
我电脑里至少躺着 几百个 PDF。合同要改条款,报告要合并章节,演示文稿得调几个字。每次打开 Adobe Acrobat,等它加载的那十几秒里,我都会想同一个问题:改个 PDF 为什么这么重?
这个问题不止我一个人在问。112k 下载量、257 个 Star,Peter Steinberger 做的 nano-pdf 给出了一个相当粗暴的答案:用嘴说就行了。你说”把标题改成 Q3 Results”,它就把标题改成 Q3 Results。不开 GUI,不点菜单,不走”编辑、修改、保存、导出”这套流程,一条命令,一句自然语言。
听起来像个 demo 级别的玩具,但它不是。nano-pdf 底层接的是 Google Gemini 3 Pro Image 模型,走的是一条”把 PDF 当图像来改”的野路子。说真的,这篇文章不打算跟你讲太多概念,就是从安装到踩坑,从设计思路到为什么它不适合所有场景,把该说的说清楚。如果你也在找一个轻量级的 PDF 编辑方案,这篇应该能帮你少走点弯路。
环境准备
nano-pdf 是 OpenClaw/ClawHub 平台上的一个 Skill,位于 steipete/nano-pdf,MIT-0 许可证。要把这东西跑起来,得备齐三样东西:OpenClaw CLI、nano-pdf Python 包、一张 Google Gemini 的付费 API Key。
安装本身不复杂。先通过 OpenClaw 装 Skill:
openclaw skills install nano-pdf
这条命令搞定了 Skill 层面的集成。但 nano-pdf 真正干活依赖的是底层 Python CLI 工具,由 Gavriel Cohen 开发,托管在 PyPI 上,目前版本 0.2.1,标记为 Alpha 状态。用 uv 或 pip 都行:
uv tool install nano-pdf
装完 Python 包还不算完。nano-pdf 依赖两个系统级工具:Poppler 负责把 PDF 页面转成图像,Tesseract 负责 OCR 回灌文字层。macOS 上 brew install poppler tesseract 一把梭,Windows 上用 choco install poppler tesseract,Linux 上 apt-get install poppler-utils tesseract-ocr。不少人卡在这一步,装完了没重启终端就跑命令,然后报错找不到依赖。
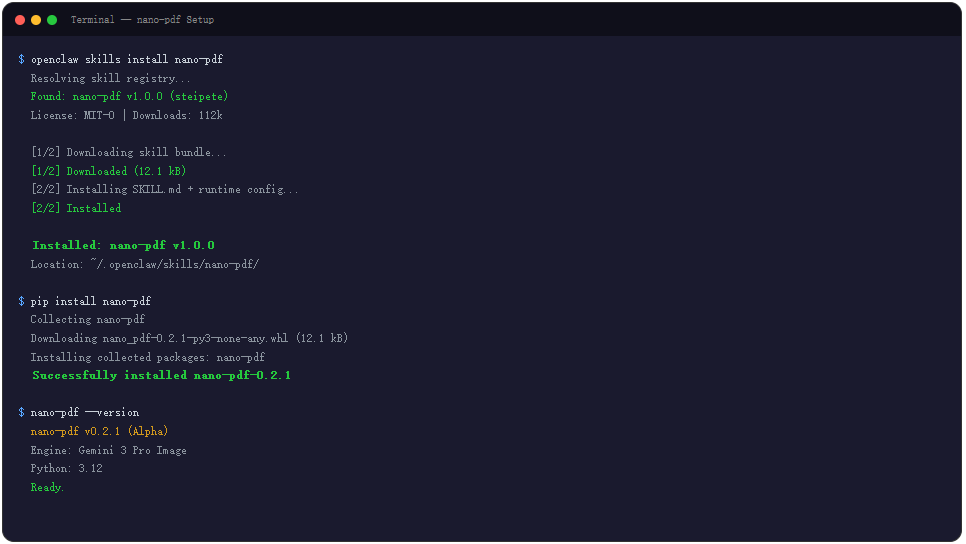
最后也是最容易让人止步的一步:API Key。nano-pdf 调用的是 Gemini 3 Pro Image,这个模型不支持免费层。你得在 Google AI Studio 开通付费账单,把 GEMINI_API_KEY 设到环境变量里:
export GEMINI_API_KEY="your_api_key_here"
没配 Key 就跑命令,报错信息不会直接告诉你”请付费”,而是一个看着像网络问题的模糊错误,这是目前体验上最让人窝火的地方。
操作流程
nano-pdf 的使用方式简单到有点反直觉。不夸张地说,核心语法就一句话:
nano-pdf edit deck.pdf 1 "Change the title to 'Q3 Results' and fix the typo in the subtitle"
三个参数:PDF 文件名、页码、自然语言指令。没了。不用学菜单位置,不用记快捷键,不用理解 PDF 的内部结构。只需要像跟同事说话一样告诉它怎么改。
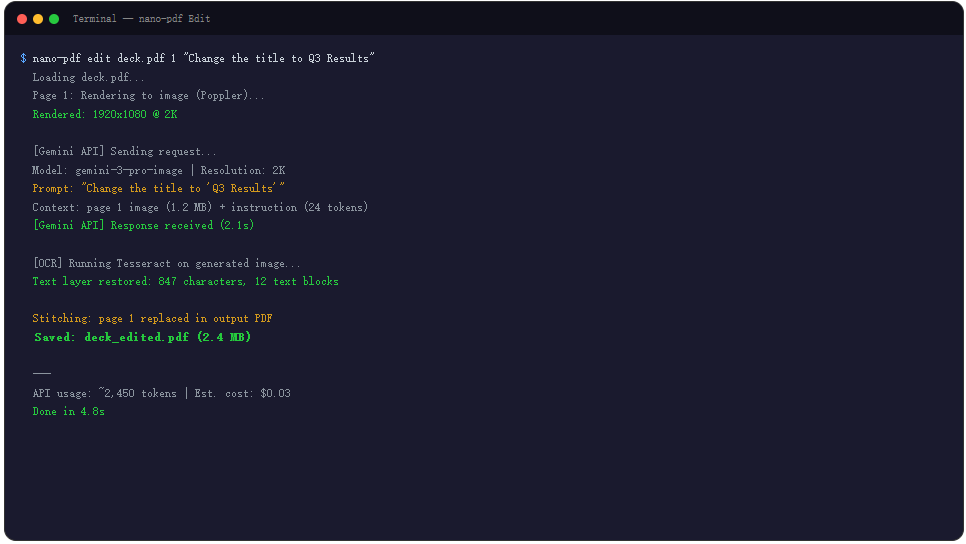
但别被这个简洁的表象骗了。页码编号的坑值得特别提一下。文档明确说了:页码到底是 0 起始还是 1 起始,取决于工具版本和配置。没有统一标准,不同版本可能不一样。你自信满满 edit report.pdf 1 "fix the date",改的是封面页而不是第一页内容。遇到这种情况别怀疑自己,换个编号方式重试就完了。
多页编辑的场景更有意思。nano-pdf 支持在同一条命令里并行处理多个页面,而且每个页面可以给不同的指令:
nano-pdf edit my_deck.pdf \
1 "将日期更新为 2025年10月" \
5 "添加公司 Logo" \
10 "修复页脚拼写错误"
这不只是省时间的优化。并行处理意味着你不需要像传统工具那样逐页打开、修改、保存,再打开下一页。一口气把整份文档的修改需求说完,等着拿结果就行。
如果你需要的是添加新页面而非修改已有内容,nano-pdf 还有个 add 子命令。它不只是插一页空白 PDF,而是利用 Gemini 的视觉能力生成与现有幻灯片风格一致的新页面,文风、色调、布局都尽量对齐。从文档和社区反馈来看,这个功能对演示文稿类 PDF 效果最好,文字密集型文档的生成质量则不太稳定。用 --style-refs "2,3" 传几个参考页能明显提高匹配度。
关键设计
nano-pdf 的设计哲学不值得绕弯子。它走的不是传统 PDF 编辑器那条”解析文档对象模型、定位文本块、修改属性”的路,而是把整个 PDF 页面当成一张图,丢给多模态模型去改。这个决策很聪明,代价也明显。
具体来说,内部管线分五步:Poppler 把指定页渲染成图像,可选地引入参考页帮助模型理解视觉风格,Gemini 3 Pro Image 接收图像和指令后生成修改版本,Tesseract OCR 把文字层回灌进去恢复可搜索性,最后把 AI 编辑后的页面拼回原文档。一条不依赖 PDF 内部结构的管线,相当干净。
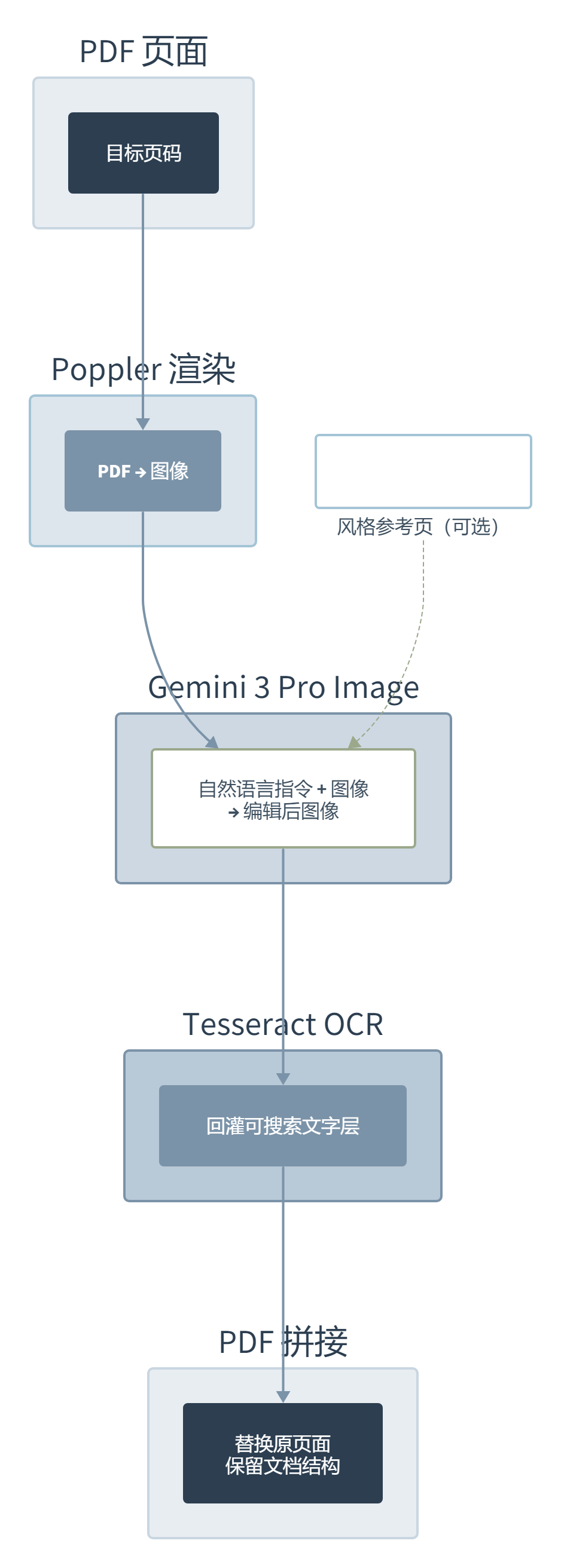
但这个设计里藏着三个值得拆的决策。
- 第一,为什么选 Gemini 3 Pro Image 而不是开源模型?从 PyPI 页面的技术架构来看,作者 Gavriel Cohen 的管线对视觉理解精度要求很高。模型需要同时理解文字内容、排版结构和视觉风格三个维度,目前开源视觉模型在这个组合任务上还差一口气。而且 Gemini 的 API 响应速度对交互式命令行场景来说是硬指标,跑一个请求等 30 秒可以接受,等 3 分钟就不行了。
- 第二,OCR 回灌这件事其实是在弥补一个先天缺陷:把 PDF 转成图像再生成图像,文字层自然就丢了。Tesseract 能恢复大部分标准字体的文字,但花式字体和极小字号的效果不理想。这意味着编辑后的 PDF 虽然看起来没问题,搜索和复制文本的体验偶尔会打折。对那些需要保持全文可搜索的文档来说,这是个实打实的痛点。
- 第三,
--style-refs这个参数的引入暴露了一个坦诚的事实:AI 不是每次都能准确理解你的文档风格。传一个参考页面让它”照着这个风格来”,本质上是在替模型补它漏掉的上下文。像代码注释里留的一个// TODO: improve style matching,只不过这块标注直接暴露在了用户侧。这种做法比假装完美要好得多。
使用场景
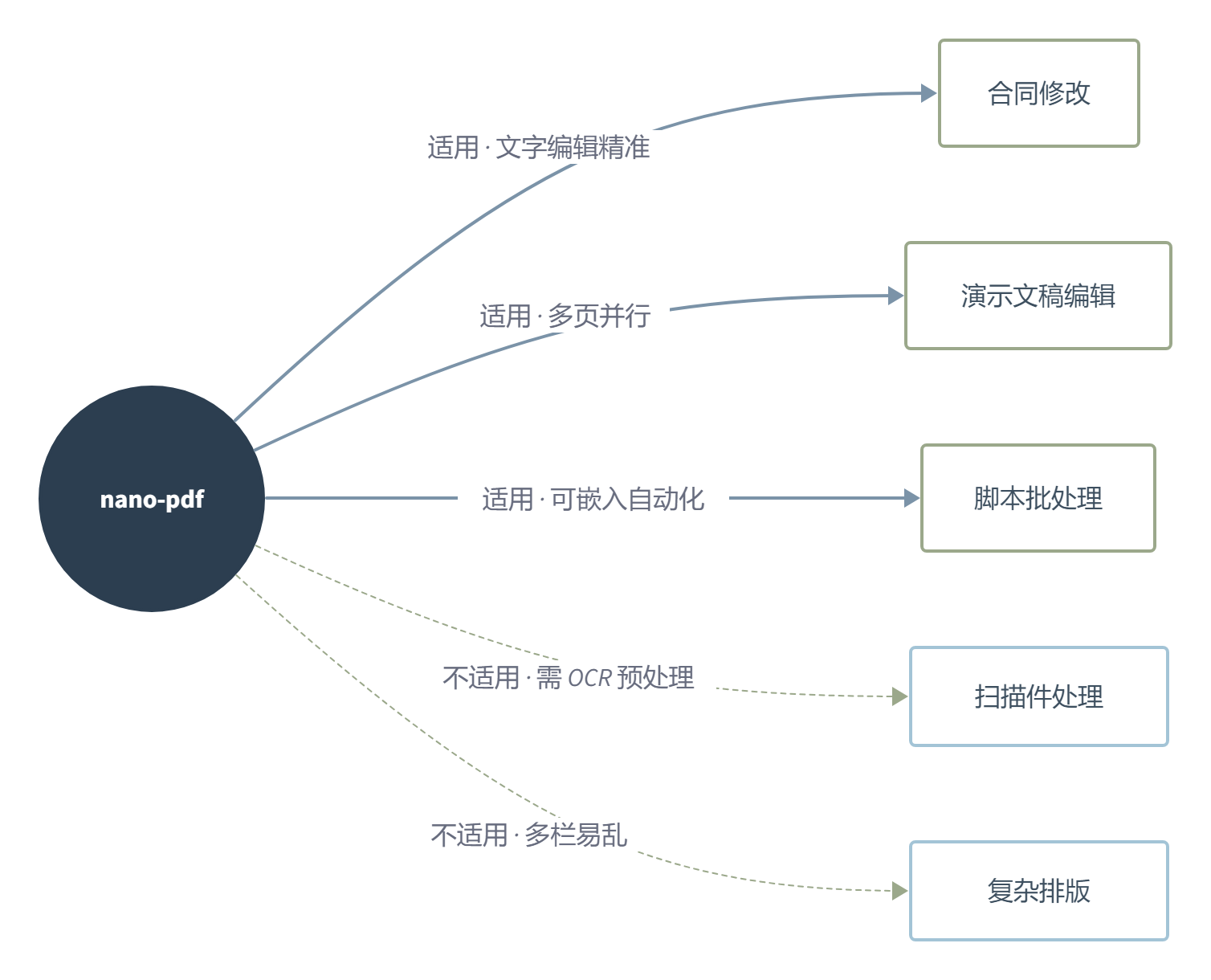
合同修改是 nano-pdf 最直观的场景。法务或商务收到一份 PDF 合同,需要把第五条的价格从 50 万改成 48 万,把甲方的注册地址更新一下。以前得打开专业软件,找到对应页面,小心翼翼改数字,祈祷排版不变形。现在就是一条命令的事。
演示文稿的批量调整是另一个刚需。做了 50 页的季度汇报 PPT 导出成 PDF,老板说”所有页面日期改成今天”、“页脚公司名换个颜色”。nano-pdf 的多页并行编辑在这种场景下直接把痛苦指数降了两个数量级。不过注意,复杂排版的支持还不太行,多栏布局和图文混排的页面编辑后容易乱。
报告合并和页面提取也是 nano-pdf 的能力范围。从多个来源收集的 PDF 章节合并成完整报告,或者反过来从几百页的文档里抽出第 3 章单独存档。这些操作在传统工具里也是几步菜单的事,但 nano-pdf 赢在你可以把它嵌到自动化脚本里,批量跑,无人值守。
但我得说实话:nano-pdf 不是 Adobe Acrobat 的替代品。扫描件 PDF 完全处理不了,因为没有文字层可以识别。合并 PDF 后原文件的书签会全部丢失,得手动重建。文件大小方面,免费版建议单文件不超过 50MB。如果你是 PDF 重度用户,需要处理复杂排版、大型文件、精细调校,nano-pdf 会让你觉得不够用。
洞察与反思
nano-pdf 最让我觉得有意思的,不是它”用自然语言编辑 PDF”这个表面功能,而是它选了一条跟整个 PDF 编辑行业相反的路。
传统 PDF 编辑器的逻辑是”理解 PDF 内部结构,精确操控每一个对象”。Adobe 花了几十年打磨这个能力。nano-pdf 的做法是”我不需要理解 PDF 内部结构,我把页面当图看”。这种路径选择本质上是用 AI 的视觉理解能力替代了对 PDF 格式规范的深度依赖。代价是精确度下降,收益是极度简化。这不是一个”更好或更差”的问题,是一个”你在乎什么”的问题。
| 维度 | nano-pdf | Adobe Acrobat |
|---|---|---|
| 操作方式 | 自然语言命令 | 菜单 + 工具栏 |
| 精确度 | 依赖 AI 视觉理解,偶有偏差 | 文档对象级精确控制 |
| 学习成本 | 接近零 | 需要一定学习 |
| 扫描件处理 | 不支持 | 支持 OCR |
| 复杂排版 | 容易乱 | 稳定 |
| 多页批量 | 单命令并行 | 需逐页操作或宏 |
| 定位 | 轻量快速修改 | 专业全功能 |
从某种角度看,nano-pdf 的价值不在”能编辑 PDF”,而是”把 PDF 编辑这件事从专业工具下沉到了命令行”。它能做的事 Adobe Acrobat 都能做,做得还更精确。但它能做的事,在一个自动化脚本里、在一个 Agent 的工作流里、在一个半夜三点只想改两个字不想打开大软件的场景里,Adobe 做不到这么轻。
API 付费是绕不开的问题。Gemini 3 Pro Image 需要付费层,nano-pdf 的每次编辑都要消耗 API 额度。改一页大概消耗多少 Token?文档没有明确说,但从模型的定价结构推断,单页修改的成本在几美分级别。对偶尔用一下的人来说不痛不痒,但每天处理上百页 PDF,成本会迅速累积。我怀疑这也是 nano-pdf 被标记为 Alpha 状态的原因之一,经济模型还没稳定下来。如果后续能接入更便宜的视觉模型或支持本地模型,它的实用性会再上一个台阶。
资源地址
| 资源 | 地址 |
|---|---|
| ClawHub | https://clawhub.ai/steipete/nano-pdf |
| PyPI (CLI 工具) | https://pypi.org/project/nano-pdf/ |
| GitHub (CLI 源码) | https://github.com/gavrielc/Nano-PDF |
总结
回头看 nano-pdf 做的事情其实很简单:把 PDF 编辑从”操作文档对象”变成”描述你想要的结果”。这个转换带来的体验变化比功能本身更大,就像从”手动挡”切到”语音导航”,你不需要知道引擎怎么工作了。
但它的能力天花板也是肉眼可见的。扫描件不行,复杂排版容易乱,文件大了吃力,API 要付费。说到底,nano-pdf 适合那些”我就想改几个字,别让我打开一个 2GB 的软件等它启动”的场景,不适合”我要精细控制 PDF 的每一个像素”的专业需求。
装好 nano-pdf 后,找一份你自己的 PDF(合同、论文、报告都行),用 nano-pdf edit your-file.pdf 1 "修改 [具体内容]" 试着改一页。观察两个东西:改得准确吗?改完后排版有没有走样?根据结果决定它适不适合你的日常场景。
FAQ
Q: nano-pdf 适合什么人用?
A: 日常需要轻量修改 PDF 的人。法务改合同条款、行政合报告、运营调演示文稿、开发者在脚本里批量处理 PDF,都是好场景。不适合需要精细排版控制的设计师和 PDF 重度编辑者。
Q: 免费能用吗?
A: 不能。Gemini 3 Pro Image 需要付费 API Key,免费层不支持图像生成。你需要在 Google AI Studio 开通付费账单后才能使用。
Q: 扫描件 PDF 能改吗?
A: 目前不能。nano-pdf 依赖 OCR 识别文字,扫描件本身没有可识别的文字层。需要先用专门的 OCR 工具把扫描件转成可编辑格式。
Q: 和 Adobe Acrobat 比差多少?
A: 功能维度上差距明显,nano-pdf 是剪刀,Adobe Acrobat 是瑞士军刀。但使用门槛上 nano-pdf 碾压,一条命令 vs 学习一套操作体系。选哪个取决于你要的是”快”还是”强”。
Q: 有免费替代方案吗?
A: LibreOffice Draw 可以免费编辑 PDF 文字,但需要手动操作。在线工具如 Smallpdf、iLovePDF 免费版有次数限制。目前没有直接用自然语言免费编辑 PDF 的等价替代。