
在 ClawHub 上翻到一个分类标着 Security 的 Skill,点进去发现跟安全半毛钱关系没有。它做的事说出来挺朴素:搜广告素材、查 App 排名、看下载量趋势。但 131k 下载量、285 个 star 放在那,显然不只是”又一个 API wrapper”那么简单。
翻完它的 Skill 定义文件之后,我觉得这东西真正的价值不在数据本身,而在它把一套原来需要点十几下鼠标的分析流程,压缩成了几句自然语言。这事看起来容易,但涉及的交互设计决策比表面上多得多。
说真的,这篇文章不讲大道理。就是把这个 Skill 从安装到实际跑通的路径拆一遍,顺便聊聊它那个复杂度路由设计为什么值得认真看一下。如果你在做出海 App、搞竞品分析、或者单纯想理解”好的 AI Skill 交互应该长什么样”,这些东西应该能给你省不少时间。
环境准备
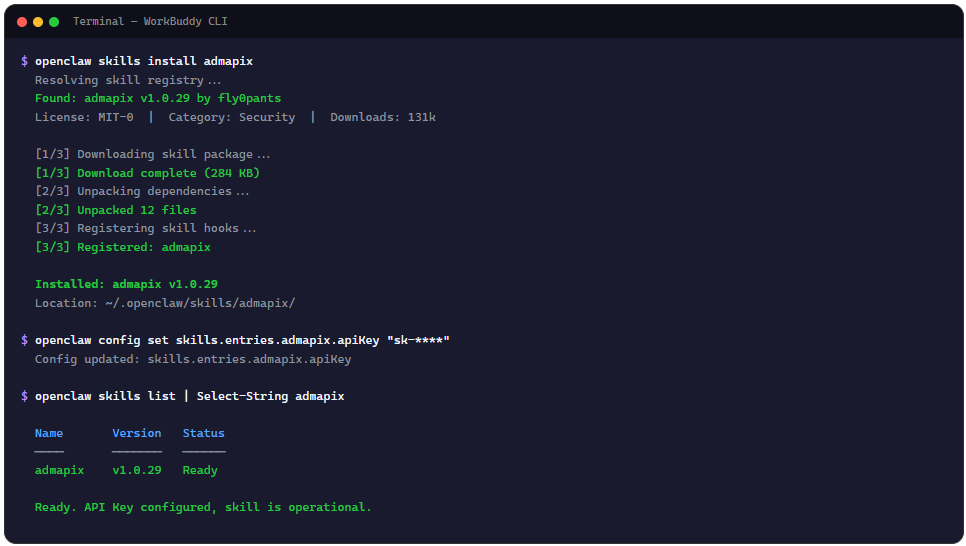
AdMapix 的安装跟 ClawHub 上其他 Skill 一样,一行命令完事。
openclaw skills install admapix
装完不代表能用。这东西本质上是个 API 网关,所有数据都来自 admapix.com 的后端,所以你需要先去官网注册账号,在控制台创建一个 API Key。
拿到 Key 之后,配到环境变量里:
openclaw config set skills.entries.admapix.apiKey "你的_API_KEY"
也可以用通用环境变量 ADMAPIX_API_KEY,看你的使用场景。
从文档来看,它没有做任何本地数据缓存,所有查询都是实时打到 api.admapix.com 的。意味着网络质量和 API 套餐配额是你唯二需要关心的前置条件。注册送免费额度,够你验证功能了。
API Key 配错是最常见的卡点。403 报错一般就是 Key 没设对或者套餐权限不够。502 的话大概率是上游数据源挂了,等几分钟重试就行,Skill 内部对这种错误有自动重试机制。
交互流程:一句话完成一次分析
AdMapix 的交互设计跟传统 SaaS 仪表盘走了完全相反的路线。你不需要选择维度、不需要勾选筛选项、不需要在七八个菜单里找入口。直接说话。
比如你想知道 Temu 在海外投了多少广告:
“搜一下 Temu 最近在投的广告素材”
Skill 会自动识别”搜””素材”这两个信号,路由到创意搜索意图组,拼好 API 参数,返回结果。
它的核心工作流分五步走。第一步是 API Key 检查,没 Key 直接拒,不浪费任何一次 API 调用。第二步做复杂度分类,判断你的问题是单次查询还是需要跨多个端点的深度分析。第三步根据用户意图路由到七个意图组中的一个。第四步执行查询,独立查询并行跑,依赖查询顺序执行。第五步按操作模式输出结果。
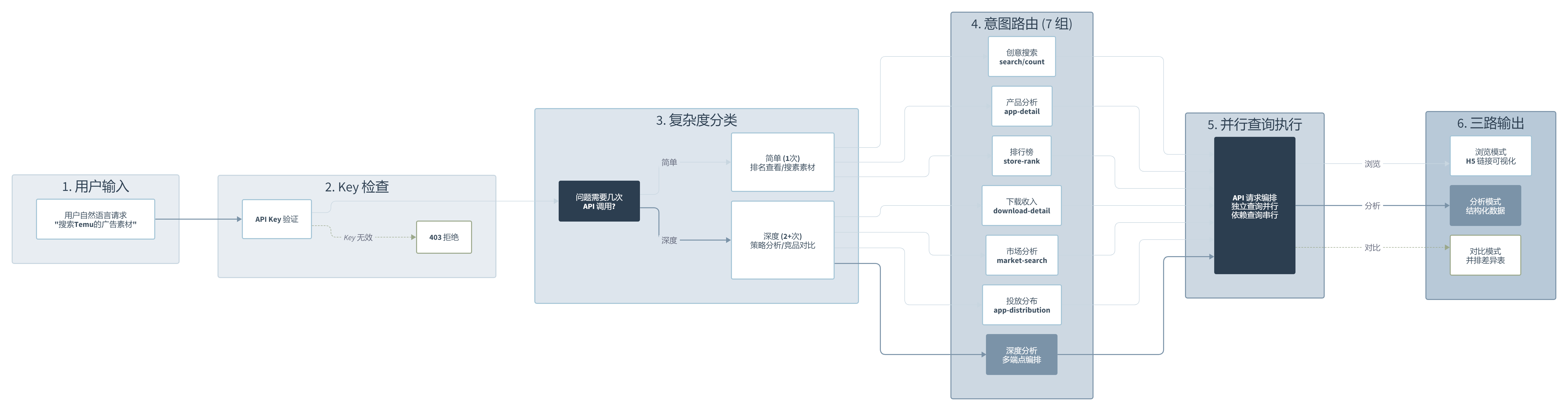
有意思的是第三步那个”操作模式分类”。同样的问题,你说”搜”和你说”分析”,它会走完全不同的输出路径。浏览模式直接给 H5 可视化链接,分析模式给结构化数据,对比模式给并排差异表。这个设计很讨巧,它在用户的措辞里埋了足够多的意图信号。
从社区反馈来看,这套路由在常见场景下准确率不错。但边界 case 也有,比如”看看 Temu 的广告策略”这种模糊请求,有时候会被判成浏览模式而非分析模式,出来的结果是素材列表而不是策略总结。这是自然语言交互绕不开的限制,任何意图分类系统都有这个毛病。
关键设计:复杂度路由是个好东西
翻完 Skill 的参考文件和 API 端点映射之后,最让我感兴趣的反而不是那些数据接口,而是它的复杂度分类机制。
AdMapix 在接到用户请求后做的第一件事不是拼 API 参数,是判断”这个问题需要几次 API 调用”。如果答案是 1 次,走简单路径,Skill 内部直接处理。如果答案是 2 次以上,触发 Deep Dive 编排,甚至可以选择扔给 Deep Research 框架做异步深度分析。
这个设计解决了一个很实际的问题。广告情报分析的请求天然具有”两极分化”特征。查排名是秒级需求,做竞品广告策略分析可能要跑七八个端点、等几分钟。如果所有请求都走同一套逻辑,要么简单查询被复杂流程拖慢,要么复杂分析被简单框架限制。
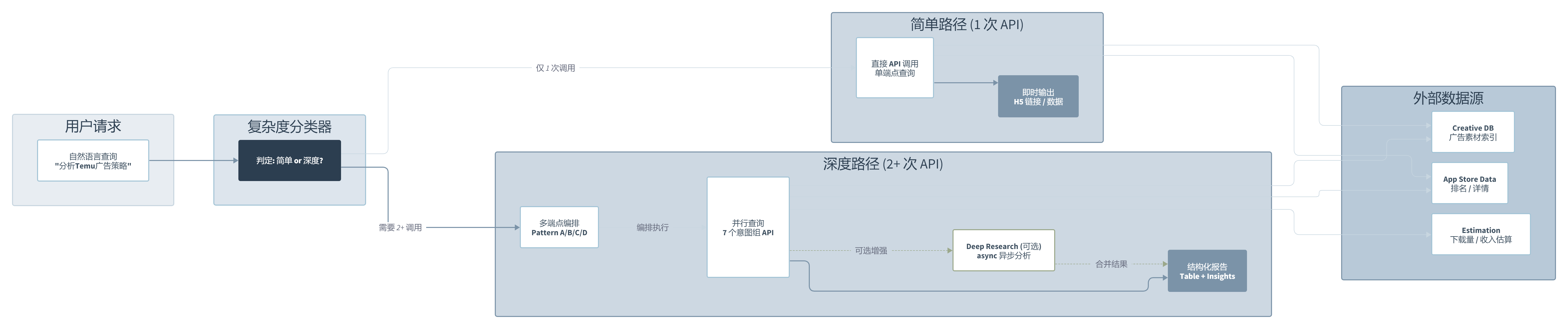
它在这个路由层之后的处理也挺讲究。独立查询并行执行,依赖查询串行执行。比如同时查两个 App 的下载数据可以并行,但”先找到 App ID,再根据 ID 查详情”这种必须串行。这种编排逻辑在其他 AI Skill 里不常见,多数 Skill 都是”收到问题、调一次 API、返回结果”的直线模式。
但我不确定这个设计是完全有意为之还是在应对 API 限制时自然演化出来的。从 Skill 文件的组织来看,七个意图组各有独立的参考文件,参数映射也单独抽了一个文件,这种结构本身透露出设计者在刻意分离”路由逻辑”和”数据处理逻辑”。如果是无意中踩到的,那这个”无意”结果比很多”有意”的设计都要好。
值得吐槽的是 Deep Research 框架需要额外配置 Token,而且轮询间隔写死 15 秒。超时之后降级回本地编排,这个兜底策略是对的,但 15 秒的硬编码意味着即使 API 响应很快,你也得干等。如果能根据历史响应时长做自适应轮询,体验会好一档。
实战场景:出海 App 竞品分析
AdMapix 最合适的场景是出海 App 的竞品广告策略分析。假设你做了一款休闲游戏,想搞清楚同类产品在海外怎么投广告。
以前的做法大概是这样。打开 Sensor Tower 或 App Annie,切到广告素材模块,选国家、选渠道、选时间段,筛选、翻页、导出、整理、对比。光操作就十几步,还没算上数据清洗的时间。
用 AdMapix,事情变成一句话。
“分析一下 Candy Crush 在美国的广告投放策略”
Skill 会自动执行五步编排。先搜到 Candy Crush 的统一产品 ID,再拉应用详情、投放国家分布、投放渠道分布、素材类型分布,最后抓几个样本素材。整个过程用 Pattern A 编排,一次对话完成。
从搜索到的反馈来看,最有价值的部分是它把”跨维度查询”变成了一次对话。以前你需要分别在排名模块看排名、在下载模块看下载、在素材模块看素材,现在一句”Temu 的广告投放策略”就能把多个维度的数据串起来。
但这个 Skill 也有明显的适用边界。下载量和收入数据是第三方估算,不是官方数据,偏差可能不小。API 返回的素材数据依赖第三方平台的抓取覆盖度,某些地区的素材可能不全。另外它本质上是个查询工具而不是分析工具,它能帮你把数据拉出来、组织好,但”这个素材为什么好””竞品的策略拐点在哪”这种洞察层面的判断,还是得你自己做。
几个典型的使用模式,我整理了一下:
浏览模式(搜素材):"搜一下休闲游戏在美国的广告素材" → H5 可视化链接
分析模式(看趋势):"分析 Candy Crush 最近三个月的下载趋势" → 结构化数据
对比模式(竞品对比):"Temu 和 Shein 的广告策略对比" → 并排差异表
深度分析(策略报告):"全面分析 Temu 的美国市场广告策略" → 结构化报告
洞察与反思:广告情报工具的”查询语言”化
把 AdMapix 放在更大的视角下看,它代表的其实是一种趋势。广告情报分析这个领域,过去十年一直在做”加功能”。从只展示排名,到加入下载估算,到加入素材库,到加入投放渠道分析。功能越加越多,入口越加越深,学习曲线越来越陡。
AdMapix 做的是反方向。它的核心交互不是”给你更多按钮”,是”让你不用按钮”。这对数据工具来说是个挺激进的思路。
从设计推断来看,这种交互方式的底气来自两件事。一是它的意图路由系统能比较准确地识别用户想干什么,不用在菜单里翻找。二是它把多端点编排这个脏活藏在 Skill 内部,用户不需要知道”先查 ID 再查详情”这类技术细节,只需要说出自己想要什么。
但这种模式的风险也明显。自然语言交互的信息带宽比 GUI 低很多。一个仪表盘可以在同一屏展示 20 个指标,你扫一眼就知道全局。对话式交互一次只能吐一条信息,看深层内容需要多轮追问。AdMapix 用浏览模式的 H5 链接部分缓解了这个问题,但 H5 页面是只读的,没法做二次筛选和交叉过滤。
我个人觉得这不是 AdMapix 一个人的问题,是整个”对话式数据查询”赛道都要面对的瓶颈。现在的解法是多模式混合,简单查用自然语言,复杂看用 H5 链接,深度分析走结构化报告。这个方向是对的,但离”对话完全替代仪表盘”还有很长一段距离。
那些真正每天用这类工具的人,大概会找到自己的混合使用节奏。快速查询丢给对话,深度分析切到仪表盘。工具的价值不在替代旧方案,在让新方案解决旧方案搞不定的那部分事。
| 资源 | 地址 |
|---|---|
| 官网 | https://www.admapix.com |
| ClawHub | https://clawhub.ai/fly0pants/admapix |
总结
AdMapix 在 ClawHub 上拿 131k 下载不是没道理的。它的核心价值三句话就能概括:用自然语言替代了十几步 GUI 操作,用复杂度路由让轻量查询和深度分析各走各路,用多端点编排把跨维度分析压进一次对话。
但别把它当万能工具。下载收入数据是估算不是官方值,某些地区素材覆盖不全,深度分析层面它只做数据拉取不做洞察生成。你对数据的判断力,决定了你能从这个 Skill 里挖出多少东西。
去 admapix.com 注册免费账号,装好 Skill 后搜一个你最关注的 App,用浏览模式看看它的广告素材长什么样。然后再用分析模式拉一份它的投放渠道分布,你大概率会对”原来它花钱最多的是这个渠道”这种发现感到意外。
FAQ
Q: 适合什么人用?
A: 做出海 App 的运营和增长团队、需要竞品广告情报的投放优化师、做行业研究想知道各家怎么投广告的分析师。纯国内业务不用折腾,数据覆盖以海外为主。
Q: 数据准确度怎么样?
A: 排名、素材数据来自第三方平台的实时抓取,可信度较高。但下载量和收入是建模估算,不是官方数据,偏差 20% 到 50% 都正常,用它看趋势还行,拿来做财务模型要慎重。
Q: 免费能用吗?
A: 注册送免费额度,够验证功能和做少量查询。高频使用的团队需要付费套餐,具体定价看 admapix.com 官网。不同套餐的 API 权限也有差异,403 报错多半是套餐权限不够。
Q: 和其他广告情报工具有什么区别?
A: 数据源层面跟 Sensor Tower、App Annie 等属于同一赛道。核心差异在交互方式,AdMapix 是对话式查询,不需要在仪表盘里点十几下菜单。数据深度可能不如专业工具那么全,但查询效率明显更高。
Q: Deep Research 模式有必要开吗?
A: 普通分析用本地 Deep Dive 编排就够了。Deep Research 适合那种”我需要你帮我跑完所有端点、整理成一份完整报告”的场景,但需要额外配置 Token 而且有等待时间。不是刚需,按需开。