
写 AI Agent 的人都有一个共同的焦虑:Token 烧得太快了。Agent 调一次工具返回几千字的 JSON,读一个文件灌进去几百行代码,RAG 检索拉回来一堆半相关的文档片段。这些内容里 70% 到 95% 是 LLM 根本不需要的噪音。但 Agent 不管,照单全塞进 prompt。
更反直觉的是:把这些冗余信息砍掉 70% 到 95%,LLM 给出的答案几乎没变。不是”差不多”,是”一模一样”。官方演示里有个 case,10144 个 token 压到 1260 个,LLM 在两边都准确找到了同样的 FATAL 错误。
Headroom 干的就是这件事。它在 Agent 和 LLM 之间插入了一个上下文压缩层,对工具输出、日志、RAG chunks、文件内容和对话历史做类型感知的智能压缩。Apache 2.0 协议,本地运行,数据不出你的机器。今年 6 月上线以来,它冲到了 29.1k Stars,v0.25.0 刚在 6 月 12 号发布,155 个 Release 的背后是 1598 次 commit。
这篇文章要回答一个实际问题:在 Agent 流水线里多插一层压缩,值不值。不聊”支持什么格式”那种废话,聊它的设计决策、隐性成本和真实的局限性。
但省 token 这件事说了一万遍了,凭什么这次不一样?压得好和压得烂的区别到底在哪。
亮点不是”能压缩”,是”知道怎么压”
压缩这件事的难处不在算法,在判断。不是所有内容都该用同一种方式压缩。如果你一刀切全丢给 LLM 做摘要,那等于用最贵的方式干最简单的活。Headroom 的方案是 ContentRouter——一个内容类型分发器。JSON 走 SmartCrusher,源代码走 CodeCompressor,自然语言走 Kompress-base 模型。每条路由背后的压缩逻辑完全不同。
SmartCrusher 对 JSON 的处理方式很高效:字段名哈希化、冗余键裁剪、数组采样、保留 schema 骨架。一个典型工具调用返回的几百行 JSON,压缩后只剩十几行骨架,结构信息完整保留。代码搜索场景实测:100 条结果,17765 个 token 压到 1408 个,砍掉 92%。SRE 事故调试场景更夸张:65694 个 token 压到 5118 个,也是 92%。
CodeCompressor 用 tree-sitter 做 AST 级压缩。但它有一个关键设计:默认几乎不压缩代码。原因是多重保护机制。少于 50 个单词跳过,最近 4 条消息中的代码不碰,用户消息里有 analyze、fix、debug 等关键词时全部代码都不压缩。这不是缺陷。你让 Agent 读代码通常是为了修改它,压缩函数体会删除你真正需要的内容。Claude 这类 LLM 不压缩反而能更精确地导航大型代码文件。
Kompress-base 是自研的 8B 参数模型,专做保意压缩。但官方直接说了:它只适合成本优化,不适合提速。模型推理本身有延迟,首次调用还有加载延迟。如果你追求极致速度,用 SmartCrusher 和 CodeCompressor 就够了,别开 ML 模式。另外,ML 推理是全局单实例加锁的,高并发场景下会成为瓶颈。
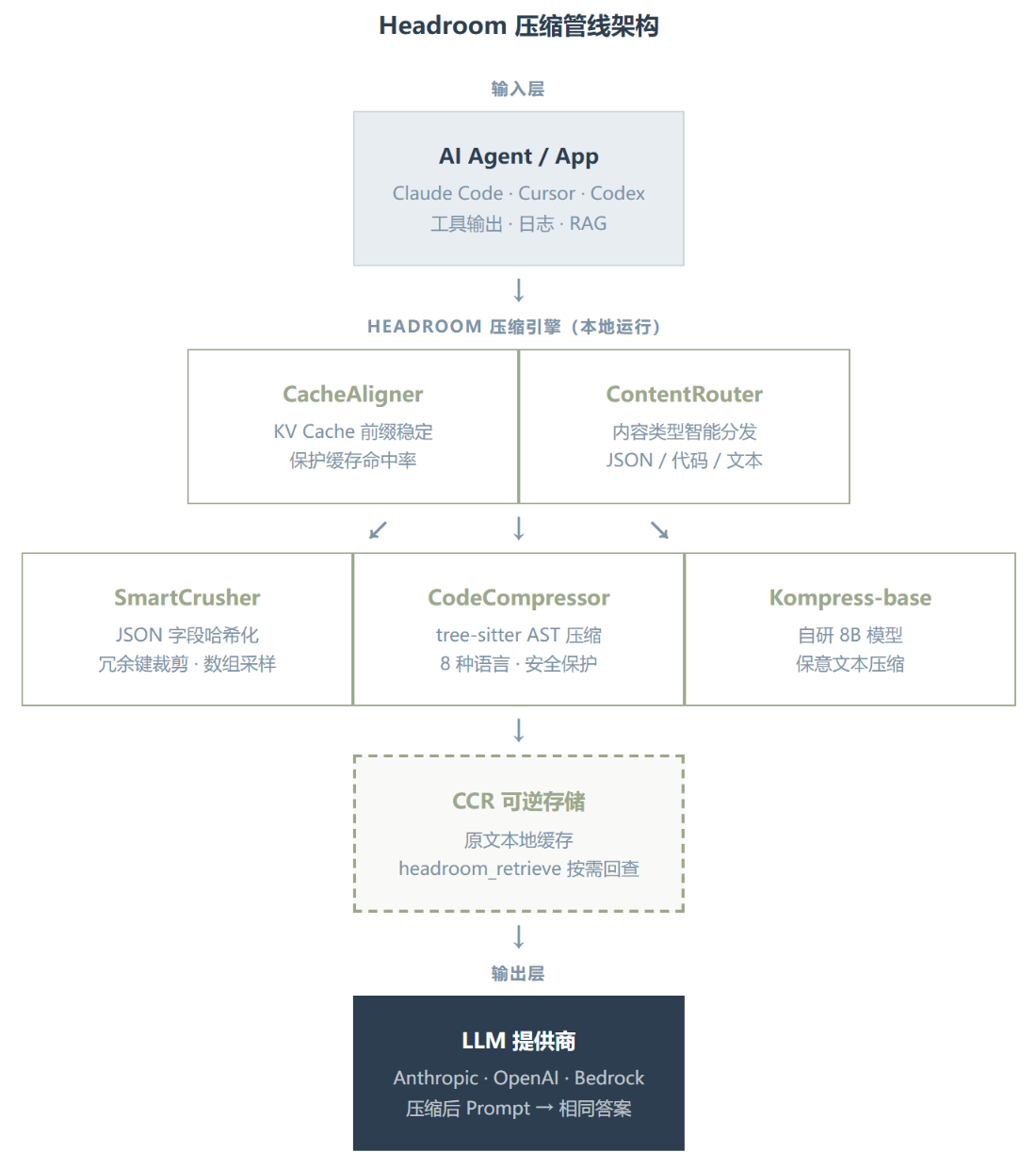
这张架构图展示了完整的压缩管线。Agent 发出的内容先进入 ContentRouter 做类型判断,JSON 路由到 SmartCrusher、代码路由到 CodeCompressor、自然语言路由到 Kompress-base。压缩后的内容经过 CacheAligner 稳定 KV cache 前缀后输出给 LLM,同时原文存入 CCR 本地缓存,LLM 可以通过 headroom_retrieve 工具按需回查。
一个让我最意外的东西是 CacheAligner。这东西解决了一个几乎没人提的隐性成本:KV cache 命中率。Anthropic 和 OpenAI 对 prompt 前缀做 KV cache,相同前缀复用算好的 attention key/value,账单差距可达 10 倍。但任何对 prompt 前缀的修改都会让 cache 失效。CacheAligner 的做法很聪明:稳定系统消息部分,只压缩真正变化的内容。这样一来,即使你压缩了 90% 的 token,真实账单可以降到原来的 1/20。说它是 Headroom 最被低估的部分,不过分。
CCR(可逆压缩)是另一个解决核心信任问题的设计。压缩后的内容不是一次性消费。原文存本地,LLM 如果觉得信息不够,通过 headroom_retrieve 工具按需取回原始内容。这解决了上下文压缩最大的风险,就是”万一 LLM 需要被压掉的信息怎么办”。不是盲目压缩,是压缩加检索。
三种接入形态覆盖了几乎所有场景。Library 模式一行 compress(messages) 嵌入代码。Proxy 模式改个环境变量让 SDK 走代理,零代码改动。headroom wrap claude 一条命令接管 Agent CLI。MCP 模式在 mcp.json 里加一行 server 配置就能用。另外还有两个延伸功能值得提:跨 Agent 共享记忆让 Claude Code、Cursor、Codex 的关键决策去重后共享,换 Agent 不丢上下文;headroom learn 扫描失败 session 后自动把”哪条命令错了、为什么错”写入 CLAUDE.md 或 AGENTS.md。
上手不复杂,但有几件事必须知道
装它有多简单?Python 3.10+ 环境一行 pip 搞定,Node 和 Docker 也有对应镜像。三条最常用的入口命令覆盖了从零代码改动到精确控制的全部需求。
pip install "headroom-ai[all]"
包装 Claude Code 只需要一条命令,自动接管 shell 调用链,敲完就能看到压缩效果。
headroom wrap claude
如果你不想改任何 Agent 的代码,启动代理模式让所有请求走 8787 端口。
headroom proxy --port 8787
跑起来之后,headroom perf 能直接告诉你省了多少 token。这是衡量效果的起点,不是终点。
但有三个坑必须提前说清楚。
- 第一,纯文本文档(文章、文档)的压缩率只有 43% 到 46%,而且会增加延迟。如果你主要在用 Agent 读文章、做摘要,Headroom 只能帮你省钱,不能帮你提速。
- 第二,ML 文本压缩需要额外下载模型权重,需要 GPU 或足够的 CPU RAM。首次调用有模型加载延迟,高并发场景下全局锁会成为瓶颈。
- 第三,CodeCompressor 的安全保护机制保守到你感受不到它的存在——大部分场景下代码根本不会被压缩。如果你期望它压代码文件,会失望。
还有一个容易被忽视的问题:所有压缩器失败时默认静默直通,不报错。如果压缩没生效,只能去日志里找 WARNING 级别的记录。这个设计保证了稳定性,但也意味着你可能在不知情的情况下花冤枉 token。
什么时候用,什么时候别用
不是所有 Agent 场景都适合塞一层压缩。这件事得分场景看,盲目装可能得不偿失。
| 场景 | 适合度 | 关键原因 |
|---|---|---|
| 日常 AI 编码 Agent | ⭐⭐⭐⭐⭐ | 工具输出是最大 token 消耗源,压缩率 70-92% |
| 多 Agent 协作工作流 | ⭐⭐⭐⭐ | 跨 Agent 共享记忆的价值超过压缩本身 |
| 长会话 Agent 任务 | ⭐⭐⭐⭐ | CCR 可逆存储让你不担心丢信息 |
| 纯文本处理 | ⭐⭐ | 压缩率低(43-46%),增加延迟,只省钱不提速 |
| 沙箱/受限环境 | ⭐ | 需要本地进程运行,部分企业环境不可用 |
| 单供应商、不需要跨 Agent 记忆 | ⭐ | 原生 compaction 够用,没必要多插一层 |
不适合的情况其实也很直接。如果你只用一家供应商的原生 compaction 且不需要跨 Agent 记忆,没必要多插一层。如果你在沙箱环境里跑不了本地进程,Headroom 用不了。但如果你每天在多个 Agent 之间切换,工具调用密集,那 Cross-agent Memory 和 headroom learn 会慢慢变成工作流的一部分,不只是省 token 的工具。
社区在爆发,但泡沫和真金并存
29.1k Stars,2k Forks,155 个 Release,1598 次 commit。这些数字背后的速度是惊人的,项目从零到 29k Stars 用了不到一个月时间。但数字膨胀得越快,越需要冷静看看背后的结构。
| 指标 | 数据 | 说明 |
|---|---|---|
| Stars | 29.1k(截至 2026.06.16) | 不到一个月从零到近 3 万,爆发式增长 |
| 核心维护者 | 1 人(chopratejas) | Bus Factor = 1,可持续性风险高 |
| Release 频率 | 155 个,最新 v0.25.0(06.12) | 高频迭代,但版本号跳得快不代表稳定 |
| 开源协议 | Apache 2.0 | 商业友好,无 copyleft 顾虑 |
最大的风险写在表里:Bus Factor = 1。整个项目只有 chopratejas 一个人。1598 次 commit、155 个 Release 的节奏不可持续。如果维护者被收购、疲劳或者兴趣转移,项目未来就是一串问号。这个问题不是在吓唬人,是所有单维护者高星项目的共同宿命。
社区反馈两极分化很明显。Reddit 和 HackerNews 上的讨论有两个极端:一边说”这是今年最有价值的 Agent 工具”,另一边说”这不过是在 LLM 前面加了个 text filter”。中文社区(掘金、CSDN、知乎)的深度分析文章普遍正面,但几乎都提到同一个担忧:单维护者的长期风险。从 Issue 区看,175 个 open Issue 有不少是关于 Codex 集成延迟和特定工具输出格式兼容性的。一个人处理 175 个 Issue 加 90 个 PR,不轻松。
数据摊完了,说点真正要紧的。
我对它的真实判断
翻完 Issue 列表、文档和社区讨论,我对 Headroom 的判断比一开始复杂很多。它不是”好”或”不好”能概括的。
它在工程判断上的清醒程度让我印象深刻。做 ContentRouter 而不是一刀切用 LLM 总结。做 CacheAligner 而不是只管压缩不管缓存。做 CCR 而不是不可逆截断。这些决策说明作者不是在追热点,是真的理解了 Agent 上下文的成本结构。Token 压缩是显性收益,KV cache 保护是隐性收益,CCR 解决了”压缩了万一需要原文怎么办”的信任问题。三个问题分别对应省钱、快速、安全,任何一个做不好都会让压缩层成为新瓶颈。
但它的问题同样不能回避。单维护者是定时炸弹,155 个 Release 的节奏不可持续。一旦维护放缓,社区热情会快速冷却。175 个 open Issue 的积压已经开始显现。纯文本和代码场景的压缩效果远低于宣传的”60-95%”,实际体验中纯文本场景只有 40% 左右,代码场景几乎不压缩。
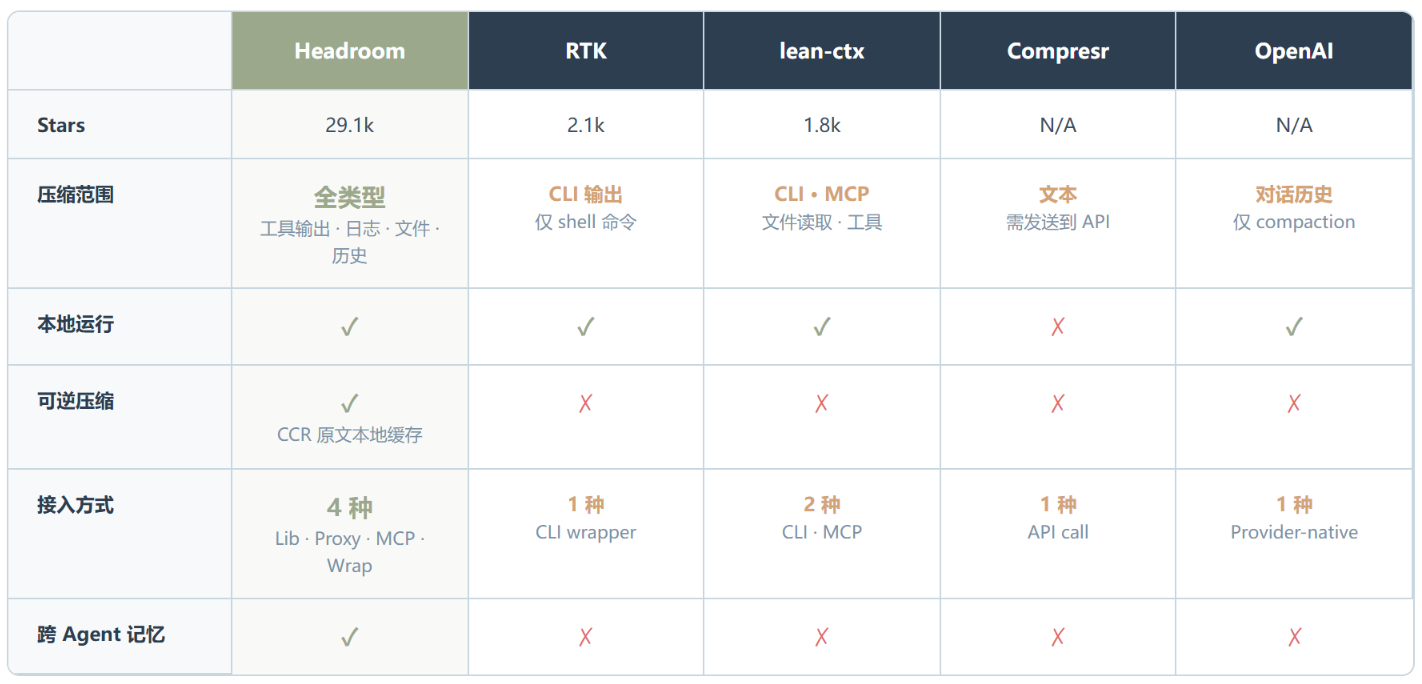
这张对比图展示了 Headroom 与 RTK、lean-ctx、Compresr、Token Co. 和 OpenAI Compaction 在压缩范围、部署方式、本地运行、可逆性四个维度的差异。Headroom 是唯一覆盖全部上下文类型、本地运行且支持可逆压缩的方案。RTK 只处理 CLI 输出,lean-ctx 范围更窄,Compresr 和 Token Co. 需要把数据发到它们的 API——这对企业用户来说是致命缺陷。
更有意思的一个观察:Headroom 最成功的不是算法,是接入方式。Library、Proxy、MCP、Agent Wrap 四种形态覆盖了从手写代码到零代码改动的全部场景。这一层易用性外壳可能是它跑赢同类的核心原因。
如果你要问值不值得跟:技术上值得,生产环境上需要等。等它解决单维护者风险,或者等到有足够的社区 contributor 开始分担 PR review 和 Issue triage。关注两个关键信号:是否有第二个核心维护者加入,Release 频率能否稳定在每周 1-2 次的可持续节奏。
聊完了判断,该上干货了。
资源地址
| 资源 | 地址 |
|---|---|
| GitHub | https://github.com/chopratejas/headroom |
| 官方文档 | https://headroom-docs.vercel.app/docs |
| PyPI | https://pypi.org/project/headroom-ai/ |
| npm | https://www.npmjs.com/package/headroom-ai |
该做的事
如果你每天在用 Claude Code、Cursor 或 Codex 写代码,现在就装。工具输出是最大的 token 消耗源,70% 到 92% 的压缩率是在帮你省钱。从 headroom wrap claude 开始,零风险、零代码改动,不满意关掉就行。
如果你在做 Agent 框架或多 Agent 协作系统,Headroom 的 Library 模式和 Cross-agent Memory 值得作为基础设施层评估。但不要把它当成即插即用的黑盒,你需要找到压缩的最佳插入点,这个位置在不同架构里不一样。
如果你在观望,盯紧两个信号。第一个是社区 contributor 的数量和质量,这是 Bus Factor 从 1 变成 N 的标志。第二个是纯文本和代码场景的压缩率是否有突破,目前这两块的体验远不如 JSON 场景。这两个信号到位了,Headroom 才可能从”个人项目里最亮的星”变成”生产环境里靠谱的依赖”。
最有意思的一点不是技术。是这件事提示了一个正在发生的范式转移:Agent 时代,token 成本和 context 质量是两个独立的优化目标,需要分层解决。在 LLM 前面加一层不是增加复杂度,是承认单纯靠模型本身解决不了 context 效率问题。