
你有没有过这种体验:Agent 明明说”我帮你搜一下”,结果要么打开浏览器卡半天,要么返回一堆链接让你自己点。搜了个寂寞。
Brave Search 这个 ClawHub Skill 做了一件事:它把”搜索+提取内容”这两个动作打包成了一个 CLI 命令,不用开浏览器,不用调 Puppeteer,Agent 拿到的直接就是格式化好的 Markdown 文本。
说真的,这篇文章不会给你讲什么”搜索 API 的发展历程”。我就是把 Brave Search 这个 Skill 怎么装、怎么用、设计上有什么巧思和硬伤,一次性拆清楚。如果你在给自己的 Agent 搭搜索能力,看完这篇应该能少走不少弯路,至少不用再把浏览器方案和 API 方案各试一遍才做决定。
环境准备
装这个 Skill 之前有一件事必须先搞定:去 Brave Search API 官网注册一个账号,拿到 API Key。免费套餐每个月有一定额度的搜索配额,日常开发够用。
安装本身一条命令的事:
openclaw skills install brave-search
装完之后别忘了进 Skill 目录跑一次依赖安装,这一步很容易忘:
cd ~/Projects/agent-scripts/skills/brave-search
npm ci
最后把 API Key 设成环境变量 BRAVE_API_KEY。很多人这一步会卡住——不是忘了设环境变量,而是设了之后没重启终端,shell 没加载新的环境变量。一个小坑,但是第一道坎。
整个准备流程不超过五分钟,但每步都是硬依赖:没 API Key 搜不了,没跑 npm ci 脚本起不来。别跳过验证那一步,跑个 ./search.js "test" 确认通了再往下走。
操作流程
Brave Search 的核心用法简单到只有两个命令,但它把每个命令的分工拆得很清楚,不是那种”一个命令做所有事”的混乱设计。
搜索命令 search.js 负责从 Brave 的独立索引里捞结果。默认返回 5 条,加 -n 可以拉到 20 条的上限。最有用的是 --content 参数——加了之后每条结果会附带页面的完整 Markdown 正文,Agent 不需要再做二次抓取。
./search.js "Claude Code最佳实践" -n 10 --content
输出格式也很干净:每条结果一个分隔块,包含标题、链接、摘要片段,如果开了 --content 还会跟着页面的 Markdown 正文。这种结构化程度让 Agent 可以直接解析,不需要额外做文本清洗。
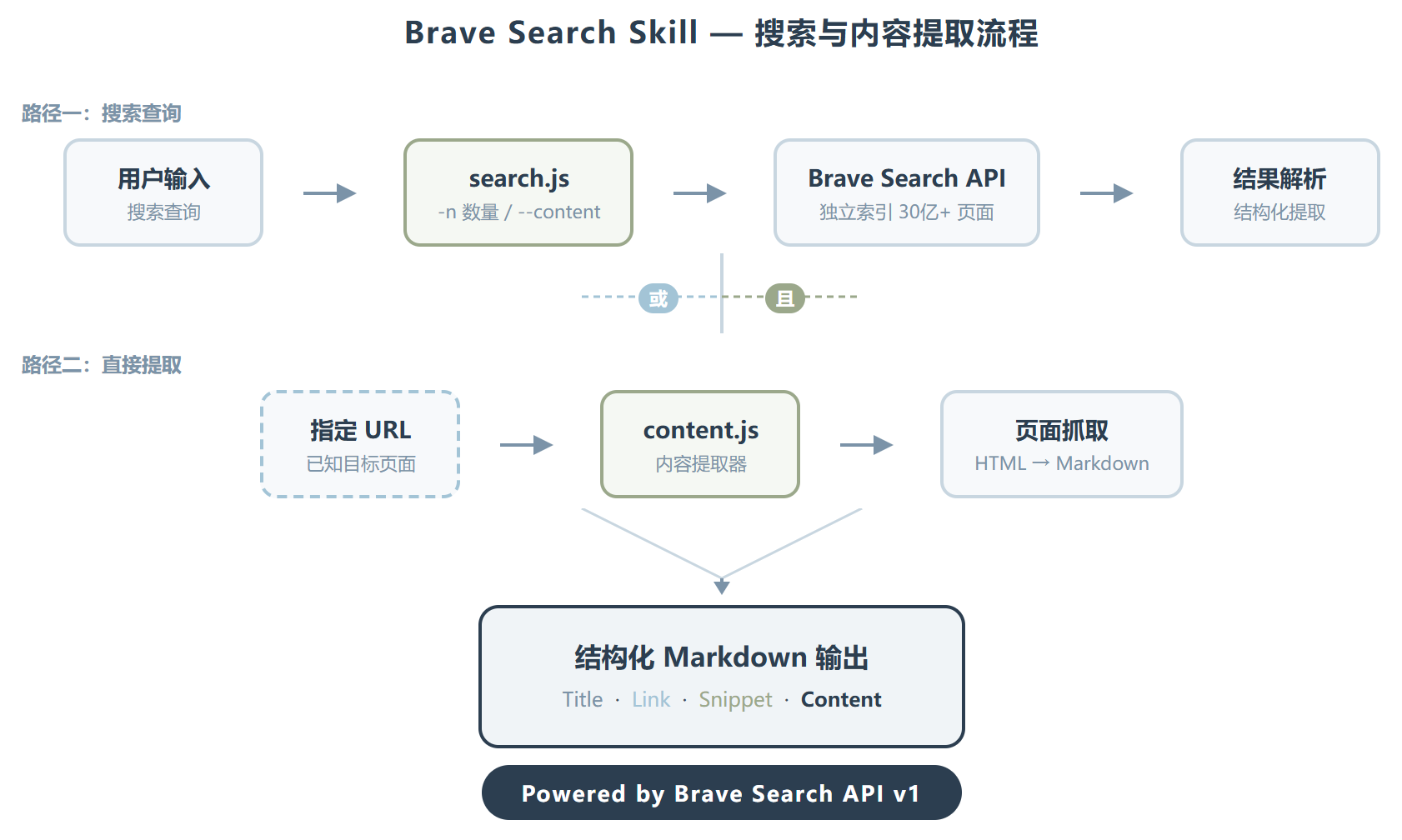
另一个命令 content.js 更直接——给它一个 URL,它把页面内容提取成 Markdown 返回给你。适合你已经有明确目标页面的场景,比如抓取一篇文档、提取一篇文章的正文内容,不需要走搜索那一步。
从文档结构推断,这两个命令的设计分工是经过深思熟虑的。搜索解决”找什么”的问题,内容提取解决”读什么”的问题。把这两步拆开而不是揉在一起,让 Agent 可以在不同阶段调用不同能力,避免了”搜一堆然后全部抓取”的浪费。
关键设计
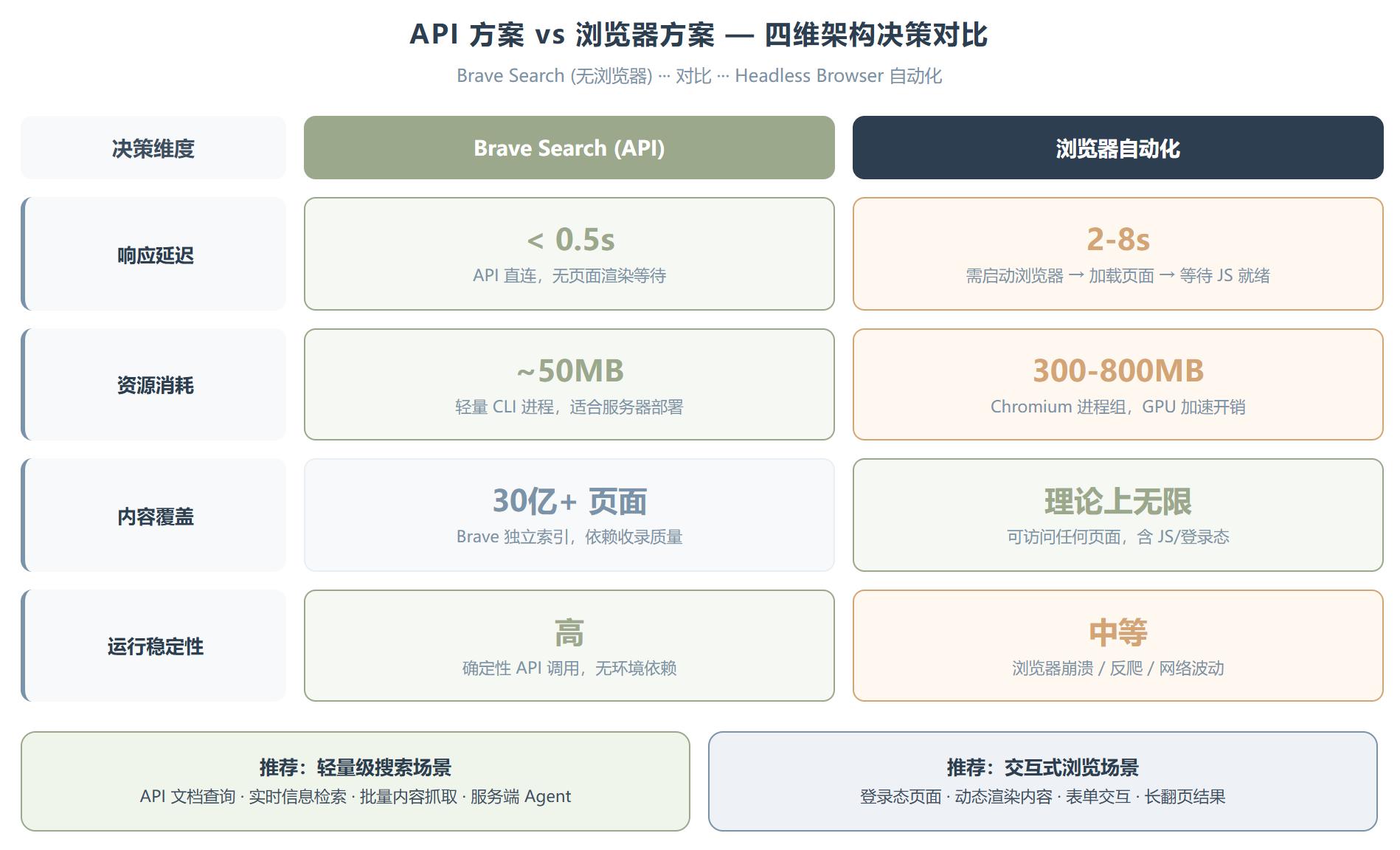
这个 Skill 最让我觉得有意思的设计决策,是它选择了”无浏览器”路线。
很多 Agent 搜索方案的思路是:启动一个 headless 浏览器,模拟人类上网搜索、点链接、读页面。这条路能力强,但代价也不低——启动慢、资源消耗大、对网络环境敏感,而且浏览器自动化本身就是不稳定因素。
Brave Search 走的是另一条路:直接调 API。不需要浏览器,不需要页面渲染,不需要等 JS 加载。这带来几个直接好处:启动几乎是瞬时的,内存占用极低,在服务器环境里跑也没什么负担。
但代价也很明显。API 方案完全依赖 Brave 的索引质量和覆盖面。如果 Brave 没收录某个页面,Skill 就搜不到。而且 search.js 一次最多返回 20 条结果,offset 上限也只有 9,意味着你最多能翻 200 条结果。对比浏览器方案”理论上可以无限翻页”,这个限制在某些深度研究场景下会捉襟见肘。

另一个值得提的设计:MIT-0 许可证。Peter Steinberger 没有选择 MIT 或 Apache 2.0,而是用了 MIT-0,比 MIT 更宽松,连版权声明的义务都可以省略。这个选择暗示了作者的意图:他希望这个 Skill 被最大程度地嵌入和分发,零摩擦。对于社区 Skill 来说,这是个聪明的战略选择。
还有一个容易被忽略的细节是输出格式的设计。每条搜索结果用 --- Result N --- 分隔,Title、Link、Snippet 各一行,结构极其规律。这种格式对 Agent 来说是理想状态:不需要 NLP 解析,不需要正则清洗,直接按行读就行。对比很多搜索工具返回的 JSON 嵌套结构或者 HTML 片段,Brave Search 的输出格式本身就降低了 Agent 消费信息的门槛。
使用场景
Brave Search 不是那种”什么都能干”的工具,它在几个特定场景下特别好用。
场景一:Agent 需要实时信息但受限于训练数据的截断日期。比如你问 Agent “最新的 React 19 有哪些 breaking changes”,Agent 可以直接调 search.js "React 19 breaking changes 2026" --content,拿到第一手的文档内容和社区讨论,而不是从 2024 年的训练数据里编答案。这种实时性对开发者社区类问题尤其关键,毕竟框架的 API 变化可能就在最近一个月。
场景二:批量文档研读。你不是搜一次就完了,而是有一串已知的 URL 需要逐篇提取内容。这时候 content.js 逐个调,每次返回结构化的 Markdown,Agent 可以直接把这些内容灌进上下文做分析。对比用浏览器逐个打开再复制粘贴,效率不在一个量级。
但有一些场景它确实不适合。如果你的搜索需求高度依赖交互式浏览,比如需要登录某个网站、需要点按钮筛选条件、需要滚动加载更多内容,那 Brave Search 帮不了你。这类场景老老实实用浏览器方案。另外,如果你需要搜索中文互联网内容(微信文章、知乎专栏),Brave 的索引覆盖明显不如 Google 和百度,搜出来的结果质量会打折扣。
洞察与反思
从社区反馈和下载量来看,59.3k 的安装量在 ClawHub 的 Data & APIs 分类里属于头部水平。这说明 Agent 开发者对”轻量级搜索”的需求是真刚需,不是伪需求。
但我认为 Brave Search 的真正价值不在搜索本身。市面上的搜索 API 多了去了,SerpAPI、Tavily、Google Custom Search,各有各的定位。Brave Search 这个 Skill 的差异化在于它把”搜索”这件事做成了 Agent 工具链里一个可组合的组件——不是一个独立产品,而是一个你可以在 Workflow 里自由编排的模块。
回头看,这其实反映了一个更底层的趋势:Agent 的搜索能力正在从”自己上网”转向”调用专门化搜索服务”。像 Brave Search 这样把搜索变成 API 调用的方式,比浏览器自动化更稳定、更可预测、更容易在 Pipeline 里做质量管控。我个人判断,未来半年到一年内,Agent 的搜索方案会加速从浏览器路线迁移到 API 路线。
不过有一个隐含风险值得注意:API 方案的”好”是建立在 API 提供商”持续靠谱”的前提上的。Brave 的定价策略、索引更新频率、API 可用性,这些都不在你的控制范围内。如果某天 Brave 改了定价或缩减了免费配额,所有依赖它的 Agent 都会受影响。把搜索能力”外包”给第三方 API 确实省心,但也把关键路径上的稳定性交了出去。
换个角度看,这也是为什么 Skill 本身的代码量这么少、逻辑这么简单的原因。它没有做太多”聪明”的事,只是把 Brave API 的能力忠实地翻译成了 CLI 接口。这种克制在 AI Agent 工具链里其实不多见,太多人倾向于加三层缓存、五层 fallback、十层 prompt 模板,最后搞出一个没人敢改的怪兽。Brave Search 选择了”做好一件事”,这个选型本身就是一种设计品味,也是一种对 Agent 架构的诚实。
资源地址
| 资源 | 地址 |
|---|---|
| 官网 | https://clawhub.ai/steipete/brave-search |
| Brave Search API | https://brave.com/search/api/ |
总结
Brave Search 是一个目标明确、边界清晰的小工具。它不试图做所有事,但它把”Agent 怎么获取网页信息”这个高频需求用一个干净利落的方式解决了。
装了六万个 Agent 不是没有原因的。轻量、稳定、输出格式友好,这三件事说起来简单,能做到的搜索方案其实不多。如果你已经有一个 Brave Search API Key,五分钟装好就能用甚至开始干活。如果你还在用浏览器自动化方案做搜索,至少可以把 API 方案也试一下,对比之后再做选择。
FAQ
Q1:Brave Search 和浏览器搜索方案该怎么选?
A1:各有优劣。 轻量级搜索、文档抓取、API 文档查询场景优先选 Brave Search。需要登录、交互操作、翻页浏览大量结果时用浏览器方案。两者不是替代关系,可以互补。
Q2:免费版够用吗?
A2:够用。 Brave Search API 有免费月度配额,日常开发和轻量使用完全够用。如果你的 Agent 每天要做上千次搜索,需要付费方案。
Q3:搜索结果质量跟 Google 比怎么样?
A3:各有优劣。 Brave 用的是独立索引(30 亿+ 页面),不是 Google 的壳。英文内容覆盖面不输 Google,但中文内容的覆盖明显不如。如果你的搜索需求以英文为主,差别不大。
Q4:能不能搜到需要登录才能看的内容?
A4:不能。 Brave Search 只能访问公开可索引的网页,需要登录、需要 Cookie、需要 JS 渲染才能显示完整内容页面,不在它的能力范围内。
Q5:和 Tavily 这类 AI 原生搜索比,有什么本质区别?
A5:有区别。 Tavily 更偏”AI 答案引擎”,直接在搜索层做摘要和答案生成。Brave Search 更偏”原始搜索 API”,把网页内容原样返回,让 Agent 自己决定怎么理解和利用。一个替你总结,一个把原材料给你。