
说一个你可能也遇到过的场景。你让 AI 帮你查一个网站上的信息,AI 说它不能访问网页。你让它帮你填一个在线表单,它告诉你它没有浏览器。你让它帮你截一张网页的图,它回你一段文字描述。这事搁在 2025 年之前算正常,但放到现在,已经不应该了。
MCP 协议的出现让这件事开始松动。以前 AI 只能通过 API 跟外部世界交互,就像一个只会打电话的人。但 MCP 给它装上了手脚,让它能操作数据库、读写文件、甚至操控浏览器。Playwright MCP 就是这条通路上的一个关键拼图,它把微软开源的 Playwright 浏览器自动化框架包装成了一个标准 MCP 服务,让 AI 能像人一样浏览网页。
这个 Skill 在 ClawHub 上有 42,900 次下载、155 个星标,算不上爆款,但在 MCP Tools 分类里已经是头部选手。作者 spiceman161 把 Playwright 的 API 浓缩成了 10 个 MCP 工具,从导航到点击到数据提取,覆盖了浏览器自动化里最常用的操作。许可证用的是 MIT-0,可以说毫无使用门槛。
说白了,这篇文章想讲的就一件事:Playwright MCP 怎么让你的 AI 助手获得一双”眼睛”和一只”手”,以及在这个看似简单的包装背后,有哪些你可能会忽略的设计考量和实际坑位。
环境准备
Playwright MCP 的前置条件不复杂。你需要 Node.js 18 以上,剩下的就是一条安装命令。但这里有个容易忽略的细节:Playwright 本身需要下载浏览器二进制文件。Chromium 的包大约 150MB,如果你在网络条件不太好的环境下操作,这一步可能会卡很久。
安装本身分两步。先用 npm 全局安装 MCP 包,再把浏览器二进制文件拉下来:
npm install -g @playwright/mcp
npx playwright install chromium
如果你不想全局安装,用 npx @playwright/mcp 也能跑,但每次启动都会检查包版本,启动速度会慢一些。对于需要在多个项目里频繁使用的场景,全局安装更划算。
验证安装也很简单。跑一下带 --version 参数的命令,如果能看到版本号,说明环境已经就绪。初次启动时 MCP 服务器默认带着 Chromium 浏览器一起跑,你可以加 --headless 把它切到后台模式。如果报了找不到浏览器的错,补一次 npx playwright install 通常就能解决。还有一个常见的坑是端口冲突,如果你本机已经跑了其他 MCP 服务,记得检查一下 STDIO 管道有没有被占用。
操作流程
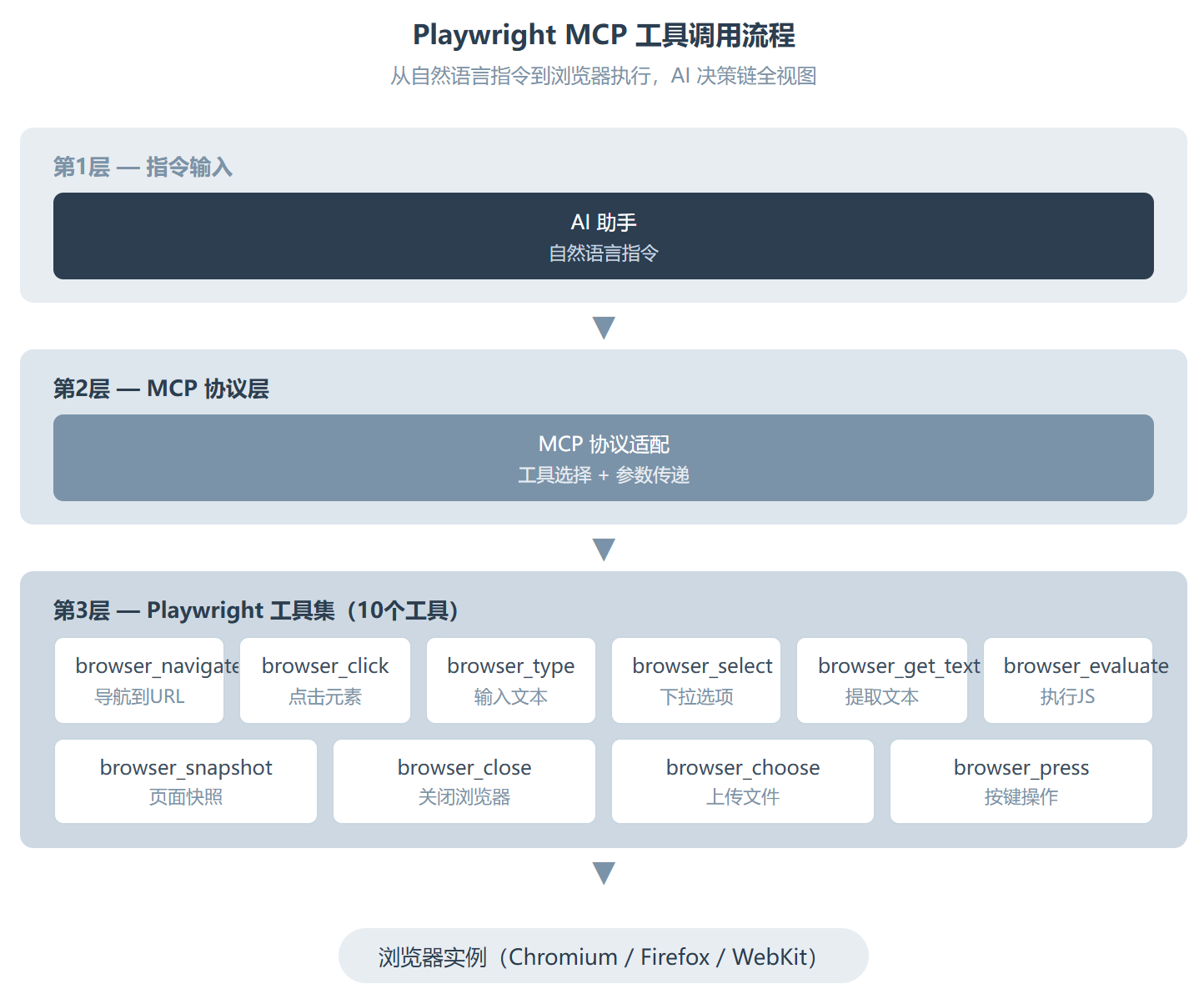
Playwright MCP 的工作方式跟传统的 Playwright 脚本有本质区别。你不是在写代码控制浏览器,而是通过 MCP 协议让 AI 助手调用浏览器。这个角色转换意味着你不需要关心选择器怎么写、异步逻辑怎么处理,你只需要告诉 AI 你想做什么,AI 自己去调对应的 MCP 工具。
这个 Skill 提供了 10 个 MCP 工具,覆盖了浏览器操作的基本面:
| 工具 | 作用 | 典型场景 |
|---|---|---|
| browser_navigate | 导航到 URL | 打开网页、跳转页面 |
| browser_click | 点击元素 | 按钮点击、链接跳转 |
| browser_type | 输入文本 | 表单填写、搜索框输入 |
| browser_select_option | 选择下拉菜单 | 筛选、配置选择 |
| browser_get_text | 提取文本内容 | 数据抓取、内容验证 |
| browser_evaluate | 执行 JavaScript | 页面交互、数据提取 |
| browser_snapshot | 获取页面快照 | 页面结构分析、无障碍信息 |
| browser_close | 关闭浏览器 | 清理上下文 |
| browser_choose_file | 上传文件 | 文件提交 |
| browser_press | 按键操作 | 键盘快捷键 |
这些工具不是孤立使用的。实际流程中它们会按”导航、交互、提取、关闭”的链条组合调用。比如一个典型的数据抓取流程:先用 browser_navigate 打开目标页面,用 browser_snapshot 理解页面结构,找到目标数据的位置,然后用 browser_evaluate 执行一段 JavaScript 把数据拉出来,最后 browser_close 收尾。
表单交互是另一个高频场景。你告诉 AI”帮我登录这个网站”,AI 会自己决定先 browser_navigate 到登录页,用 browser_type 填入用户名和密码,browser_click 提交按钮,最后用 browser_get_text 验证登录是否成功。整个过程你不需要写一行代码。但有个现实问题:如果页面 DOM 结构比较复杂,比如用了 Shadow DOM 或者动态渲染的组件,AI 可能会选错元素。这时候你就需要给一些具体的提示,告诉它目标元素的 id 或者 class 名。
数据提取场景里最实用的工具是 browser_evaluate。它允许 AI 在页面上下文中执行任意 JavaScript,这意味着你可以用一行 JS 把整个表格的数据转成 JSON 拉出来,比逐行 browser_get_text 高效得多。但这也带来一个安全考量:如果你允许 AI 执行任意 JS,它理论上可以操作页面里的任何东西。Playwright MCP 默认限制了文件系统访问范围,同时支持 --allowed-hosts 白名单控制,这些措施在实际使用中不可跳过。
关键设计
Playwright MCP 在设计上做了一个我认为很聪明的取舍:它没有试图把 Playwright 的所有 API 都包装成 MCP 工具。Playwright 原生的 API 有上百个方法,但 spiceman161 只选了 10 个。这不是偷懒,是对 MCP 协议”工具调用”语义的深刻理解。
MCP 的核心交互模式是”AI 选择工具、传参数、等返回结果”。如果工具太多,AI 的决策负担会急剧增加,选错工具的概率也更高。一个好的 MCP Skill 不是 API 的一比一映射,而是对使用场景的提炼和抽象。10 个工具刚好覆盖了”浏览网页、交互页面、提取数据”这三个核心需求,不多不少。
另一个值得注意的设计选择是 STDIO 传输。Playwright MCP 默认走 STDIO 模式,通过标准输入输出管道跟 AI 宿主通信,而不是 HTTP。这个选择有几个好处:不需要开放网络端口,安全面更小;启动延迟低,AI 调用工具的等待时间短;不依赖网络栈的稳定性,本地管道天然可靠。代价是你不能把它部署成远程服务,但对大多数个人使用场景来说,这不是损失。
安全设计上,Playwright MCP 做了一些必要的限制。默认开启浏览器沙盒,默认阻止 Service Workers,默认限制文件系统访问在工作区根目录。--allowed-hosts 的白名单机制可以防止 AI 被诱导访问恶意网站。这些设计不是可有可无的附加功能。当 AI 获得了操控浏览器的能力,安全问题就不再是”会不会出 bug”,而是”被别人利用能做什么”。从安全审计通过的结果来看,这个 Skill 在这一点上是及格的。

它也有明显的局限性。对需要复杂多步交互的场景,比如处理验证码、拖拽操作、Canvas 交互,这 10 个工具是不够的。spiceman161 选择了覆盖 80% 的常用场景而不是 100% 的全部能力,这是一个务实的取舍。
使用场景
Playwright MCP 最适合的场景是那些”需要 AI 跟网页交互但不需要太复杂操作”的任务。
第一个典型场景是数据采集。你要从某个网站上定期抓取数据,但这个网站没有公开 API。过去你得自己写爬虫脚本,处理登录、翻页、数据解析。现在你可以直接告诉 AI”去这个网页,找到表格里的数据,整理成 CSV”。AI 会自己调用浏览器工具完成整个流程。当然了,如果网站有反爬机制,比如 Cloudflare 的 5 秒盾,Playwright MCP 不一定能过,这一点要心里有数。
第二个场景是自动化测试。你有一个 Web 应用,需要验证某个操作流程是否正常。以前你可能要写 Selenium 或者 Playwright 脚本。现在你可以用自然语言描述测试步骤,让 AI 通过 Playwright MCP 执行并反馈结果。测试报告的质量取决于你给 AI 的指令有多明确。指令模糊,测试就会漏;指令太细,不如直接写脚本。
跟直接用 Playwright 脚本相比,MCP 方案的优势在于灵活性。你不需要提前写好所有交互逻辑,AI 可以在执行过程中根据页面实际情况调整策略。但劣势也很明显:速度慢,每一步都需要 AI 做决策;对复杂交互的处理能力有限,遇到非标准组件容易翻车。所以它更适合探索性操作和一次性任务,而不是需要反复执行的固定流程。
老实说,Playwright MCP 目前还不能替代传统的 Playwright 脚本。它在”让 AI 快速浏览网页”这件事上做得很好,但在”精准控制浏览器行为”这件事上,不如直接写代码。这个定位在短期内不会改变,毕竟 MCP 协议本身在设计上就不是为了提高执行效率,而是为了降低使用门槛。
洞察与反思
Playwright MCP 放在更大的视角下看,它的意义不只在于”让 AI 能浏览网页”这个功能本身。它代表了 MCP 生态的一个重要方向:把已经成熟的开发者工具通过 MCP 协议桥接到 AI 世界。
Playwright 在浏览器自动化领域已经是事实标准,下载量超过千万级别。spiceman161 做的事情不是从零造轮子,而是架了一座桥。这座桥的价值在于,它让成千上万已经熟悉 Playwright 的开发者可以直接把浏览器自动化能力接入 AI 工作流,不需要学一套新的 API 或者自己写 MCP 适配层。这个思路值得更多开源项目参考。
但桥的两边有天然的张力。Playwright 是为”人类写代码控制浏览器”设计的,它的设计哲学是精确、可控、可复现。MCP 的哲学是让 AI 自主决策、灵活应变。把精确控制工具交给一个不确定的 AI 来驱动,意味着你会牺牲一部分可控性来换取灵活性。如果你的任务是批量跑 1000 条测试用例,你不会想用 MCP,因为 AI 每一步都在猜,猜错一次整个流程就断了。但如果你的任务是”帮我看看这个新上线的功能页面有没有明显的布局问题”,MCP 方案比写脚本快得多。

从 ClawHub 上 42,900 次下载这个数据来看,市场对这种”桥梁型” Skill 的需求是真实的。MCP 生态过去一年的关键词是”基础设施”,大家都在搭协议、写适配器、做 SDK。但下一步是什么?我的判断是”组合”。不是单个 MCP 工具有多强,而是多个 MCP 工具能不能在 AI 的调度下协同工作。Playwright MCP 加上一个数据库 MCP 加上一个文件系统 MCP,你就有了一个能自己上网查资料、存数据、写报告的 AI 助手。这个方向目前还有不少坑,多个 MCP 工具之间的上下文传递没有标准方案,AI 在管理和切换多个工具时容易丢失上下文。但如果这些问题能在未来半年到一年内有改善,MCP 工具组合的价值会比单个工具大一个量级。
资源地址
| 资源 | 地址 |
|---|---|
| ClawHub | https://clawhub.ai/spiceman161/playwright-mcp |
| NPM | https://www.npmjs.com/package/@playwright/mcp |
| Playwright 文档 | https://playwright.dev |
| MCP 协议 | https://modelcontextprotocol.io |
总结
回过头来看,Playwright MCP 最让我印象深刻的地方不是它的功能有多丰富,而是它的”克制”。10 个工具,覆盖 80% 的常用场景,不做多余的事。这种克制的设计在开源项目里其实不多见,大部分人拿到 Playwright 的 API 列表第一反应肯定是”全给它包进去”。能忍住不做的,才是真正理解了使用场景的。
如果你日常工作中经常需要跟网页交互,或者你正在搭建 AI 自动化工作流,Playwright MCP 值得一试。它不是银弹,但它确确实实解决了一个具体的问题。装好之后可以先从一个简单的任务开始,比如让 AI 帮你查一次航班信息或者填一个在线问卷,感受一下 AI 操控浏览器的体验。
这个 Skill 目前还比较年轻,v1.0.0 版本还有很多可以打磨的地方。如果你在使用过程中遇到了问题或者有改进想法,不妨去 GitHub 上给 spiceman161 提个 issue。MCP 生态现在还处于早期,每一个有价值的反馈都在帮这个生态变得更好。