
48.7k Stars,半年时间。但一个给 AI 编程 Agent 做”前置索引”的工具冲到这个数字,我的反应不是兴奋,是警觉。
AI 编程工具赛道卷到什么程度,不用我多说。Cursor、Claude Code、Codex、Aider、Cline——每个都在抢”谁更聪明”的牌桌。这时候冒出来一个说自己不增强模型推理能力、只减少上下文开销的工具,反而有点意思。
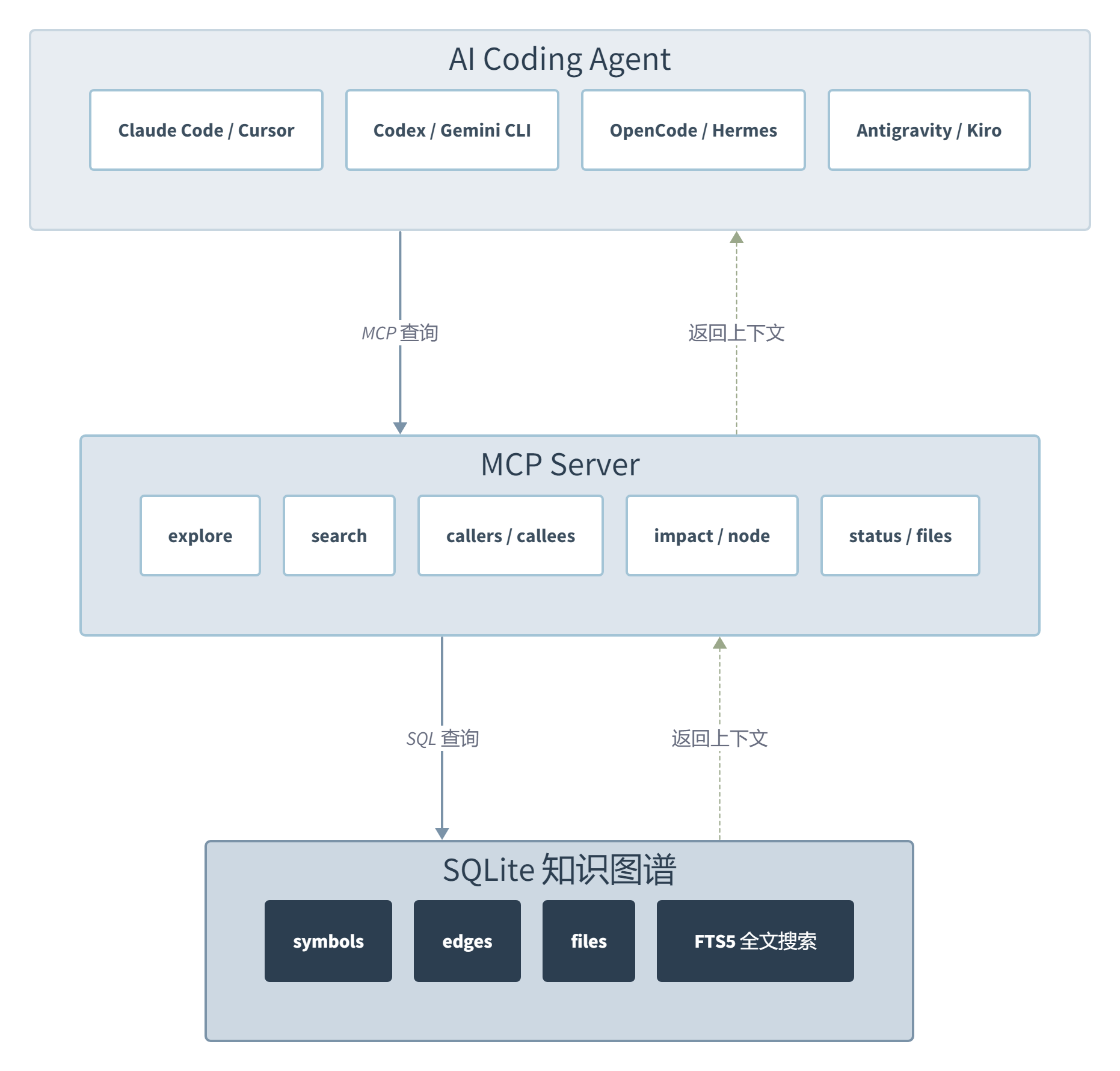
它的逻辑很直白:你的 Claude Code 在回答”这段代码怎么改”之前,花了大量预算在 grep、glob、Read 上先搞清楚”代码在哪”。CodeGraph 说,这部分工作可以提前做——把代码库变成一张知识图谱,Agent 直接查图而不是满仓库翻文件。
官方的数字更诱人:平均减少 47% Token、58% 工具调用、16% 成本。但这些数字背后有多少水分,得扒开来看看。
说白了这篇文章就想讲明白一件事:这个图谱能不能让你的 AI 编程 Agent 真的变聪明,还是只是省了几次 grep 调用。
但数字归数字。真正让我改观的,是翻完 README 和社区分析之后发现的几处设计。
打动我的几个地方
第一个,也是最核心的:它改的是 Agent 工作流里最贵的那一步。
没用 CodeGraph 的时候,Agent 面对一个陌生仓库的典型姿势是这样的:先 grep 搜关键词,找不到就换模式再搜,找到候选文件后 Read 打开看内容,发现不对继续翻——这个过程叫 discovery,而 discovery 占掉的 Token 和时间远比你直觉中多。
CodeGraph 的思路是:把 discovery 从”每次提问都重新做”变成”初始化时做一次,之后复用索引”。它用 tree-sitter 把源码解析为 AST,提取出符号(函数、类、方法)和边(调用、导入、继承、实现),存进本地的 SQLite 数据库里配 FTS5 全文搜索。Agent 之后就不是 grep 了,是直接查图。
这里的关键词是 tree-sitter,不是正则。正则抽符号属于”差不多能用”级别——Java 的 @Override 注解、Python 的装饰器、Rust 的宏,正则都容易漏。AST 解析是语言感知的,跨 20 多种语言能做到 95% 以上的跨文件覆盖率,这个工程投入不小。
第二个让我意外的是框架感知路由和跨语言桥接。
大多数代码索引工具停留在”找到函数调用关系”就结束了。CodeGraph 多走了两步:
它识别 17 个 Web 框架的路由绑定——Django 的 path()、FastAPI 的 @app.get()、Express 的 app.get()、Laravel 的 Route::get()、Spring 的 @GetMapping,甚至 React Router 和 SvelteKit 的文件路由。这意味着你可以问”/api/users 这个接口最终调了哪个函数”,Agent 能顺着路由定义一路追到 handler。
更狠的是 iOS/React Native 的跨语言桥接——它能连接 Swift 和 ObjC 的互调、React Native 的 NativeModules、TurboModules、Fabric 视图组件、Expo Modules。这些跨语言边界是传统静态分析工具的盲区,CodeGraph 靠的是 heuristic 规则补边。
第三个,MCP 协议接入,八个 Agent 即插即用。
一条 codegraph install 自动检测并配置以下 Agent,不需要手动改任何 MCP 配置文件:
Claude Code
Cursor
Codex CLI
opencode
Hermes Agent
Gemini CLI
Antigravity IDE
Kiro
对不想折腾配置的人来说,这个体验门槛降到了最低。
跑起来之后也基本不用管——文件监控器用原生 OS 事件(macOS 的 FSEvents、Linux 的 inotify、Windows 的 ReadDirectoryChangesW)监听变更,2 秒防抖窗口后增量同步。默认排除 node_modules、vendor、dist、build,自动尊重 .gitignore,大于 1MB 的文件不进图。
不过设计归设计——实际跑起来能不能兑现这些承诺?
上手什么感觉
安装确实快,三条命令的事:
curl -fsSL https://raw.githubusercontent.com/colbymchenry/codegraph/main/install.sh | sh
codegraph install
cd your-project && codegraph init
有 Node 的话 npm i -g @colbymchenry/codegraph 也行。完事之后 Agent 就会自动走 CodeGraph 的 MCP 工具了。
不过文档里没写清楚几件事:
-
首次索引大仓库(比如 VS Code 级别,约一万个文件)需要时间,虽然 README 说”无需手动操作”,但索引跑完之前 Agent 拿到的图谱不完整。如果刚 init完就扔一个架构问题给 Agent,结果可能还不如不用 CodeGraph。 -
database is locked这个报错在 Issue 区出现频率不低。原因是旧版本安装可能残留了不兼容的 SQLite 配置,或者项目放在 WSL2 的/mnt下(网络盘的 WAL 模式有问题)。官方说重装一次通常会好,但确实是一道卡点。 -
符号缺失不一定是 bug,大概率是自动同步还没跑完。等几秒或者手动 codegraph sync就行,但第一次遇到容易以为是工具坏了。
支持的 Agent 覆盖了当前主流选择:
Claude Code
Cursor
Codex CLI
opencode
Hermes Agent
Gemini CLI
Antigravity IDE
Kiro
零配置支持 20 多种语言这点也确实省心——从 TypeScript 到 Rust 到 Kotlin 到 Pascal,覆盖面在同类型工具里算第一梯队。
不过话说回来,上面这些亮点都属于”看 README 能了解个大概”的范畴。真正决定值不值得用的,是搞清楚它的适用边界。
什么时候用,什么时候别用
| 场景 | 典型用户 | 优势 | 局限 |
|---|---|---|---|
| 大型仓库架构问答 | 新接手项目的开发者 | 减少 50-80% 工具调用 | 首次索引耗时 |
| 跨模块调用链追踪 | 做重构/修 bug 的开发者 | trace/impact 工具直给结果 | 动态调用仍可能遗漏 |
| CI 增量测试 | DevOps/团队 Lead | affected 命令做传递依赖分析 |
需接入 CI 流程 |
| 跨语言/跨框架项目 | 全栈团队 | 框架路由 + iOS/RN 桥接 | 部分框架覆盖率 <80% |
| 小仓库(<100 文件) | 个人开发者 | 原生 grep 已经够快 | 维护图谱的成本 > 收益 |
有些场景则完全不该碰 CodeGraph,直接列出来免得踩坑:
-
你的日常工作以生成新代码为主,很少需要理解既有代码结构。CodeGraph 省的是 discovery 成本,不是生成成本。 -
你用的是不支持 MCP 的 Agent 或 IDE。CodeGraph 的核心交付形式是 MCP Server,没有 MCP 就完全接不上。 -
你的仓库主要是配置文件、YAML、Terraform 之类——tree-sitter 对这类 DSL 的解析覆盖率远不如通用编程语言。
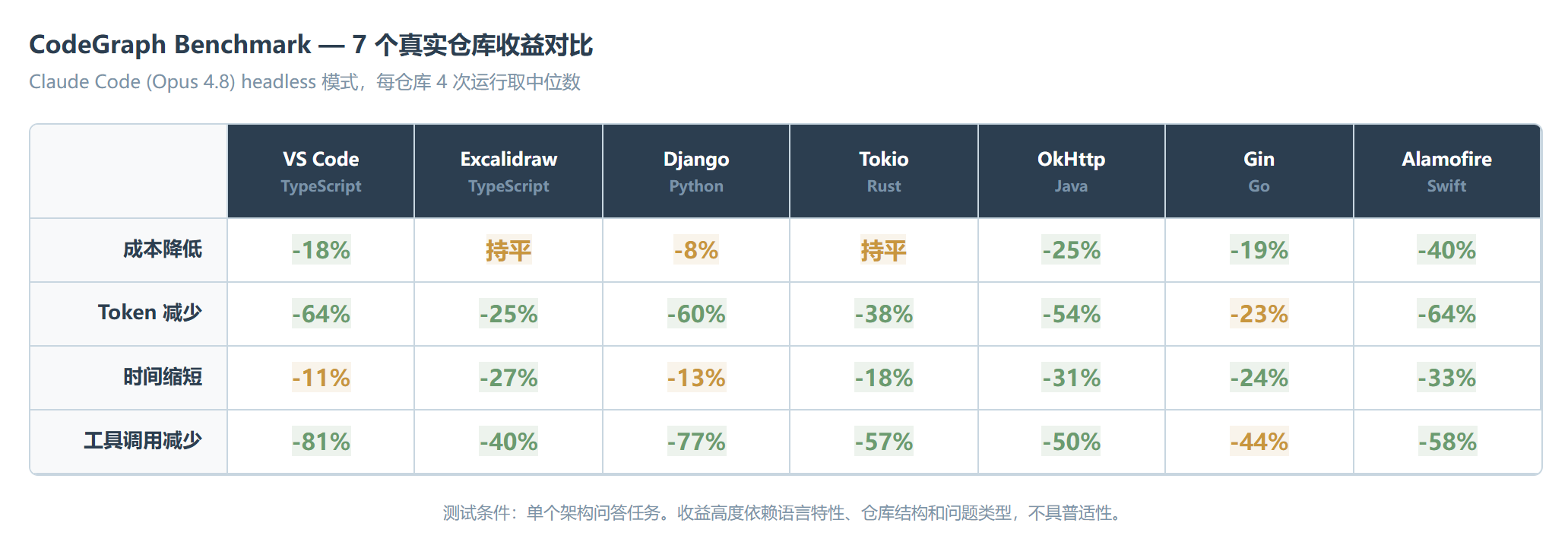
一个需要正视的事实:txtmix 的深度分析指出,官方 benchmark 的收益从 OkHttp(Java)的 2% 到 Tokio(Rust)的 82% 差距悬殊。收益高度依赖语言特性、仓库结构和问题类型,不是”接上就省一半”。
功能层面聊得差不多了。但选开源项目不能只看功能——维护者的状态有时比代码质量更能决定项目的命运。
社区怎么样了
| 指标 | 数据 | 说明 |
|---|---|---|
| Stars | 48.7k(截至 2026 年 6 月) | 半年内从 0 冲到近 5 万,增速极快 |
| 核心维护者 | 1 人(Colby McHenry) | Bus Factor = 1,是最大风险点 |
| Open Issues | 70 | 数量合理,但 162 个 Open PR 说明合并带宽不足 |
| 开源协议 | MIT | 完全商业友好,无使用限制 |
| 最新版本 | v1.0.1(2026-06-13) | 已出正式版,共 17 个 Release |
| 提交频率 | 501 次提交 | 活跃但明显由单人驱动 |
48.7k Stars 的增速确实惊人,但这个数字背后有一个容易忽略的细节:维护者只有一个人。Colby McHenry 自称 15 年以上经验的自学软件工程师,从提交记录来看代码质量不差,但 162 个 Open PR 堆在那里——这不是社区贡献踊跃,这是合并带宽严重不足。
社区讨论的质量倒不低。txtmix 那篇深度解析对 benchmark 的批评相当到位:”测试基于特定问题类型(架构问题),不代表日常混合任务的真实分布。”这个判断一针见血。官方说省 47% Token,但你的日常工作里有多少是”请求怎么到达数据库”这种结构理解问题,有多少是”帮我写一个 Button 组件”这种生成任务——前者越多,CodeGraph 越值。
知乎和 CSDN 上的几篇教程也反映了同一个现象:接入很快,效果有感知,但对”什么时候不该用”的讨论明显不足。这不是 CodeGraph 的问题,是所有高速增长的开源工具都会经历的阶段——先用起来,再慢慢搞清楚边界。
社区的数字说完了,但数字不会自己下判断。该说说我自己的结论了。
我的真实看法
CodeGraph 让我改观的地方不是它的 benchmark 数字,是它对 AI 编程 Agent 工作流的工程理解。
它解决的既不是”模型不够聪明”也不是”提示词写得不好”,而是一个更底层的问题:Agent 花了大把资源在找代码而不是理解代码。这个问题的存在感跟仓库规模成正比——小仓库感受不到,一旦过了几百个文件,discovery 成本就开始无声地吞噬你的 Token 配额。
从这个角度看,CodeGraph 不是”增强 Agent”的工具,是”减少 Agent 浪费”的工具。这种定位在 AI 编程赛道里反而不多见——大多数工具在卷”让 Agent 更聪明”,CodeGraph 在卷”让 Agent 少做无用功”。
但我对它的长期可持续性有三个保留:
第一,Bus Factor = 1。这是一个人的项目,而且增长太快。48.7k Stars 意味着关注度已经远超个人维护者能轻松驾驭的水平。162 个 Open PR 不是勋章,是警钟。
第二,v1.0.1 刚发布不到 24 小时(截至 2026 年 6 月 13 日),这是正式版的开始,也意味着 API 和 MCP 工具接口可能会有一轮调整。生产环境接入之前最好等一两个 minor 版本。
第三,CodeGraph 的商业模式还没明朗。README 提到 getcodegraph.com 有托管产品的早期 Beta 等待列表。MIT 协议保证了开源版不会突然收费,但如果托管产品成了主力方向,开源版的维护优先级会不会下降——这是一个需要持续观察的信号。
资源地址
| 资源 | 地址 |
|---|---|
| GitHub | https://github.com/colbymchenry/codegraph |
| 官方文档 | https://colbymchenry.github.io/codegraph/ |
| npm | https://www.npmjs.com/package/@colbymchenry/codegraph |
判断说完了。但判断本身不是终点——你得知道接下来该做什么。
说完了,该你了
如果你在维护一个几百到上万文件的项目,并且日常会问 Agent”这段逻辑是怎么串起来的”——装 CodeGraph,从最大的那个仓库开始索引。这一步几乎没有风险,不接外部服务,卸载也只是一条命令的事。
如果你主要写独立脚本、做小规模原型、或者团队用的 Agent 还不支持 MCP——先观望。原生 grep 对你来说足够快,CodeGraph 带来的额外维护面(索引、同步、排查)可能不值得。
如果你在纠结要不要在生产环境接入,关注两个指标:合并 PR 的速度是不是在加快(意味着维护带宽在扩充),以及 v1.0.x 的小版本迭代是否稳定(意味着 API 没有大改的风险)。这两点决定了这个工具能不能从”一个人维护的好工具”变成”团队可以依赖的基础设施”。
半年 48.7k Stars 的速度在开源圈不多见。但 Star 可以点一下就有了,一个稳定合并 PR 的维护者团队不行。