

选大模型像开盲盒?ChatGPT、Claude、Gemini 都说自己最强,到底信谁?LMArena 的玩法很直接,把你的问题丢进去,两个匿名模型同时回答,你投票选更好的那个。420 万+ 真实用户投票撑起的 Elo 排行榜,覆盖文本、代码、图像、视频 9 大能力维度。从伯克利实验室走出来的开源项目,现在估值 17 亿美元。到底值不值得信,上手投几票就知道了。
产品概述
LMArena(原名 Chatbot Arena)是一个由 UC Berkeley、UCSD 和 CMU 研究人员联合发起的众包 AI 模型评测平台。2023 年 5 月上线时只是为了比较几个开源模型的优劣,没想到三年后成长为估值 17 亿美元的行业标杆,覆盖 400+ 模型的盲测排名。
它的核心逻辑很简单:用户提问后,两个匿名模型同时生成回答,你看不到品牌标签,纯粹凭内容质量投票。这种机制直接切中了传统基准测试的死穴,MMLU、HumanEval 这类固定题库可以被”刷榜”,但真实用户的实时偏好没法伪造。
官网:https://lmarena.ai | 项目地址:https://github.com/lmarena

平台背后的 LMSYS 组织来自学界,所有评测数据、排名算法、前后端代码全部开源。2025 年注册商业化实体 Arena Intelligence 并先后完成两轮融资,a16z 和 Lightspeed 都是股东。从非营利学术项目到独角兽,这条路走得比大多数 AI 初创还要漂亮。
到底强在哪
说了一堆概念,但真正让 LMArena 出圈的是它那套评测机制。
匿名盲测对战:每次对战随机匹配两个模型,你不知道谁是谁,只看回答质量投票。这种”双盲”设计消除了品牌光环,大厂的营销预算在这里赚不到一分钱优势。
Elo 评分系统:底层用 Bradley-Terry 数学模型,根据每场对战的胜负关系动态调整分值。新模型上线后只要参加对战,排名就会实时变化,不做阶段性”刷榜”操作。
9 大能力维度:平台不只测聊天对话,细分赛道覆盖了当前 AI 的几乎所有能力方向:
| 竞技场分类 | 评测能力 | 典型场景 |
|---|---|---|
| Text Arena | 文本生成与理解 | 日常对话、写作、推理 |
| WebDev Arena | Web 开发能力 | 代码生成、项目搭建 |
| Vision Arena | 视觉理解 | 图像识别、场景分析 |
| Text-to-Image Arena | 文生图质量 | 创意设计、海报生成 |
| Image Edit Arena | 图像编辑 | 修图、风格转换 |
| Search Arena | 搜索增强 | 联网检索、信息整合 |
| Text-to-Video Arena | 文生视频 | 短视频、动态内容 |
| Image-to-Video Arena | 图转视频 | 静态图变动态短片 |
| Copilot Arena | 编程助手 | 代码补全、调试辅助 |
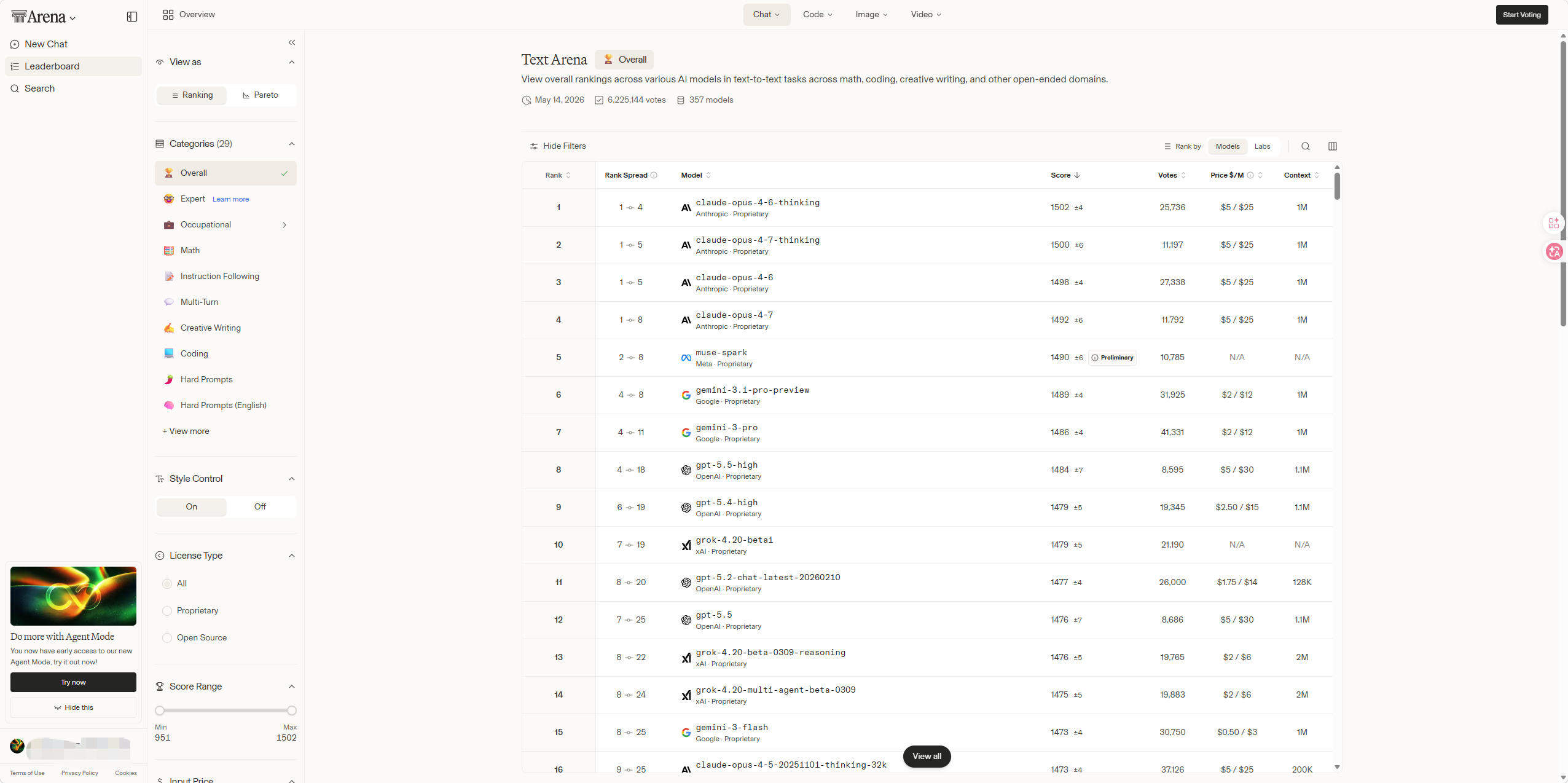
完全开源透明:从投票数据到排名算法全部公开可查,没有”黑箱操作”的空间。这也让 LMArena 成了学界和业界共同认可的参照系。
上手体验
九个竞技场听着挺多,但实际参与对战的路径比你想象中短得多。
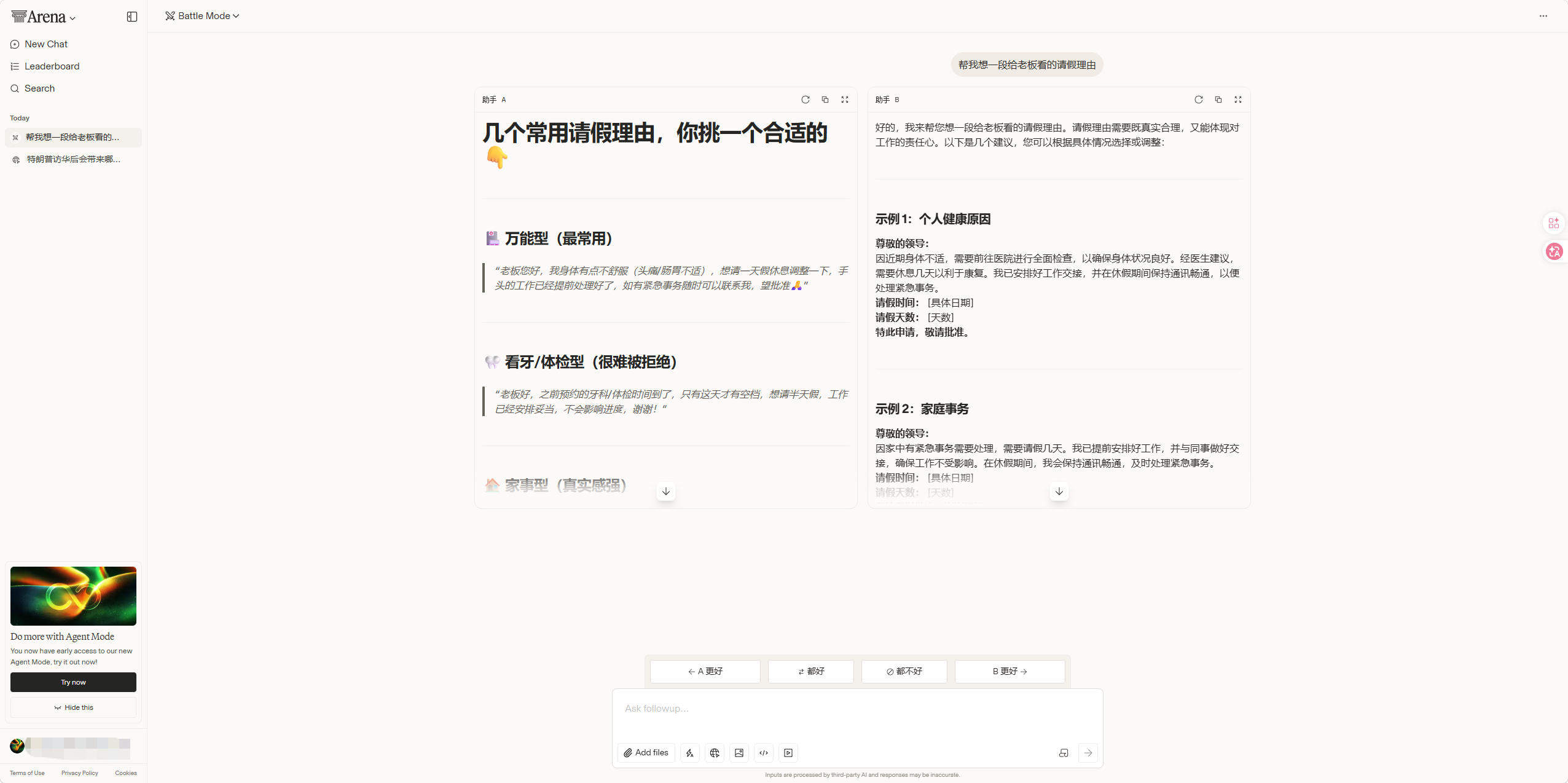
打开官网,不需要注册就能直接开始,选择 Text Arena,输入一个问题,两个匿名模型几乎同时给出回答。我试了个有点刁钻的测试:帮我想一段给老板看的请假理由。右边模型给的理由敷衍得像模板,左边那条细节到位还带着点幽默。我果断投了左边。整个过程不到两分钟。
注册账号后的体验更完整。可以用 Google 或 GitHub 账号登录,之后每次投票会被计入个人贡献。投票越多,平台的数据就越丰富,有种参与建设行业标准的感觉。
不过也有槽点。偶尔遇到模型生成卡住不动的情况,刷新页面重试通常能解决。高级数据分析需要联系销售,这说明商业化产品的门槛不低。但就核心的”盲测投票”而言,个人用户完全无门槛使用,这一点值得加分。
几个隐藏技巧
基础对战玩法大家都知道,但真正用得透的人都在用这几个进阶操作。
-
Side-by-Side 手动对比:很多人不知道可以不玩匿名对战模式。在官网切换到”直接对比”,手动选定两三个模型对同一问题输出,适合做选型调研时快速横向比较。 -
按榜单选场次:新模型上线或某类模型集中更新时,Text Arena 的对战数据会快速更新。关注这类节点去投票,你的每次选择都在影响行业排名。 -
PDF 文档联合分析:把技术文档、论文报告丢进去,选多个模型同时解析。同一份文档在不同模型眼中的摘要方式差异巨大,这个功能对比 LLM 的阅读理解能力特别直观。 -
追踪 Copilot Arena:如果你关心代码助手的选择,Copilot Arena 专门测编程辅助工具(GitHub Copilot、Cursor、Windsurf 等)。对程序员来说,这是比任何跑分都更有说服力的参考。
和同类比怎么样
模型评测赛道玩家不少,但各家玩法和侧重点完全不同。
| 对比维度 | LMArena | Hugging Face | 智谱AI开放平台 | Poe |
|---|---|---|---|---|
| 核心机制 | 匿名盲测+Elo排名 | 标准化基准测试 | 平台内对比报告 | 多模型切换体验 |
| 排名透明度 | 完全开源 | 自动化打分 | 企业级不公开 | 无正式排名 |
| 中文评测覆盖 | 有限 | 弱 | 强 | 中等 |
| 社区参与度 | 极高(投票驱动) | 高(模型提交) | 低(企业导向) | 中(用户创建bot) |
| 是否免费 | 免费 | 基础免费 | API 按量计费 | 基础免费 |
LMArena 最大的护城河是它的匿名盲测机制,这是 Hugging Face 的自动化基准和 Poe 的轻量体验都做不到的差异化。智谱的评测更偏向中国本土场景,但缺乏开放数据让外界验证公信力。如果论”谁说真话”,LMArena 的投票数据比任何一家都更有底气。
真实用户怎么说
去 G2 和社群逛了一圈,用户对 LMArena 的态度有赞有弹。
认可的一方主要集中在盲测机制的公信力上,“这是目前唯一一个不受厂商营销影响的榜单”、“做模型选型调研时,LMArena 的排名比任何博客评测都靠谱”。连 Andrej Karpathy 都公开推荐过,说明它在技术圈的地位确实不低。
吐槽的声音也不小。有研究发现大厂模型在对战中出现的频率超过 34%,导致数据分布偏向头部公司。还有人指出 Meta 测试了 27 个版本的 Llama 4 才提交一个参加公开排名,这种操作本质上是在”刷榜”。部分中文用户反馈中文场景对战的样本量太少,榜单对中国模型的参考价值有限。
总体来看,LMArena 的盲测机制是它最硬的底牌,但远非完美。把它当作唯一红宝书来用,可能会吃大厂的暗亏。
多维评分
反馈看了一堆,从六个核心维度给 LMArena 打个量化分。
| 维度 | 评分 | 一句话解读 |
|---|---|---|
| 功能完整性 | ⭐⭐⭐⭐☆ | 9 大竞技场覆盖全面,但缺深度专项测试 |
| 易用性 | ⭐⭐⭐⭐⭐ | 不用注册直接玩,两分钟能投一票 |
| 性价比 | ⭐⭐⭐⭐⭐ | 个人用户完全免费,开源数据毫无保留 |
| 创新性 | ⭐⭐⭐⭐⭐ | 匿名盲测真实人类偏好,刷新了评测范式 |
| 稳定性 | ⭐⭐⭐☆☆ | 偶有卡顿报错,大规模并发时响应慢 |
| 推荐度 | ⭐⭐⭐⭐☆ | AI 从业者必看,普通用户当参考即可 |
综合评分:7.8 / 10
LMArena 在产品设计上足够聪明,免费策略和开源透明让它快速积累了公信力。扣分主要扣在数据分布的偏差和稳定性上,如果哪天它能平衡中小模型的出场率,分数还能往上走。
优点和槽点
优势
-
匿名盲测消除品牌偏见:不看品牌纯凭回答质量投票,这是它最大的护城河 -
覆盖模型种类全:400+ 模型横跨文本、代码、图像、视频,一站搞定选型调研 -
完全免费且开源:个人用户零门槛,数据算法全部公开可查验 -
社区参与感强:你的每次投票都在影响行业排名,这种共建感是其他平台做不到的
不足
-
数据分布偏头:大厂模型出现频率过高,中小模型在榜单上吃亏 -
可被针对性优化:允许厂商反复测试后提交最佳版本,存在”刷榜”空间 -
中文场景评测不足:中文对战样本量有限,对中国模型的排名参考价值打折扣 -
偶发稳定性问题:生成卡顿或报错影响体验,高峰时段响应较慢
适合谁用
了解完优缺点之后,来对号入座。
-
AI 研究者和算法工程师:LMArena 的 Elo 排名和开源数据是论文和选型时最硬的参照物,比任何官方宣称都可信 -
企业技术选型团队:在做模型采购或 API 接入决策时,LMArena 的盲测数据可以交叉验证厂商的 PPT 内容 -
AI 发烧友和普通用户:想体验各模型能力差异,两分钟投一票就能参与,比读几百页评测报告直观得多 -
模型开发者和AI初创公司:想知道自家模型在同类中排什么位置,LMArena 是公开透明的”体检中心” -
希望避免盲目跟风的人:如果你不信厂商宣传又不想自己逐一测试,LMArena 的众包排名是最折中的选择
价格贵不贵
产品和人群对上了,来看看预算。
| 版本 | 价格 | 核心权益 | 限制 |
|---|---|---|---|
| 免费版 | $0 | 参与盲测对战、查看所有排行榜、访问开源数据 | 无商业级分析功能 |
| AI Evaluations | 企业定制 | API/SDK 嵌入生产环境评测、定制化报告 | 需联系销售报价 |
核心对战和排名功能对个人完全免费,这跟 LMArena 的学术基因一脉相承,它本来就不是为了卖工具,而是让整个行业有一个透明的参照系。
商业化产品 AI Evaluations 的年经常性收入已达 3000 万美元,主要服务需要将模型评测嵌入生产流程的 B 端客户。对于大部分个人用户来说,免费版的功能已经足够。
常见问题
Q1:LMArena 和常规基准测试有什么区别?
A1:LMArena 衡量的是真实用户偏好,而非固定题库得分。 传统基准如 MMLU 用标准化试题打分,可以被针对性训练。而 LMArena 让真实用户在实践中匿名投票,反映的是模型在实际对话中的表现。
Q2:参与对战需要注册吗?
A2:不需要注册也能投票。 访问 lmarena.ai 直接输入问题即可参与。但如果要查看个人投票历史或持续追踪某类模型的表现,推荐用 Google 或 GitHub 账号登录。
Q3:排行榜多久更新一次?
A3:排行榜实时更新。 每有一场新的对战投票完成,Elo 评分就会重新计算。新模型上线后只要参与对战,排名变化几乎立即可见。
Q4:LMArena 有中文版吗?
A4:官网支持中文界面,但中文对战样本量有限。 这意味着中文模型的排名稳定性不如英文模型高,中国用户参考时需要留意这一偏差。
Q5:排名会被厂商操控吗?
A5:不无可能。 虽然匿名机制消除了品牌偏见,但厂商可以在内部多次测试后只提交最佳版本参与公开对战,这种做法在本质上就是优化排名。
Q6:我能拿 LMArena 的评测数据做研究吗?
A6:完全没问题。 所有投票数据、提示词、排名算法全部开源,任何人都可以下载用于学术研究或商业分析。
Q7:LMArena 支持哪些模型的评测?
A7:目前已覆盖 400+ 模型。 包括 ChatGPT、Claude、Gemini、Llama、DeepSeek、Qwen 等主流商业和开源模型,以及大量新锐模型的早期版本。
Q8:AI Evaluations 商业化产品做什么的?
A8:将盲测评测能力打包成 API 和 SDK 嵌入企业生产流程。 适合需要持续监控模型质量的大规模 AI 应用场景,定价按企业定制方案执行。
Q9:LMArena 和 ChatGPT 有什么关系?
A9:没有直接关系。 LMArena 是一个独立的中立评测平台,不隶属于任何模型厂商。ChatGPT 只是平台上被评测的 400+ 模型之一。
Q10:在 LMArena 上哪个模型目前排第一?
A10:排名会实时变动。 建议直接访问 lmarena.ai 查看最新 Elo 排名。不同竞技场的 top 模型可能完全不同,选你关注的赛道去查最准确。
最后的结论
LMArena 提供了一个独特的视角:不看品牌、不认背景,纯粹让真实用户的偏好决定模型排位。对于 AI 从业者,它是做选型调研时最有温度的参考系。
对于普通用户,花两分钟投一票,你就参与了定义行业标准的过程。但它不是圣经,数据分布偏差、可被优化、中文覆盖不足,都是读榜时必须戴上的眼镜。建议先上手玩几轮,再结合自有场景交叉验证,别让任何一张排行榜替你做最终决策。