
你给 AI Agent 交代了一堆偏好和决策,聊到第三轮它全忘了。你问它”上次说的那个方案还记得吗”,它回你一句”什么方案?”
这事我刚翻 ClawHub 数据时注意到一个很反常的信号:有个叫 Elite Longterm Memory 的 Skill,下载量 61.7k,GitHub 星标 221,看起来不大,但下载/星标比接近 280:1。这意味着什么?大部分人是直接冲着”解决 Agent 遗忘”这个刚需来的,根本懒得点星标。
这个 Skill 的思路也跟常规不一样。它不是让你加一个记忆配置文件就完事,而是把整个 Agent 的记忆拆成五层架构,像计算机的内存体系那样分级管理。从文档来看,它的设计哲学很明确:Agent 的记忆问题不是”存不下”,而是”该记的没记、不该记的写了一堆”。
说真的,这篇文章就是把我拆完这个 Skill 之后觉得最有意思的几个设计拿出来聊聊。为什么它把”写状态”放在”回复用户”之前?为什么用 Git 存决策而不是用数据库?Mem0 的自动提取到底省了多少 Token?你读完应该能对 Agent 记忆系统的设计多一层理解,哪怕你用的是 Cursor 而不是 OpenClaw。
环境准备:先跑通这个链路
Elite Longterm Memory 是 OpenClaw 平台的 Skill,安装方式很直接:
openclaw skills install elite-longterm-memory
一条命令装完,但别急着用。这个 Skill 对运行环境有要求,你的 Agent 必须是 OpenClaw 生态里的,不支持 Cursor 或 ChatGPT 直接挂载。要让它完整跑起来,至少需要三样东西:OpenAI API Key、Git、Python 3。
OpenAI Key 是用来驱动 LanceDB 的语义搜索的,没有这个,Layer 2 的向量召回就是摆设。Git 更关键,Layer 3 的冷存储完全依赖 Git Notes 来管理知识图谱。这两项缺一不可,Python 3 倒是只在运行 maintenance 脚本时才用上。
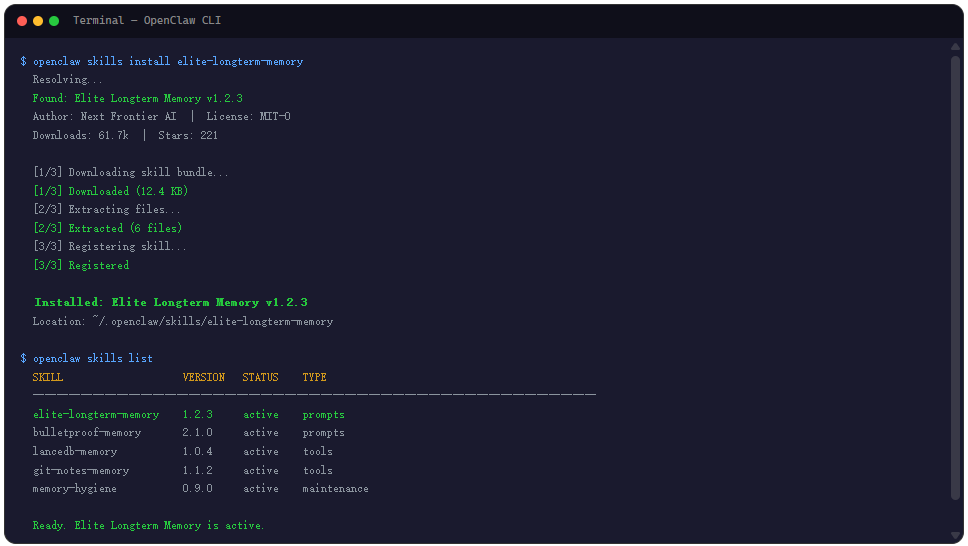
验证是否装好,跑个 openclaw skills list 就能看到。装完后建议第一时间把 OPENAI_API_KEY 配置好,不然到后面你会发现自己用了半天,实际的语义搜索能力根本没激活。这是新手最常踩的坑,文档里提了但很容易被跳过。
可选的两个增强组件:SuperMemory 做云备份,Mem0 做自动事实提取。Mem0 是推荐装的,能自动从对话里抽偏好和决策,文档说能减少 80% 的 Token 消耗,这个数据我没法独立验证,但从它的去重逻辑来看,确实比每次都把全量上下文塞进 Prompt 聪明得多。
操作流程:会话级记忆的完整链路
这个 Skill 把一次 Agent 会话拆成三个阶段:启动、运行、结束。每个阶段都有明确的内存操作,不是”想到了就记一下”的随意方案。
启动阶段的逻辑很有意思。Agent 不会直接开始对话,而是先做三件事:读取 SESSION-STATE.md 拿上次的活跃上下文,跑 memory_search 从 LanceDB 召回相关历史记忆,再检查当天的 memory/YYYY-MM-DD.md 了解最近活动。这三步走完,Agent 相当于快速”回忆”了一遍自己之前都在干什么,然后才进入对话模式。
这就是它跟普通记忆方案拉开差距的地方。常规做法是每次对话开始前把历史记录摘要塞进 System Prompt,但摘要到底要包含什么?是人写好的还是自动生成的?Elite Longterm Memory 把”启动时该加载什么”做成了结构化的多层查询,每一层有明确的职责边界,不是一股脑全塞进去。
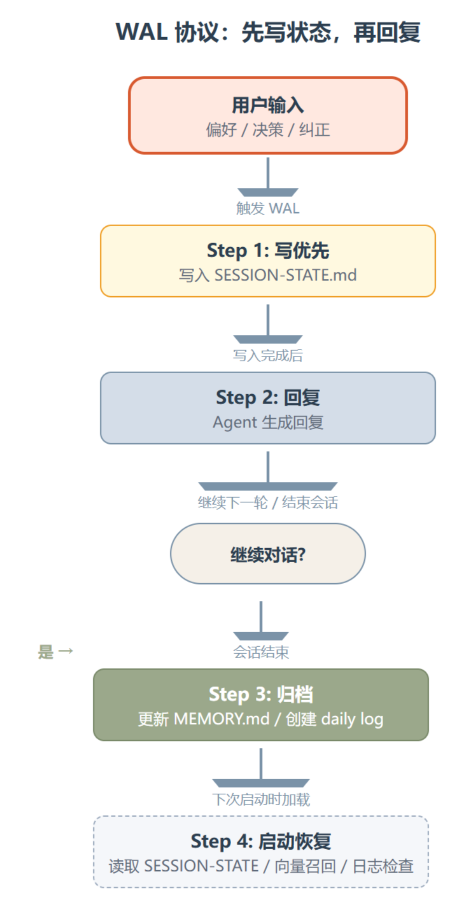
对话过程中,最核心的机制是 WAL(Write-Ahead Log)协议。这个协议来自数据库领域,用在 Agent 记忆上相当聪明:Agent 在被允许回复用户之前,必须先把自己刚接收到的关键信息写入 SESSION-STATE.md。用户说了偏好?先记。用户做了决策?先记。用户纠正了一个错误?先记。记完了,再回复。
这个”先写再回”的顺序是关键。一般的 Agent 都是先回应用户再试图记住什么,但这时候记忆很容易被新一轮对话打断或冲掉。WAL 协议强行把”记录”放在”回应”之前,确保即使在长对话中频繁切换话题,最近的关键上下文也不会丢失。
会话结束时,流程继续。Agent 把 SESSION-STATE.md 更新为最终状态,把有价值的持久信息迁移到 MEMORY.md,再创建或更新当天的 memory/YYYY-MM-DD.md 日志。这个收尾动作保证了 Layer 1 的热数据不会一直堆积,该归档的归档,该清理的清理。
每周还要做一次记忆卫生:审查 SESSION-STATE.md 归档已完成任务、检查 LanceDB 里的垃圾数据、把过期的每日日志整合到 MEMORY.md。文档里提供了一套命令可以直接跑,比如 memory_recall query="*" limit=50 审计向量记忆,rm -rf ~/.openclaw/memory/lancedb/ 做核弹级清理。
关键设计:为什么是五层而不是一层
这个 Skill 最值得拆的设计,是它的五层记忆分层架构。
Layer 1 热内存用的是 SESSION-STATE.md 纯文本文件。看起来太简单了对吧?一个 Markdown 文件做活跃工作记忆?但仔细想,这恰恰避开了数据库方案在会话场景下的问题:文件没有连接开销、没有查询延迟、Agent 可以直接 read_file 获取全部热上下文。对高频读写的活跃记忆来说,纯文本文件比任何向量数据库都快。
Layer 2 温存储是 LanceDB 向量数据库。这一层负责语义搜索,Agent 不靠关键词匹配找记忆,而是靠语义相似度自动召回相关上下文。支持 memory_recall 查询、memory_store 存储、memory_forget 删除。这里有个细节:autoRecall 默认开启但 autoCapture 默认关闭,说明设计者很谨慎,不想让 Agent 自动把对话内容全量写入向量库,只让它在需要时主动查询。
Layer 3 冷存储用的是 Git Notes,这个选择是最反直觉的。哪个正常人会用 Git 存 Agent 的记忆?但 Git Notes 有个天然优势:它是版本化、分支感知的结构化存储。Agent 在不同分支上工作时,记忆天然隔离。而且 Git Notes 是静默存储的,Agent 不会每次存记忆就跟用户说一句”我已经把这个决策记录下来了”,避免了对话中的噪音干扰。

Layer 4 和 Layer 5 是策展归档和云备份。MEMORY.md 是人类可读的长期记忆文件,按主题组织,控制在 5KB 以内,链接到更详细的子文件。SuperMemory 做跨设备同步,但需要额外 API Key。
这五层的设计本质上是把计算机的内存体系搬到了 Agent 域:寄存器→L1→L2→RAM→磁盘。热数据在最前面、高频访问用向量检索、低频但重要的决策用 Git 持久化、人类需要审阅的内容用 Markdown 文件。这个映射不是巧合,是设计者有意为之的结构选择。
但我也得说,这个设计有明显的上手成本。普通用户可能一辈子不会用到 Layer 3 的 Git Notes,Layer 5 云同步也不是必需。六步安装流程对非 OpenClaw 用户来说基本等于新学一个平台。这个 Skill 更适合已经在用 OpenClaw 并且每天跟 Agent 交互超过 2 小时的深度用户。
实战场景:两种典型用法
最常见的场景是 vibe-coding 开发模式。
假设你在用 OpenClaw Agent 写一个全栈项目,前端 React、后端 FastAPI,中间还夹了一层 WebSocket 通信。昨天的决策是”用 zustand 管理状态,不要用 Redux”,前天的决策是”API 路径统一用 /api/v1/ 前缀”。没有 Elite Longterm Memory 的情况下,Agent 每次启动都像失忆一样,你需要不停地重复”还记得我们用的是 zustand 吗?”
有了这套系统,Agent 启动时自动从 Layer 1 热内存读到当前任务上下文,从 Layer 2 向量库召回”zustand vs Redux 决策”和”API 版本规则”,从 Layer 3 Git Notes 找到项目分支下的架构决策记录。你不需要再说一遍。它甚至能在你做错的时候自动提醒你”之前决定用 zustand,这里引入 Redux 会冲突”。
另一个场景是长周期研究项目。你在做一个持续三周的数据分析,每天跟 Agent 讨论结果、调整假设。每天的进度、结论、被推翻的假设都记录在 memory/YYYY-MM-DD.md 里,每周整合进 MEMORY.md。三周后回看,整个项目的思考演变完整留存,不需要从聊天记录里翻找。
不过这个 Skill 也有明显的适用边界。场景持续时间太短的话,五层架构的维护成本会超过收益。如果只是偶尔让 Agent 帮忙改个 bug、调个格式,一个简单的 MEMORY.md 就够了。Elite Longterm Memory 是为那些把 Agent 当长期工作伙伴的场景设计的,不是给轻量交互用的。
洞察与反思:Agent 记忆的范式转移
拆完这个 Skill,我最大的感受是:Agent 记忆系统的核心问题不是技术选型,而是”写”和”读”的时序设计。
绝大多数记忆方案都在纠结”用什么存”:用向量数据库?用关系数据库?用文件系统?但 Elite Longterm Memory 把焦点放在了”什么时候记、什么时候读”上。WAL 协议强行把写入放在回复之前,LanceDB 的 autoRecall 让读取在对话开始时自动触发,Git Notes 的静默写入消除了”我记住了”这种无效反馈。
这个时序优先的思路让我重新审视了很多 Agent 系统的设计。大多数 Agent 框架把记忆当作事后处理——聊完了总结一下,存入数据库,下次搜一搜。但记忆如果只在对话边界触发,中间的认知状态就会不断流失。WAL 协议把记忆嵌入了每一次交互的中间,这才是”Agent 有连续意识”的前提。
从行业趋势看,这种多层记忆架构会越来越普遍。Anthropic 的 Claude 已经在推 System Prompt Caching,OpenAI 有 Conversation History API,但它们都是在模型层面做缓存优化,不是在 Agent 层面做记忆管理。Elite Longterm Memory 做的事更底层:让 Agent 自己学会”什么该记住、记在哪、什么时候用”。
我个人对这个方向持乐观态度,但也有一个保留:目前的实现依赖太多外部组件(LanceDB、Git Notes、SuperMemory、Mem0),每多一个组件就多一个可能挂掉的点。如果能把这些组件收敛到一个统一的记忆引擎里,同时保持分层设计的思想,适用面会宽得多。但话说回来,61.7k 的下载量说明很多人愿意接受这个复杂度,这本身就说明刚需有多强。
| 资源 | 地址 |
|---|---|
| ClawHub | https://clawhub.ai/nextfrontierbuilds/elite-longterm-memory |
总结
Elite Longterm Memory 不是”又一个记笔记的工具”,它是一套把计算机内存体系搬进 Agent 对话流的架构实验。五层分级、WAL 协议、静默写入、自动召回,这些设计放在一起,解决的不是”能不能记住”的问题,而是”记住的东西能不能在正确的时间点被用上”。
装完之后建议从 Layer 1 和 Layer 2 开始用,别一上来就配全五层。热内存和向量存储已经覆盖了 80% 的场景,Git Notes 和 SuperMemory 可以等真正需要了再加。Mem0 的自动提取是最值得投资的增强,如果你有 API Key,先装这个。
FAQ
Q1:Elite Longterm Memory 支持 Cursor 或 ChatGPT 吗?
A1:不支持。 它是 OpenClaw 平台的 Skill,依赖 OpenClaw 的 Skill 系统和运行时环境。Cursor 和 ChatGPT 有各自的记忆机制,不能直接复用这套方案。
Q2:设置复杂吗?大概要多久?
A2:不算复杂。 完整设置需要安装 OpenClaw、配置 OpenAI API Key、初始化 Git 仓库、设置 LanceDB 搜索,大约需要 15-30 分钟。如果只装 Layer 1 和 Layer 2,大概 5 分钟搞定。
Q3:Mem0 是什么?必须装吗?
A3:无需。 Mem0 是一个自动事实提取工具,能从对话中自动提取偏好、决策和事实,声称可减少 80% Token 消耗。它不是 Elite Longterm Memory 的核心组件,但如果你的 Agent 对话量大,装了之后效果明显。
Q4:和单文件 MEMORY.md 方案比有什么优势?
A4:本质不同。 单文件 MEMORY.md 是人手动维护的静态文本,Elite Longterm Memory 是多层自动化的记忆系统。核心差异在于自动召回和时序控制:单文件方案只在 Agent 启动时加载一次,Elite Longterm Memory 在对话过程中持续写入和查询。
Q5:这个 Skill 有安全问题吗?
A5:没有问题。 ClawHub 平台标注安全审计已通过。但所有记忆数据(包括 API Key 配置)都存储在本地,注意不要在 MEMORY.md 中明文记录敏感凭据。