越闭源旗舰。这个趋势一旦确认,未来两年的 AI 行业格局,可能真的要变一变了。