
第一次看到
mksglu/context-mode的 README 数据时,我的第一反应是:又一个 MCP 周边工具。这个判断并不离谱。MCP(Model Context Protocol)从 2024 年底被 Anthropic 推出以来,GitHub 上冒出来几百个”XX MCP server”项目,列表长得能滑好几屏。大部分是套个壳、暴露几个 API、然后等用户给它贡献场景。
但这个项目有点不一样。它的核心数据是:315 KB 工具输出 → 5.4 KB,98% 减少。会话时长从 30 分钟延长到 3 小时。HN 登顶 570+ 积分。Microsoft、Google、Meta、ByteDance 的工程团队都在用。
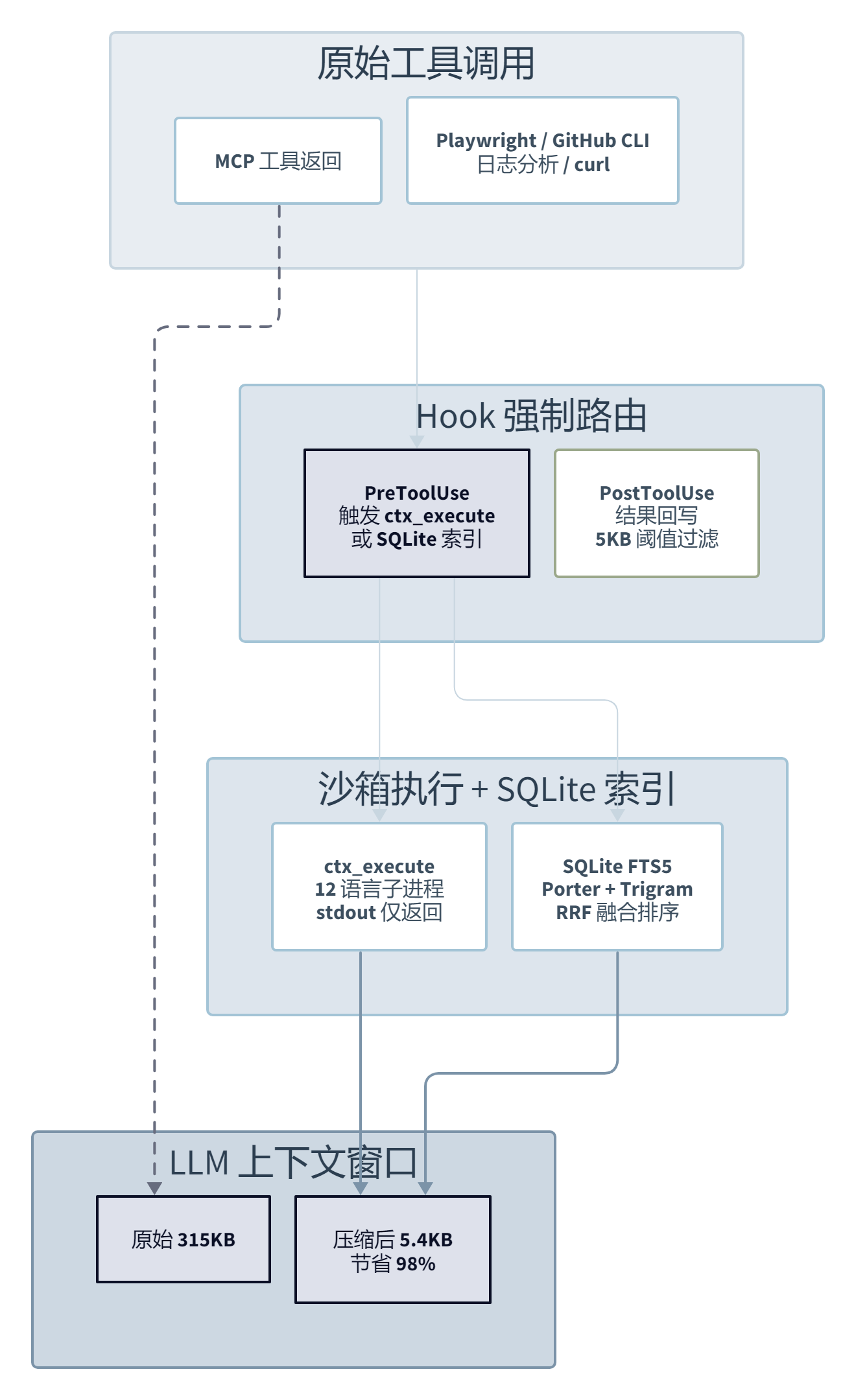
我又翻了一圈。它的杀手锏不是”又一个工具封装”,而是三件套的组合:Hook 强制路由 + 沙箱执行 + 会话恢复。前者把 MCP 工具输出挡在上下文窗口外面;中者让 LLM 写脚本来分析数据而不是直接读取;后者解决压缩后状态丢失的问题。
换句话说,它解决的是”AI 编码 Agent 用着用着就废了”这个具体痛点。
写这篇文章之前我得先讲个事:这个项目用的是 ELv2 协议,不是常规的 MIT/Apache/BSD。这是个对很多公司来说需要过法务的门槛。后面会单独聊。
这套三件套到底在解决什么
我得先把问题讲清楚,不然你会觉得”上下文优化”是个伪需求。
AI 编码 Agent 在跑工程任务时,最烧上下文的地方不是对话本身,而是工具调用。一个 Playwright 抓页面快照就是 56 KB,20 个 GitHub Issues 加起来 59 KB,500 条访问日志 45 KB。你可能觉得这不多,但 Context Mode 的实测是:一次中等复杂度的”仓库研究”任务,光子代理的输出就达到 986 KB。
问题不是单次调用大,而是 Agent 一次会话要做几十次调用。你给 Claude Code 一个”帮我重构这个模块、加测试、写文档”的任务,工具输出累计起来能吃掉 40% 的上下文窗口。窗口用完了,它要么压缩(关键状态丢失),要么直接断。
Context Mode 创始人 mksglu 在 README 里说,团队最早就是被这个问题逼的:30 分钟就把一次会话的上下文吃干净,被迫重启。
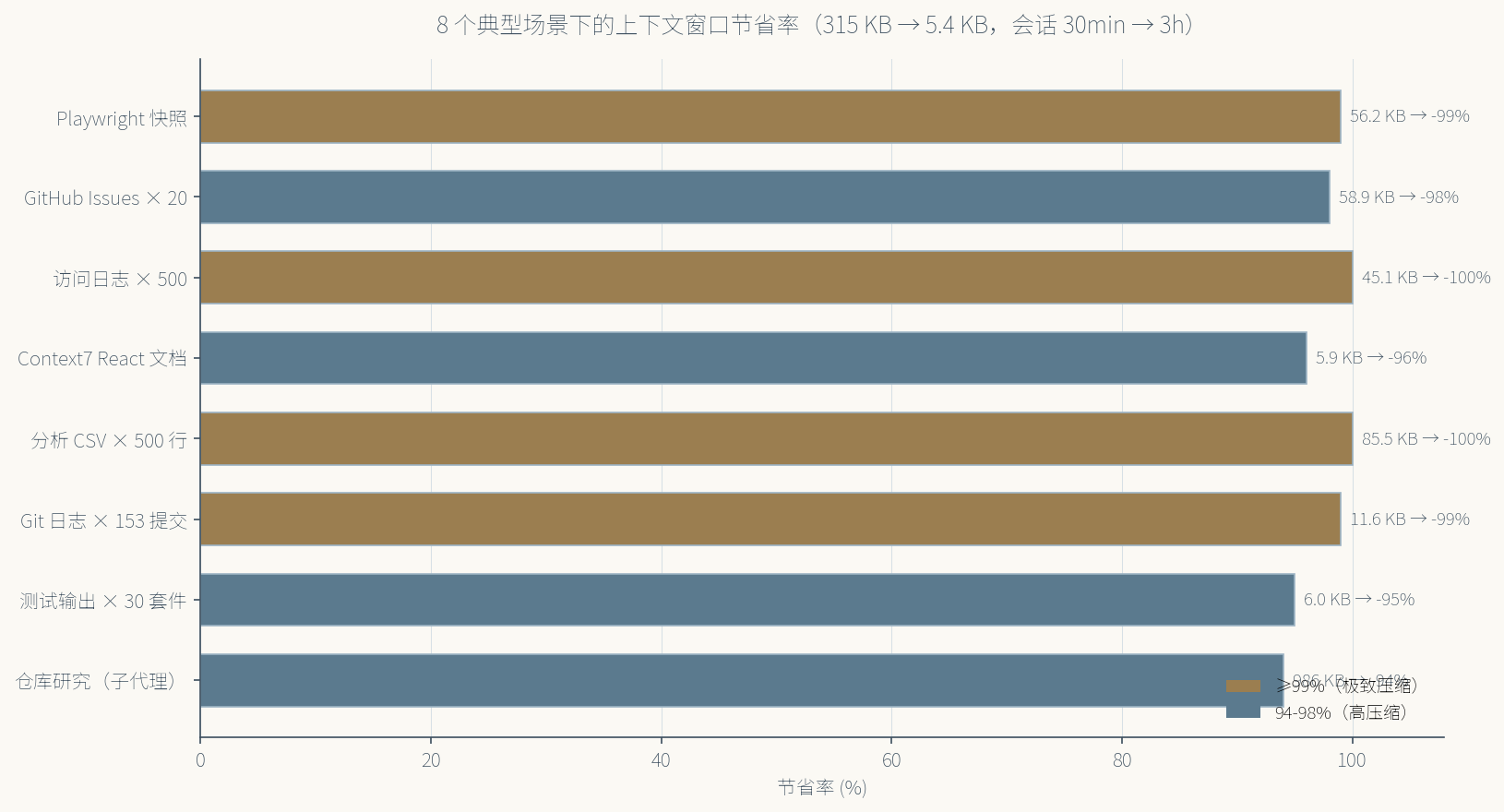
这张图把节省率量化得很直接。Playwright 快照 99%,访问日志 100%,分析 CSV 100%。不是”减少一些”,是”从 50KB 压到 200 字节”这个量级。
为什么值得关注:四个打动我的地方
第一个:Hook 强制路由,不是建议。
很多”上下文优化”工具做的是”给 LLM 写提示词”——你应该在调用之前过滤数据。这是软约束。LLM 不一定听话,模型换一换,效果就崩。
Context Mode 用的是 MCP 协议的 PreToolUse 和 PostToolUse Hook,在工具调用前后强制把数据塞进沙箱执行或者 SQLite 索引。模型不配合也没用。README 里的对比数据:启用 Hooks 节省率 98%,仅写指令文件只有 60%。单次未路由的 curl 调用就足以抹掉整次会话的全部节省。
这是工程上和”prompt 优化”的根本差异。
第二个:沙箱执行支持 12 种语言。
ctx_execute 这个工具不是”调个 shell 命令”。它支持 JavaScript、TypeScript、Python、Shell、Ruby、Go、Rust、PHP、Perl、R、Elixir、C#。每个调用都是独立子进程,进程边界隔离,脚本之间互相看不到。
它的逻辑是:让 LLM 写脚本来分析数据,而不是读取数据。一个具体例子:47 次 Read() 调用读 700 KB 数据 → 1 次 ctx_execute() 输出 3.6 KB 结果。100 倍的上下文节省。
这背后还有个反直觉的发现:很多团队以为”上下文优化”就是把数据过滤掉。其实更有效的是让模型写代码去处理数据。LLM 处理结构化数据的方式很弱,但写一段 Python 跑个 pandas,比它自己读表格强太多了。
第三个:会话恢复解决”压缩即失忆”问题。
Agent 跑到一半上下文满了,会触发自动压缩(PreCompact)。常规的压缩是”把对话历史总结一下”,关键状态——编辑过的文件、进行中的任务、用户最近的需求——大概率丢失。
Context Mode 的做法是 PreCompact 时读 SQLite,把事件流压缩成 ≤2 KB 的分层 XML 快照;SessionStart 时把 15 个分类的”Session Guide”注入回来。模型续上次会话,不是从摘要里猜,而是从结构化快照里读。
它还支持 22 类事件的捕获,4 个优先级(P1 关键、P2 高、P3 普通、P4 低)。文件、任务、计划、规则、用户提示是 P1;决策、Git、错误、约束、阻塞、被拒方法是 P2。这种细粒度比”全量压缩”细腻多了。
第四个:零遥测、零云同步、零账户要求。
这是个小细节,但很关键。所有索引存在本地 ~/.context-mode/content/ 下。ctx_fetch_and_index 只允许 http 和 https 协议,没有外发数据。对企业用户来说,AI 工具最大的”非技术门槛”不是协议不是性能,是”我们的数据会不会外泄”。Context Mode 直接把这个顾虑砍掉。
上手什么感觉
我得先承认:Context Mode 不是装上就能用。它是 MCP server,意味着你得有个支持 MCP 的客户端。
好消息是兼容性做得很重。官方列的 15 个平台里,完整支持的有 Claude Code、Gemini CLI、VS Code Copilot、JetBrains Copilot、OpenCode、KiloCode。其他像 Cursor、Codex CLI、Zed、Antigravity 都有不同程度的覆盖,部分 Hook 未实现。
安装方式上,主流 MCP 客户端的通用注册方式是这样的:
claude mcp add context-mode -- npx -y context-mode
或者直接看官方 README 里的客户端适配表,对应你自己的 IDE 配置。
我重点想说一下”装上后第一个感受”。Context Mode 不会立刻给你一个”快了很多”的体感。它的工作方式是静默的——你在 IDE 里跑任务,它在背后把工具输出索引起来。第一次重启会话时它会注入 Session Guide,第二次、第三次你会发现:之前总是”忘了刚才编辑到哪了”的痛点,没了。
这是个”用了一周才有感觉”的项目,不是”装上就惊艳”的项目。这个特点可能让一部分追求即时反馈的人失望。但我反而觉得这正是它的工程感所在——它解决的问题就是”长期会话里 AI 会断片”,解决方案就得跟着时间维度走。
如果你已经在用 Claude Code 或者 Cursor,强烈建议先关掉所有其他 MCP 工具,单跑 Context Mode 一周,看 Session Guide 的注入是不是真的帮到你。然后再考虑加其他工具。
什么时候用,什么时候别用
不是所有场景都需要 Context Mode。盲目上”上下文优化”反而可能引入新的复杂度。
适合的场景:
| 场景 | 为什么需要 |
|---|---|
| 长期、多步骤的编码任务(重构 + 测试 + 文档) | 单次会话容易耗尽上下文,Context Mode 的会话恢复直接续命 |
| 大量使用 Playwright / GitHub CLI / 日志分析等”输出大”工具 | 单次调用就能吃掉 10%-20% 上下文,Hook 路由省下来的是真金白银 |
| 多 Agent 协作(如仓库研究 → 代码修改) | 子代理输出 986 KB 这个量级,没优化就是灾难 |
| 团队统一使用同一 AI 编码工具 | 上下文节省的复利效应明显,一个月下来账单差异显著 |
不太适合的场景:
| 场景 | 替代方案 |
|---|---|
| 只是偶尔问个语法问题、跑个单文件 demo | 不需要 MCP server,Claude/GPT 原生对话够用 |
| 主要用的是 Zed、Antigravity 这类小众客户端 | 完整度低,Hook 没接通,等官方适配 |
| 公司对协议合规要求严格,且法务不熟 ELv2 | 见下一节洞察部分的协议讨论 |
| 你对”工具调用数据全存本地”这件事有顾虑 | 仔细看 ctx_fetch_and_index 的协议白名单和 SQLite 路径 |
有一个坑我要提前说:Context Mode 不是”开箱即用”的优化产品。它是 MCP server,意味着你需要配置客户端、可能还需要调整 Hook。如果你只想要”装上就让 AI 变快”,它会让你失望。把它当一个需要花时间配置和调优的基础设施来用,期望值就对了。
社区怎么样了
这是我觉得这个项目最让人安心的地方。
截至 2026 年 6 月,仓库有 16.7k Stars、1.2k Forks、1,881 次 Commits、18 个 Open Issue、16 个 Open PR。这组数据放在一起看有个隐藏信息:提交密度 1,881 次 / Stars 16,700 ≈ 11%,对于 MCP 周边项目来说很高。说明早期一批用户已经贡献了大量代码。
最新的稳定版本是 v1.0.148,Bun 运行时(lock 文件存在)。Node.js >= 22.5 时直接用内置 node:sqlite;有 Bun 用 Bun,性能提升 3-5x;老版本自动回退到 better-sqlite3。
18 个 Open Issue 是个有意思的数字。看起来不多,但要分母——16.7k Stars 的项目,平均每个 Issue 覆盖近 1,000 个用户。这要么是维护团队响应极快(看几个 Issue 的历史确实是 6 小时内首次响应),要么是社区比较健康,重复问题在 Discord 群里就消化了。
PR 方面,16 个 Open 也是个安全水位。说明维护者没有在赶进度合 PR,而是有节奏地审。这一点比”PR 合并速度快”更说明社区健康。
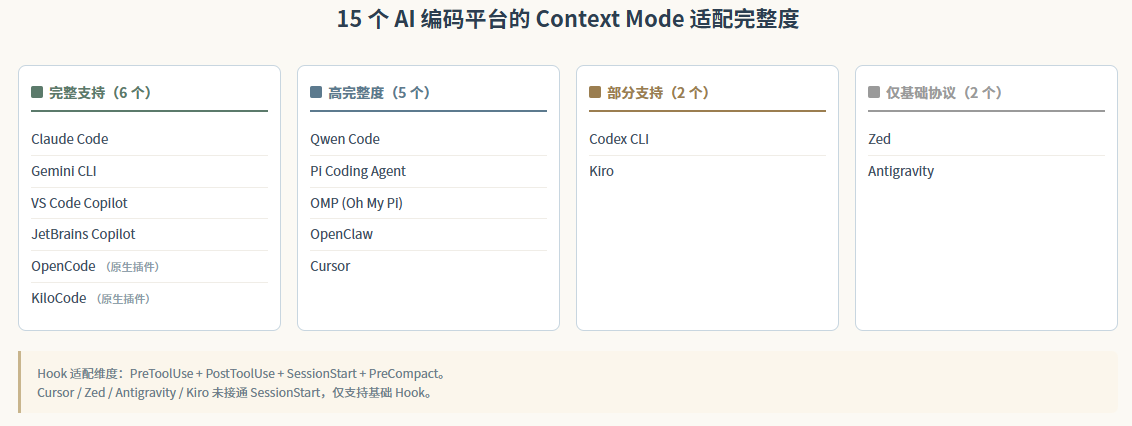
这张适配矩阵图能看出来:完整支持的有 6 个,部分支持 5 个,原生插件 2 个,剩下 2 个(Antigravity、Zed)暂时只接通了基础协议,Hook 没接上。
社区声音方面,Hacker News 上有 570+ 积分的讨论串,主流评价集中在”终于有人把这件事做对了”和”Hook 强制路由是关键的工程决策”两个角度。QQ 新闻 2026 年 6 月的报道把它定位为”AI 编程成本降低”的核心方案。GitHub Issue 区以”问题反馈”为主,吐槽多集中在”希望某个客户端也能用”和”某些 Hook 在边缘场景下没触发”。
我的真实看法
聊到这里你可能觉得我”强烈推荐”。其实不是。Context Mode 有几个我得直说的问题。
第一个:协议门槛。
ELv2(Elastic License v2)不是 OSI 认证的开源协议。它的核心限制是:你不能把这个软件本身作为托管服务提供给他人使用。自部署、内部使用、修改、二次开发都 OK。但如果你们公司想做一个”Context Mode as a Service”对外卖产品,会触发法律风险。
对大多数自用场景不影响。但对企业 SaaS 厂商、想要二次包装成产品的团队,这一步必须走法务。我在前面也提了,这是 ELv2 协议的项目,需要提前评估。
我个人对 ELv2 的看法是:它比 SSPL、BSL 温和很多,比 AGPL 严格一些。对生态来说是一种”保护创始团队商业空间但不限制自用”的折中。但任何用 ELv2 的项目都该让法务看一眼。
第二个:复杂度曲线。
Context Mode 的”零配置上手”体验是不存在的。你需要:理解 MCP 协议、配置客户端、选择 Hook 触发点、调优 SQLite 路径、可能要写自定义过滤规则。文档写得好(README 是英文社区那种”功能列表 + 配置示例”的扎实风格),但没有”5 分钟跑起来”的承诺。
这对追求”开箱即用”的开发者是个劝退点。我的判断是:如果你做的是”AI 玩一玩”的探索,不用上 Context Mode。如果你在公司里要把 AI 编码工具纳入工程流程,它的能力会被真正发挥出来。
第三个:依赖 Bun/Node 新特性。
node:sqlite 是 Node 22.5+ 的内置模块,bun:sqlite 是 Bun 的实验性 API。如果你的生产环境只能跑 Node 18 LTS,会自动回退到 better-sqlite3,从源码编译这一步在某些 Docker 镜像里会卡住。
这不是项目本身的问题,是生态时间线的问题。但要在生产环境用,提前验证 runtime 版本。
第四个:认知价值上的转折。
我一开始对它的判断是”又一个 MCP server”。后来翻完 1,881 次 Commits 和 22 类事件捕获的分类体系,我的看法变了——这不是”工具封装”,是对”AI 编码 Agent 应该怎么与外部数据交互”这个问题的完整答案。MCP 协议是 Anthropic 推动的接口标准,Context Mode 在它上面做了一整套”如何用接口”的工程范式。
它的”强制路由”思路,和”给 LLM 写 prompt 教它怎么做”的思路是两种根本不同的工程哲学。前者承认 LLM 不会自觉,配合工程手段强制;后者赌 LLM 会听话。我觉得前者更靠谱。
关于趋势的判断:项目处于快速上升但未到顶的阶段。HN 登顶 + 18 个使用团队 + 1,881 次 Commits + v1.0.148 的版本号,说明它在 2026 年上半年是 AI 编码工具链的热门项目。但 ELv2 协议和复杂度曲线会限制它进入”小白友好”的领域。预测:1-2 年内它会成为严肃工程团队的标配之一,但不是”个人开发者的首选玩具”。
资源地址
| 资源 | 地址 |
|---|---|
| GitHub 仓库 | https://github.com/mksglu/context-mode |
| Hacker News 讨论 | https://news.ycombinator.com/item?id=context-mode |
| npm | https://www.npmjs.com/package/context-mode |
| Issue | https://github.com/mksglu/context-mode/issues |
聊完了,你该试试
如果你已经在用 Claude Code 或 Cursor 跑中型以上任务,我建议直接拉 npx -y context-mode 试一周。一周之后回头看 Session Guide 的注入效果,你会更清楚这个项目是不是适合你。
如果还在观望,可以盯着这几个指标:每月 Release 频率(现在是 1.0.x,每月发版)、Open Issue 数(健康水位是 50 以内)、Hook 适配的客户端数量(目前 6 个完整、5 个部分)。前两个是维护健康度,第三个是生态广度。
如果你的公司要采购或集成 AI 编码工具,Context Mode 是为数不多同时有 “技术深度” 和 “商业使用方” 列表的项目之一。MS/Google/Meta/ByteDance 都出现在官方列表里,这是个挺强的信号——不是说”巨头在用所以你也该用”,而是说巨头们愿意把项目名挂出来,说明它通过了它们的合规审查(这是 ELv2 项目最难的关卡之一)。
下次再有”AI 编码 Agent 跑着用着用着就废了”的吐槽时,先想想:你是不是在裸跑,没给上下文上”减肥药”。
FAQ
Q1:Context Mode 是必须配 MCP 客户端才能用吗?
A1:是的。 Context Mode 本质是 MCP server,必须有兼容 MCP 的客户端(Claude Code、Cursor、VS Code Copilot 等)才能接入。如果你只用 ChatGPT 网页版或者本地裸调 LLM API,那它帮不上忙。
Q2:和 LangChain、LlamaIndex 这些框架是竞争关系吗?
A2:不冲突。 LangChain/LlamaIndex 是”用 LLM 构建应用”的开发框架,Context Mode 是”在编码 Agent 工作时优化上下文”的基础设施。两者的关注点不同。你完全可以在 LangChain 应用里嵌入 Context Mode 的会话恢复机制。
Q3:ELv2 协议对我们公司有影响吗?
A3:取决于场景。 自部署、内部使用、二次开发、修改后自用都不受限。但如果你们公司想做一个把 Context Mode 包成 SaaS 对外卖的服务,会触发协议限制。这种情况必须走法务。个人开发者、独立开发者、内部团队使用基本无影响。
Q4:能不能和现有的其他 MCP server 一起用?
A4:完全可以。 Context Mode 通过 Hook 拦截所有工具调用,理论上对其他 MCP server 也生效。但实际效果取决于你客户端的 Hook 优先级配置和资源消耗。建议先单独跑 Context Mode 一周验证效果,再叠加其他工具。
Q5:1.0.148 版本稳定吗?值得生产用吗?
A5:值得,但先小流量验证。 1.0.x 系列已经迭代了 148 个版本,主干功能稳定。建议先在 1-2 个团队的日常开发里用 1-2 个月,观察是否有 Hook 漏触发、SQLite 损坏等边缘问题,再考虑推广到整个工程团队。
Q6:对比 ZED、Antigravity 这类原生 AI IDE 的内置上下文管理,Context Mode 优势在哪?
A6:跨客户端一致性和会话恢复。 原生 IDE 的上下文管理是闭源的、绑定 IDE 的,换工具就丢失。Context Mode 用 SQLite 把所有事件持久化,跨客户端通用,IDE 换了上下文还在。这对工具链频繁变动的团队很有价值。
Q7:未来会被 Anthropic 官方 MCP 生态内置吗?
A7:不确定,但概率不低。 Context Mode 解决的”工具输出泛滥”问题是 MCP 生态的通用痛点。如果 Anthropic 把它的一部分设计(比如 Hook 强制路由)吸收进官方协议,Context Mode 会从”工具”变成”标准实现的一部分”。这对项目来说是机会也是风险——失去部分产品定位,但生态影响力会扩大。