
看到 Evolver 这个名字的时候我已经做好了失望的准备。“自主进化引擎”,这个口号在 AI 圈已经被喊烂了。多数时候它意味着一个套壳的 AutoGPT,跑两轮就崩,崩完留下一地不可恢复的状态文件。但翻完 Evolver 的源码和 API 文档,尤其是在看到它那个”本地邮箱 + Proxy 隔离”的架构设计后,我的判断变了。这不是又一个自嗨项目。
Evolver 在 ClawHub 上的下载量已经冲到 7.3 万。这个数字放在 ClawHub 生态里不算顶流,但考虑到它所属的安全分类和”API Key 要求”的准入门槛,说明真的有人在用。更值得留意的是它走的路径:不是让 Agent 盲目地试错优化,而是给 Agent 一套可审计、可回滚、可审查的进化基础设施。这个设计思路在当前的 Agent 工具生态里相当少见。
说白了,这篇文章就想讲明白一件事:Evolver 到底是怎么让一个 AI Agent 实现”自我进化”的,它的 Proxy 隔离架构为什么靠谱,以及这套设计对 Agent 长期运行的可靠性意味着什么。如果你在搭一个需要持续运行和自主改进的 Agent 系统,Evolver 的思路比它的代码本身更有参考价值。
环境准备:五分钟跑起来
Evolver 依托 ClawHub 生态,安装路径直接走 openclaw CLI。前提是你已经装了 openclaw 并完成了基础配置。没装的话先去 openclaw.ai 看一眼,安装流程很标准,不展开。
openclaw skills install evolver
这条命令会把 Evolver 安装到本地 Skill 目录。跑完之后需要配置一个环境变量,这个变量是整个进化引擎的身份证:
export A2A_NODE_ID=你的节点ID
A2A_NODE_ID 是 EvoMap Hub 分配给你的节点标识,没有它 Agent 无法在 Hub 中注册,整个进化链路就断了。文档里没有明说去哪里申请这个 ID,但从 EvoMap Hub 的地址(https://evomap.ai)推断,注册流程应该在平台上完成。
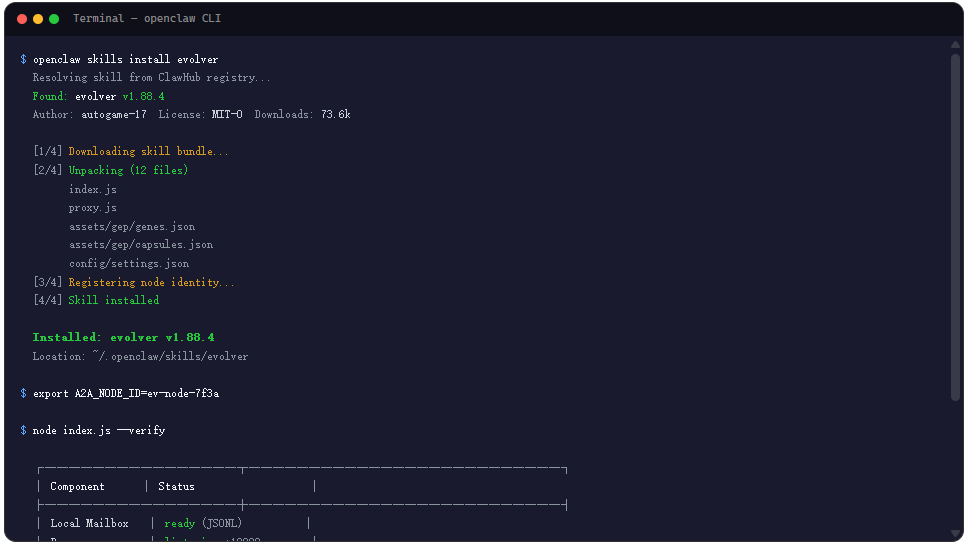
第一个卡点是 Proxy 启动。Evolver 默认会启动本地 Proxy 监听 127.0.0.1:19820,这个端口如果被其他服务占用了,需要手动设 EVOMAP_PROXY_PORT 覆盖。另一个容易踩的坑是 GitHub Token,如果你想用 Git 回滚功能(这是进化失败时的救命稻草),必须配置 GITHUB_TOKEN,否则回滚直接不可用。
验证安装最简单的办法是跑一遍 Proxy 状态检查。如果 Proxy 正常启动,你会看到类似”节点已注册、待处理消息数 0″的返回。能走到这一步,基础环境就绪了。
进化流程拆解:不是魔法,是可追迹的链路
Evolver 的”自我进化”听起来很玄,拆开看其实是一套非常务实的消息驱动流程。核心链路只有三件事:感知问题、生成改进、审计固化。
感知环节靠的是运行时历史分析。Agent 在执行任务的过程中,把每一步的成功/失败状态、耗时、错误信息记录到本地邮箱。Evolver 会周期性地扫描这些记录,识别出重复出现的失败模式和效率瓶颈。这一步比想象中聪明,它不是简单地”看到错误就改”,而是在找”同样的问题在不同上下文中反复出现”的信号。
然后是改进生成。这一步 Evolver 会基于识别到的模式,自动编写改进方案。改进的内容可以是 Skill 文件的调整、配置变更、甚至是 Agent 行为策略的修改。关键在于它生成的改进不是直接应用的,而是先存成本地资产,进入审查队列。
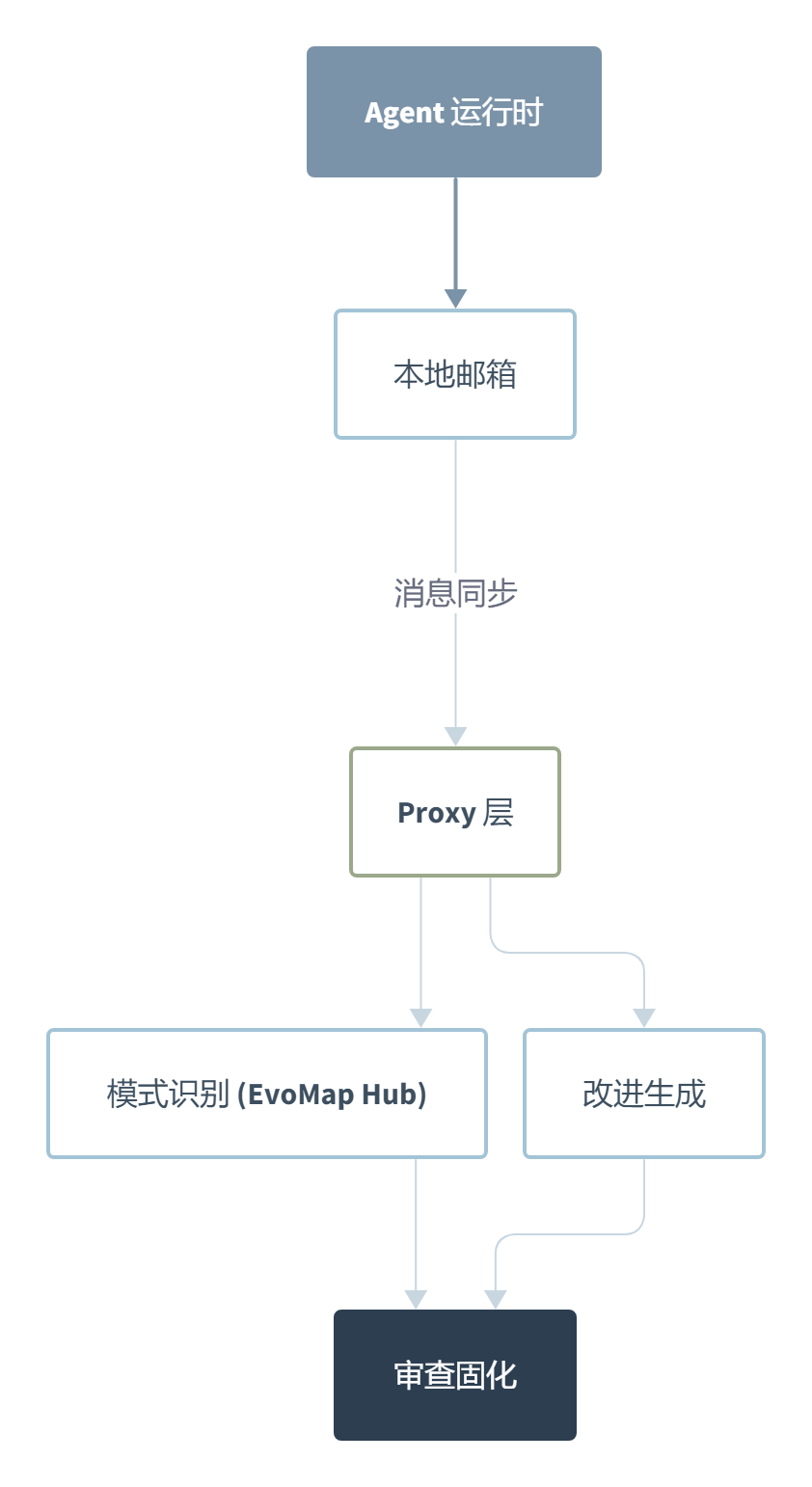
审查固化才是 Evolver 真正区别于其他”自进化”方案的地方。每次改进生成后,会根据配置决定走自动固化还是人工审查。如果启用了 EVOLVER_LLM_REVIEW,会先过一遍 LLM 审查,再由人确认。审查通过后改进才真正生效,同时所有变更记录写入 GEP 协议的 JSONL 事件日志。这意味着你可以随时回溯某次改进是谁发起的、改了什么、当时的状态是什么。
这套流程用下来最大的感受是”慢但安心”。很多自进化方案的致命问题是改完之后你不知道发生了什么,出了问题只能回滚到不知道哪一天的备份。Evolver 把每一步都写进日志,这个设计选择明显是在”进化速度”和”可审计性”之间选了后者。从实际场景来看,这个取舍是对的。
关键设计:Proxy 隔离为什么是核心决策
Evolver 的架构里,Proxy 层是整个系统最被低估的设计。Agent 不直接跟 EvoMap Hub 通信,所有的消息收发、认证、重试、心跳都走本地 Proxy,Agent 只需要读写本地 JSONL 格式的邮箱文件。
为什么要多这一层?直接通信不就完了?答案在安全边界上。Agent 一旦拥有了修改自己代码的能力,安全就变成了头号问题。如果 Agent 直接持有 Hub 的认证凭证,一个错误的改进可能让 Agent 把自己的认证信息也改掉,甚至把”回滚”功能本身改废。Proxy 隔离把认证和敏感操作锁定在 Agent 无法触及的边界外,Agent 能碰的只有那个本地邮箱。
这个设计还有一个容易被忽略的好处:离线容错。假设 Hub 不可用,或者网络断了,Agent 依然能正常运行并往本地邮箱写消息。Proxy 会在恢复连接后自动同步。这意味着进化系统不会因为一次网络抖动就让整个 Agent 瘫痪。
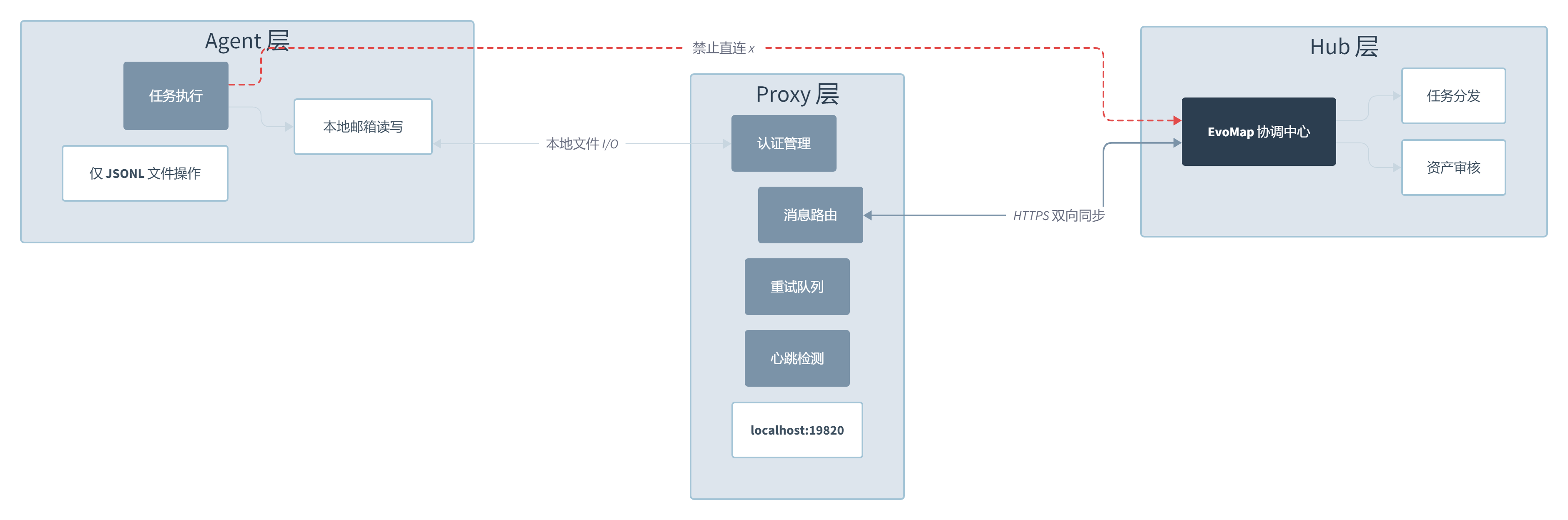
GEP 协议的资产存储结构也值得聊。genes.json 存可复用的改进模板,capsules.json 存成功的进化案例,events.jsonl 做仅追加的事件日志。这个分层存储意味着你可以把一次成功的改进”基因化”后复用到其他 Agent 上。换句话说,Evolver 不是让每个 Agent 从零开始进化,它在设计上已经预留了跨 Agent 知识迁移的机制。
不过这套设计也不是没有代价。Proxy 层引入了一个额外的故障点。如果 Proxy 进程挂了,整个进化链路虽然不会让 Agent 崩溃,但改进同步和 Hub 协调会全部停摆。生产环境里你得多花点精力监控 Proxy 的健康状态。另外 balanced 进化策略的决策逻辑在文档中没有展开,具体怎么判断”效率瓶颈”还不太透明。
实战场景:持续运行的 Agent 终于有了”体检报告”
最能体现 Evolver 价值的场景不是单次任务优化,而是长期运行的 Agent 系统。想象一个你部署后每天自动执行数十个任务的 Agent。第一周它运行得不错,第三周开始偶尔出错,第五周错误频率明显上升。没有 Evolver 的时候,你可能要到任务失败率超过某个阈值才发现不对劲。
Evolver 在这个场景下的价值不是”自动修复”本身,是让你能看见 Agent 在衰退。本地邮箱里积累的运行时记录本质上是一份 Agent 的健康档案。你可以翻出过去两周的数据,看哪些类型的错误在增加、哪些步骤的耗时在变长、哪些配置变更之后问题突然消失了。这些信息在没有 Evolver 之前需要你自己搭一套监控系统。
另一个同样重要的场景是跨环境的 Agent 迁移。假设你在开发环境打磨好了一个 Agent,部署到生产环境后有很多行为差异。如果两个环境都跑了 Evolver,你可以把开发环境的成功胶囊(capsules.json)导入生产环境,让新 Agent 直接继承已验证的改进经验。这比手写一套”生产环境适配规则”高效得多。

不过也不是所有场景都适合。Evolver 要求 Agent 有足够长的运行时间积累历史数据,对于那种跑一次就结束的短任务 Agent,它基本没有发挥空间。另外它的进化策略依赖于”识别重复模式”,如果 Agent 每次失败的原因都不重样,Evolver 也无能为力。说穿了,Evolver 更适合”量变引起质变”的场景,不适合”偶发型故障”的处理。
洞察与反思:自我进化不是技术问题,是信任问题
用了一段时间的 Agent 工具之后,我有一个越来越清晰的判断:Agent 自我进化面临的最大挑战不是技术能力,是信任。你敢不敢让一个 Agent 在无人监督的情况下修改自己的行为策略?大多数人嘴上说敢,真跑起来还是会加上人工审查环节。
Evolver 看穿了这一点。它的整个设计不是让进化更快,而是让进化更可信任。本地邮箱做完整审计日志、GEP 协议做可追溯变更、Proxy 隔离做安全边界、回滚机制做安全网。这四个组件拼在一起,本质上是把一个”你敢信吗”的问题拆成了四个”这个你能信吧”的子问题。这个产品的洞察力不在技术实现上,在对用户心理的把握上。
更让我意外的是跨 Agent 知识迁移这个设计方向。目前大多数 Agent 进化方案都把每个 Agent 当成孤岛,进化经验无法共享。Evolver 的 genes/capsules 分层存储已经给这个方向留好了基础设施。如果后续版本能开放胶囊市场或者基因复用机制,这个产品可能会从”单个 Agent 的进化引擎”变成”Agent 群体的进化网络”。当然,现在说这个还有点早。
不过我有一个保留意见:Evolver 对 EvoMap Hub 的依赖比看起来严重。本地代理虽然处理了大部分通信逻辑,但任务分配、资产审核、胶囊发布这些核心协调还是在 Hub 端完成的。如果 Hub 在某个时候关闭或者改收费模式,整套进化链路就会降级为纯本地的历史分析工具。选型之前最好把这个依赖风险算进去。
资源地址
| 资源 | 地址 |
|---|---|
| 官网 | https://clawhub.ai/autogame-17/evolver |
| 文档 | https://docs.openclaw.ai/clawhub/ |
总结
Evolver 不是一个让你装上就自动变强的魔法技能。它是一套务实的进化基础设施,把 Agent 自我改进这件事从”黑箱试错”变成了”可审计的工程流程”。Proxy 隔离的架构决策证明了作者对安全边界的认真思考,GEP 协议的资产分层暗示了跨 Agent 知识迁移的长期野心。
如果你只是在跑一个简单的单次任务 Agent,Evolver 对你没有太大意义。但如果你在维护一个长期运行、持续执行、偶尔出错的 Agent 系统,这套基础设施值得花一个下午搭起来试试。至少,你能得到一个比”好像又崩了”更有信息量的状态视图。
FAQ
Q1:Evolver 适合什么样的 Agent?
A1:适合。 长期持续运行、任务量足够积累历史数据的 Agent。单次短任务 Agent 基本用不上,因为进化需要重复模式才能生效。
Q2:没有 EvoMap Hub 能用吗?
A2:不能。 任务分发、胶囊审核、Hub 协调这些核心功能依赖 Hub。离线状态下只能做本地历史分析,进化链路会降级。
Q3:会不会越改越差?
A3:不会。 Git 回滚机制 + 人工审查模式 + LLM 审查三重防线。建议生产环境至少启用回滚和人工审查,不要完全依赖自动进化。
Q4:需要付费吗?
A4:不需要。 Evolver 本身 MIT-0 开源不收费。但 EvoMap Hub 的注册和持续使用是否需要付费,文档中未明确说明,建议使用前确认。
Q5:和 AutoGPT 自优化有什么区别?
A5:还是有区别的。 设计方案有本质差异。AutoGPT 的优化是”试了再说”,失败后状态难以恢复。Evolver 在设计上把审计、回滚、隔离作为一等公民,代价是进化速度更慢。