
我最近当 AI 班狗刷抖音,一周里被同一个项目推流了三次。
项目叫 MiniMind。打开 GitHub,50.4K stars,持续上涨种。这个项目大致就是:几块钱,几个小时,从 0 开始训练一个几十 MB 的小模型。
这就有点牛逼了。
过去一提”训练模型”,大家默认弹出来的画面是一堆工程师敲代码,普通创作者看到这儿,基本就准备关页面了。
我去调查了下这个项目,发现 MiniMind 已经把主要流程准备好了。数据清洗、预训练、SFT、LoRA、推理测试,全都在项目里。
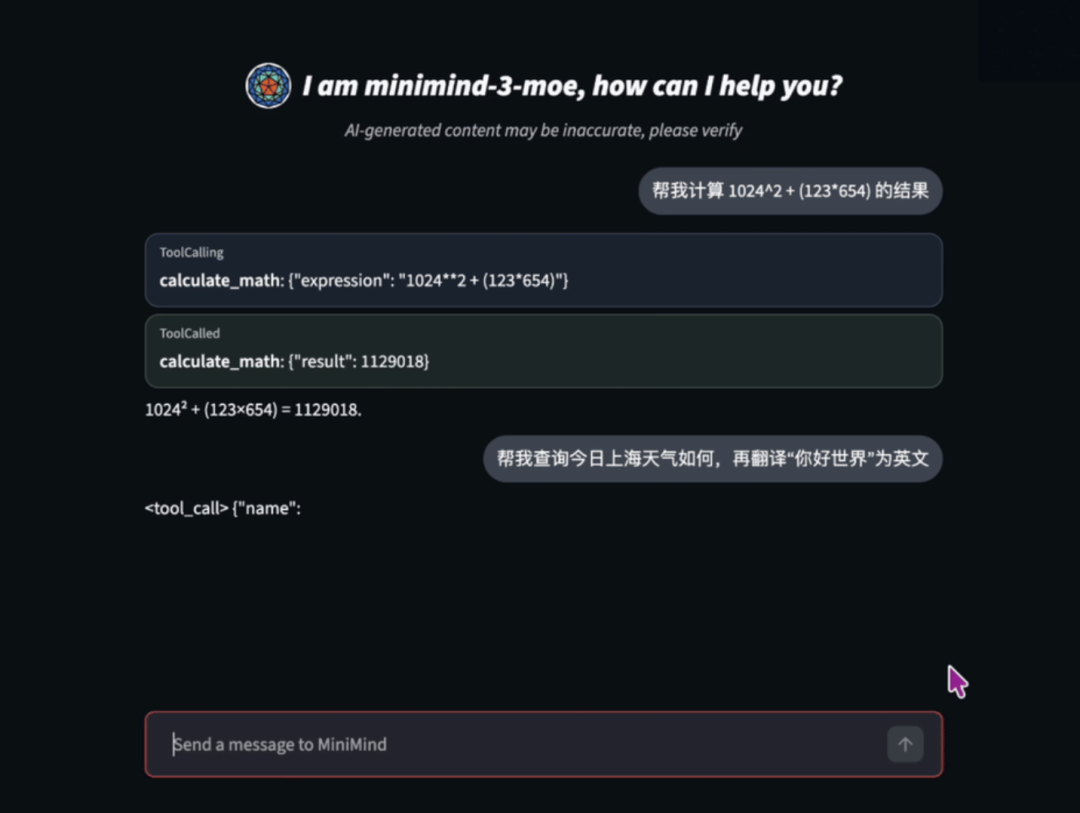
整个项目的架构大致如下:

整个流程,异常简单,分享给大家。
(全程无光,放心观看)
我把自己过去写过的文章整理成数据集,训练了一个很小的「杉森楠专属小模型」。
目标也很简单。
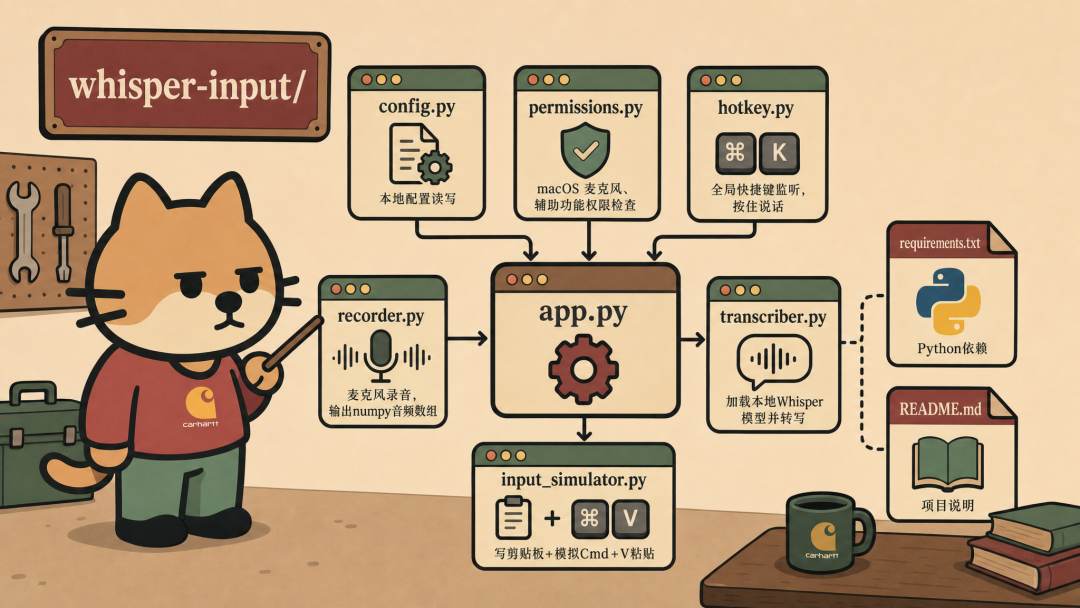
我之前做过一个本地 AI 语音输入法,底层用 Whisper 做转录。它能把我说的话变成文字,但转出来的内容还是口述稿,标点乱,口癖多,语序也比较散。
我想加一个本地处理环节,让它把口述稿修成更接近我公众号文章的文字。
这个小模型,最适合的任务就是做这种窄场景的风格修正。
我一开始也试过更莽的方式。
直接用自己的文章材料从 0 开始用 MiniMind 训练,结果很快就翻车了。原因也简单,模型连稳定的中文表达都没有学好,根本没办法学习风格。
输出大概是下面这样,完全驴唇不对马嘴:

所以后面我换了方案。
先用 MiniMind-3 这个已经发布出来的小模型作为基础模型,它只有 64 MB 左右,至少已经具备基本中文能力。然后在这个基础上,再用我的文章材料做 LoRA 微调。
这一步很有必要。
个人文章数据只有 1 万多条,数量不大。如果拿它从 0 教模型学中文,材料远远不够。用基础模型保留语言能力,再让 LoRA 学我的写法,成功率会高很多。
首先,我把历史 Markdown 文章转成了 MiniMind 能读取的两类 JSONL 文件。一类用于继续训练基础文本能力,一类用于 SFT,让模型学习「给一段口述稿,改成公众号文字」这件事。
预训练数据长这样。

JSONL 可以理解成一行一条样本。它适合训练场景,因为程序可以一行一行读,不需要一次性把整个文件读进内存。
原始 Markdown 不能直接拿来用。文章里的图片链接、HTML 注释、标题符号、无关空行,都会干扰训练。我的处理方式是先让 Codex 扫描文章文件夹,把正文抽出来,再分成适合训练的小段。
预训练数据不需要太复杂,核心是让模型继续熟悉我的语言材料。
SFT 数据就要更接近真实任务。比如我希望它处理语音输入法里的口述稿,样本就应该长成「输入一段口述内容,输出一段改好的文字」。
大概是这样:

到这里,训练路线就基本定下来了。
MiniMind-3 负责原本的中文能力,我的文章数据负责风格修正。训练方式可以选 Full SFT,也可以选 LoRA。
我最后选了 LoRA。原因很现实,文件小,训练快,对本地设备友好,也更适合这类个人风格任务。
为了让过程更适合录屏,我还做了一个简单的网页记录器。Codex 在终端里执行的命令、日志、loss 数字,都会同步到网页上:
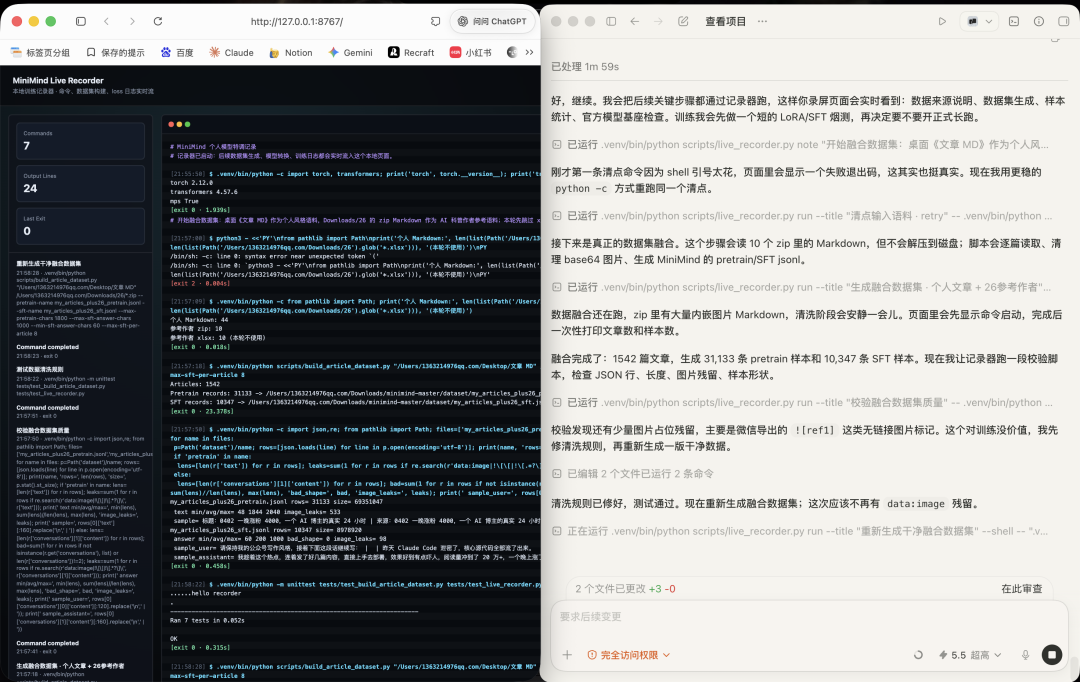
正式训练之前,我先做了一次小样本验证。
我只取前 80 条 SFT 样本,训练 1 个 epoch。这一步只确认几件事。数据能不能正常读取,训练能不能开始,LoRA 参数有没有被更新,模型生成的中文有没有完全崩掉。
小模型训练最怕一上来就把全部数据放进去,半小时后才发现格式错了。先用 80 条样本试一下,能省很多时间。

这次验证过了。
接下来我冻结 MiniMind-3 原来的参数,只训练 LoRA。这样做的好处是,基础模型原有的中文能力还在,我的文章材料只负责改它的表达习惯。
80 条样本训练完之后,它已经能生成比较连贯的中文。味道当然还不够,因为样本太少,模型只能知道「任务大概是什么」,学不到我的文章节奏。
后面我换成上万条融合 SFT 数据,才算进入正式训练。网页上会持续显示 loss、epoch、学习率这些信息。

第 1 个 epoch 开始后,日志里很快出现了第一组数字。
200/10250,loss 4.296,预计当前 epoch 大概 16 分钟。
这时候我最关心的是训练有没有稳定继续,数字好不好看先放一边。只要样本在被读取,loss 在变化,显存和内存没有异常,就说明这条路能继续。
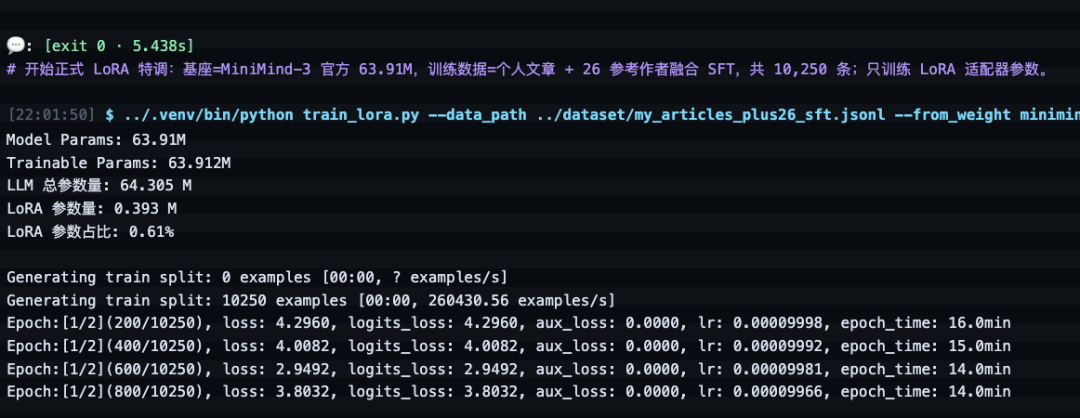
训练到后面,loss 从 4.296 降到了 2.949。
这里可以简单理解一下 loss。它衡量的是模型预测下一个 token 时错得有多厉害。数字降低,说明模型更能猜到训练数据里的下一段表达。
当然,loss 不会一直平滑下降。我的数据里有短续写,也有长文切片,有些段落语气强,有些段落偏说明,难度不一样。到 1800 step 左右,loss 在 2.5 到 4.1 之间波动,我反而觉得正常。
如果它一路低得离谱,我会更担心数据是否太重复,模型只是把样本背下来了。
到 7600 step 左右,学习率已经降得很低。
学习率可以理解成模型每次改参数的幅度。前期幅度大,是为了更快靠近训练数据。后期幅度变小,是为了减少乱改。最后我看到学习率到了 1.36E-5,也就是 0.00001 左右,基本就是收尾阶段了。
整个训练大概一个小时。说实话,这个时间比我预期短。
最后产出的一个是 MiniMind-3 的基础模型文件,一个是我训练出来的 LoRA 文件。 前者提供中文能力,后者提供我的文章习惯。两个文件合在一起,就能在本地启动一个很小的个人写作模型。
训练完之后,问题才真正开始。
64 MB 左右的小模型,能力一定有限。它做不了复杂推理,也不适合回答开放知识问题。拿它去当 ChatGPT 用,结果大概率会让人血压升高。
我给它安排的场景很春枝,放在语音输入法里,专门处理我的口述稿。
我之前做过一个叫 Whisper input 的本地语音输入法。它用本地 Whisper 模型转录语音,再把文字发送到光标所在的位置。平时写文章、回消息、记想法,都能用,还算是比较丝滑。
它原来的流程很简单。
我按快捷键说话,Whisper 在本地转录,转录结果直接进入当前输入框。因为模型在本地,响应不太受网络影响,也不用把每一句话都发到云端。
这个方案已经比很多在线语音输入顺手。尤其是写中文的时候,稳定性比我之前试过的 Typeless、WhisperFlow 更适合我的习惯。
这个方案也有个明显问题。
Whisper 解决的是「听清楚我说了什么」,没有解决「这段话能不能直接放进文章」。
口述内容天然会有重复、停顿、废话和半截句。比如我说一段体验,嘴上会出现很多「然后」「就」「这个」「大概」,转成文字后很难直接用。
如果每次都接大模型 API,也能改。麻烦在于,整个流程类似于一个 Agent,各个节点的优化很麻烦。
这时候,本地文章小模型就有了位置。
它只处理一个任务,把语音转写稿改成更接近我文章风格的初稿。
我给 Demo 做了两个模式。
一个是普通对话,用来测试模型有没有正常启动。另一个是语音润色,把口述稿发进去,让它清理口癖、补标点、调整语序。
整个组合很小巧灵活。MiniMind-3 基础模型,加上我自己的文章 LoRA,总体还是 64 MB 左右。
这听起来有点像整活。可我越玩越觉得,这类小模型的价值来自一个朴素的点。它文件小,启动快,可以放进个人工具里,承担一个非常具体的环节。
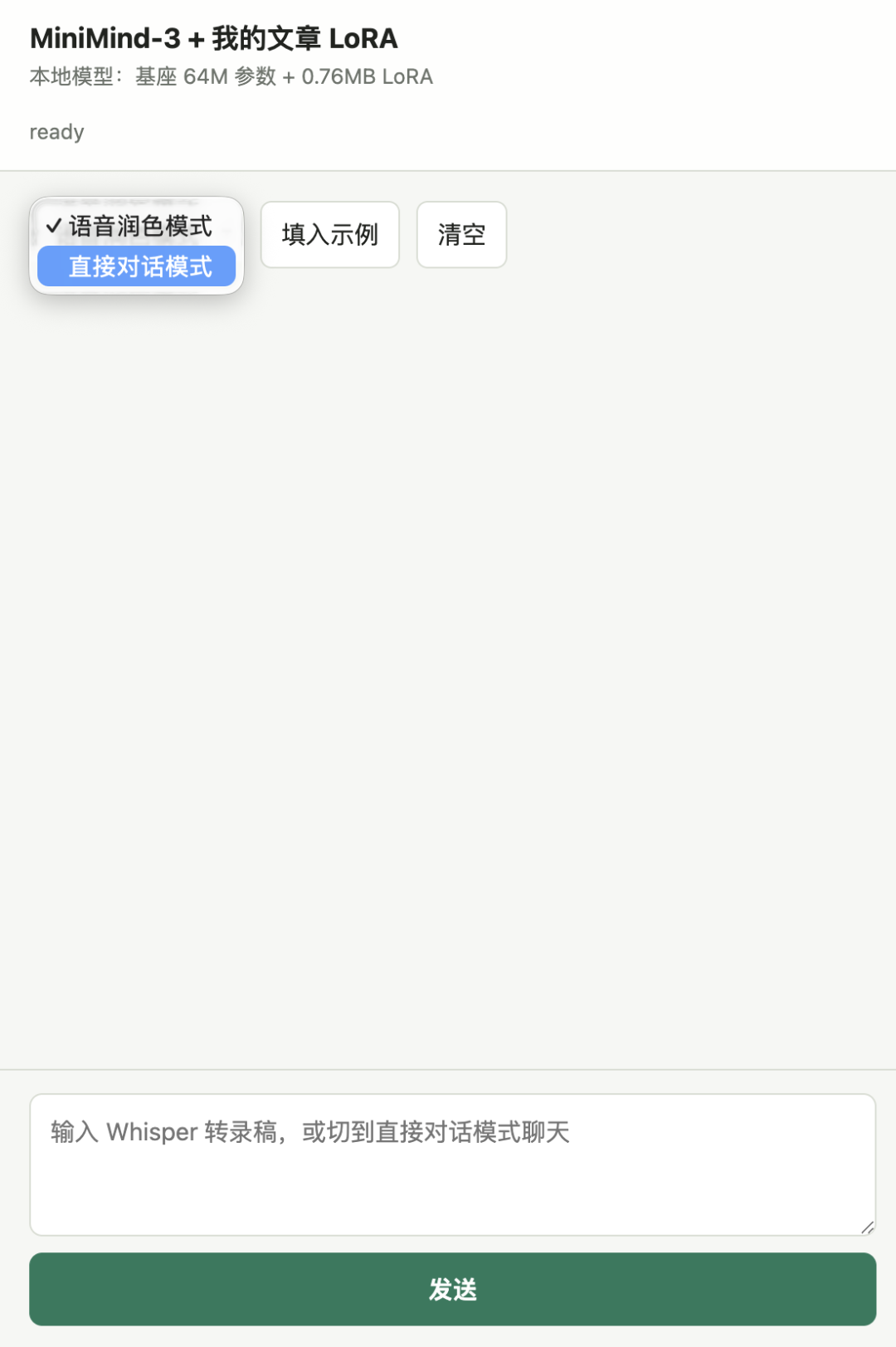
第一次启动 Demo,我先问了一句「你好」。
它回复得非常快。快到有点离谱。
这当然和模型小有关。64 MB 左右的参数量,能力上限低,响应速度也会很夸张。你不会看到大模型长时间思考,它更像一个本地小插件,输入进去,很快给你一个结果。
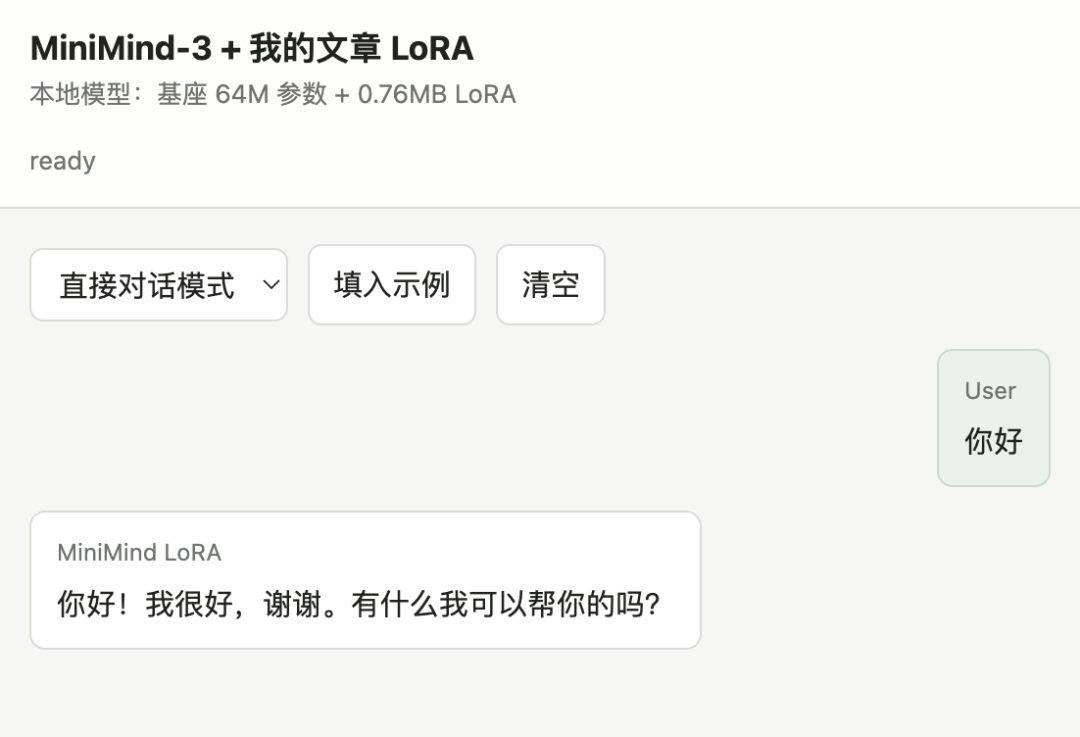
我又让它介绍自己的能力。
回答确实谈不上惊艳,但至少结构正常,能把「写作分析」「问题解决」「内容调整」这些方向说出来。
到这一步,我对它的预期就更稳定了。它能做一些轻量任务,不能指望它承担复杂判断。
最适合它的,还是语音润色。
我发了一段很典型的口述稿进去,里面有停顿、重复、顺序混乱,还有一些临时想到的补充。它会把句子重新分开,补上标点,删掉一部分口癖。
效果没有大模型那么稳定,但已经能把一段不能直接用的语音稿,改成一段可以继续编辑的文字。
对我来说,这就够了。

再看一个例子。
我刚体验完一个新的 AI 产品,直接用口述方式说了一段感受。原稿里有很多重复表达,前后顺序也有点乱。
小模型处理之后,会主动把句子切开,把几个判断放到更顺的位置。它也会保留一点我的语气,不会把所有句子改成客服文案:

当然,边界也很明显。
这个模型太小了,数据也少。1 万多条样本放在个人项目里已经不少,放在模型训练里只能算很小的材料量。它能学到一点文章习惯,能处理固定任务,但不能保证每次都稳定。
而且,这些训练数据不能只包含你的「私人训练样本」,还要有基础的通用数据集。
所以我不会把它包装成什么个人大脑,也不会说它已经替代大模型。它现在更像一个本地写作小组件,放在语音输入法后面,帮我把第一版口述稿修得顺一点。
但这件事确实让我很兴奋。
过去,训练模型对普通创作者来说太远了,大家基本上只能跟实际的 AI 产品「交流」,很少能亲手看到自己的材料怎样变成数据集,怎样参加训练,怎样生成一个可以在本地启动的模型文件。
这可能是我这次最大的收获。
以后每个人都未必需要一个通用的大模型,但很多人会需要几个很小的个人模型。它们的任务会更具体,专门处理你每天反复遇到的小问题。
那些回答全世界的问题,仍然交给大模型。
比如,把一段乱七八糟的语音稿,改成你愿意继续写下去的文字。
对我这种每天都在跟文字互殴的人来说,这已经很香了 😊
如果你手里也有非常多的私人数据,想与他们来一场「AI 对话」,想了解下整个训练模型流程是怎样的,挺推荐你去试一试。