
整个 AI 编程赛道都在做同一件事:帮 AI 写代码。Cursor 帮你补全,Claude Code 帮你重构,GitHub Copilot 帮你生成。Understand-Anything 做了一件所有人都觉得理所当然、却几乎没人真正去做的事:帮人读懂代码。
对,就是字面意思的”读”。你刚接手一个 20 万行的代码库,文档过时了,架构图没人画过,唯一的”知识库”是三个已离职同事的聊天记录。Understand-Anything 塞给你一张交互式知识图谱:每个文件是一个可点击的节点,每个函数有摘要和标签,依赖关系用线连出来,你甚至可以直接搜”支付流程怎么走的”然后看它把整条调用链高亮出来。
这颗图谱不是静态的 PPT 插图。你可以点进去看某个函数的业务含义、翻它的导入导出关系、让 AI 导游带你按正确顺序走一遍架构。它甚至会自动把代码按层次分组:API 层是蓝色的,Service 层是绿色的,Data 层是灰色的。对于任何一个被丢进陌生代码库的开发者来说,这玩意儿比三个月的 onboarding 文档管用。
说白了这篇文章就想讲明白一件事:在这个所有人都在追”让 AI 自己写代码”的时代,Understand-Anything 选择了一条更稀缺的路,让 AI 先帮人看清代码长什么样,再决定怎么改。这条路走通了没有?往下看。
一个图谱,七套眼睛
Understand-Anything 真正的核心不是某个单一功能,而是一套多 Agent 流水线。七个 Agent 各自负责一块视角,像不同专业的同事围着代码库开会。
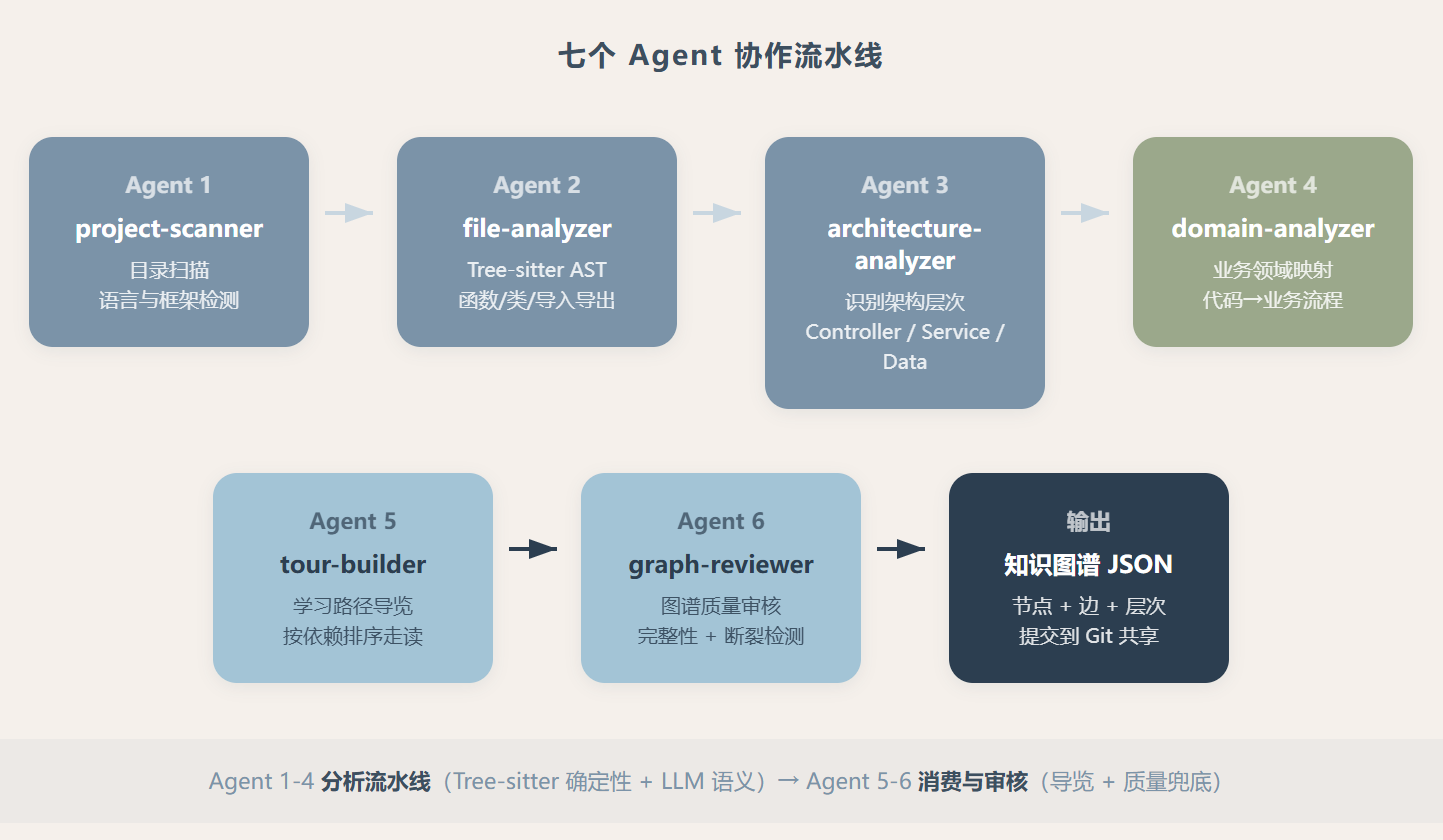
project-scanner 最先上场,扫目录结构、检测语言和框架。它决定了后面所有 Agent 的工作范围。接着 file-analyzer 上场,用 Tree-sitter 把每个文件拆成 AST,提取函数、类、导入导出关系。这一步是纯确定性的,同样的代码永远输出同样的结果。没有幻觉问题。
architecture-analyzer 接着上场,把散落的文件归类到架构层次里。不是拍脑袋分的,它读每个文件的引用模式和命名约定,自动判断”这个目录大概是 Controller 层”“那个像是数据访问层”。domain-analyzer 更进一步,从函数名、注释、调用关系里推断业务领域。把代码里的 handlePayment() 映射到业务概念”支付流程”,把 sendNotification() 归入”消息通知”。这不是 grep 能做到的事。
最后两套眼睛最特别。tour-builder 不分析代码本身,它分析”学习路径”,按依赖关系排出一个应该先看哪个文件、再看哪个文件的导览序列。graph-reviewer 做质量兜底,检查图谱的完整性:有没有文件被遗漏、跨模块引用是否断裂。六个分析 Agent 生成的结果,由第七个 Agent 来审。
这套流水线的设计哲学很清楚:把确定性的事交给 Tree-sitter(不会犯错),把需要理解的事交给 LLM(可以犯错但有 reviewer 兜底),两个引擎的边界划分得很干净。文件分析器支持 5 个并发、每批 20-30 个文件,对于 500 文件以下的代码库,Analysis 在几分钟内就能完成。
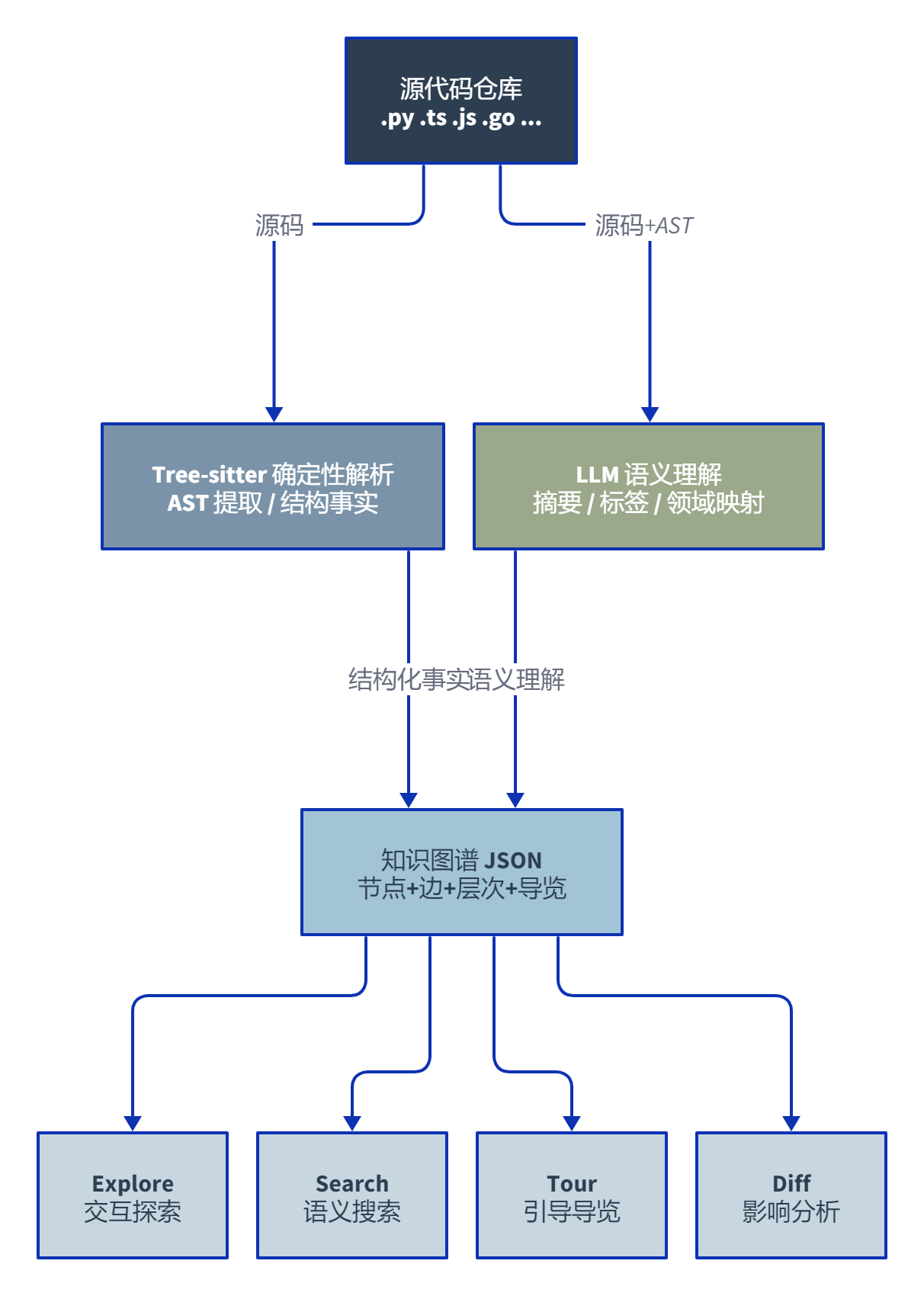
交互层面还有两个让我意外的细节。一个是模糊搜索,你不需要记住精确的函数名,输入”认证相关的部分在哪”它就能定位。搜索走的是语义匹配而非关键词。另一个是 Committer 级别的 diff 影响分析,提交前它会告诉你当前改动会波及哪些模块、哪些函数间接受影响。这不是 CI 里跑的测试覆盖率报告能替代的东西。
跑起来看:一行命令然后等
Understand-Anything 的安装路径宽到离谱。15 个平台原生支持,Claude Code 里直接走插件市场:
/plugin marketplace add Egonex-AI/Understand-Anything
/plugin install understand-anything
如果用的是 Cursor、VS Code Copilot、Cline 等支持自动发现的平台,你甚至不需要手动安装。macOS 和 Linux 走一行 curl:
curl -fsSL https://raw.githubusercontent.com/Egonex-AI/Understand-Anything/main/install.sh | bash
Windows 的 PowerShell 同样一行解决。
装完之后跑 /understand,剩下的事就是等。这个”等”是 Understand-Anything 最诚实的体验门槛。它用的是按需转换策略,每次查询时实时解析相关代码。100-1000 个文件的代码库,首次构建需要几分钟;跨模块的复杂继承分析也快不到哪去。
常见坑点有两个,都跟这个实时解析架构有关。第一个是内存:大型单体仓库(5000+ 文件)的首次分析可能会拖到 10 分钟以上,期间 CPU 持续高负载。Issue 区的讨论建议把分析范围限制在子目录:/understand src/frontend 而不是整个仓库。第二个坑是增量更新的触发机制。按文档说用 --auto-update 提交后会自动刷新图谱,但实际上如果你同时改了 20 个文件且涉及跨模块依赖变更,增量更新偶尔会漏掉间接引用。graph-reviewer 会标记这些断裂点,但它不会自动修复。
图谱本身以 JSON 格式存在 .understand-anything/knowledge-graph.json,可以提交到 Git 给团队共享。超过 10MB 建议上 git-lfs。已有团队拿它给 GoogleCloudPlatform/microservices-demo 这种多仓库项目建了共享知识库,效果反馈不错。
什么时候必装,什么时候别碰
适用场景用一张表说清楚:
| 场景 | 典型用户 | 优势 | 局限 |
|---|---|---|---|
| 接手陌生中型代码库 | 新入职/转岗开发者 | 十几分钟建立全局认知,替代散落的 onboarding 文档 | 第一次构建需要等待 |
| 技术选型前的架构评估 | Tech Lead / 架构师 | 架构层次可视化 + 依赖热区一目了然 | 跨语言项目分析准确度下降 |
| 新人入职 Onboarding | 团队管理者 | 导览系统按正确顺序走读,不需要老员工陪跑 | 图谱需要定期更新保持同步 |
| 大型重构前的依赖摸底 | 资深开发者 | Diff 影响分析精确到函数级,避免遗漏间接依赖 | 超大型仓库(10000+ 文件)构建时间过长 |
不适用的情况同样明确。你只是想修一个已知位置的小 Bug,用不着开一整个图谱,grep 加 IDE 跳转够了。你的代码库是 Java + Python + Go 加一堆 shell 脚本的混合体,Tree-sitter 的跨语言桥接能力目前还不算稳。更根本的是,如果你追求的是”让 AI 直接帮你改代码”那种体验,Understand-Anything 不对这个账。它解决的是理解问题,不是生成问题。

这里就必须提到 CodeGraph。两个项目的定位差异大到像是不同物种:CodeGraph 做预索引,首次构建慢但之后每次查询都是毫秒级,目标是让 AI Agent 以最低 Token 成本获取代码上下文。Understand-Anything 做按需转换,每次查询可能都要解析代码,但目标是让人看得舒服、点得明白。一个给机器用,一个给人用。
但实际情况比这个对比复杂。CodeGraph 在社区的技术讨论热度更高,HackerNews 上有人直说”给它 2000 个文件的 TypeScript 项目,索引完之后的查询体验像本地文件系统一样顺畅”。Understand-Anything 在用户体验侧的投入更多,包括角色自适应 UI、业务领域映射、学习导览。你要的是 Agent 效率就选前者,要的是团队知识沉淀就选后者。
59k Stars 用了不到一个月,然后呢
先说硬指标:
| 指标 | 数据 | 判断 |
|---|---|---|
| Stars | 58.9k(截至 2026.06.14) | 2026 年 5 月下旬约 22k,三周翻 2.7 倍 |
| 核心维护者 | Yuxiang Lin + Infinite Universe, Inc. | Bus factor 偏低,但公司实体支撑降低了单点风险 |
| 协议 | MIT | 无商业使用顾虑 |
| 最新 Release | v2.7.3(2026.05.19) | 发布节奏稳定,7 个 Release 覆盖 570 commits |
| Open Issues | 75 | PR 120 个待合并,说明贡献活跃但 review 有积压 |
Stars 的增速需要拆开看。22k 到 59k 的三周暴涨时间线,和 Claude Code 插件生态的大规模推广高度重合。Understand-Anything 是 Claude Code 插件市场的标杆项目之一,官方推荐位给了可观的流量。这不是坏事,但也不全是自然增长。真正值得看的不是 Star 数,是 120 个待合并的 PR。一个 58k Stars 的项目如果 PR review 积压了 120 个,意味着贡献者的耐心在被消耗。
社区的正面声音集中在这几个方面:可视化做得”超出预期好用”(Better Stack 出的走读视频评论区原话)、业务领域映射被 PM 群体强烈认可、多语言 README(中/日/韩/西/土/俄)降低了非英语社区的上手门槛。CNBlogs 上有一位连续对比了三款代码图谱工具的开发者,对 Understand-Anything 的评价是”最接近我理想中’代码浏览器’的产品,但离那个目标还有距离”。
50k+ Stars 加上 MIT 协议,加上 15 平台支持。这组配置的安全垫已经足够厚了。但 120 个积压 PR 和单维护者模式是两个需要盯着的指标。如果接下来三个月 PR review 速度没有改善,贡献者流失会加速。
值不值得跟?我看的三个信号
先给结论:Understand-Anything 值得放进你的工具链,但要放对位置。
它不是 Copilot 的替代品,也不是 CodeGraph 的替代品。它占据了一个目前几乎没有对手的生态位:把代码库从”需要死记硬背的文本堆”变成”可以逛、可以搜、可以问的结构化空间”。这个体验一旦用过,回头再看纯文本的代码导航,会有明显的降级感。
我看好的三个信号。
- 第一,Claude Code 插件生态在 2026 年上半年的增长速度超出了大多数人的预期,Understand-Anything 作为生态中的标杆项目,会持续吃到这波红利。
- 第二,LLM 的上下文窗口在变大,但 Token 成本并未同比例下降,很多团队的解决思路正从”塞更多 Token 进去”转向”先理解再精准检索”,Understand-Anything 的按需转换架构恰好对齐了这个方向。
- 第三,120 个待合并 PR 虽然让人皱眉,但反过来看,说明贡献者社区已经在自发形成了。这不是一个靠创始人一口气硬推的项目。
但也有两个让我犹豫的信号。120 个 PR 积压本身就是一个反信号。如果 maintainer 的带宽跟不上贡献的增长,项目会陷入”Stars 暴涨但实质迭代放缓”的尴尬期。另一个是竞争格局。CodeGraph 和 graphify 分别在 Agent 效率和代码分析深度上有各的积累,Understand-Anything 在可视化体验和业务映射上的领先能否持续,取决于它能不能把”好用”变成”不可替代”。
我看这个问题的角度跟三个月前不一样了。三个月前我以为代码理解工具是 AI 编程的过渡产物,模型上下文窗口大到一定程度之后就不需要了。现在我的判断反过来了:代码理解工具会越来越重要,不是因为模型不够强,是因为真实世界的软件工程从来不是一个人的游戏。你需要让别人也能看懂你的代码,你需要让新加入的同事 15 分钟建立全局认知而不是三周。Understand-Anything 做的就是这个账。
资源地址
| 资源 | 地址 |
|---|---|
| GitHub | https://github.com/Egonex-AI/Understand-Anything |
| 官网 | https://understand-anything.com |
| Live Demo | https://understand-anything.com/demo/ |
| 社区视频教程 | https://www.youtube.com/watch?v=VmIUXVlt7_I |
说完了,该你了
如果你正在接手一个陌生的中型代码库。装了它,跑一次 /understand,然后花十分钟逛一遍图谱。这件事的成本是一行命令加几分钟等待,收益是一张你靠自己翻文件可能要花几天才能建立起来的全局认知。
如果你还在观望。盯两个指标:PR review 速度(120 个积压是减还是增)和增量更新机制(Issue 区有没有更多人抱怨它漏引用)。这两点决定了这个项目能不能从”一个人用着很爽的工具”变成”一个团队可以依赖的基础设施”。前一个决定了贡献者留存,后一个决定了生产环境的可靠性。
话说回来,58k Stars 的三周暴涨,到底是泡沫还是信号?我的直觉是两者都有。但翻完 Issue 区、看完那 7 个 Agent 的分工、理清楚 Tree-sitter 和 LLM 的边界设计之后,我的天平歪向了后者。这个项目做的账是对的。现在要看的是执行。