
王云鹤在华为做了很多年模型压缩。把一个臃肿的大模型裁成能在手机上跑的小模型,是他最擅长的事。2026 年初,他从华为出来创业,做的却不是模型压缩。他盯上了一个更隐秘的问题:AI Agent 在运行过程中,到底浪费了多少 Token。
答案比他预想的更夸张。同一个任务,全量使用 Claude Opus 4.7 的 Agent 要花 $6.23,而用他的智能路由方案只要 $0.68。得分几乎持平,成本差了九倍。这不是魔法,是 Harness 层的结构性优化。他给这个项目取名叫 OpenSquilla,Squilla 是拉丁语里”小虾”的意思,主打的就是小而精。
OpenSquilla 不是一个模型,也不是一个 Agent 框架。它是一层夹在 Agent 和大模型之间的运行中枢,Harness。它的核心逻辑很简单:不是每一步都需要最强模型。分类、摘要、格式整理这些简单任务,丢给便宜模型就够了。只有复杂推理才上 Opus。这套逻辑听起来不新鲜,但把它做成一个开源的、本地运行的、能自我进化的完整系统,OpenSquilla 是第一家。
说白了这篇文章就想回答一个问题:当有人告诉你,用了这套 Harness 之后 Token 成本能降 90%,你到底该不该信。
智能路由只是开始
SquillaRouter 是 OpenSquilla 最核心的组件。它本质上是一个跑在本地的 LightGBM 加 ONNX 分类器,对每一次对话轮次做五个维度的评分:长度、语言、代码量、关键词和语义嵌入。评分结果对应 T0 到 T3 四个层级的模型,T0 是最便宜的即时模型,T3 是最强的推理模型。分类过程完全在本地完成,你的 Prompt 不会离开本机去做路由决策。
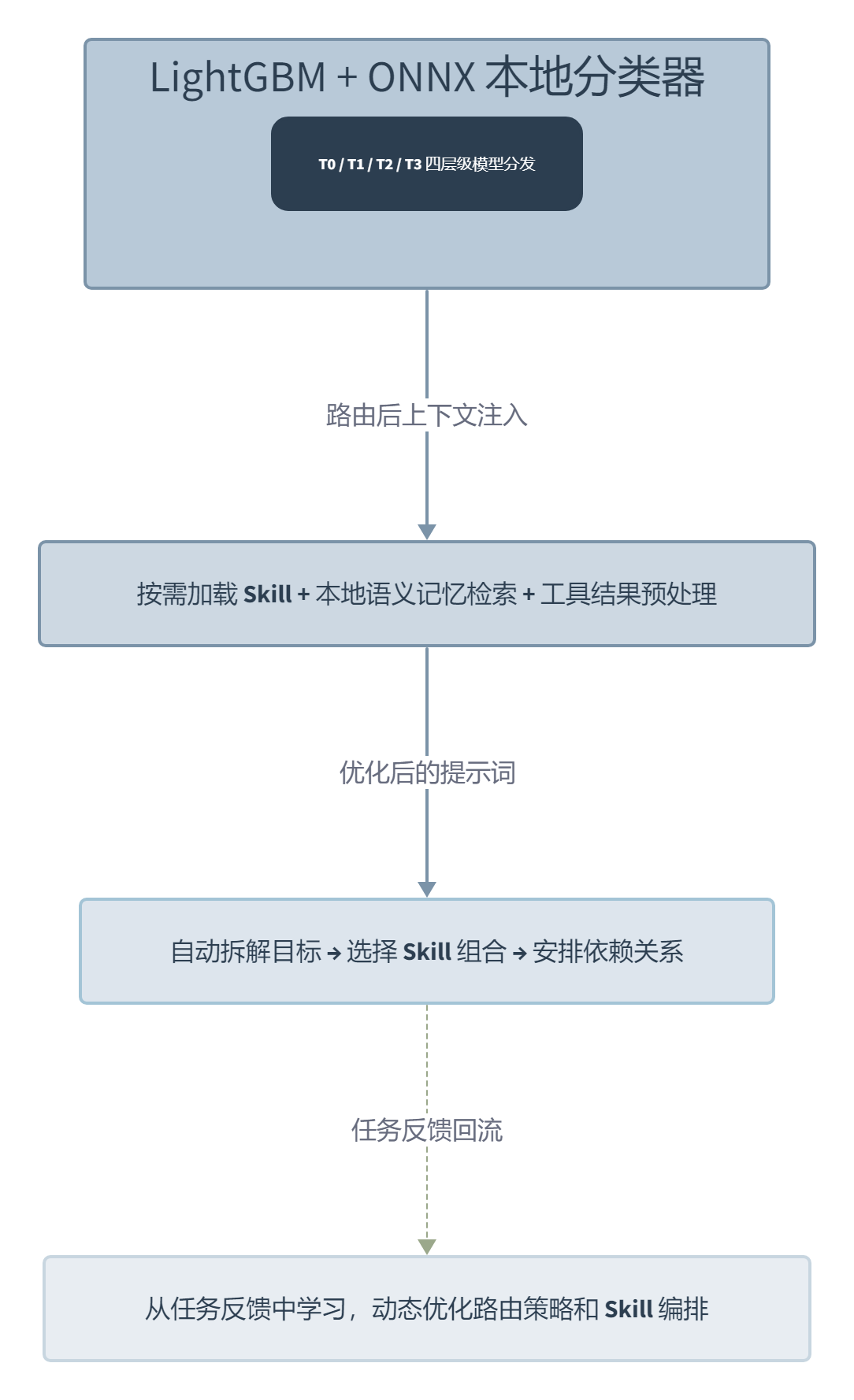
这张架构图展示了 OpenSquilla 的四层设计。SquillaRouter 在最底层做模型调度和分发,上下文管理层在上面做 Token 瘦身,MetaSkill 编排层负责把复杂目标拆成串行或并行的 Skill 组合,最顶层的可进化引擎让整个系统从每一次任务反馈中持续优化路由策略和 Skill 编排。
这个路由器跟 OpenRouter 不是一回事。OpenRouter 是云端 API 网关,面向所有开发者提供通用路由。SquillaRouter 是本地跑的,专门服务于你的 Agent 使用习惯,能根据任务成功失败、Token 消耗和模型性价比这些信号自我调整。
团队给出的数据是:路由精度比 OpenRouter 高 4.4 个百分点,成本低 75%。更重要的是,路由决策不依赖任何外部服务,网络断了照样干活。
上下文管理是第二块拼图。OpenSquilla 的 Skill 系统采用按需加载机制,一次任务只注入可能用到的 Skill 说明,而不是把十几个 Skill 的全套指令全塞进 Context Window。记忆检索走的是本地 SQLite 全文搜索加 sqlite-vec 语义召回,用 ONNX 在本地跑嵌入向量,不依赖云端 API。
工具返回的网页内容也会先裁掉 HTML 标签、导航栏和广告再喂给模型。这三层优化叠加起来,可以额外带来 20% 到 50% 的成本降低。
MetaSkill 解决的是另一个问题。当你的 Skill 越来越多之后,用户不知道怎么选、怎么组合。MetaSkill 把这件事自动化了,你只说要干什么,它自己拆步骤、选 Skill 组合、安排依赖关系。每个步骤加 Skill 组合独享一段上下文,不用把所有指令一次性灌进去。
而可进化引擎做的事更根本:当你反复修改一个任务直到满意,系统会回看整个调整过程,把用户补充的条件、纠正的偏差、最终认可的结果沉淀进 Skill 或工作流。下次遇到类似任务,Agent 不需要从零开始。
跑起来看看
安装路径有三条。最推荐的是通过 uv 从 PyPI 安装 Wheel 包,Windows 用户有便携版 Zip 包内置 CPython 解压即用,追主线开发的可以从源码跑。
uv tool install opensquilla
opensquilla onboard
Onboard 这一步是交互式引导,会带你填 API Key、配置模型路由表、选择需要的 Skill。整个过程大概五分钟,比大多数 Agent 框架的初始化流程友好。如果你用的不是 OpenRouter 的标准模型,需要手动指定 T0 到 T3 层级,这一步是新手最容易卡住的地方。
几个常见的坑。Windows 上 SquillaRouter 的 ONNX 运行时依赖 Visual C++ Redistributable 2015 到 2022 x64 版本,没装的话路由功能会静默回退到单模型模式,不会报错但成本优势全部消失。另一个坑是 API Key 配置,OpenSquilla 支持 20 多家 LLM 提供商,但 Onboard 流程默认只引导 OpenRouter 和 Anthropic,其他的需要事后手动编辑配置文件。
启动之后,所有操作都走统一的网关服务,监听在 127.0.0.1:18791。Web UI 地址是 /control/,内置嵌入式控制台。CLI、Web UI、Slack、Telegram、飞书、钉钉、企业微信这些通道共享同一套 turn loop,工具调度、重试、决策日志保持一致。这个设计意味着你可以在电脑上用 Web UI 交互,在手机上通过 Telegram 发指令,Agent 的上下文是连续不断的。
跑起来之后的印象是:信息密度确实高。不像有些 Agent 框架把所有 Skill 指令一次灌进 Context,OpenSquilla 的 Context 窗口里大部分是真正有用的任务信息。这跟团队在模型压缩领域的积累是一致的,他们知道什么东西可以裁掉,也知道裁掉之后不能影响效果。
什么时候用,什么时候别用
| 场景 | 典型用户 | 优势 | 局限 |
|---|---|---|---|
| 日均百次 Agent 调用 | 重度 AI 用户、开发者 | Token 成本降低 80% 到 90% | 初期配置耗时,冷启动需要学习使用模式 |
| 多模型混合使用 | 有多个 API Key 的用户 | 自动选择最优性价比模型 | T0 到 T3 分级需要手动调整,默认分级可能不符合场景 |
| 需要持久记忆的 Agent | 个人助理、知识工作者 | 本地记忆库加语义搜索 | 记忆检索质量依赖嵌入模型,小语种可能召回不准 |
| 多通道接入 | 团队协作、多渠道运营 | 统一会话状态 | 每个通道需单独配置,企业微信和飞书的配置文档不全 |
不适用的情况也很明确。如果你只是偶尔用用 Claude Code 或 ChatGPT,一天不超过十次调用,OpenSquilla 的 Harness 层带来的额外复杂度不值得,直接用原生客户端更省心。如果你的任务几乎全部是复杂推理,每个请求都需要 Opus 级别的模型,那路由器的价值也不大,T0 到 T2 的模型根本用不上。
还有一个容易被忽略的限制:OpenSquilla 目前主要是 Python 生态的,Windows 上部分 Skill 有已知兼容问题。基于 Bubblewrap 的安全沙箱只支持 Linux,Windows 和 macOS 用户只能用较弱的安全层级。如果你对安全隔离有硬性要求,这一点需要心里有数。
社区怎么样了
| 指标 | 数据 | 说明 |
|---|---|---|
| Stars | 4,200+(截至 2026.06) | 5 月发布后快速增长,目前日均新增约 50 Stars |
| 核心维护者 | 约 10 人 | 基元律动科技团队主导,Bus Factor 偏低 |
| Open Issues | 61 | 以功能请求和 Skill 兼容性问题为主,严重 Bug 不多 |
| 协议 | Apache-2.0 | 商用友好,无 copyleft 限制 |
| 最新 Release | v0.3.1(2026.06.03) | 维护版本,修复了 Slack Socket Mode 和频道格式问题 |
| 融资估值 | 1 亿美元 | 成立数月即完成首轮,资本市场对 Harness 赛道认可 |
活跃度不错,但要看你怎么定义”活跃”。105 次 commit、10 个贡献者、6 个 Release,对于一个成立几个月的项目来说是健康的节奏。61 个 Open Issue 偏高,不过以功能请求和 Skill 兼容问题为主,严重的 Bug 报告不多。
有一点值得注意:社区贡献目前高度集中在创始团队。38 个 Open PR 中大部分来自内部开发者,外部贡献者的深度参与还不多。对于一个 Apache-2.0 协议的项目来说不算致命,但如果核心团队因为融资压力转向商业化,社区的独立维护能力存疑。
社区声音方面,项目在中文技术圈讨论较多。硅星人 Pro、知乎和今日头条都有深度分析文章,普遍对 Harness 这个定位给予了认可。英文社区目前集中在 X 和 Twitter 的技术 KOL 圈层,Reddit 和 HackerNews 上暂时没有出现代表性讨论串。创始团队的履历在技术圈引发了关注,但长期社区口碑还需要更多第三方评测来验证。
我的真实看法
翻完 Repo、Benchmark 数据和社区讨论,我的判断是:这不是又一个靠概念融资的 AI 项目。Harness 层的问题确实存在,现在的 AI Agent 就是在烧 Token,团队选择了一条对的路,并且用开源的方式去验证。
但有几个点让我保持谨慎。基准测试来自 PinchBench 1.2.1,25 个任务的平均值,样本量偏小。团队自报的 9 倍成本差异在真实场景中可能会打折扣,当你用的 T0 模型变弱时,可能出现”先试便宜的、发现不行、再试贵的”这种重复调用,抵消部分成本优势。这个问题团队自己也在 Issue 区承认了,正在优化路由的重试策略。
另一个有趣的角度:OpenSquilla 把 Harness 定位为 Agent 和模型之间的独立层,这意味着如果你的 Agent 框架本身也在做上下文管理和工具调度,两头就会打架。目前 OpenSquilla 和 OpenClaw 的 Harness 层面互不兼容,这是 Harness 赛道走向标准化之前绕不开的摩擦。
这引出一个更尖锐的问题:OpenSquilla 到底是一次性的省钱工具,还是一个能越用越聪明的长期基础设施?从架构设计来看,可进化引擎和 MetaSkill 的编排能力确实指向了后者。它不只关心”这一轮省了多少 Token”,更关心”下一轮能不能更精准地判断该用哪个模型”。但前提是你得持续用它,冷启动阶段的路由判断远不如跑了一两周之后精准。
趋势判断上,我对这个项目的中期持乐观态度。Harness 层的需求是真实的,Token 成本是每个重度 AI 用户都会碰到的天花板。OpenSquilla 选的路径,本地路由、开源、Apache-2.0,在技术主权和商业化之间找到了一个体面的平衡。但六个月到一年之内,大模型厂商自己会不会把推理成本降到不需要 Harness 的程度,是整个赛道最大的不确定性。
资源地址
| 资源 | 地址 |
|---|---|
| GitHub | https://github.com/opensquilla/opensquilla |
| 官网 | https://opensquilla.ai |
| 中文文档 | https://opensquilla.ai/zh |
该怎么选
如果你每天的 AI Agent 调用在几十次以上,并且用的是 OpenRouter 或直连 Anthropic,OpenSquilla 的路由方案值得花一个下午部署试试。从 onboard 流程开始,先跑一周看路由日志里的 T0 到 T3 分布,算一下实际的 Token 节省率,再决定要不要全量切过去。
如果你还在观望,关注两个指标:大模型厂商的降价节奏和 OpenSquilla 的外部贡献者增长。前者决定了 Harness 层的存在价值,后者决定了这个项目能不能从一家公司的产品变成一个真正的开源社区项目。
Harness 这个赛道才刚刚开始。OpenSquilla 不是第一个,也绝不会是最后一个。但它是第一个把”减少 Token 浪费”当作核心产品主张、并且用开源的方式推到台前的。冲着这点,就值得尊重。