
如果你关注过个人 AI Agent 这个赛道,大概率听过两个名字:OpenClaw 和 Hermes Agent。OpenClaw 做的是”让 AI 常驻你的电脑”,Hermes Agent 做的是”让 AI 从经验中学习技能”。它们都在抢”个人 AI 助手”这个坑位。OpenHuman 走的是第三条路:它让你把邮箱、日历、GitHub、Slack、Google Meet 全接进来,然后帮你建一个本地的、可追溯的、Obsidian 兼容的记忆库。
说人话:它不是另一个聊天窗口,它是个会翻你历史记录、知道你跟谁开过会、记得你三周前 Code Review 说了什么的桌面 Agent。
这个定位不是空穴来风。截至 2026 年 6 月,OpenHuman 在 GitHub 上有 31.8k Stars,128 位贡献者,v0.54.0 版本刚在 5 月 19 日发布。主语言是 Rust,许可证 GPL-3.0。看过它的 stars 增长曲线的人都会被吓一跳:5 月初还在 6k 左右的量级,一个月出头冲到三万多。这在个人 Agent 赛道是现象级的。
但我翻完它的架构文档、最近的 Release Note 和社区的几篇深度评测之后,结论比 Stars 曲线复杂。它不是没有真东西,但包装之下藏着几个你要是现在就开始用就一定会碰到的坑。
真正让它跟同类拉开距离的东西
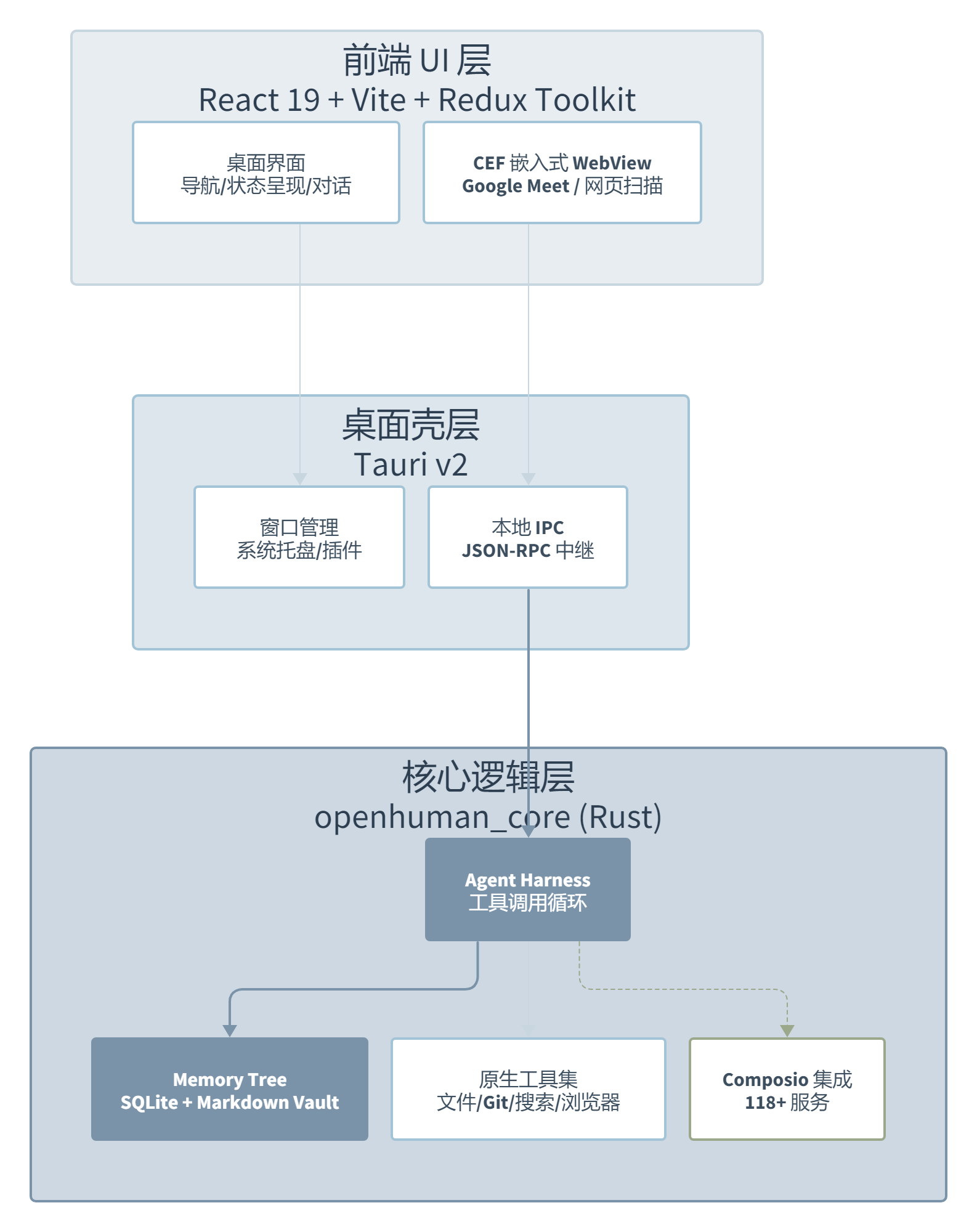
先说最让我在意的设计——Memory Tree。这玩意儿不是那种”把 Chunk 扔进向量数据库然后说我有记忆了”的缝合怪。它的记忆系统有三条并行的树:Source Tree 按数据来源组织(Gmail 的归 Gmail,Slack 的归 Slack),Topic Tree 按主题分类,Global Tree 做全局索引。每条数据都记录 provenance——你能追溯到这条记忆是从哪封邮件、哪次聊天里来的。
更关键的是存储格式。它用 SQLite 存索引和 Chunk,但同时维护一个 Obsidian 兼容的 Markdown Vault 目录。这意味着你可以在 Obsidian 里直接打开、搜索、编辑你的 AI 记忆。这个设计聪明在哪?它没有造一个封闭的记忆黑箱——你的数据是你的,你可以用自己喜欢的工具操作它。这在个人数据主权越来越敏感的当下,是个很有说服力的卖点。
第二个有区分度的是 Composio 集成体系。118 个以上的服务通过四种方式接入:一键 OAuth(托管模式)、Auto-Fetch(20 分钟周期自动拉数据)、Trigger Source(事件触发)和 Agent Tool(Agent 直接调 API)。覆盖面确实广——Gmail、Notion、GitHub、Slack、Linear、Jira、Stripe 都在列。但这里有个很多人没注意到的细节:托管模式 OAuth 走的是 OpenHuman 后端代理,Direct Composio 模式才真正跑在你本地。后者需要你自己搭 Webhook 基础设施。我看了社区反馈,不少刚上手的人以为 118 个集成都是”即插即用”,实际只有托管路径是。
第三个值得关注的是 TokenJuice——一个在工具输出进模型上下文之前做压缩的组件。它有三层规则体系:builtin、user、project,可以对 git diff、npm 日志、邮件 dump 这种高噪声输出做截断、去重、折叠和正则过滤。这个设计直接回应了 AI Agent 领域一个真实痛点:你给 Agent 开了 Google Meet 转录权限,它把一小时会议原封不动塞进上下文,Token 费比你一个月咖啡钱还多。TokenJuice 让你可以给不同工具设定不同的压缩策略。这个设计很务实,比那种”我们用了更好的模型所以 Token 更少”的空话实在多了。
还有一个容易被忽略但影响深远的细节:Hint 前缀模型路由。你在调 Agent 的时候可以在模型参数里加一个 hint——reasoning、fast、vision、summarize、code——系统会根据这个 hint 自动把任务路由到不同的模型。比如写代码走 code 模型,看图片走 vision 模型,做摘要走 summarize 模型。这在多模型混用的场景下能省不少钱,而且不需要你在前端手动切来切去。
安全性方面的设计也值得提一句。OpenHuman 有一个 Prompt Injection Guard,在用户输入进 Agent 之前做规范化、规则匹配和可选的启发式分类,输出 allow、review 或 block。更关键的是它只记录 prompt_hash、长度和判断结果,不存原始 prompt。配合 OS keychain、workspace-scoped 文件系统工具和 sandboxed skills,安全底子比大多数早期的个人 Agent 项目厚实。当然,GPL-3.0 协议意味着商业场景需要谨慎评估。

跑起来看看
安装不算麻烦。macOS 和 Linux 用户一条 curl 管道搞定,Windows 用 PowerShell 一键脚本:
curl -fsSL https://raw.githubusercontent.com/tinyhumansai/openhuman/main/scripts/install.sh | bash
装完之后第一件事是配模型。默认走的是云端模型,但如果你在意隐私或者想省钱,可以切到 Local AI 模式——支持 Ollama 和 LM Studio。不过要注意,Local AI 默认只跑 embedding、摘要树构建和”潜意识”后台任务。聊天、视觉、语音转文字、文字转语音这些核心交互仍然要走云端。你没法完全离线用,至少目前的 v0.54 版本不行。
坑呢?有,而且不少。
- 第一个坑是 OAuth Scope。默认弹出的授权窗口有时要的权限比你以为的多。Issue 区有用户提到它申请了 Gmail 的完整读写权限,而实际上它只需要读取新邮件就行。建议装完之后先去设置里把 Scope 收窄,而不是一路点 “Allow”。
- 第二个坑更隐蔽。它的文档——包括 AGENTS.md、CLAUDE.md 和架构文档——在描述运行时架构时有不一致的地方。旧版文档还在讲 sidecar 和 QuickJS 运行时,但当前的 Cargo.toml 和 AGENTS.md 已经确认核心逻辑嵌入了 Tauri 主机进程。如果你是在看文档学习架构,很可能被带的绕一圈才发现走错了路。v0.54.0 的 Release Note 也印证了这一点:这一版光是 socket、auth、CEF、Linux/Windows 兼容性就修了一大堆。
- 第三个坑是资源消耗。CEF 内嵌浏览器加上 Local AI 再加上 20 分钟周期的 auto-fetch 再加上 embedding workers 再加上语音和 Google Meet agent——这些东西同时跑的时候,你的笔记本风扇不会沉默。在低配机器上跑全套功能基本不现实。建议先从 1-2 个 provider 开始,别一上来就全接。
| 接入方式 | 安装难度 | 平台支持 | 需要额外配置 |
|---|---|---|---|
| 托管模式(默认) | 低 | macOS/Win/Linux | 仅需 OAuth 授权 |
| Direct Composio | 高 | macOS/Win/Linux | 自建 Webhook 基础设施 |
| Local AI(Ollama/LM Studio) | 中 | macOS/Win/Linux | 先装 Ollama 或 LM Studio |
什么人该用,什么人别碰
| 场景 | 典型用户 | 优势 | 局限 |
|---|---|---|---|
| 本地优先 AI 记忆库 | 知识工作者、开发者 | Memory Tree + Obsidian Vault,数据完全在本地 | 初始化需要时间积累数据才有价值 |
| 多数据源聚合 Agent | 重度使用 Gmail/Slack/GitHub/Notion 的人 | 118+ Composio 集成,自动同步 | Direct 模式需自建 Webhook |
| 隐私敏感场景 | 数据主权要求高的用户 | Local AI 可关掉云端 embedding | 核心对话仍走云端,无法完全离线 |
| 语音+会议 Agent | 频繁开 Google Meet 的人 | 实时转写入 Memory Tree | CEF 资源开销大 |
不适用的情况同样明确:
-
你只想找个好用的 AI 聊天客户端,ChatGPT Desktop 或 Claude Desktop 更轻量。OpenHuman 的记忆和集成体系对你来说是过度工程。 -
你预期的是一个成熟的、生产环境可依赖的工具。Early beta 加 v0.54.0 那一长串稳定性修复说明,它还没到那个程度。 -
你的笔记本配置一般,希望装完即用不折腾。CEF + Local AI + 后台任务组合的资源消耗不低,16GB 内存起步会比较舒服。
跟竞品比,这个取舍很清楚。OpenClaw 更适合需要 AI 常驻桌面做操作自动化的用户,它的本地入口整合比 OpenHuman 更成熟。Hermes Agent 更适合想训练 AI 积累领域经验的场景,它的技能沉淀机制是 OpenHuman 没有的。OpenHuman 的核心壁垒只在一个点上:你把越多的个人数据喂给它,它的 Memory Tree 就越接近一个”真正了解你的助手”。这个价值是竞品替代不了的,但前提是你愿意投入那个数据积累的冷启动周期。
社区到底靠不靠谱
| 指标 | 数据 | 说明 |
|---|---|---|
| Stars | 31.8k(2026-06-15) | 5 月至今爆发式增长,多次登 GitHub Trending |
| 核心贡献者 | 128 人 | Bus Factor 中等,但核心维护团队规模不明确 |
| 最新 Release | v0.54.0(2026-05-19) | 修复密度大,socket/auth/CEF/Linux/Win 兼容性问题集中修复 |
| 许可证 | GPL-3.0 | 对商业使用有限制,二次开发需开源 |
Stars 的爆发式增长背后有两股推力:一是确实有真东西,Memory Tree 和 Composio 的差异化够硬;二是硅谷媒体的刷屏效应推了一把。后者不可持续,前者才是判断这个项目值不值得跟的关键。
从社区反馈看,评价两极分化。HackerNews 上有用户评价:”OpenHuman 的记忆系统是目前个人 Agent 里最接近’有用的记忆’的,但它还只是一个记忆系统,不是一个决策系统。”这个判断跟我翻完架构文档后的感受完全一致。知乎上的早期试用者则指出了另一个问题:首次配置如果选错 OAuth Scope,后续撤回授权很麻烦,需要去各服务商的后台手动操作。
v0.54.0 的 Release Note 坦诚度不错。它没有掩饰这一版主要是修 bug 而非加功能——Sentry 噪声过滤、memory chunker 优化、Composio direct mode 修复、多平台稳定性改进。这种”承认问题再修”的态度,在开源项目里比藏着的技术债更让人放心。
扒开闪光灯之后,我的真实判断
我对 OpenHuman 的评价经历了三个阶段。第一阶段是看到 31.8k Stars 和那堆新闻标题时的本能排斥——又一个被热钱和媒体推起来的 AI 项目。第二阶段是翻完架构文档、AGENTS.md 和 Cargo.toml 之后的认知松动——Memory Tree 的设计和 TokenJuice 的务实思路,说明团队不是在做 PPT 产品。第三阶段是看完 v0.54.0 Release Note 和 Issue 区的稳定性讨论之后——确认了它有价值,但也确认了它还不是成品。
这不是”好”或”不好”的问题,是”什么时候值得上车”的问题。如果你现在就开始深度使用,你会成为它的测试者而非受益者。文档漂移、OAuth Scope 过大、资源消耗这些坑,会让你的第一个月体验充满挫败感。
但我对它的长期判断是积极的。在 OpenClaw、Hermes Agent、OpenHuman 这三个目前最受关注的个人 Agent 里,OpenHuman 在记忆系统上的投入最深。OpenClaw 的强项是本地入口整合,Hermes Agent 强在技能经验的自我沉淀,OpenHuman 赌的是”如果你不能记住我的一切,你就不算真正的个人助手”。这个赌注很大,但目前看它赌的方向是对的。
趋势上,v0.54.0 的”修 bug 大于加功能”说明团队正在从快速铺功能转向夯实基础。这个拐点对早期项目来说是个好信号。如果未来 2-3 个版本能把文档一致性、OAuth 权限粒度和资源优化这三件事做好,它的护城河会比现在深得多。
说它好用的和说它垃圾的,其实都没说到点子上。它是一个方向正确、执行粗糙、需要再迭代至少一个大版本才值得普通人深度使用的项目。对开发者和早期采用者来说,现在是个研究它的架构、搭个最小闭环、跟踪它迭代节奏的好时机。对普通用户来说,再等几个月不亏。
资源地址
| 资源 | 地址 |
|---|---|
| GitHub | https://github.com/tinyhumansai/openhuman |
| 官方下载 | https://tinyhumans.ai/openhuman |
| 中文社区文档 | https://openhuman.org.cn/docs/overview/getting-started |
说完了,你的数据你说了算
如果你已经是 Gmail + GitHub + Slack 重度用户,而且对数据隐私有执念,从 1-2 个 provider 开始接入 OpenHuman 是值得的。但别一口气全接——你会在 OAuth Scope 和资源消耗上吃瘪。先从 Gmail 开始,跑通 Memory Tree 的写入到 Obsidian 可查阅这条链路,再逐步扩展。
如果你还在观望,盯两个指标就够了:Release Note 里”breaking change”的出现频率,和 Issue 区里关于文档一致性的反馈数量。前者告诉你它是不是还在剧烈重构,后者告诉你工程师文化是不是真在乎新用户的体验。这两个指标比 Stars 数诚实得多。
一个能翻你邮箱、知道你日历、还在后台默默建索引的 AI,你得先了解它怎么用你的数据,再决定要不要让它进来。