

面向 AI 时代,软件研发正在经历一场深刻的范式跃迁:传统 SDLC 的每一个环节都以人为核心驱动力——需求靠人拆解、代码靠人编写、构建靠人触发、故障靠人修复;而 Agentic Coding 的兴起,让代码生成从辅助补全进化为端到端的自主交付,彻底改写了”人力规模决定产能上限”的旧范式,小型 Demo 已可在分钟级交付;然而当我们把视角切换到超级应用的复杂工程——数亿用户、数百万行代码、数十团队协同——一个深刻的悖论浮现:AI 越写越快,系统却越来越乱,整体研发效率并未发生质变。
根源在于三道鸿沟:工业级质量成本高、无约束生成导致系统熵增失控、多方协作中人的沟通仍是最大瓶颈。为了实现从”AI 辅助写代码”到”AI 自主工业级交付”的跨越,本系列将带你走进 “超级应用的 AI 原生研发模式探索”的背后,看我们如何逐一击破三大挑战(能力底座 → 抗熵架构 → 生产线跃迁):
第一期 | 工业级能力底座:AI-Native 的端云一体基建
AI 要产出工业级代码,前提是有工业级基础设施可发现、可理解、可调用。我们将端云基建从”人类可用”升级为”AI 语义友好”,围绕八大关键能力通过 Skill/MCP 协议暴露给任意 Agent,配合三维评测闭环,让 AI 在已验证的工业级组件上”即插即用”。
第二期 | Spec as AIOS:AI-Native 全栈交付的抗熵架构
有了底座还需”操作系统”统治一致性。当多元 Agent 并行生成时,无约束产出以指数级引入系统熵。我们借鉴 Spec-Driven Development 前沿范式,将规范重构为 AI 可执行的操作系统——仓库唯一真源、三层递进、三级分层加自动化门禁,在源头控制熵增。
第三期 | 7×24 pipeline:AI-Native 生产线的范式跃迁
底座提供”积木”,规范定义”拼法”,生产线释放全部产能。通过 AI 全托管、Self-Healing 自闭环与 Harness Engineering 驱动的 Agent 自进化,实现 7×24 无人值守的端到端交付——人定规则,AI 永动执行。
接下来,就让我们进入第二期,看看当多元 Agent 在同一代码库高速并行时,我们如何将规范体系打造为 AI 的”可执行操作系统”,从源头构建起对抗代码熵增的免疫屏障,让速度红利不再被债务成本吞噬。

在 AI 原生研发模式下,我们正在经历从「人机协作」到「AI 高自治托管」的范式跃迁。这一转变的核心洞察在于:限制生产效率的瓶颈不再是人力规模或专业壁垒,而是沟通协作成本与 AI 执行的确定性。要实现「人定规则与边界,AI 驱动端到端全栈交付」的目标,要解决其中根本性挑战:
1.1 AI 代码熵增:无约束生成的系统性风险
在长周期、大规模工程中,无约束的 AI 代码生成会导致系统复杂度失控,这一现象被称为「AI 代码熵增」。正如业界观察所指出的:”AI agents ship code fast — and they also ship entropy.”(AI 代理快速生成代码的同时,也在快速引入系统熵)。具体表现为:命名风格不一致、架构模式混用、隐式依赖蔓延、重复代码堆积。随着时间推移,这些问题会形成「技术债雪崩」,使系统维护成本呈指数级增长。
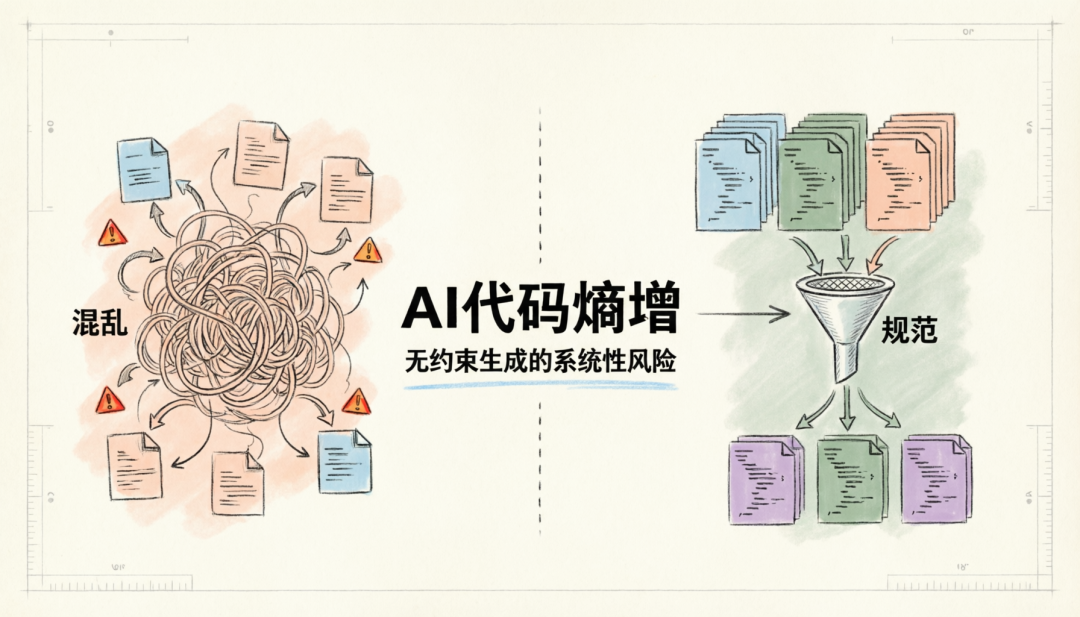
传统的代码审查和人工约束在 AI 高速生成的场景下难以为继。我们需要一套可以被 AI 自动理解、自动遵循、自动验证的规范体系,从源头控制熵增。
1.2 多 Agent 协同:一致性的必然要求
当前 AI 工具生态百花齐放:Qoder、QoderWork、Claude Code、Codex 等多元 Agent 并存。每个 Agent 有不同的能力边界和行为偏好。统一规范为所有 Agent 提供了一个共同的「操作手册」,确保无论使用哪个 AI 工具,其产出都遵循相同的质量标准和架构约束。这也是实现「开放接入体系」的基础——让任意 AI 工具即插即用的前提,是有一套清晰的、AI 可读的规范。
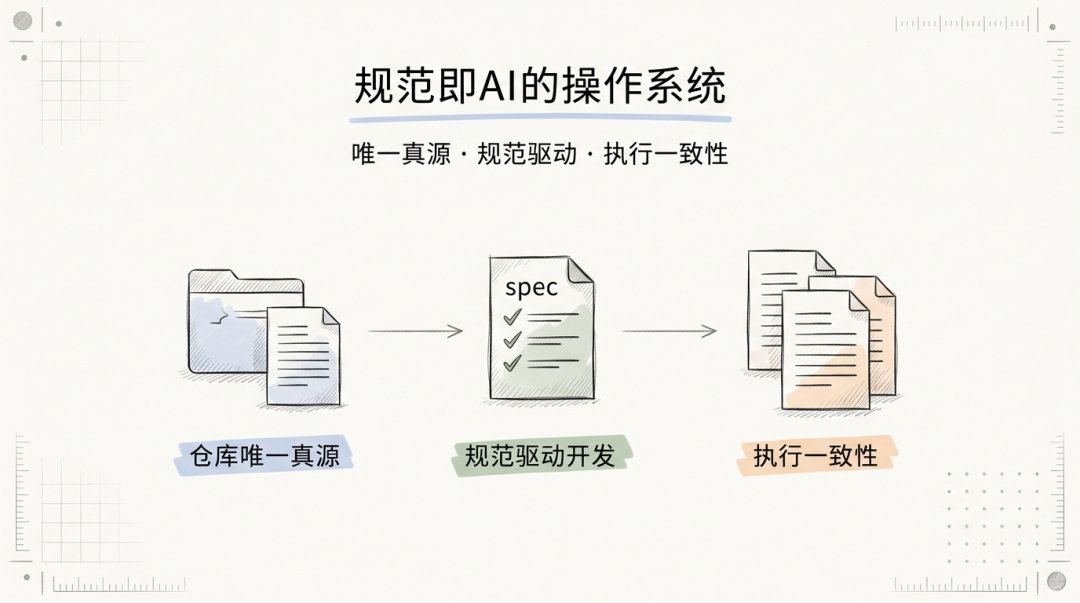
统一规范的本质是为 AI 构建一个「软件化的操作系统」——它不是写给人看的制度文件,而是写给 AI 读的执行指令。这一理念建立在三个核心支柱之上。
2.1 仓库唯一真源(Repository as Single Source of Truth)
在 AI 原生研发范式中,代码不仅是功能实现的载体,更是系统事实的唯一来源。这意味着:
-
结构即架构:系统架构通过目录结构、模块划分、依赖关系在代码中显式表达,而非仅存在于设计文档中。AI 通过阅读代码结构即可理解系统全貌。
-
代码即规则:业务规则、校验逻辑、状态机转换等通过类型系统和接口契约表达,而非散落在注释或 Wiki 中。
-
文档即约束:关键文档(AGENTS.md、README.md、API 契约等)与代码共存于同一仓库,作为 AI 补充说明书,通过 CI 自动验证其与代码实现的一致性。
这一原则为 AI 提供了确定性的基准:人脑中的隐式知识,分散到各文档的特殊说明都要标准化的存储到当前仓库中。让 AI 不再丢失关键信息,因为答案永远在仓库中。
2.2 规范驱动开发(Spec-Driven Development)
业界正在形成「规范驱动开发」(SDD)的新范式共识。其核心思想是:维护软件的核心从「修改代码」变为「演进规范」。在 AI 原生场景下,SDD 表现为三层递进结构:
-
Spec(规范定义):定义「做什么」,包括需求描述、接口契约、数据模型。这是 AI 理解任务的起点。
-
Plan(技术方案):定义「怎么做」,包括架构决策、技术选型、模块拆分。这是 AI 执行的路线图。
-
Task(执行清单):定义「做到什么程度」,包括验收标准、测试要求、输出格式。这是 AI 完成度的度量尺。
当需要调试时,重点不再是修改代码,而是修正产生错误代码的规范或方案。当需要重构时,可以基于同一份规范,生成一个全新技术栈的实现。
2.3 AI 执行一致性(AI Execution Consistency)
统一规范的终极目标是实现「AI 执行一致性」——无论在什么时间、由哪个 Agent、在哪次会话中执行同一任务,其产出应当在架构风格、代码质量、文件组织等维度保持高度一致。这需要规范覆盖从架构到测试的完整链路:架构规范、研发规范、设计规范、安全规范、测试规范、流程规范等形成统一约束体系。
正如 AI 友好框架研究所指出的:”AI agents produce their best code when the framework dictates how things should be done.”(当框架明确规定了做事方式时,AI 代理能产出最好的代码。)
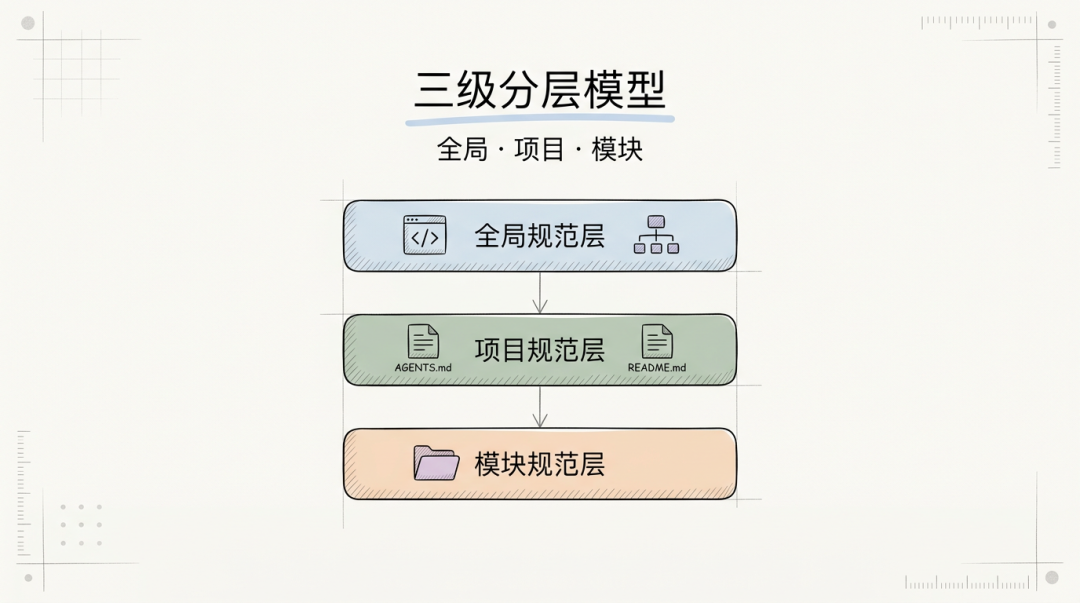
为了兼顾全局一致性与局部灵活性,规范体系采用三级分层模型,每一级承担不同的职责和作用范围。
3.1 全局规范层
全局规范定义跨项目、跨团队的基线标准,是所有 AI Agent 的「公共知识」。其物理载体为全局 Skills 和公用配置。
-
编码风格规范:统一的命名约定(kebab-case 文件名、PascalCase 类名、camelCase 方法名)、格式化规则、目录规范等。
-
架构约束规范:分层架构的依赖规则(上层可依赖下层,反之禁止)、模块边界定义、跨模块通信协议。
-
安全基线规范:密钥管理、输入校验、权限检查等安全编码要求的最低标准。
-
API 设计规范:100% RESTful 标准、错误码体系、版本策略、请求/响应格式约定。
-
通用 Skill 库:经过验证的规范和流程 Skill 可申请加入公用 Skill 库,审核通过后加入默认安装列表,实现最佳实践的自动化分发。
3.2 项目规范层
项目规范继承全局规范并做项目级定制,是每个代码仓库的「操作手册」。其物理载体为仓库根目录下的规范文件集合。
核心文件:
-
AGENTS.md(必需):项目全景地图,约 100 行以内,作为 AI 的导航入口。包含项目一句话说明、工作规则、模块导航索引、输出格式要求。它是「地图」而非「手册」——只做索引和指路,详细内容通过链接按需加载。
-
README.md(必需):面向人类的项目说明,AI 也会参考其中的上下文信息。
-
docs/architecture/:项目架构总览、层级依赖规则、核心数据模型、接口契约定义。
-
.agents:AI 历史决策、错误修复记忆,自进化信息。
3.3 模块规范层
模块规范聚焦于单一模块的局部上下文,是 AI 处理具体模块时的「就近参考」。
-
模块级 AGENTS.md:描述模块的职责边界、内部依赖、特殊约束和注意事项。
-
模块 README.md:模块的公共 API 说明、使用示例、配置参数。
这三级规范形成了「全局对齐、项目定制、模块精细化」的递进结构。AI Agent 在执行任务时,按照「从近到远」的优先级依次参考模块规范、项目规范、全局规范。
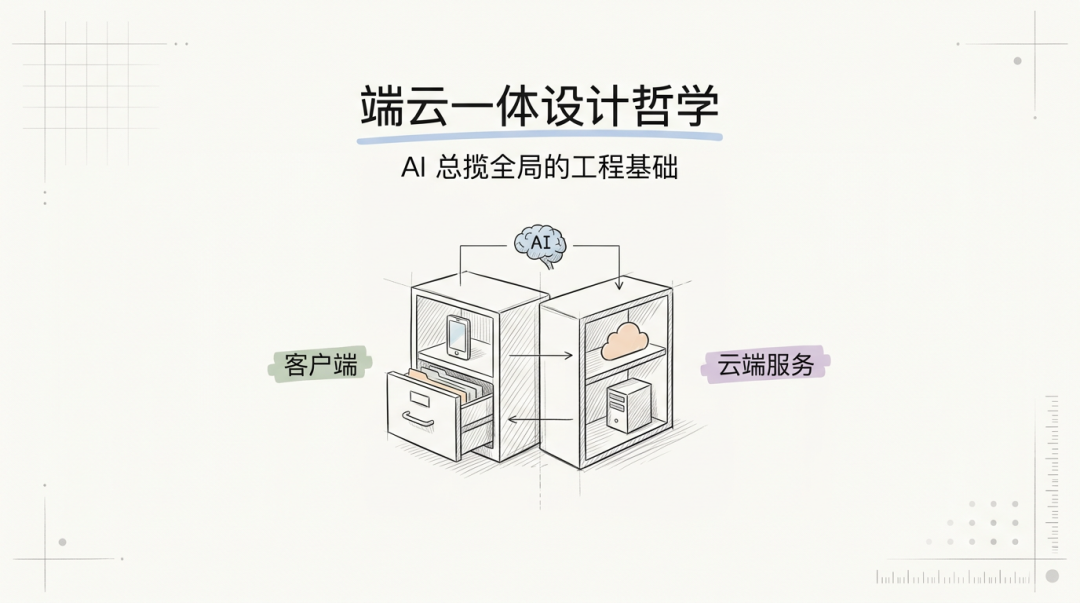
“端云一体”是 AI-Native 基建区别于传统前后端分离架构的核心设计哲学。其本质是:将客户端能力与云端服务统一纳入同一个工程体系和治理框架,让 AI 能够以全局视角理解和操作整个应用栈。
4.1 端云同仓:AI 总揽全局的前提
传统研发中,客户端与服务端分属不同代码仓库、不同技术栈、不同团队。这种割裂对人类工程师而言或许可控,但对 AI Agent 而言是致命的——它无法在一次会话中同时理解端和云的上下文,无法跨仓库追踪数据流转,无法全局优化接口设计。
端云同仓(Monorepo)将全栈代码收敛到统一仓库中,使 AI 能够:在一次 Context 加载中获取完整的系统视图;跨越端云边界追踪类型定义和接口契约;发现并消除端云之间的冗余定义和不一致性;在修改服务端接口时,同步更新客户端调用逻辑。
2026 年业界的趋势也在印证这一方向。Spectro Cloud 的分析指出,AI 编码工具正在推动 Monorepo 的复兴——当 AI Agent 能够一次性加载整个代码库时,Monorepo 的”高认知负载”劣势消失了,而”全局一致性”的优势被极大放大。
4.2 全栈工程底座:统一的工程治理
端云一体不仅是代码组织层面的统一,更是工程治理的统一。这包括:统一的构建工具链、统一的依赖管理、统一的测试框架、统一的发布流程。通过全栈工程底座,AI 只需要学习一套规则就能操作整个系统,极大降低了 Agent 的认知成本和出错概率。
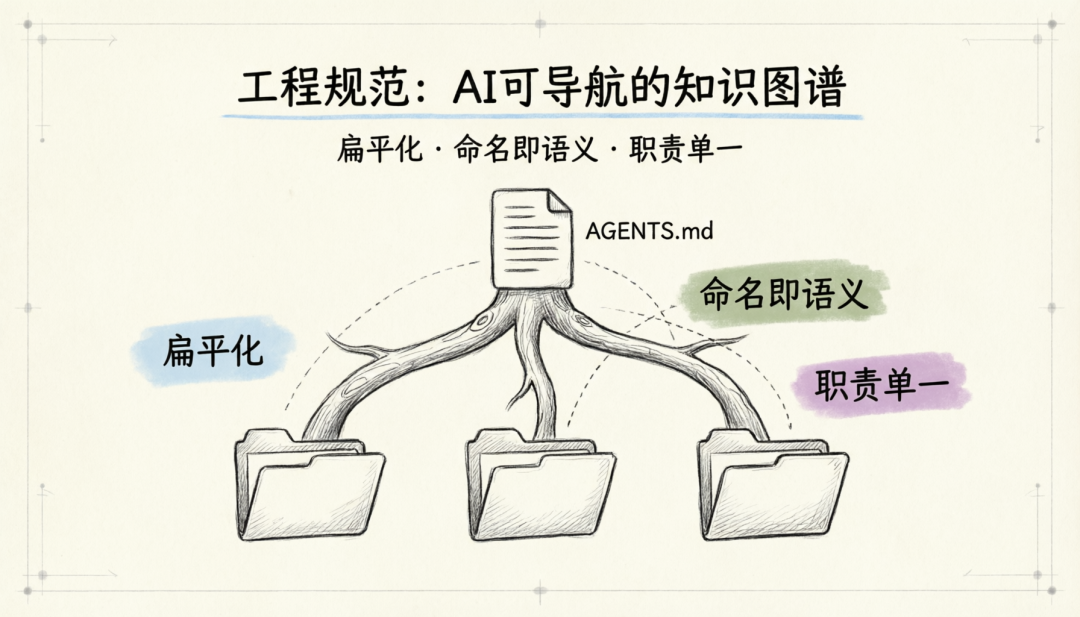
目录结构是 AI 理解项目的第一入口。一个 AI-Native 的目录结构,本质上是一个可导航的知识图谱。
5.1 设计原则
-
扁平化优先:避免过深的目录层级,任何文件最多不超过四层嵌套。深层嵌套会显著增加 AI 的上下文消耗,降低定位效率。
-
禁止大文件:文件过大时容易分散模型注意力,应按内容分成多个文件,并按层级引用。
-
命名即语义:目录名和文件名应可直接表达用途,使用 kebab-case 命名。带编号的文档使用三位数字前缀如
prd-001-feature-x.md。避免模糊目录(如utils/、misc/、common/)和杂糅结构。 -
职责单一:每个目录只承担一种职责,「当一切都重要时,什么都不重要」。
-
元数据与内容分离:
docs/存放项目规范、prd 等关键信息,.agents/存放 AI 可读的元数据和运行时配置。 -
Agent 协议标准化:定义统一的 Agent 通信协议(任务分发、进度报告、结果提交),不同 AI 工具实现的 Agent 可作为”工人”无缝接入生产线。
5.2 推荐目录结构
~/.agents/ # 全局公用 AI 配置└── skills/ # 全局公用 Skills└── <skill-name>/└── SKILL.md # 技能定义文档workspace/├── AGENTS.md # 必需:项目全景地图(AI 导航入口)├── CLAUDE.md # 可选:特定 Agent 配置(可软链到 AGENTS.md)├── WORKFLOW.md # 可选:工作流策略(YAML + Agent Prompt 模板)├── README.md # 项目说明(面向人类)│├── .agents/ # 仓库私有 Agent 能力配置│ ├── skills/ # 当前仓库私有技能│ │ └── <skill-name>/│ │ └── SKILL.md│ ├── memory-session/ # 任务记忆│ │ ├── ERRORS.md # 经验教训(避坑记录)│ │ └── LEARNINGS.md # 关键决策记录│ └── self-evolution/ # 自进化│ └── AGENTS-1.md # 常用知识沉淀│├── docs/ # 规范与约束文档│ └── architecture/│ ├── layer-rules.md # 层级依赖规则│ ├── data-model.md # 核心数据模型│ └── api-contracts.md # 接口契约规范│└── src/ # 业务代码└── modules/└── <module>/├── AGENTS.md # 模块级 AI 说明├── README.md # 模块公共 API└── ...
5.3 架构规范
-
分层架构契约:明确定义各层的职责边界与依赖方向。例如:表现层不得直接访问数据层;领域层不得依赖具体框架实现。这些约束以 ArchUnit 或类似的架构守护工具编码实现,AI 生成的代码如违反分层规则将在 CI 阶段被自动拦截。
-
模块边界定义:每个模块通过标准化的”模块描述文件”(Module Manifest)声明其公共接口、依赖项与所属领域。AI Agent 在生成代码时,可通过读取 Manifest 精确理解模块的职责范围,避免跨界实现。
-
扩展点规范:定义系统的可扩展边界与扩展方式。新功能应通过预定义的扩展机制(插件注册、事件订阅、策略模式等)接入,而非对核心代码进行侵入式修改。
5.4 端云一体化工程视图
对于端云一体(Full-Stack)应用,目录结构需要让 AI 能够「总览全局」。将前端、后端、共享类型定义、基础设施配置统一在一个 Monorepo 中,通过根级 AGENTS.md 提供全栈导航,使 AI 能够在一个上下文窗口内理解从 API 契约到 UI 渲染的完整链路。这是实现「AI 总览全局」的关键工程基础。
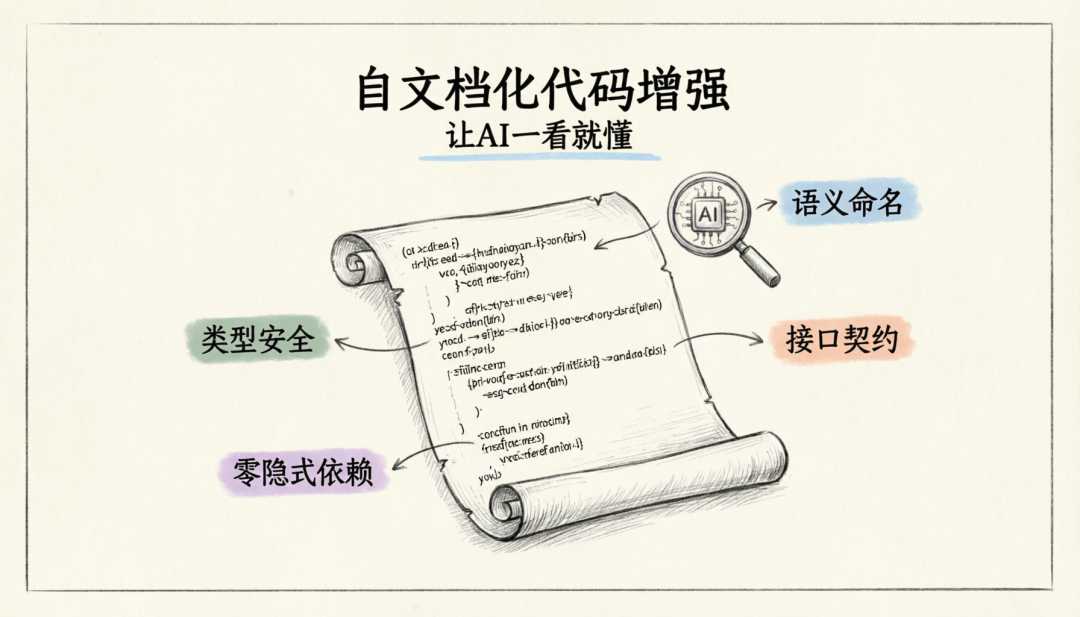
代码级规范的核心目标是降低 AI 的理解成本,提高生成的确定性与一致性。
6.1 语义化命名
- 变量和函数:名称应完整表达意图,避免缩写。
calculateOrderTotalPrice()优于calcOTP()。AI 依赖名称理解语义,缩写会增加歧义。 - 常量:使用 UPPER_SNAKE_CASE,并附带注释说明取值来源和修改条件。
- 类型/接口:使用 PascalCase,名称应反映业务概念而非技术实现。
PaymentTransaction优于DataObj。
6.2 类型安全优先
强类型系统是 AI 最重要的「自动审查员」,让 AI 更好的理解函数结构。具体要求:
-
禁止
any类型,所有公共 API 必须有完整的类型签名。 -
使用联合类型(Union Types)和字面量类型(Literal Types)精确约束取值范围。
6.3 接口契约标准化
100% RESTful 规范,零野接口。每个 API 必须满足:
-
明确的 HTTP 方法语义(GET 读取、POST 创建、PUT 更新、DELETE 删除)。
-
标准化的错误响应格式,包含错误码、错误消息和可选的详情字段,错误信息要 AI 可读。
-
版本化策略(URL 路径版本
/v1/)。 -
完整的 OpenAPI/Swagger 定义,作为 AI 生成客户端代码和测试用例的输入。
6.4 零隐式依赖
每个模块的依赖必须显式声明,不依赖全局状态、环境变量魔法或运行时注入。AI 应当能够通过阅读模块的依赖声明和配置文件,完整理解其依赖图谱。这是实现「上下文独立,可独立测试」的基础。
6.5 函数职责单一
AI 的 context window 有限,一个 500 行的函数让 AI 很难定位问题;20 行的纯函数则几乎总能被正确理解和修改。
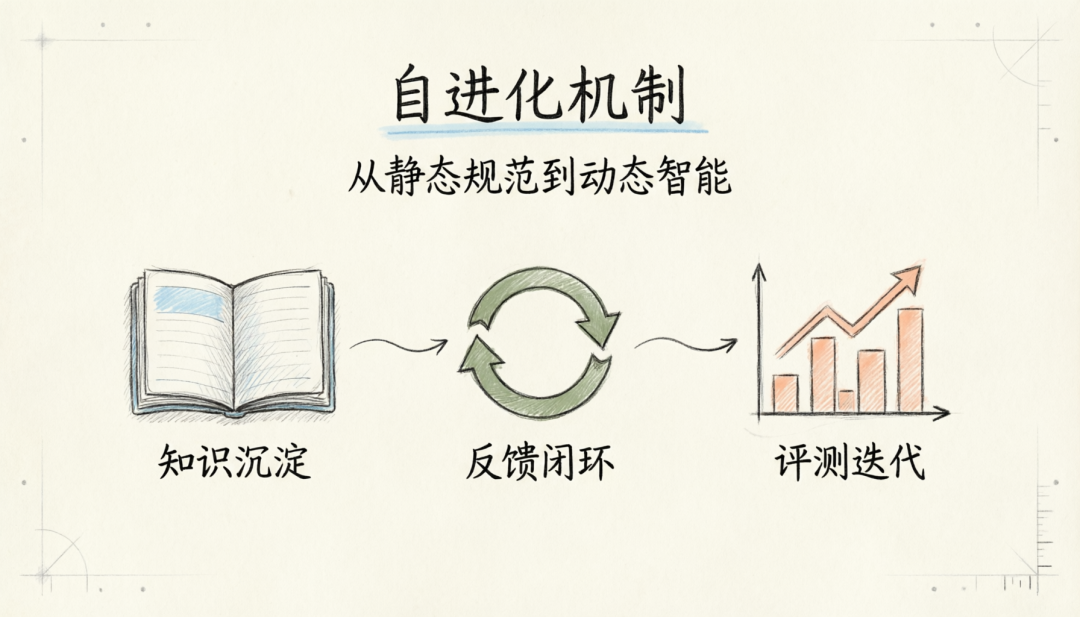
规范不应是一成不变的文档,而应是持续进化的活系统。
7.1 知识沉淀
.agents/memory-session/ 目录承担 AI 的「组织记忆」功能:
-
ERRORS.md:记录 AI 执行中遇到的典型错误和解决方案,避免同一错误重复发生。
-
LEARNINGS.md:记录关键架构决策(Architecture Decision Records, ADR),包含背景、取舍和最终选择,帮助 AI 理解「为什么是这样」而非仅仅「是什么样」。
7.2 反馈闭环
每次 AI 任务执行完成后,自动评估执行质量,将发现的问题和改进建议反馈到规范体系中。这个闭环使得规范能够基于实际执行数据持续优化,而非依赖人工经验判断。
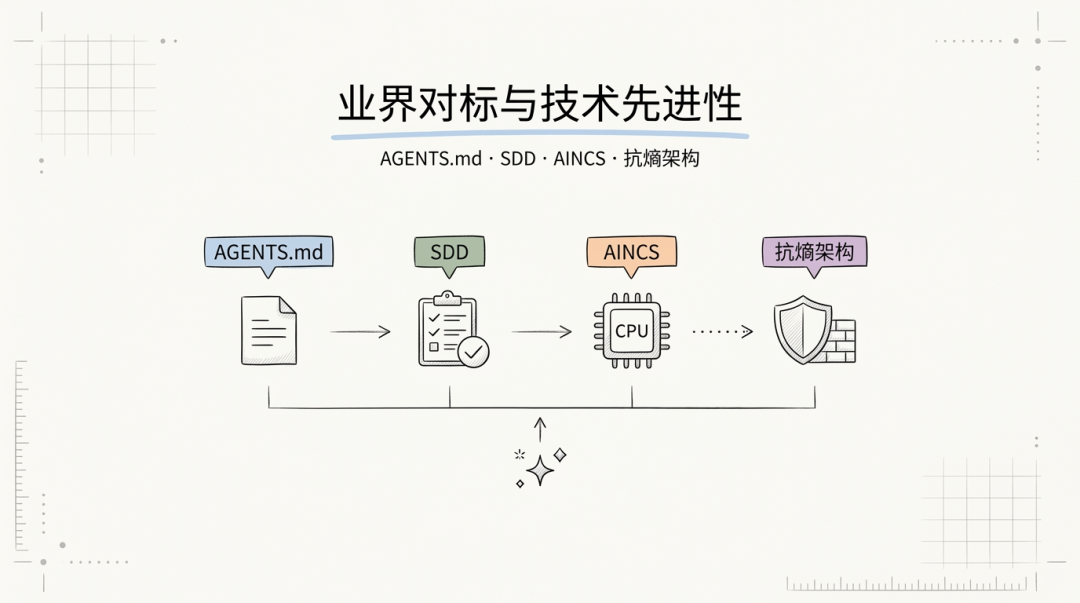
本规范体系的设计融合了业界最前沿的实践和理念。
8.1 AGENTS.md:AI 代理的通用标准入口
AGENTS.md 正在成为业界事实标准——正如其官方定义所言:”Think of AGENTS.md as a README for agents.”(把 AGENTS.md 想象成面向 AI 代理的 README。)Google 工程师 Addy Osmani、Anthropic 的 Claude Code、GitHub 的 Spec-Kit 等均采用了类似的「指令文件」机制。我们的实践在此基础上进行了系统性增强:引入三级分层模型(全局/项目/模块),支持按需加载,避免上下文窗口浪费;同时通过 .agents/ 目录引入「AI 工作环境基础设施」的概念,将任务记忆和自进化能力内建到项目结构中。
8.2 Spec-Driven Development:规范驱动的范式升级
我们的规范体系与业界兴起的 SDD(Spec-Driven Development)范式高度对齐,同时做了关键创新:不仅定义了 spec → plan → task 的文档层次,更通过 SKILL 模板机制实现了规范的可复用、可分发。验证通过的规范 Skill 可以自动进入全局安装列表,实现「最佳实践的零边际成本扩散」。
8.3 AI-Native Computing 理念的落地
AI-Native Computing Standard(AINCS)提出了 AI 作为「一等公民执行实体」的理念。我们的规范将这一理念具体化:AI 不是被调用的外部服务,而是内生于开发流程的自主参与者。它通过 AGENTS.md 了解项目上下文,通过规范约束自身行为,通过 CI 门禁验证自身产出,通过 memory-session 积累执行经验。这是一种将 AI 视为「有状态的持久代理」而非「无状态的 API 调用」的根本性范式转换。
8.4 抗熵架构:工业级的长期可维护性
针对 AI 代码熵增这一业界公认的核心挑战,我们的规范体系构建了多层防线:类型系统做静态约束、CI 门禁做自动化验证、架构规则做分层隔离、AGENTS.md 做上下文对齐、memory-session 做经验沉淀。这种「规范即免疫系统」的设计理念,确保了系统在 AI 高频生成下仍能保持架构的清晰和代码的可维护性。
AI-Native 的统一规范是 AI 原生研发模式的基石。它的核心价值不在于约束 AI 的能力,而在于为 AI 的能力提供正确的方向和边界。通过「仓库唯一真源」确保基准的确定性,通过「规范驱动开发」确保执行的可控性,通过「三级分层模型」确保治理的灵活性,通过「自动化质量门禁」确保产出的可靠性,通过「自进化机制」确保体系的持续进化。
在这套规范的支撑下,我们能够真正实现:人定规则与边界,AI 驱动端到端全栈交付——从而释放 AI 产能,实现指数效率跃迁。