
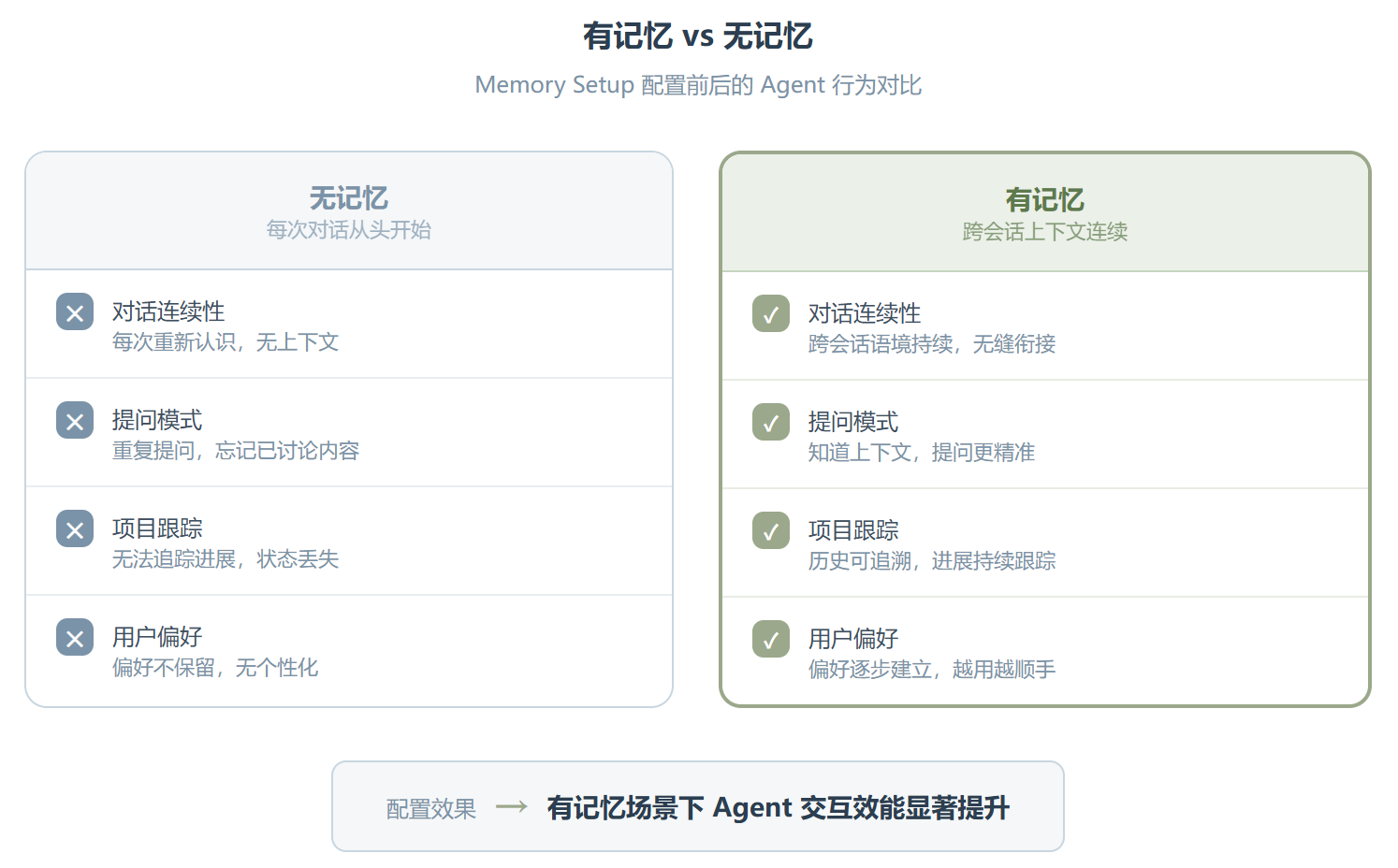
用过 Clawdbot 或 Moltbot 的人应该都有这种体验:你跟它聊了一整个下午,调好了配置、整理好了项目上下文,关掉终端再打开,它又变成一个”初次见面”的陌生人了。那种感觉说实话挺挫败的。
这其实不是 Agent 的错。默认状态下它就是没记忆的——每次对话都是全新的上下文,过去的讨论、做过的决策、你告诉它的偏好,全部清零。这就像你每天上班都得给同事重新介绍一遍自己是谁。
Memory Setup 就是来解决这个问题的。这是一个 ClawHub 上开源的 Skill(44.3k 下载、安全审计通过),专门给 Moltbot/Clawdbot 配持久记忆用的。它做的不是把”记住”这件事推给 Agent 自己,而是搭了一套结构化的记忆系统:MEMORY.md 管长期记忆,memory/ 目录管日誌,再加上向量搜索找相似上下文。
说真的,这篇文章不打算跟你讲太多抽象概念。我就把拆完这个 Skill 之后的理解整理一下,配置怎么走、背后是怎么设计的、实际跑的时候可能踩什么坑。如果你也在折腾 Agent 记忆,应该能省不少时间。
环境准备:你要的先不多
先说说前置条件。你不需要什么特殊环境——只要 Moltbot 或 Clawdbot 已经装好能跑就行。如果有 openclaw CLI 工具就更方便了。
| 前置 | 说明 | 必须? |
|---|---|---|
| Clawdbot / Moltbot | 已安装并能正常运行 | ✅ |
| CLI 工具(推荐) | openclaw 命令可用 |
推荐 |
| API Key(可选) | Voyage / OpenAI 的 embedding key | 按需 |
安装就一句话:
openclaw skills install memory-setup
等个几秒就能装好。版本号是 v1.0.0,MIT-0 协议,装完可以跑个验证:
openclaw skills list | grep memory-setup
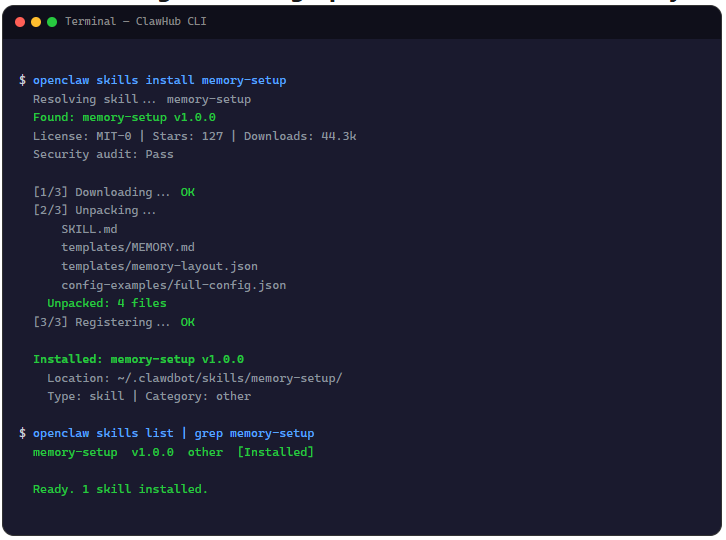
到这一步,Skill 就位了。但真正让它开始”记住”东西,还需要配置。这部分才是重点。
操作流程:四步走,从零到有记忆
整个配置链路不算长,但步骤之间有依赖关系。我按”先开开关、再搭架子、再装内容、最后写规矩”的顺序拆一遍。
第一步是打开记忆搜索的开关。在 ~/.clawdbot/clawdbot.json 里补一个 memorySearch 段:
{
"memorySearch": {
"enabled": true,
"provider": "voyage",
"sources": ["memory", "sessions"],
"indexMode": "hot",
"minScore": 0.3,
"maxResults": 20
}
}
这个配置项决定了三件事:用什么引擎做嵌入、索引哪些内容、怎么召回。后面的设计章节会细说。
第二步是搭记忆目录的架子。这个 Skill 的文件结构设计得挺清晰:
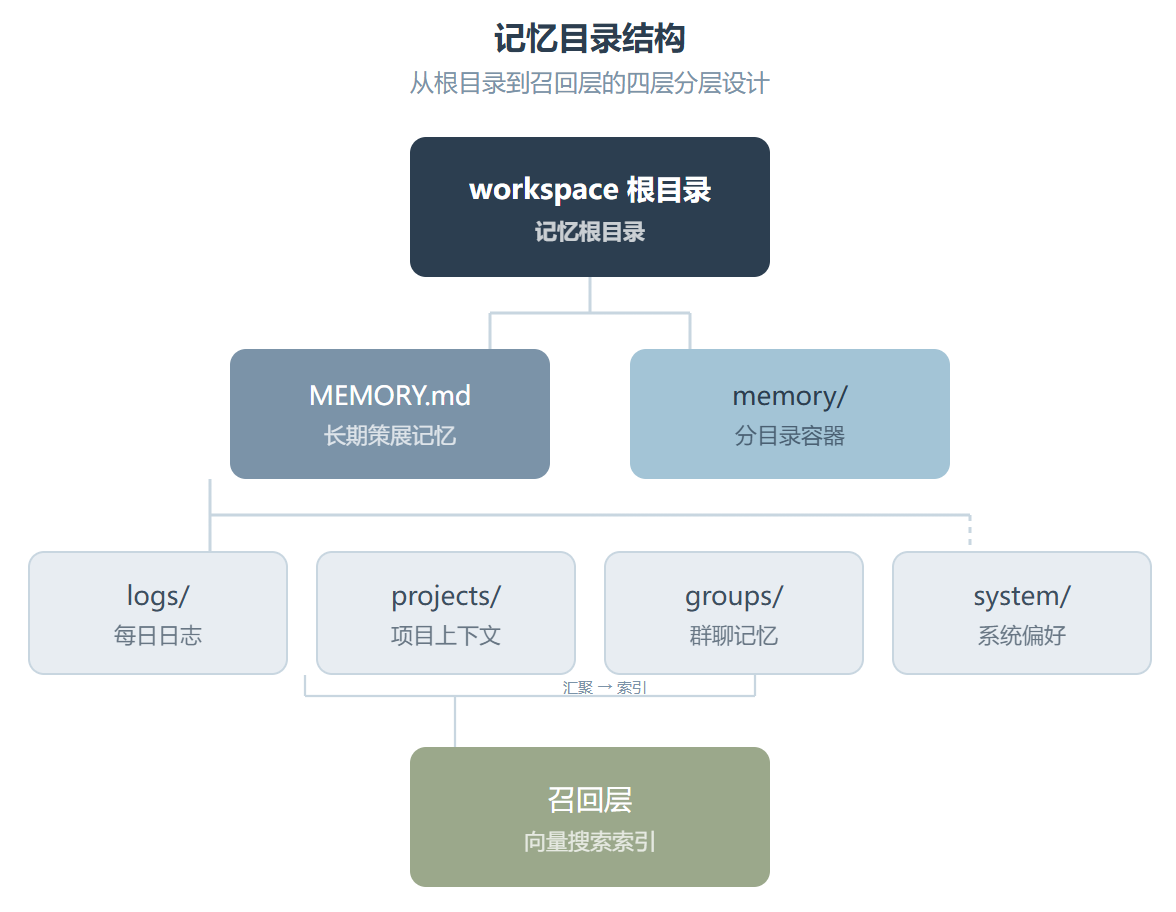
每个子目录有自己的职责。logs/ 放每日工作日志,projects/ 放项目级上下文,groups/ 放群聊记忆,system/ 放偏好和设置。这种分层结构不是随便想的——它恰好对应了 Agent 在不同粒度上需要记住的信息类型。
第三步是初始化 MEMORY.md。这是一份”长效记忆”文件,记录不随时间变化的元信息:用户的关键事实、活跃项目概览、做过的重要决策、以及沟通偏好的总结。
# MEMORY.md — Long-Term Memory
## About [User Name]
- Key facts, preferences, context
## Active Projects
- Project summaries and status
## Decisions & Lessons
- Important choices made
- Lessons learned
你在日常对话中产生的具体记录,会进入 memory/logs/ 的每日文件。但 MEMORY.md 是那个”不管过多久都要记住的东西”。
第四步,给 Agent 写指令。在 AGENTS.md 里加一段记忆召回的行为规范:
## Memory Recall
Before answering questions about prior work, decisions, dates, people, preferences, or todos:
1. Run memory_search with relevant query
2. Use memory_get to pull specific lines if needed
3. If low confidence after search, say you checked
这步很多人会跳过,但实际上非常关键。没有这段指令,Agent 不会主动去查记忆——它只会被动等配置生效。
关键设计:为什么这样搭
拆完这个 Skill 的配置体系后,我意识到它背后的设计逻辑比表面看起来要成熟。
先说 Provider 的选择。支持三种嵌入引擎:Voyage(推荐)、OpenAI、Local。选择 Voyage 作为默认方案不是随便定的。从配置优先级的排布来看,设计者明显更看重”质量优先”——Voyage 在长文本嵌入和跨语言语义匹配上的表现确实比 OpenAI embedding 稳定,而 Local 方案的存在是为了让没有 API Key 的用户也能跑起来,属于”有总比没有好”的兜底策略。
配置项的设计也有讲究。indexMode: "hot" 表示实时索引——每当记忆文件发生变化,立即更新向量索引。这个选择对使用体验影响很大。选”cold”模式性能好但召回会延迟,Agent 正在聊天的过程中出现”等等,我还没索引完”的体验很断裂。设计者在这里选了一个对用户友好但对性能要求更高的路径。
sources 的设计是另一个值得说的点。["memory", "sessions"] 表示既索引文件记忆(MEMORY.md + memory/ 结构),也索引对话历史。很多人以为记忆等于文件,但实际上 Agent 在对话过程中产生的上下文——你刚才跟它讨论的方案、你改过的一个细节——同样重要。两种来源互补,才构成完整的记忆画像。
| 维度 | 统一文件记忆 | 零散对话记忆 |
|---|---|---|
| 持久性 | 高 | 低(会过期) |
| 召回速度 | 快(已索引) | 中 |
| 信息密度 | 高(策展过) | 低(原始转录) |
| 适用场景 | 长期参考 | 短期跟踪 |
不过也要说几个我觉得可以改进的地方。一是配置项缺少”记忆过期”机制——今天的对话和三个月前的对话被同等对待,没有衰减逻辑。二是 minScore 和 maxResults 两个参数没有区分”精确查询”和”模糊查询”的使用场景,用户得自己试出合适的值。
使用场景:什么时候真的需要它
讲完设计,说说具体什么场景下值得上这套记忆系统。
最典型的场景是新用户上手期。你刚装好 Clawdbot,开始跟它讨论项目。第一天你设好了后端架构、确定了一个技术选型、列了一堆 TODO。第二天打开终端你问”我们昨天那个方案还要改什么吗?“——它给你回一句”I don’t have context about that conversation.” 这个瞬间,你会非常想装一个 Memory Setup。
第二个场景是跨项目切换。如果你同时维护两三个项目,Agent 在你换目录的时候会”失忆”。Memory Setup 的 projects/ 子目录刚好解决这个问题——每个项目一份独立的上下文,切换时按目录隔离召回。
第三个场景有点反直觉。你在一个群里用 Moltbot 讨论问题,群聊信息太多太杂,Agent 很难抓住重点。groups/ 子目录的设计就是给这个场景准备的——只索引群聊中的关键决策,过滤掉日常闲聊。
不过需要说清楚边界。这套方案最适合的是”一个人或一个小团队长期使用同一个 Agent 实例”的场景。如果你的场景是频繁重建环境、批量部署临时 Agent,那配置这套记忆系统的成本可能高于收益。
洞察与反思
说到底,Agent 记忆这个问题的本质不是技术问题,而是信息架构问题。很多 Agent 框架到现在还在用”把所有东西塞到 system prompt”的思路,导致上下文窗口越撑越满、召回质量越来越低。Memory Setup 选择用分层结构来处理——长效记忆写入 MEMORY.md,短期记忆走向量搜索,对话历史走 sessions 索引。这个分层的思路是对的。
但有一个问题值得思考:为什么选择 Voyage 作为默认嵌入引擎,而不是更主流的 OpenAI?从配置推荐度来看(Voyage 标了 recommended 而 OpenAI 没有),设计者明显对 Voyage 的质量更有信心。但社区里对 Voyage 的讨论热度远低于 OpenAI embedding,这形成了一个反差。我个人觉得这反而是好事——说明设计者是基于实际效果做选择,而不是跟着热度走。
另一个让我有感触的设计点是 AGENTS.md 的指令部分。很多人以为配好 memorySearch.enabled: true 就完事了,但少了 Agent 的行为指令,记忆配置就像装了全套监控摄像头却没人去查看录像。这个”配置 ≠ 生效”的落差,可能是新手用户最常踩的坑。
回到更大的视角来看这件事。Agent 记忆的价值不在”记住”本身,而在”记住之后能做什么”。如果你只是让 Agent 记住你上周说过什么,那它充其量是个高级记事本。但如果你能让它在记住的基础上做模式识别、趋势判断、甚至主动推荐——那就完全是另一个层面的事了。Memory Setup 目前还停在第一阶段,但它的架构已经为第二阶段的扩展留了余地。
| 资源 | 地址 |
|---|---|
| ClawHub | clawhub.ai/jrbobbyhansen-pixel/memory-setup |
| 文档 | docs.openclaw.ai/clawhub |
总结
这套记忆配置流程走下来,最让我有感触的不是技术本身,而是它对”Agent 记忆”这个问题的定义方式。它没有试图把所有信息塞进一个文件,也没有完全依赖向量搜索的玄学,而是用了”策展文件 + 目录结构 + 向量索引 + 行为指令”四层组合。
每个层都有自己的职责边界。MEMORY.md 管你”是什么”,memory/ 管你”做了什么”,向量搜索管”哪些相关”,AGENTS.md 管”什么时候去查”。这四条线叠在一起,才能让一个 Agent 从”每次都重新认识你”变成”好像真的记得你是谁”。
如果你是第一次折腾 Agent 记忆,按前面的四步走就能跑起来。如果已经踩过坑,建议你重点关注 minScore 和 maxResults 的调参——那才是真正影响使用体验的地方。
这个好