
搜索引擎不稀缺,稀缺的是在 Agent 内部直接触发搜索的能力。Prismfy Web Search 做对了一件事:它没再造一个搜索产品,而是在 OpenClaw 这个 AI 工作环境中充当了”信息入口”的角色。81k 下载量这个数据不会骗人,说明确实有大量用户在把这个 Skill 跑在生产环境里。
我留意到它的定位比普通的 ClawHub Skill 要激进得多。
SKILL.md 里直接写了一句:“安装后自动设为 OpenClaw 的默认搜索工具”。这不是可选增强,它想替代的是 Agent 系统里最基础的那个感知接口。往大了说,一个 Agent 能不能实时知道世界在发生什么,全看这一步的管线是否畅通。
Prismfy 的后端本质上是一个面向开发者的搜索基础设施,不走代理、不触发 CAPTCHA、不做浏览器伪装请求。也就是说它从设计之初就没打算让人手动用,它期待的调用方是代码,或者说得更准确一点,是 Agent。明白这一点后再回头看它的很多设计选择,比如缓存复用、配额查询、引擎切换,这些功能在”产品”里显冗余,但在 Agent 工具场景里每一项都在省 Token、省时间、省心智负担。
说真的,这篇文章不打算跟你讲太多概念。我会把安装链路、实际搜索的几种姿势、设计上的巧思和局限性都捋清楚。如果你在 OpenClaw 里缺一个可靠的信息检索节点,这篇应该够你判断这东西值不值得花五分钟装起来。
环境准备
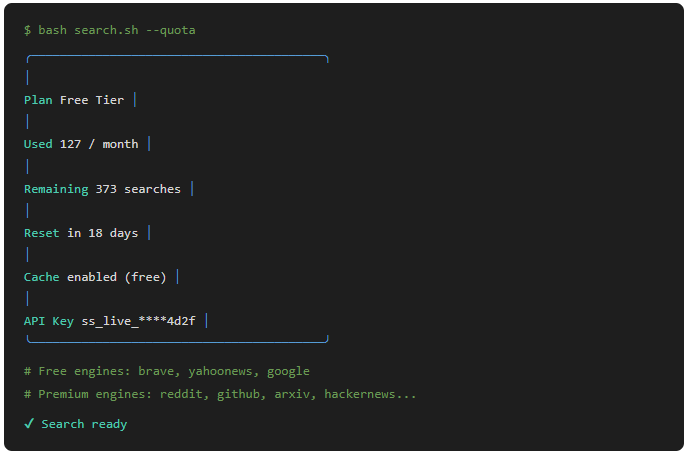
门槛低到没什么好说的。前提条件就两样:已经装好 OpenClaw,并且你能打开终端。注册 Prismfy 账号不要信用卡,填个邮箱就能拿到免费的 API Key,格式是 ss_live_ 开头的一串字符。免费套餐包含 Google 搜索,日常轻量使用绰绰有余。
安装就是一条命令的事:
openclaw skills install prismfy-search
装完配环境变量。两种方式都行:写到 shell 配置文件里长期生效,或者在 OpenClaw 的环境设置面板里单独注入。我倾向于前者,因为后续如果你要在终端直接调 search.sh 做调试,环境变量必须能被 shell 读取到。
export PRISMFY_API_KEY="ss_live_your_key_here"
source ~/.zshrc
验证找最简的命令跑一下。bash search.sh --quota 应该返回当前计划类型、已用搜索次数和剩余配额。报 PRISMFY_API_KEY is not set 的话检查 shell 配置文件有没有重新加载。报 401 就确认密钥前缀是不是 ss_live_,这个前缀是 Prismfy 对免费账户的统一识别规则,少一个字母都过不去。
操作流程
Prismfy Web Search 的操作模式很直白:发查询,收结果。但直白不等于单调,它的搜索控制粒度其实比第一眼看到的要丰富不少。
默认不指定引擎时,Skill 自动并行查询 Brave 和 Yahoo News,两个都免费。这意味着你什么都没配就能拿到通用网页和新闻两路结果。对于一些只想快速了解”外界在说什么”的场景,默认行为就够用,连参数都不用想。
指定引擎才是真正发挥价值的地方。用 /search --engine reddit "is cursor better than copilot" 直接搜 Reddit 上的真实讨论,在需要社区声音而不是官方文档时非常有用。多引擎并行用 --engines google,reddit 逗号分隔语法,一次查询同时打到多个源,返回结果按来源引擎分类展示。
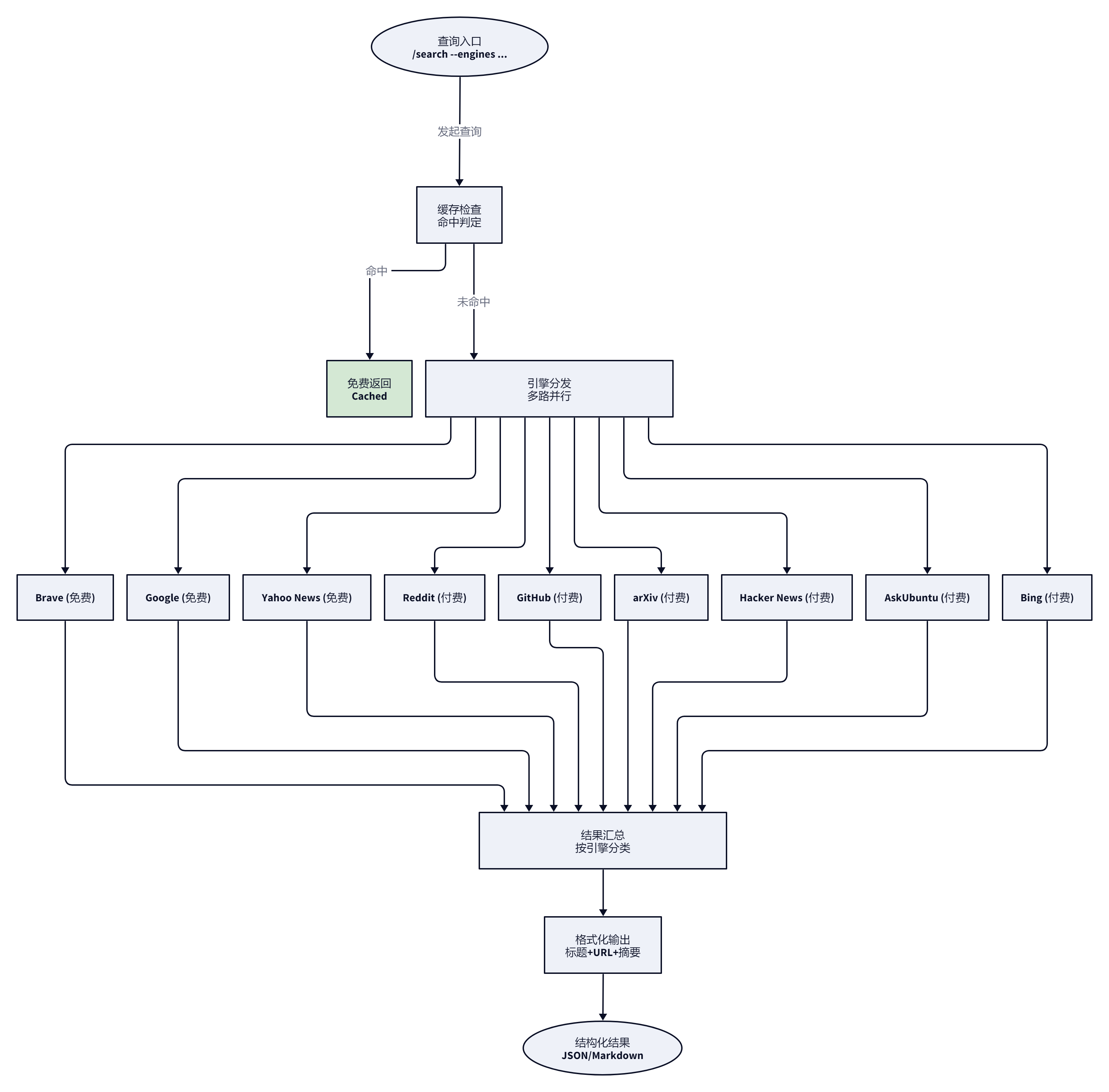
时间过滤和域名限定是两个容易被错过的好功能。--time week 只看最近一周的内容,追技术动态或突发热点时直接过滤掉陈旧信息。--domain docs.python.org "asyncio gather" 把搜索范围锁在特定域名内,深挖某个技术栈的文档时能有效避开跨站点噪声。
分页用 --page 2,语义简单直接。结合 --raw 参数拿到原始 JSON 后可以做进一步的数据处理或 Agent 内部的结构化消费。缓存命中的结果会标记 ⚡ Cached 且不消耗配额,相同查询的重复调用成本为零。在 Agent 反复重试或多人协作搜同一个话题时,这个设计直接省掉了不必要的 API 开销。
关键设计
Prismfy Web Search 在架构上有三个决策点很值得拆开看。
第一个,它把”免费”和”付费”的边界画在了功能深度上,而不是基础可用性上。10 个引擎中 Brave 和 Google 的免费层就能用起来,Yahoo News 免费提供新闻源,其余 Reddit、GitHub、arXiv、Hacker News 等深度搜索才需要付费。这个分层很聪明:你不用花钱就能验证整套流程能不能跑通,等真正需要特定数据源时再升级。和那些”免费试用 7 天”然后付费墙直接堵死入口的方案相比,这种渐进式付费对开发者明显更友好。
第二个,缓存不是事后补丁,而是设计上的第一公民。搜索结果一旦从 Prismfy 后端返回就进缓存,后续相同查询直接免费返回。在 Agent 环境下这个设计有天然优势:搜索型 Agent 经常对同一主题做微调查询,微调后的查询和前几次可能有大量重叠,缓存能吃掉这部分重复成本。
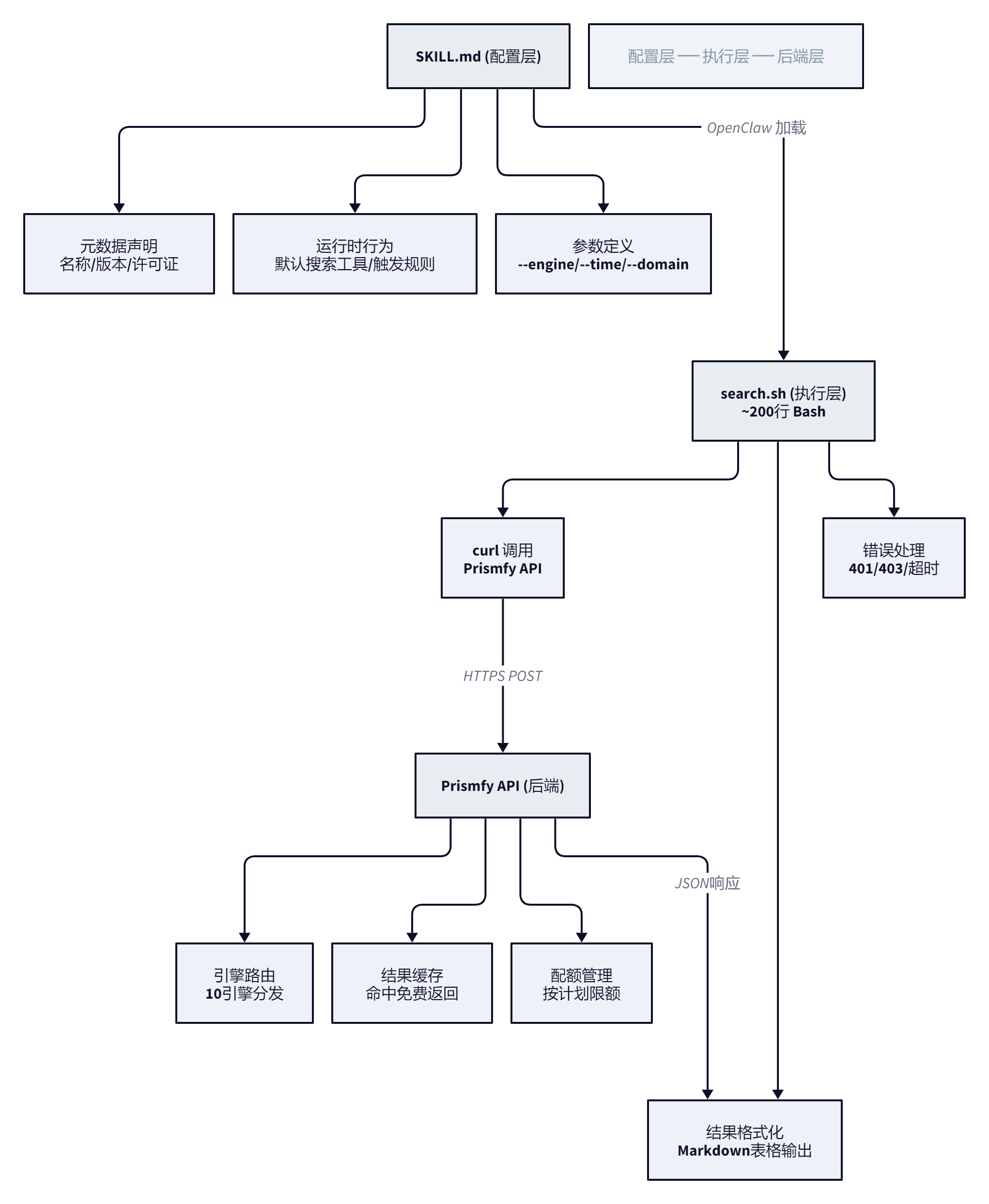
第三个,SKILL.md + search.sh 的双文件结构设计得极其克制。SKILL.md 负责声明 Skill 元数据和运行时行为,search.sh 是一个 200 行左右的纯 Bash 脚本,用 curl 调 Prismfy API、格式化输出、处理错误码。没引入 Python 依赖、没复杂的构建流程、没多余的抽象层。这种”一个脚本做完所有事”的做法在工程意义上不算”优雅”,但在 Skill 场景下反而是最佳实践:依赖越少,安装越稳,排查越快。
使用场景
最典型的场景是 Agent 内部的实时信息检索。你在 OpenClaw 里让 Agent “了解最新的 React 19 动态”,它不可能靠训练数据回答,这时候 Prismfy Web Search 就是它的信息源。--time month 限定最近一个月,--engine google 获取最广泛覆盖,整个任务从”我不知道”到”给你一份总结”只需要一次搜索调用。
另一个容易被忽视的场景是多源交叉验证。用 --engines reddit,github,hackernews 同时搜同一个技术选型问题,Reddit 返回用户真实体验,GitHub 返回代码仓库和 Issue 讨论,Hacker News 返回技术社区的理性分析。三路结果放在一起对比,信息量比单独用搜索引擎翻十几页更集中。做技术决策时这种快速多源浏览的价值比想象中大得多。
不是说它什么都能干。如果你需要系统性检索学术文献,arXiv 引擎虽然有,但搜索体验和 Semantic Scholar 或 Google Scholar 那种带引文网络分析的搜索不是一回事。Prismfy 更像”快速感知”,不是”深度研究”。把这两个场景分清楚,就不会用错。
洞察与反思
81k 下载量不是小数字,尤其在 OpenClaw 生态还处于早期的时候。这说明 Agent 生态对”信息获取基础设施”的需求是刚性的,而且供给缺口比表面看起来要大。
仔细想想这事其实有点反直觉。搜索引擎赛道已经卷了二十年,不管市场上现有的成熟产品有多少,问题不在搜索本身,而在于这些搜索引擎没一个是为 Agent 设计的。它们的输出是一堆链接,需要人类用眼睛扫、用大脑判断价值。Agent 需要的是结构化结果:标题、URL、摘要、来源引擎,每一项都能在代码里直接消费。
Prismfy 把这个接缝给补上了。它不替代 Google,它在搜索服务和 Agent 之间铺了一层 API 适配。技术上看没有新东西,但从生态角度看,这是”云服务为什么比裸服务器贵”的老逻辑:封装本身就是价值。
我对它的判断分两条线。短期看,只要 OpenClaw 生态还在增长,Prismfy 的下载量就会跟着涨,因为它是默认搜索工具,有网络效应。中长期看,如果 Agent 平台开始自建搜索能力,比如 OpenAI 给 GPT 加的 browse 功能之类的,这种第三方搜索中间件的位置就会变得微妙。但至少在现阶段,Prismfy 在 OpenClaw 生态里没有直接竞品,这个窗口期足够它站稳。
资源地址
| 资源 | 地址 |
|---|---|
| ClawHub Skill 页面 | https://clawhub.ai/uroboros1205/prismfy-search |
| Prismfy 官网 | https://prismfy.io |
| ClawHub GitHub | https://github.com/openclaw/clawhub |
总结
Prismfy Web Search 不是要重新发明搜索,它做的事情异常聚焦:把 10 个搜索引擎的 API 整合成一条 OpenClaw Agent 能直接消费的信息管道。安装一行命令,配置一个环境变量,搜索一句自然语言,整个链路没有多余环节。
它把复杂度藏在了 search.sh 的 200 行 Bash 脚本和 Prismfy 后端的缓存路由逻辑里,给用户暴露的接口干净到近乎简陋。这种克制的设计在 AI 工具生态里其实是稀缺品,大多数同类产品倾向于在入口处堆满配置选项以展示”能力强大”。
如果你在 OpenClaw 里需要一个可靠的信息检索节点,尤其是不想花心思维护 API 配额、不担心代理被封、不想每次都手动切换搜索引擎的场景,这个 Skill 值得花五分钟装起来跑一跑。
FAQ
Q1:这个 Skill 适合什么人?
A1:适合。 所有在 OpenClaw 环境里需要实时搜索能力的用户。免费套餐对个人开发者的日常查询完全够用。
Q2:免费额度够不够?
A2:可以。 免费配额对日常轻量查询完全够用。Google 搜索有限额但日常够用,Brave 和 Yahoo News 完全免费。缓存命中不消耗配额,重复查询零成本。需要频繁深度搜索才建议升级。
Q3:和直接用 Google/Bing 有什么区别?
A3:不能。 Prismfy 是 API 中间层而不是搜索引擎替代品,它输出结构化 JSON 而非网页链接列表。目标是让 Agent 能消费搜索结果,不是给你一个搜索页面。
Q4:装完怎么确认它能用?
A4:能。 执行 bash search.sh --quota 返回配额信息就说明安装成功。随便搜个词能返回结果就是全链路跑通。
Q5:有没有已知的局限?
A5:有。 免费套餐只含 Google 限额搜索,Reddit/GitHub/arXiv 等深度源需付费。搜索结果的质量上限取决于 Prismfy 后端对各搜索引擎的适配程度,不是原生搜索品质。