

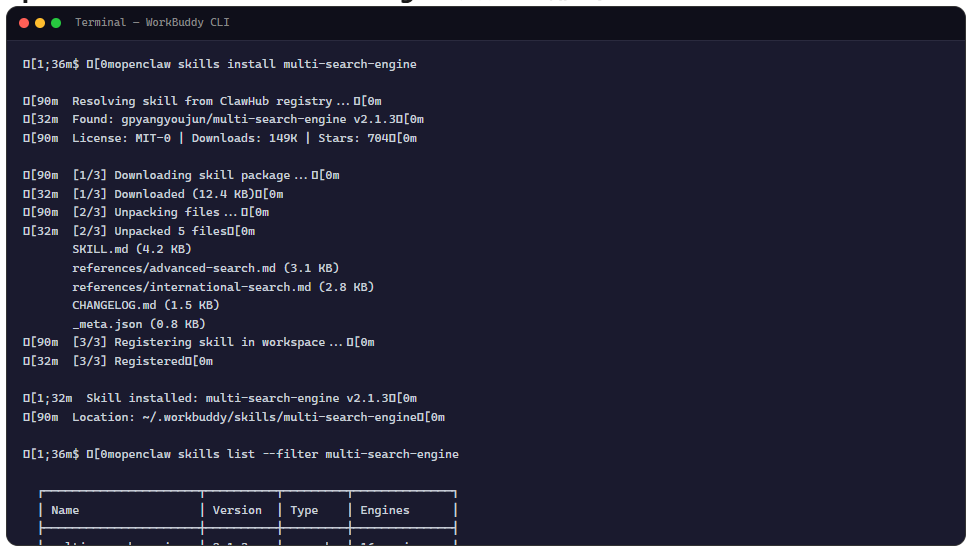
做调研的时候最烦的一件事,就是换个搜索引擎就要重新配一套 API key。Google 要密钥,Bing 要密钥,DuckDuckGo 虽然不要但也要折腾接口。一个搜索任务来回切三四套配置,还没开始查资料就先被配置卡住了
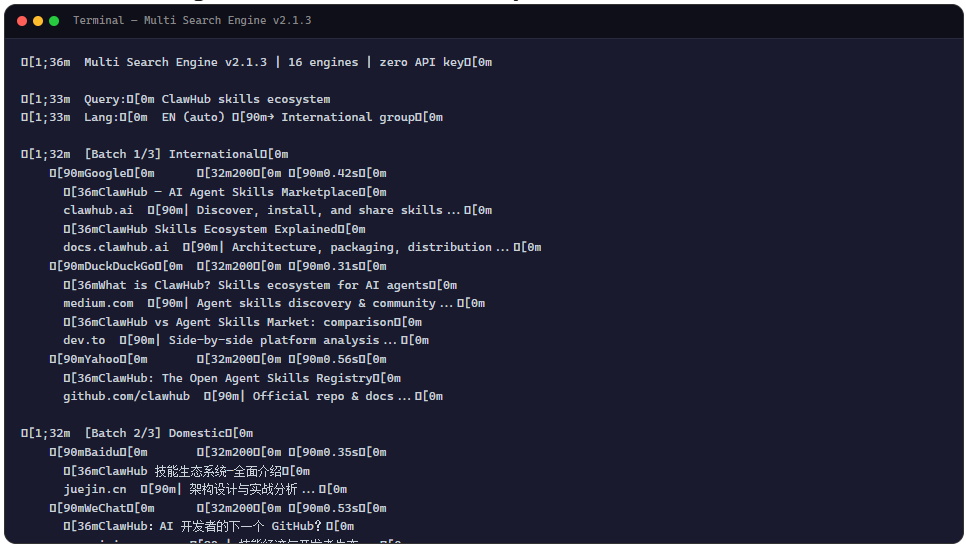
前几天在 ClawHub 翻到一个叫 Multi Search Engine 的 Skill,作者是 g_pyAng,下载量 149k,Star 数 704。看了一眼介绍,说它集成了 16 个搜索引擎,而且不需要任何 API 密钥。这说法听起来有点反直觉,搜索引擎不给 API key 怎么查?抱着”看看它怎么做到的”的心态翻了文档,发现它的思路比我想象中直接得多。
说白了这篇文章就想讲明白一件事:这个 Skill 是怎么做到零 API 成本完成多引擎聚合搜索的,以及它的设计里有哪些值得注意的细节和取舍。如果你也在搭需要搜索能力的 Agent Workflow,可以拿它当个参考。
环境准备
使用这个 Skill 的门槛出乎意料地低。它跑在 OpenClaw 环境里,所以前提是已经装好了 OpenClaw CLI。除此之外不需要注册任何搜索服务的开发者账号,不需要申请 API key,也不需要配置环境变量。这点和绝大部分搜索类工具都不一样,很多方案光是密钥申请流程就能劝退一半人。
安装命令只有一行:
openclaw skills install multi-search-engine
装完之后不需要额外配置。它不读 config.json 里的密钥字段,也不依赖外部服务的认证流程。从文档说明来看,它直接用标准搜索 URL 加网页抓取的方式获取结果,绕过了整个 API 体系。这种设计在”零配置”上做到了极致,但也意味着它的工作方式和传统搜索 API 完全不同。
有个细节值得注意。因为本质上是通过网页抓取获取搜索结果,所以它的稳定性和搜索引擎的页面结构强相关。如果某个引擎改版了结果页布局,可能会影响抓取效果。作者提到了这个风险,但目前 149k 的下载量说明它在大部分场景下是可靠的。
操作流程
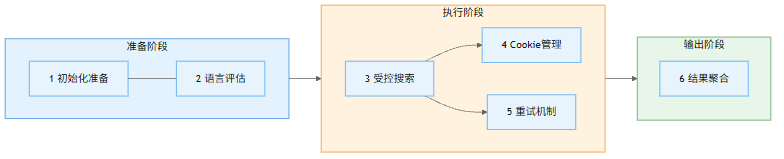
这个 Skill 的核心工作流可以分为六个阶段:初始化准备、语言评估、受控搜索、Cookie 管理、失败重试、结果聚合。听起来步骤不少,但实际运行时是自动完成的,用户侧只需要发起一个搜索请求。
初始化阶段会创建一个内存级的 Cookie 存储。这里的设计很有意思,它不持久化到磁盘,也不从配置文件加载预置 Cookie,而是完全在运行时维护。我一开始以为这是为了简化配置,后来看文档才明白真正的原因:搜索引擎对自动化抓取通常会做访问控制,403 或 429 错误时往往是因为缺少有效的会话 Cookie。这个 Skill 的策略是”按需获取”,搜索失败时才去引擎首页拉取会话 Cookie,而不是一开始就拿着一套可能过期的 Cookie 去撞。
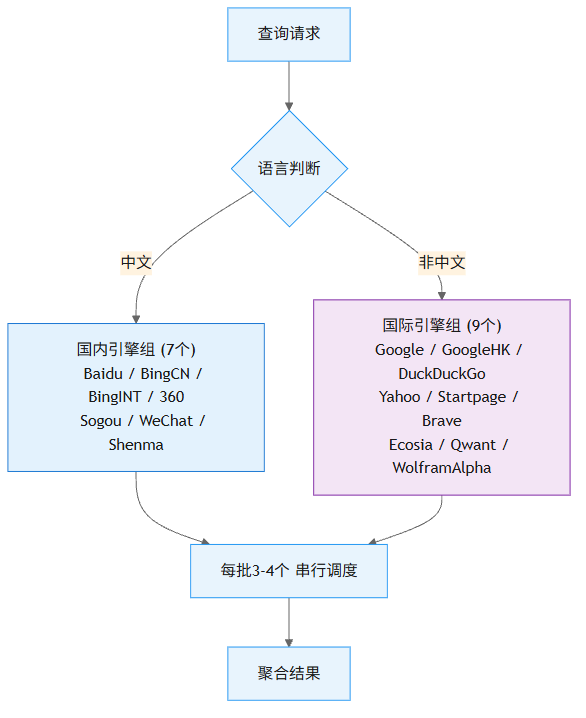
语言评估阶段会判断查询语句的语言属性。如果是中文,优先调用国内引擎组,包括百度、必应中国版、必应国际版、360、搜狗、微信搜索和神马。如果是非中文查询,则切到国际引擎组,包括 Google、Google 香港版、DuckDuckGo、Yahoo、Startpage、Brave、Ecosia、Qwant 和 WolframAlpha。这个自动路由的逻辑对中文用户很友好,不用手动指定引擎,也不用纠结”查中文用百度还是 Google”这种问题。
搜索执行阶段有一些工程细节。请求间隔控制在 1 到 2 秒,模拟人类搜索行为避免触发反爬。每批并行调用 3 到 4 个引擎,批次之间串行执行。携带标准浏览器的 User-Agent,遇到 403 或 429 时自动获取 Cookie 并重试一次。这些限流和容错策略说明作者对搜索引擎的反爬机制有实际了解,不是简单的”发请求拿结果”。
关键设计
Multi Search Engine 的设计里有几个我觉得值得单独说的决策点。
第一个是”全内存运行、零持久化”的架构。Cookie 不写入文件,会话结束后立即清除,只捕获搜索引擎域的会话 Cookie。从隐私角度看这很干净,不收集用户信息,不落地任何数据。从工程角度看也减少了配置复杂度,用户不需要管理 Cookie 文件的有效期。代价是每次运行都需要重新建立会话,但作者通过”按需获取”和”单次重试”机制把这个开销控制在了可接受范围。
第二个是 16 个引擎的编排策略。不是所有引擎同时请求,而是按语言分组、按批次限流。我一开始想,16 个引擎全开是不是太慢了?但仔细看了调度逻辑后发现它的批次设计很聪明:国内和国际分开,每批 3 到 4 个并行,既保证了覆盖度又控制了并发压力。如果某个引擎挂了,其他引擎的结果还能兜底,不会因为单点失败导致整次搜索作废。
第三个是高级搜索运算符的完整支持。site: 站内搜索、filetype: 文件类型过滤、精确匹配引号、排除词减号、OR 逻辑运算符,这些在传统搜索引擎里常用的语法它都支持。还支持时间过滤参数 tbs=qdr:,可以限定过去一小时、一天、一周、一个月或一年的结果。对做调研的人来说,这几个功能基本覆盖了日常搜索的绝大部分精细化需求。
不过也有明显的取舍。它不支持搜索引擎的个性化结果,因为不登录账号。也不支持需要身份认证的搜索场景,比如某些学术数据库。另外,由于依赖页面抓取,如果搜索引擎返回的是 JavaScript 动态渲染的结果页,抓取可能会失效。作者在文档里坦诚地提到了这些边界,没有夸大覆盖范围。
使用场景
Multi Search Engine 最擅长的场景是”快速跨引擎信息收集”。比如做竞品调研时需要同时看中文媒体和英文讨论,以前要分别在百度和 Google 搜一遍,现在一个请求就能覆盖两边。再比如查技术文档时想确认某个问题的解决方案在中文社区和 Stack Overflow 上的差异,用它也能一次性拿到多源结果。
另一个实用场景是隐私敏感搜索。它支持 DuckDuckGo、Startpage、Brave、Qwant 这几个隐私导向的引擎,不需要通过这些引擎的 API 接口,直接走网页搜索路径就能拿到无追踪的结果。对不想留下搜索痕迹的场景,这比登录隐私引擎的账号更方便。
WolframAlpha 的集成也扩展了它的能力边界。做数据查询时可以直接用自然语言提问,比如货币转换、数学计算、股票信息、天气查询,结果以结构化数据返回而不是网页链接。这部分相当于在搜索引擎之外叠加了一个知识计算层。
但它不是万能药。对实时性要求极高的场景,比如股价秒级刷新或新闻推送,网页抓取的延迟和频率限制会成为瓶颈。对需要深度定制搜索算法的场景,比如语义相似度排序或向量检索,它的能力也有限。这些场景还是需要专门的 API 或自建索引。
洞察与反思
Multi Search Engine 的设计思路其实反映了一个更广泛的取舍:在”零配置、低成本、广覆盖”和”高性能、强定制、深度集成”之间,它选择了前者。这不是技术能力不足,而是产品定位的刻意选择。149k 下载量说明这个定位切中了大量用户的痛点,很多人需要的不是最强的搜索能力,而是”能搜、够用、不用折腾”的搜索能力。
从 Skill 设计的角度,它的隐私处理值得借鉴。内存级 Cookie、按需获取、不持久化,这三条规则把数据收集降到了最低。在越来越多的 AI 工具需要读取用户数据的背景下,这种”最小权限”的设计反而成了差异化优势。
两种方案在核心维度上的差异很明显:
| 维度 | 传统搜索 API | Multi Search Engine |
|---|---|---|
| 成本 | 按调用量付费 | 完全免费 |
| 配置 | 申请密钥 + 参数调优 | 一行命令安装 |
| 覆盖 | 单引擎深度检索 | 16 引擎聚合 |
| 稳定 | 官方 SLA 保障 | 依赖页面结构 |
从成本角度看,Multi Search Engine 的优势一目了然。但从长期运营角度看,官方 API 的稳定性承诺是企业级场景更看重的因素。
不过我也有些顾虑。网页抓取本质上是在搜索引擎的服务条款边缘游走。虽然作者做了限流和合规处理,但长期来看,如果主流搜索引擎收紧对自动化访问的限制,这个方案的可持续性会受挑战。
API 方案虽然要花钱、要配置,但至少是在官方支持的通道内运行。这个 Skill 更像是一种”务实的 workaround”,而不是长期的架构方向。短期用非常香,长期看可能需要准备 Plan B。
资源地址:https://clawhub.ai/gpyangyoujun/multi-search-engine
总结
Multi Search Engine 的核心价值是”零成本、零配置、多引擎聚合”。它不追求搜索能力的上限,而是把”快速获取多源搜索结果”这件事的门槛降到了最低。对于不想管理 API 密钥、不想研究每个搜索引擎接口文档、只想快速拿到结果的用户来说,这个 Skill 是个非常务实的选择。
如果你正在搭建需要搜索能力的 Agent,可以先拿它跑通流程,验证搜索需求的真实性和频率。等业务量上来、对搜索质量有更高要求的时候,再逐步迁移到专用 API 或自建检索系统。它不是终点,但很可能是最合适的起点。
FAQ 常见问题
Q: 这个 Skill 适合什么人? A: 不想折腾 API 密钥、需要快速聚合多引擎搜索结果的人。做调研、查资料、验证信息源的适用度最高。
Q: 和传统搜索 API 比有什么优缺点? A: 优点是完全免费、无需配置、开箱即用。缺点是依赖页面抓取所以稳定性不如官方 API,也不支持个性化结果和深度定制。
Q: 最大的缺点是什么? A: 长期可持续性存疑。如果搜索引擎收紧反爬策略,网页抓取方案可能会失效。另外对实时性要求高的场景延迟较大。
Q: 16 个引擎会全部请求吗? A: 不会。按查询语言分组,每批并行 3 到 4 个引擎,批次间串行。这样既保证覆盖又控制并发压力。