
我上一次认真用 RSS 阅读器是去年的事。一个笨重的本地客户端,里面塞着七八十个源,每天打开看到四位数的未读数,焦虑感比信息量先涌上来。后来算法推荐接管了一切,Twitter 的 For You、Google Discover、各种”你可能感兴趣”,我慢慢把 RSS 这件事忘了。
但最近一年多,风向有点变了。越来越多人开始抱怨算法推荐的盲区。你关注的人发了一篇重要的博客,平台不推给你。GitHub 上一个你盯了三个月的项目默默更新了 README,没人通知你。信息源在变多,但有效触达率在变差。
BlogWatcher 就是在这个背景下出现的。它是 Peter Steinberger 写的一个 Go 命令行工具,唯一的功能就是盯着你指定的那些博客和 RSS 源,告诉你谁更新了。没有推荐算法,没有社交层,甚至没有图形界面。一个纯粹的”信息雷达”。
说真的,这篇文章不打算跟你扯什么信息焦虑的大词。我把这个工具的使用链路、设计取舍和你可能会用到的几个场景拆了一遍。如果你也在找一种不受算法干扰的信息获取方式,BlogWatcher 的思路至少值得你花五分钟了解一下。
环境准备
上手 BlogWatcher 的门槛低到几乎可以忽略。它本质是一个 Go 编译出来的独立二进制文件,零运行时依赖,不需要 Python 环境,不需要 Node.js,不需要 Docker。你在终端里能输入命令,它就准备好了。
安装有两条路。如果你已经在用 OpenClaw 生态,一条命令搞定:
openclaw skills install blogwatcher
不想依赖 OpenClaw 的话,走标准 Go 安装也可以:
go install github.com/Hyaxia/blogwatcher/cmd/blogwatcher@latest
装完之后跑个 help 验证一下,出现命令列表就说明环境 OK 了。如果报 “command not found”,大概率是 Go 的 bin 目录没加到 PATH 里,Windows 用户常见的问题,确认 $GOPATH/bin 或 %GOPATH%\bin 在环境变量里就行。
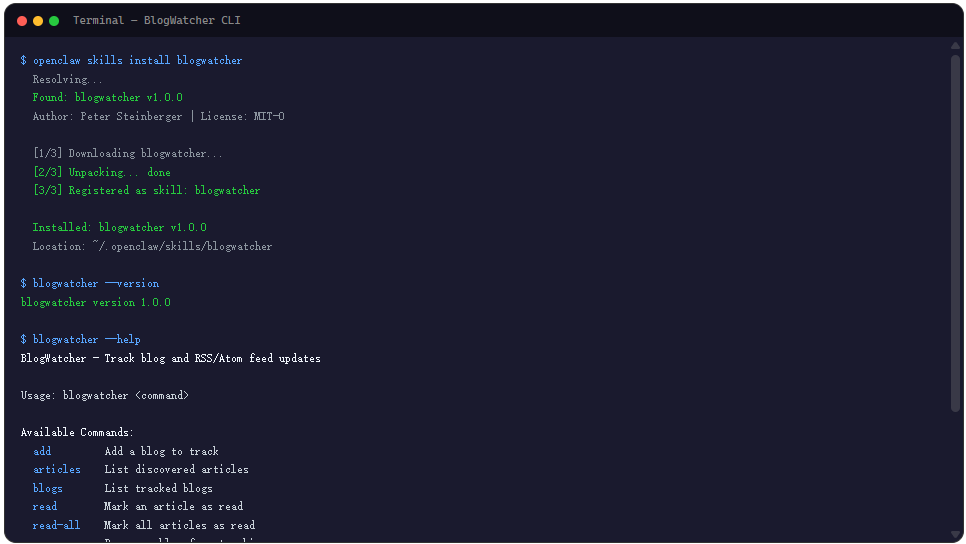
打个底:这个工具目前版本是 v1.0.0,作者在一个月前完成的最后一次更新。功能集已经稳定,不算活跃开发中,但核心能力足够日常使用。
操作流程
BlogWatcher 的使用逻辑非常简单,简单到你可能觉得”就这?”。但正是这种简单让它不会被你闲置。
整套操作围绕五个子命令展开:添加源、列出源、扫描更新、看文章、标记已读。你不需要记参数表,跑一遍就记住了。
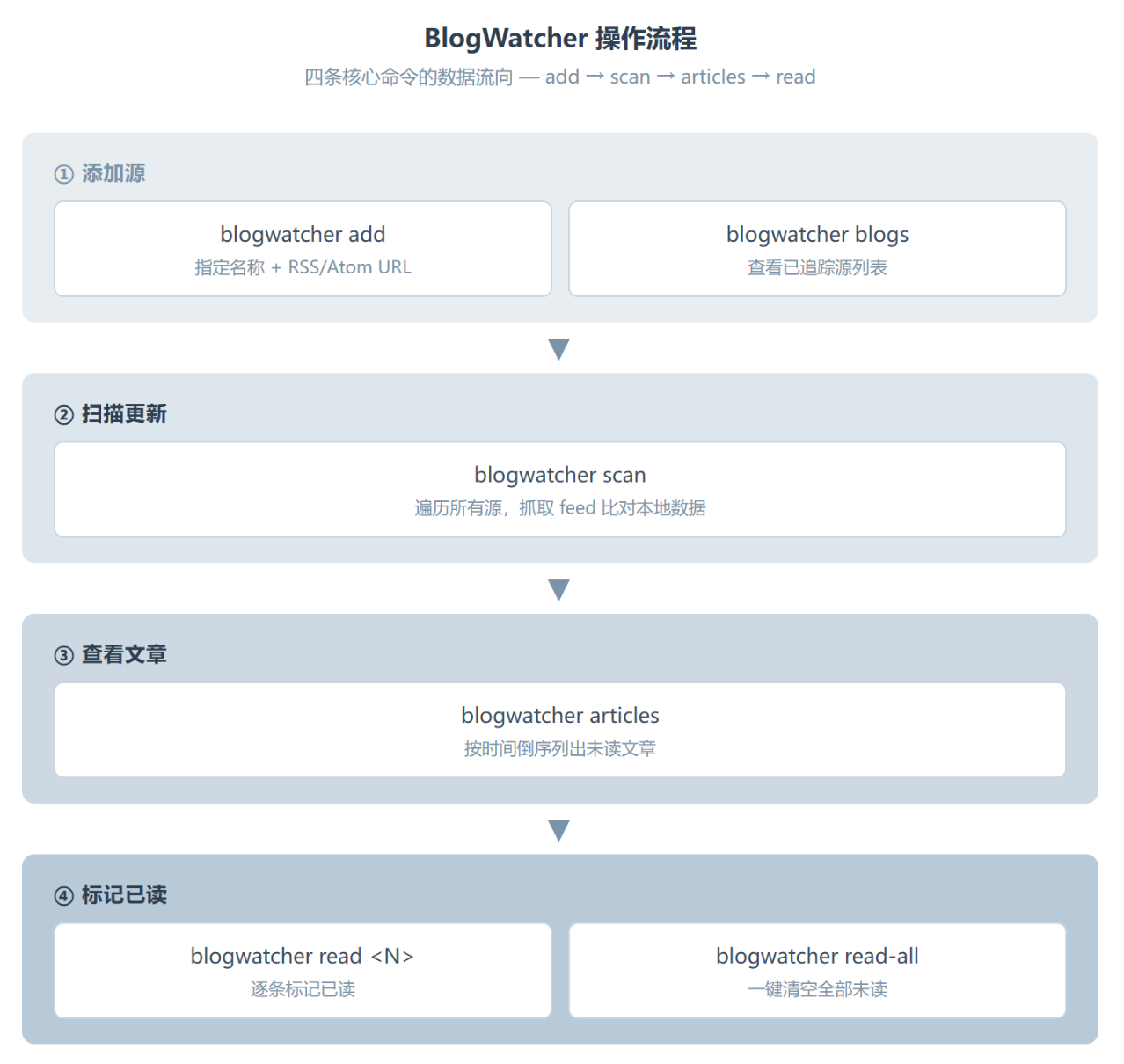
添加一个博客源是最先做的事:
blogwatcher add "技术博客名" https://example.com/feed
URL 可以是 RSS 也可以是 Atom 格式,工具两种都认。加完之后用 blogwatcher blogs 看一眼列表,确认源已经进了追踪清单。这里有一个小细节值得提前知道:命令里的博客名不是随便起的标签,它是后续 remove 和列表展示时的唯一标识,别用”blog1″”test”这种随手写的名字,给自己找麻烦。
扫描更新是核心操作:
blogwatcher scan
这个命令会遍历你加进去的所有源,逐个抓取 RSS/Atom feed,比对本地存储的数据,吐出新增的文章数。输出格式很干净,每个源一行,告诉你抓到了多少篇、其中几篇是新的。没有花里胡哨的进度条,没有卡顿,几个源基本秒出结果。
扫完后用 blogwatcher articles 看文章列表。每条有编号,按时间倒序排。看完的用 blogwatcher read 编号 单独标,或者直接 read-all 一键清空。整个流程从打开终端到完成扫描,通常不超过十秒。
这套流程的节奏感很好。你不用想着”得去检查一下有没有更新”,而是习惯性地敲一个 scan,像检查邮件一样自然。工具本身不做推送,不弹通知,它只是在你问它的时候,老老实实汇报结果。
关键设计
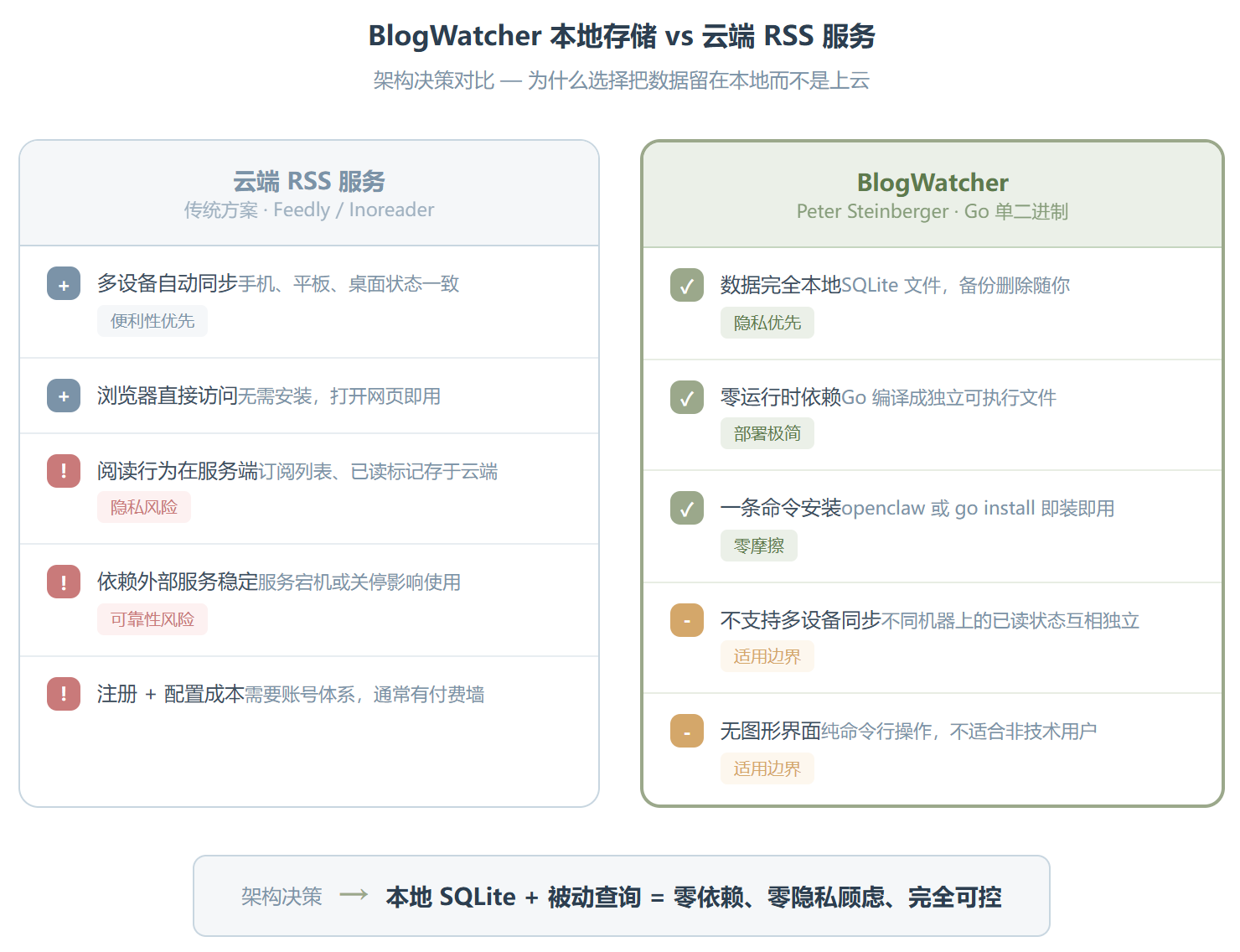
BlogWatcher 在架构上做的最聪明的决定,就是把数据存在本地 SQLite 里。
这件事听起来平平无奇,但它直接决定了使用体验。你不需要注册账号,不需要配 API Key,不需要担心第三方服务挂了你的数据就没法用。所有东西都在你机器上一个 .db 文件里,想备份就备份,想删就删。Peter Steinberger 显然是在刻意回避”云依赖”,这是有态度的一种设计选择。
但这个选择的另一面也很明显:
| 维度 | 本地存储(BlogWatcher) | 云端同步(Feedly/Inoreader) |
|---|---|---|
| 隐私 | 数据完全本地 | 阅读行为在服务端 |
| 多设备 | 不支持 | 原生支持 |
| 可靠性 | 不依赖外部服务 | 服务宕机影响使用 |
| 安装成本 | 一条命令 | 注册+配置 |
选本地存储就意味着放弃跨设备同步。你在公司电脑上标的已读,家里的电脑不知道。对于多设备用户来说,这是一个硬伤。但换个角度想,如果你就是把 BlogWatcher 当成开发机上的工作流工具,而不是消费级的阅读器,这个取舍就说得通了。
另一个值得聊的设计是 Go 单二进制部署。作者没有用 Node.js 或者 Python 去写这个工具,而是选了 Go,把整个程序编译成一个没有任何外部依赖的可执行文件。这对于 CLI 工具来说是一个很成熟的选择,部署体验比需要装一堆包的工具好得多。代码托管在 GitHub 上(github.com/Hyaxia/blogwatcher),MIT-0 许可,70 个 Star,体量不大但结构清晰。
我不确定的一个点是,作者为什么没有加一个 notification hook。从社区 feedback 来看,这是被提得最多的需求,扫描完之后自动通过系统通知或者 Webhook 推一条消息。技术上不复杂,可能是作者更倾向于保持”被动查询”的交互模型,让工具不主动打扰你。这个理念本身没问题,但如果能做成可选功能,会减少不少”忘了 scan”的情况。
使用场景
BlogWatcher 最擅长的那种场景,是你有一批固定要盯的信息源,但不需要每天都逐篇看完。
盯竞品动态是一个典型场景。假设你关注了几个同行的技术博客、产品更新日志、创始人的个人站点,把它们全部加到 BlogWatcher 里。每隔几天跑一次 scan,扫一眼新文章的标题,挑感兴趣的读。比每天点开五六个网站高效得多,也不会漏掉什么。
技术情报收集也适合这个工具。arXiv、工程博客、安全公告、框架的 changelog,这些源的更新频率参差不齐,有的一个月不发,有的一周好几篇。用 RSS 集中管理比挨个打开查看合理得多,BlogWatcher 做的就是把这个集中管理变成一个命令行动作。
个人知识管理的场景也很贴切。越来越多技术写作者选择自建博客而不是在平台上发,博客的独立性在回升。你关注的那些人的个人站点,多数都提供 RSS。把他们的源集中追踪起来,等于给自己建了一个去中心化的信息入口。
但这个工具的适用边界也很清楚。BlogWatcher 不做内容提取,你看到的是标题和链接,想看正文还得打开浏览器。它不做全文搜索,历史文章没有索引。它不做推荐,你加什么就看什么。如果你需要的是一站式阅读体验,Feedly 或者 Inoreader 依然是更合适的选择。BlogWatcher 的定位是”扫描仪”,不是”阅读器”。
另外有一个现实问题:不是所有网站都提供 RSS 了。Medium 的自定义域、Substack 的 newsletter、Twitter 的 thread,这些内容源的 RSS 支持不完整或者根本不存在。碰到这种情况,你需要搭配 RSS Bridge 之类的工具做桥接,这就会增加维护成本。BlogWatcher 本身不解决”没有 RSS”的问题,它只解决”有了 RSS 怎么高效追踪”的问题。
洞察与反思
从一个更广的视角看,BlogWatcher 代表的不只是一个小工具,更是一种对信息获取方式的立场表达。
过去十年的主流叙事是”个性化推荐 > 主动订阅”。平台知道你想看什么,你不用自己去发现。这个叙事在产品层面确实赢了,但代价是用户丧失了对信息源的控制权。你看到的不是你选的,是算法帮你选的。2026 年的今天,RSS 和命令行工具的重新抬头,某种意义上是在纠正这个失衡。
BlogWatcher 在 ClawHub 上拿到 43,000 次下载这件事本身也说明了一些东西。一个没有任何图形界面、只能用命令行操作的 RSS 工具,能在这个体量被下载,说明有一批用户正在主动寻找”更笨的工具”。不是功能更多的工具,而是功能更少、但完全受自己控制的工具。
我注意到这个趋势在开发者群体里尤其明显。最近两年,CLI first 的信息管理工具越来越多,从 newsboat 到 miniflux 再到 BlogWatcher,每一代都在做减法。这种”减法思维”跟主流产品的”加法逻辑”完全相反,但它恰好击中了那些被功能臃肿折磨过的用户的痛点。
BlogWatcher 目前的功能还比较基础。它的订阅管理是纯文本的,没有分组、没有标签、没有优先级。如果你订阅超过一百个源,列表会变得很难维护。v1.0.0 能做的事情基本就是本文讲的这些,后续会不会加功能,取决于作者和社区的投入。但换个角度想,一个工具如果功能加得太快,反而容易变成它最初想替代的那种臃肿产品。这个平衡不好把握。
| 资源 | 地址 |
|---|---|
| ClawHub | https://clawhub.ai/steipete/blogwatcher |
| GitHub | https://github.com/Hyaxia/blogwatcher |
收尾
BlogWatcher 不是什么革命性的产品,它做的事情几十年前的 RSS 阅读器就在做。但它的价值恰恰在于”没做什么”。没有算法推荐,没有社交功能,没有云同步,没有推送通知,甚至连一个网页界面都没有。
这种”克制”在当前的 AI 工具生态里是稀缺品。人人都在给产品加 AI 能力、加固有智能、加个性化推荐的时候,一个只做”扫描 RSS 并告诉你结果”的工具反而显得很特别。
如果你每天的信息获取被算法推荐裹挟,花五分钟装一个 BlogWatcher,加五个你真正关心的源,试一周。不一定要用它替代现有的阅读方式,但至少体验一下”自己选择看什么”的感觉。那种掌控感,比任何推荐算法都好。