
17.5 万 Star。这不是一个框架,不是一个工具,甚至不是一个项目。它只是一个 CLAUDE.md 文件。
我第一次在 GitHub Trending 上看到这个数字的时候,脑子里闪过两个念头。第一,这东西一定有水分。第二,我得看看它到底写了什么,能让人点 17.5 万次星标。打开仓库,README 不到 200 行,核心文件更是只有一个 CLAUDE.md。但它背后的人,是 Andrej Karpathy。
Karpathy 在推上发过一条吐槽,说 LLM 写代码有三个让人抓狂的问题:遇到模糊提示就瞎猜,100 行能搞定的事硬写成 1000 行,改一个 bug 顺手重构了半个文件。multica-ai 团队把他的这些观察提炼成了四条行为准则,塞进了一个文件里。
说人话就是:你把这个文件放进 Claude Code,AI 的行为会从”实习生”变成”高级工程师”。怎么放进去,怎么验证生效,以及这四条规则为什么能起作用,下面一层层拆开说。
环境准备
这东西对环境的要求低到离谱。你不需要装任何新工具,不需要注册任何新账号,甚至不需要重启编辑器。
前置条件只有三条。你得装了 Claude Code,版本随意,能跑就行。你得有一个项目目录,空的也行。你得能联网,因为插件安装要走网络。不具备这些条件也没关系,它支持三种安装路径,总有一条适合你。
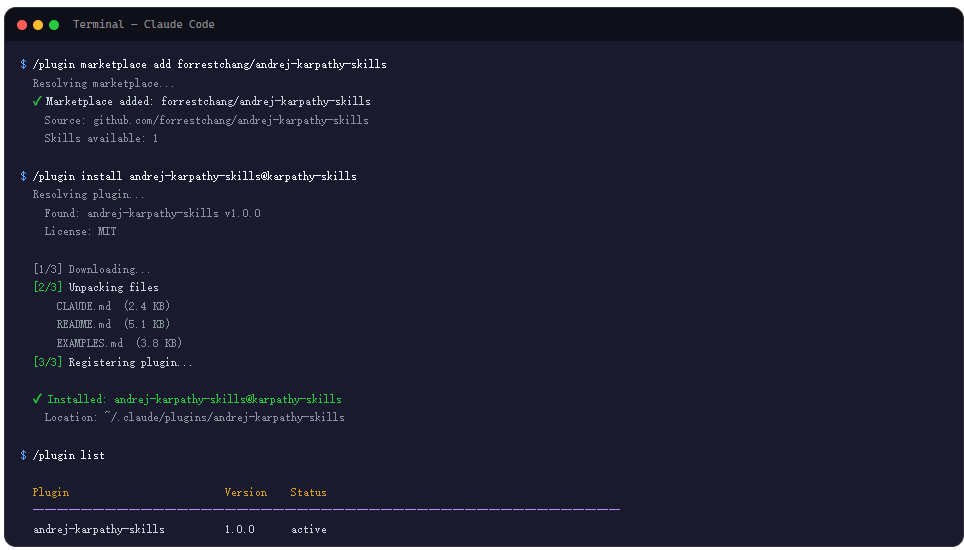
最推荐的方式是通过 Claude Code 插件安装,一条命令搞定全局生效。在 Claude Code 的终端里跑下面这两行:
/plugin marketplace add forrestchang/andrej-karpathy-skills
/plugin install andrej-karpathy-skills@karpathy-skills
装完之后,这个技能会在你所有的 Claude Code 项目中自动生效。不需要每个项目单独配置,也不需要维护多份文件。
不习惯用插件的话,还有更轻量的方案。直接 curl 一个 CLAUDE.md 到项目根目录就行。新项目用第一条命令,老项目用第二条追加。本质上就是往 Claude Code 默认读取的上下文文件里塞了一段行为约束。两种方式的效果完全一样,区别在于插件的控制粒度更细,可以随时开关。
# 新项目
curl -o CLAUDE.md https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md
# 老项目(追加到已有文件末尾)
curl https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md >> CLAUDE.md
怎么确认装成功了?随便打开一个项目,让 Claude Code 帮你改一行代码。观察它的 diff,如果它只改了你要改的那一行,没有顺手调整周围的注释、空格和变量名,那就是生效了。这是最直观的验证方法。
操作流程
这套规则的工作方式跟你想的可能不太一样。它不增加任何功能,不改变 Claude Code 的任何能力边界。它只做一件事:约束行为。
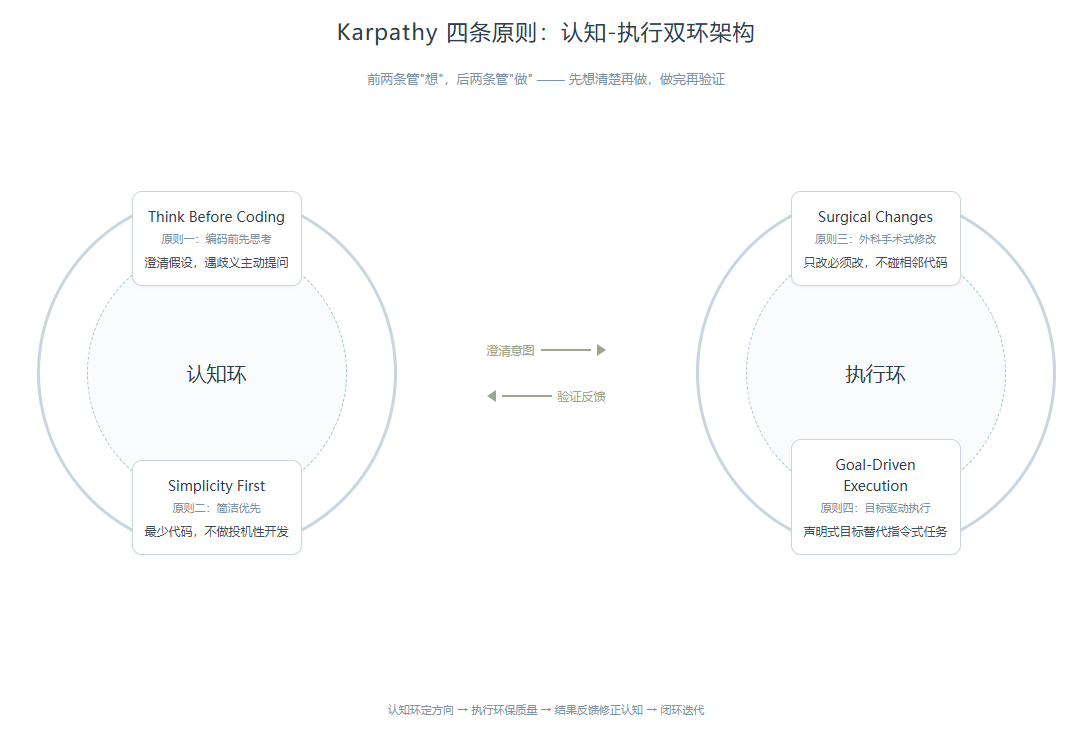
你把 CLAUDE.md 放进项目的那一刻,Claude Code 在每次收到指令时,都会先把这四条规则过一遍。四条原则各自解决一个 LLM 编程的经典问题,它们之间还有递进关系。
第一条,Think Before Coding。LLM 面对模糊指令时,倾向于选一个最可能的解释然后立刻动手。结果经常是写得快、错得也快。这条规则强制它在动手前先澄清假设,遇到歧义时主动提问。翻译成人话:别猜,问清楚再写。
第二条,Simplicity First。LLM 天生喜欢过度设计。你让它写一个工具函数,它给你搭了一套完整的抽象层,带着工厂模式和依赖注入。这条规则告诉它:用最少代码解决问题,不要为未来可能用不到的需求写代码。如果一个 200 行的实现能压到 50 行,就重写它。
第三条,Surgical Changes。这是四条里最反直觉的一条。LLM 在改代码时,经常顺手”优化”周围的注释、格式、变量命名。看起来是好事,实际上制造了一堆与需求无关的噪声 diff。这条规则要求它严格做到只改必须改的,不碰相邻代码。发现无关的死代码,只能提一句,不能删。
第四条,Goal-Driven Execution。这是整个体系的核心。它把前三条从”行为规范”升格成了”可验证系统”。核心理念是把命令式指令转化为声明式目标。比如”修复这个 bug”变成了”写一个能复现这个 bug 的测试,然后让它通过”。AI 拿到的不再是一个任务清单,而是一个成功标准。
四条原则的行为转变,用表格看最清楚:
| 原则 | 解决的 LLM 问题 | 行为转变 |
|---|---|---|
| Think Before Coding | 隐藏困惑:遇到模糊提示就瞎猜 | 先澄清假设,再动手 |
| Simplicity First | 架构臃肿:100 行能搞定的写成 1000 行 | 用最少代码解决问题 |
| Surgical Changes | 无关编辑:改 bug 顺手重构半个文件 | 只改必须改的,不碰相邻代码 |
| Goal-Driven Execution | 无验证循环:写完了不知道对不对 | 用测试驱动,声明式目标替代指令式任务 |
把四条连起来看,你会发现一个很有意思的模式。前两条管”想”,想清楚了没、想复杂了没。后两条管”做”,改对了没、改完了没。Karpathy 实际上把 LLM 编程的问题拆成了认知问题和执行问题,然后用两对规则分别兜底。
关键设计
这套设计最聪明的地方,不是四条规则本身。是它选择了一个极简的载体。没有插件、没有 SDK、没有 API,就是一个纯文本文件。可能你会觉得这不算设计决策,更像是一种偷懒。但从效果来看,这恰恰是它 17.5 万星的原因之一。
CLAUDE.md 是 Claude Code 原生支持的上下文注入机制。放进去的任何内容,会在每次对话中自动拼接到 system prompt 前面。这意味着这个文件不需要任何运行时,不需要任何权限,甚至不需要 Claude Code 以外的任何东西。它利用的是 Claude Code 既有的基础设施,而不是另起炉灶。
另一个关键设计是声明式 vs 指令式的范式转换。绝大多数 AI 编码指南告诉你”第一步做什么,第二步做什么”。这套规则告诉你”什么样的结果是好的”。区别在于,前者把 AI 当执行器,后者把 AI 当问题解决者。指令式导向的是完成度,声明式导向的是正确性。
举个具体例子。传统的做法是:“修复 user_service.py 第 42 行的空指针异常”。Karpathy 的做法是:“写一个测试来复现 user 创建时的空指针异常,然后让测试通过”。前者告诉 AI 怎么做,后者告诉 AI 什么算做好了。后者给了 AI 自主选择实现路径的空间,但把验收标准牢牢握在自己手里。
当然,这套设计不是没有代价。偏谨慎的策略意味着简单任务也会被”过度流程化”。改一个拼写错误理论上也要走”先确认我的理解→写最小改动→不改相邻代码→验证通过”的完整链条。项目 README 也明确承认了这个 trade-off:这些原则偏向”谨慎”而非”速度”,对于简单任务请自行判断。

使用场景
这套规则最理想的落地场景是新项目初始化。从头开始搭一个项目的成本很低,这时候把 CLAUDE.md 放进去,从第一行代码开始就约束 AI 的行为。根据社区反馈,新项目里这个文件的”存在感”最明显,因为 AI 还没有形成任何行为惯性。
第二个场景是已有项目的行为纠偏。如果你的 Claude Code 已经养成了”改 bug 顺手重构”或者”过度设计”的习惯,追加这个文件相当于一次重置。效果不会立竿见影,通常需要 3 到 5 次交互后 AI 才开始稳定遵守规则。这个”延迟生效”现象在社区讨论中被反复提到。
第三个场景有点反直觉:用它来教育自己。不少开发者反馈,读这个文件的过程本身就是一次代码审查习惯的自我校准。当你看到 AI 被约束成”只改必须改的”,你会开始反思自己的 PR 是不是也经常夹带私货。这套规则最终改变的不仅是 AI 的行为,还有使用者的编码习惯。
这套规则的适用边界也很清楚。它最适合 Claude Code 和 Cursor 这类已经把 CLAUDE.md 或 .cursor/rules 作为一等公民的编辑器。对于不支持上下文文件注入的 AI 编码工具,效果会大打折扣。它不是一种通用的 Prompt 技巧,而是一个绑定平台能力的配置方案。
洞察与反思
175k 星这个数字本身就是一个值得分析的信号。它说明了一件事:开发者对 AI 编码质量的不满足,已经积累到了一个临界点。大家不是不需要 AI 辅助写代码,而是受够了 AI 写出”看起来对但用起来慌”的代码。
把这个文件放在更大的趋势里看,它代表了一种”轻量配置层”的崛起。以前人们觉得要控制 AI 的行为,得靠精调、RAG、复杂的工作流编排。Karpathy 的 CLAUDE.md 用实践证明了另一种可能:一个几百行的文本文件,就能显著改变 AI 的行为模式。这可能比我们想象的要重要得多。
我个人的判断是,这个项目的价值被严重低估了。不是因为它的技术含量有多高,而是因为它暗示了一条被忽视的产品路径。如果几百行的行为约束就能让 Claude Code 的编码质量上一个台阶,那”行为配置”本身就可以成为一个独立的产品品类。multica-ai 在做的 Multica 平台,看起来就是在往这个方向铺路。
但我也要说一盆冷水。17.5 万星不代表 17.5 万人真的在用。GitHub 星标本质上是一个收藏动作,跟实际使用之间有巨大的落差。而且这个文件的效果高度依赖上下文窗口的质量和模型的遵循度,不同版本、不同场景下表现会参差不齐。它不是一个万能药,而是一个方向性的尝试。
资源地址
| 资源 | 地址 |
|---|---|
| GitHub | https://github.com/multica-ai/andrej-karpathy-skills |
| DeepWiki | https://deepwiki.com/multica-ai/andrej-karpathy-skills |
| 作者 Twitter | https://x.com/jiayuan_jy |
| 相关项目 Multica | https://github.com/multica-ai/multica |
总结
回头看这四条规则,你会发现它们共同指向一个更底层的范式:把 AI 当同事,不当工具。当成工具你会给它指令清单,当成同事你会告诉它目标,让它自己想办法。
如果你只用一句话记住这篇文章,记住这一句就够了。下次让 AI 写代码,别告诉它怎么做,告诉它什么算做对了。然后把验收标准写成一个测试。这个思路不是 Karpathy 发明的,但他用一个 175k 星的 CLAUDE.md 文件,让这件事变成了工程实践。
这套规则放进 Claude Code 只需要三十秒。真正需要时间的,是你在用它之后,开始反思自己过去的编码和协作习惯。那种感觉有点像第一次用 linter,一开始嫌烦,后来离不了。