

你刚把一段 Python 爬虫丢进服务器,第二天目标网站改版了。所有 CSS 选择器全挂,日志里一片
AttributeError。你修好选择器重新部署,第三周 Cloudflare 升级了反爬策略,你的requests直接返回 403。
写过三年以上爬虫的人都懂这种循环。不是你的代码写得差,是 Web 本身就是一个不断移动的靶子。每次网站改版,你要么重新分析 DOM,要么加一层更复杂的反检测逻辑。维护爬虫的时间远超写爬虫的时间。
Scrapling 就是被这种痛逼出来的。作者 Karim Shoair(GitHub ID: D4Vinci)在 2024 年 10 月开源了这个项目,到 2026 年 6 月已经拿下 64,861 Stars、6,375 Fork,最新版本 v0.4.9 在一周前刚发布,测试覆盖率稳定在 92%。
但真正让我认真看这个项目的,不是 Star 数。是它用一套设计回答了爬虫领域三个最麻烦的问题:网站改版了怎么办、反爬升级了怎么办、从小脚本扩展到全站爬取怎么平滑过渡。一个库,三件事,没有引入三套依赖。往下看。
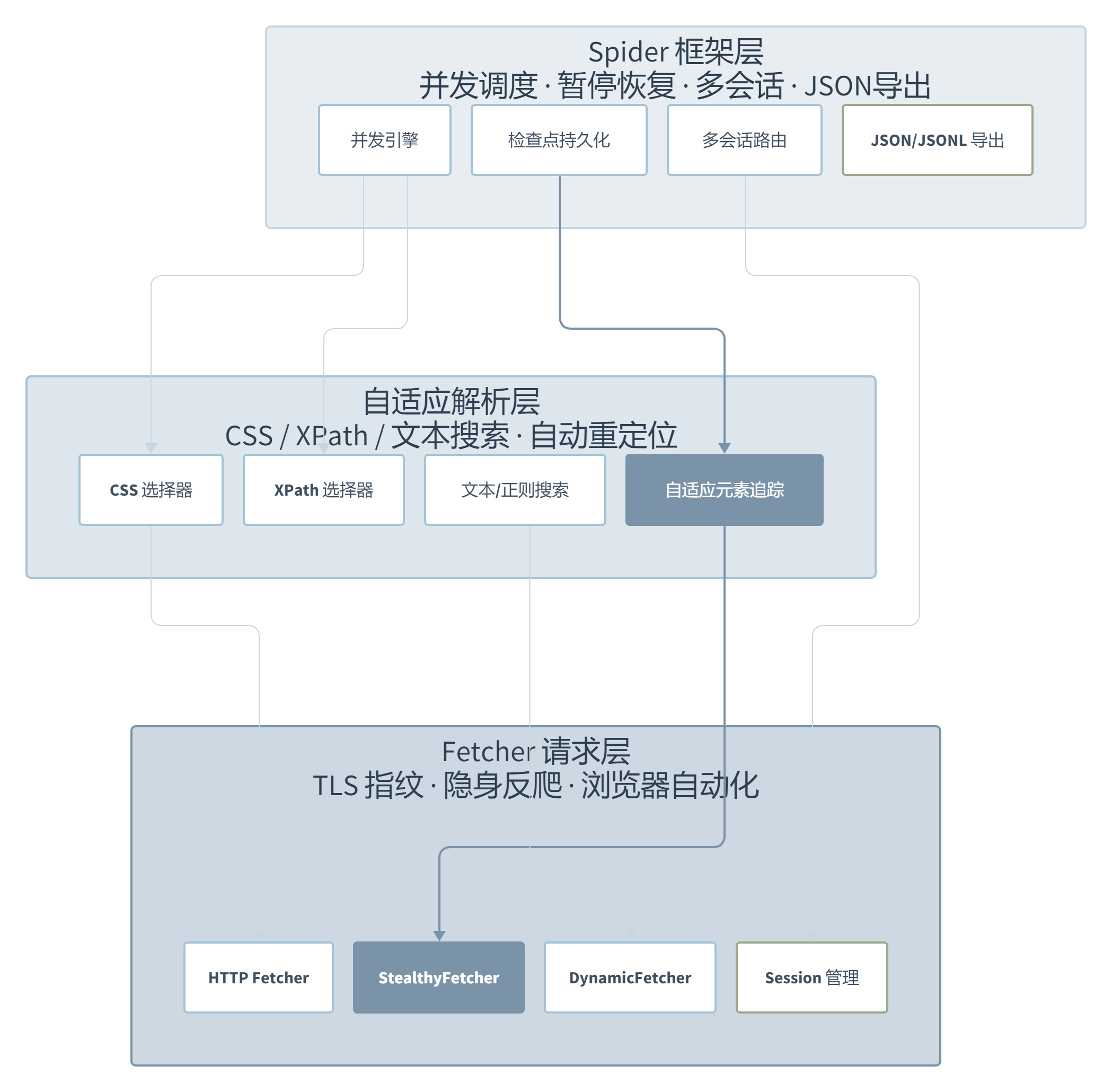
Scrapling 的分层设计很干净,这和它”一个库解决全链路”的定位一致。最底层负责请求隐身(TLS 指纹模拟、HTTP/3 支持、Cloudflare Turnstile 自动绕过),中间层是你包在手里但未必意识到的杀手锏——自适应解析器,最上层是带并发、多会话、暂停恢复能力的完整 Spider 框架。
三层各自独立又互不阻塞:你可以在 Spider 最外层用 StealthySession 做隐身请求,中间靠自适应解析器抗网站变化,抓到数据直接 JSON/JSONL 导出。这套分层没有像 Scrapy 那样需要你额外装 middleware 才能串联,也没有 Playwright+Selenium 那种”我只负责浏览器,解析你自己搞定”的半成品感。
真正打动我的几个地方
性能数据是让我开始正视这个项目的第一件事。在 README 公开的 benchmark 里,Scrapling 的文本提取只用 2.02ms,跟 Parsel/Scrapy 的 2.04ms 基本持平,但比 BeautifulSoup 快 784 倍,比 MechanicalSoup 快 767 倍。元素相似性搜索上,它比 AutoScraper 快 5 倍。这些数字确实漂亮,不过 benchmark 永远是理想条件下的数值。我更在意的是一件事:它的解析器引擎是整个库里依赖最少的模块,你甚至可以单独 from scrapling.parser import Selector 当轻量 HTML 解析器用,完全没有拖家带口的依赖焦虑。
自适应解析才是真正的区分点。大多数爬虫框架的解法是”网站改了你自己改选择器”,Scrapling 的思路刚好反过来:解析器学习你的目标元素的特征(位置、文本、属性、周围结构),网站改版后自动用相似性算法重新定位元素。这不算魔法,它的实现基于元素指纹的多维相似度计算。但够用——当目标页面的 DOM 结构微调(比如套了层新 div、class 名换了命名规则),你的爬虫不会直接崩,而是”自己找回来”。当然有个诚实的前提:如果网站彻底重构了布局,自适应也救不了。
第三个让我愿意认真对待这个项目的原因是它的反爬方案设计。StealthyFetcher 能自动绕过 Cloudflare Turnstile,这不是通过注入第三方绕检测脚本实现的,而是从 TLS 指纹(curl_cffi 的 impersonate 能力)、请求头伪装、浏览器行为模拟三个层面组合出的隐身栈。DynamicFetcher 则直接接 Playwright 的 Chromium 做完整浏览器自动化,覆盖那些必须执行 JS 才能渲染内容的场景。关键是这两个 Fetcher 共用同一套 Session 管理接口,互切几乎无感。
第四个亮点容易被忽略但很实用:暂停恢复和开发模式。大型爬取任务跑到一半崩了是家常便饭。Scrapling 的 Spider 支持基于检查点的持久化,你按 Ctrl+C 优雅退出,重新启动后从断点继续,不会重复爬已完成的页面。开发模式下,首次运行把 HTTP 响应缓存到本地磁盘,后续调试 parse() 逻辑时直接回放缓存,不用反复打目标服务器。这对反爬敏感的站点尤其友好:你不会因为调试代码而触发风控。
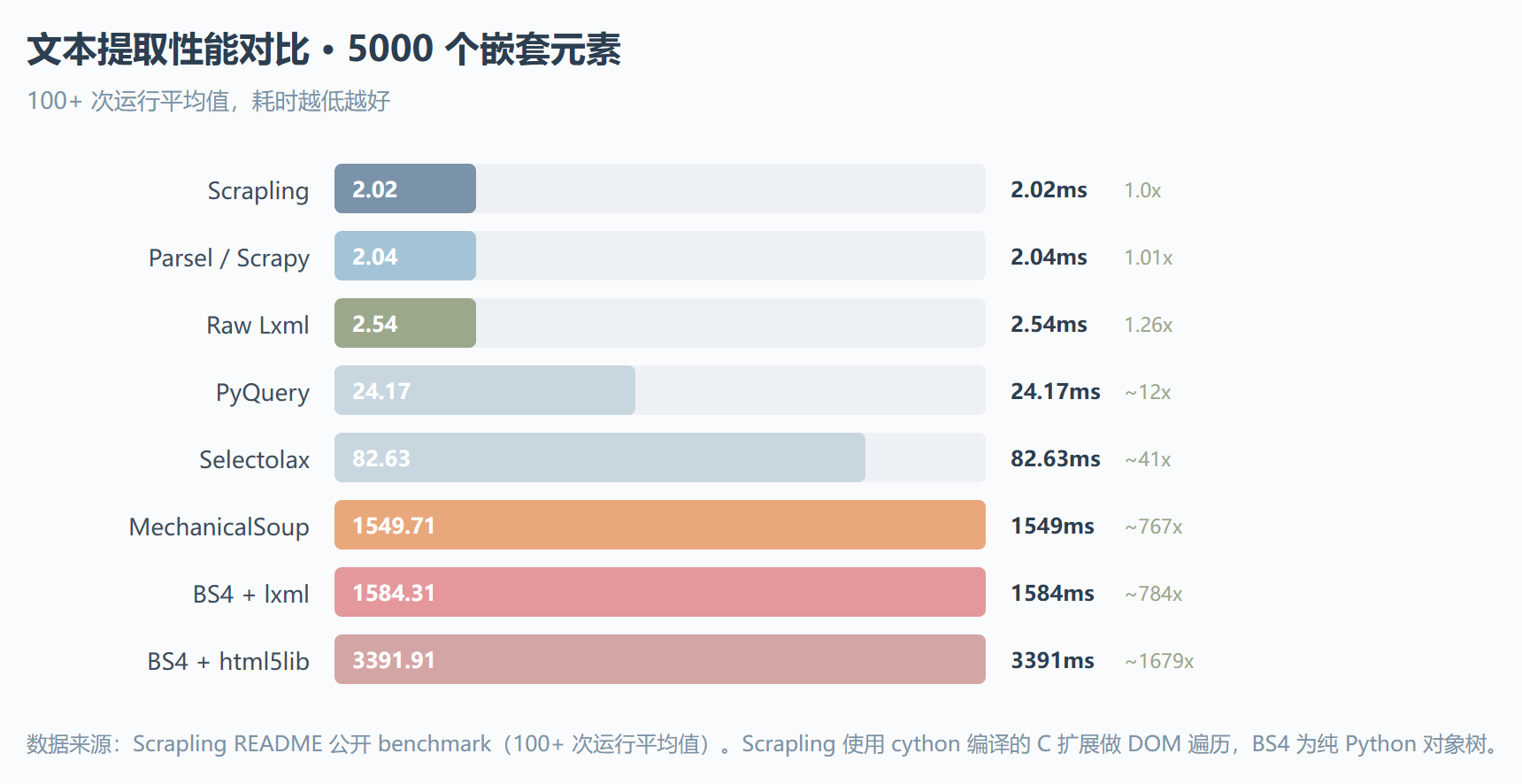
这张对比拉的是 README 公开的基准测试数据——5000 个嵌套元素下的文本提取用时。Scrapling 和 Scrapy/Parsel 在 2ms 档位缠斗,而 BS4+lxml 要 1584ms。差距不在算法复杂度上,在底层实现:Scrapling 用 cython 编译后的 C 扩展做 DOM 遍历,BS4 是纯 Python 的对象树。
跑起来看看
安装不算无脑,但路径清晰。基础解析器只需要 pip install scrapling。如果你要反爬和隐身能力,得加 pip install "scrapling[fetchers]",然后跑 scrapling install 补齐 Playwright 浏览器依赖。MCP 服务器和交互式 Shell 分别对应 [ai] 和 [shell] extras。这种分层安装策略是对的——不是所有人上来就需要完整浏览器自动化。
常见坑点有几个。第一是 Docker 路径,官方镜像 pyd4vinci/scrapling 每次 release 都会自动构建,但镜像体积不小(内含 Chromium),网络不好的时候拉取可能超时。第二个坑在 Issue 区能找到:部分用户反馈 StealthyFetcher 在隐身模式下触发了不必要的广告/追踪请求,会额外消耗代理配额。项目已经加了内置广告拦截(约 3500 个域名),但开启方式藏在文档较深处。
最基本的用法很直接。拿 FetcherSession 发一个带 Chrome 指纹的请求,拿到 page 对象后就能用 .css() 或 .xpath() 提取数据。选择器支持链式调用,page.css('.quote').css('.text::text').getall() 这种写法跟 Scrapy 的风格一致,迁移成本低。
如果只用解析器不需要发请求,单独导入 Selector 就行。这对于那种”我只要解析已经拿到的 HTML 字符串”的场景非常友好——不用引入整个框架。
pip install scrapling
# 反爬 + 隐身能力
pip install "scrapling[fetchers]"
scrapling install
# AI/MCP 支持
pip install "scrapling[ai]"
# 全部功能
pip install "scrapling[all]"
什么时候用,什么时候别用
| 场景 | 典型用户 | 优势 | 局限 |
|---|---|---|---|
| 需要反检测的中型爬取 | 数据工程师 | Cloudflare 绕过 + 自适应解析 | 极致高并发不如 Scrapy |
| 网站频繁改版的数据采集 | 爬虫维护者 | 自动重新定位元素 | 彻底重构的布局仍会失效 |
| AI Agent 辅助抓取 | AI 开发者 | 内置 MCP Server | 生态和社区插件不如 Scrapy |
| 临时数据提取 | 分析师 | 命令行 extract get 一条搞定 |
复杂登录流程需写代码 |
| 大规模全站爬取(>10万页) | 爬虫团队 | 暂停恢复 + 多会话 | 分布式需要自己搭 |
不适合的场景也值得说清楚。如果你的爬虫是稳态运行的——目标网站结构完全固定,反爬策略不升级,那 Scrapling 的自适应和反检测层对你来说是多余的。直接 requests + lxml 就够了。如果你需要 Scrapy 级别的中间件生态、Pipeline 扩展和社区插件,Scrapling 还差得远——它不是 Scrapy 的替代品,是 Scrapy 覆盖不到的灰色地带的补充。
跟 Playwright 或 Selenium 单独使用相比,Scrapling 的价值不在浏览器控制能力上,而在”自适应解析 + 隐身请求 + Spider 调度”这三个东西被打包到了一个统一的会话模型里。不用自己拼 Requests → BeautifulSoup → Selenium 三件套,也不用手写代理轮换和并发控制。
社区怎么样了
| 指标 | 数据 | 说明 |
|---|---|---|
| Stars | 64,861(截至 2026.06.19) | 从 0 到 64k 仅用 20 个月,日均约 100 Star |
| 核心维护者 | 1 人(D4Vinci) | Bus factor 较高,后续可持续性是最大风险 |
| Open Issues | 10 | Issue 管理干净,技术债累积速度可控 |
| 协议 | BSD-3-Clause | 商业友好,无 copyleft 限制 |
| Release 频率 | 约每 3-4 周一个版本 | v0.4.9 发布于 2026.06.07 |
Stars 增速是现象级的。从 2024 年 10 月上线,到 2026 年 3 月破 25k,再到 6 月接近 65k。这个曲线比很多同期的 AI 项目都要陡。但 Star 可以买,维护质量骗不了人。真正的压力测试在这个项目的 Bus Factor 上:唯一核心维护者 D4Vinci 同时维护提交、发布、文档、社区答复,1478 次 commit 几乎是他一个人完成的。
Discussions 区有一些值得关注的讨论。有人提了 RFC 讨论 Scrapy 集成方案,想把 Scrapling 的自适应解析嫁接到 Scrapy 的 Response 对象上。另一个 RFC 提出自动翻页检测,减少手动写”下一页”规则的工作。这些讨论的质量不低,但目前为止没有第二个核心贡献者站出来主导实现。
Issue 区整体干净,10 个 open issue 里多数是使用问题。有一个值得注意的信号:部分用户反馈在某些特定站点(如 Quora)的 Cloudflare 绕过不稳定,这可能跟目标站点的防护等级有关。如果你爬的是高价值反爬站点(电商、社交媒体),别把 StealthyFetcher 当成万能钥匙。
我的真实判断
翻完这个项目,我最深的感受是:Scrapling 重新定义了 Python 爬虫工具链的集成方式。在它出现之前,你用 Requests 发请求、BeautifulSoup 做解析、Scrapy 管调度、Playwright 做浏览器渲染、自己写代理轮换和反检测逻辑。五六个库拼在一起,每个都有自己的 API 风格和微妙的不兼容。Scrapling 把这些事打包进了一个统一的会话模型,这是它跟所有同类项目最根本的区别。
但它的单点依赖问题也必须正视。D4Vinci 是一个执行力很强的开发者,从 commit 密度和文档维护质量来看,他目前没有松劲的迹象。但一个 65k Stars 的项目依赖一个人,这在开源世界里是典型的”高回报高风险”。如果这个项目是你的生产环境依赖,关注两个信号:是否有第二位活跃维护者出现,以及商业赞助能否稳定支撑持续开发。
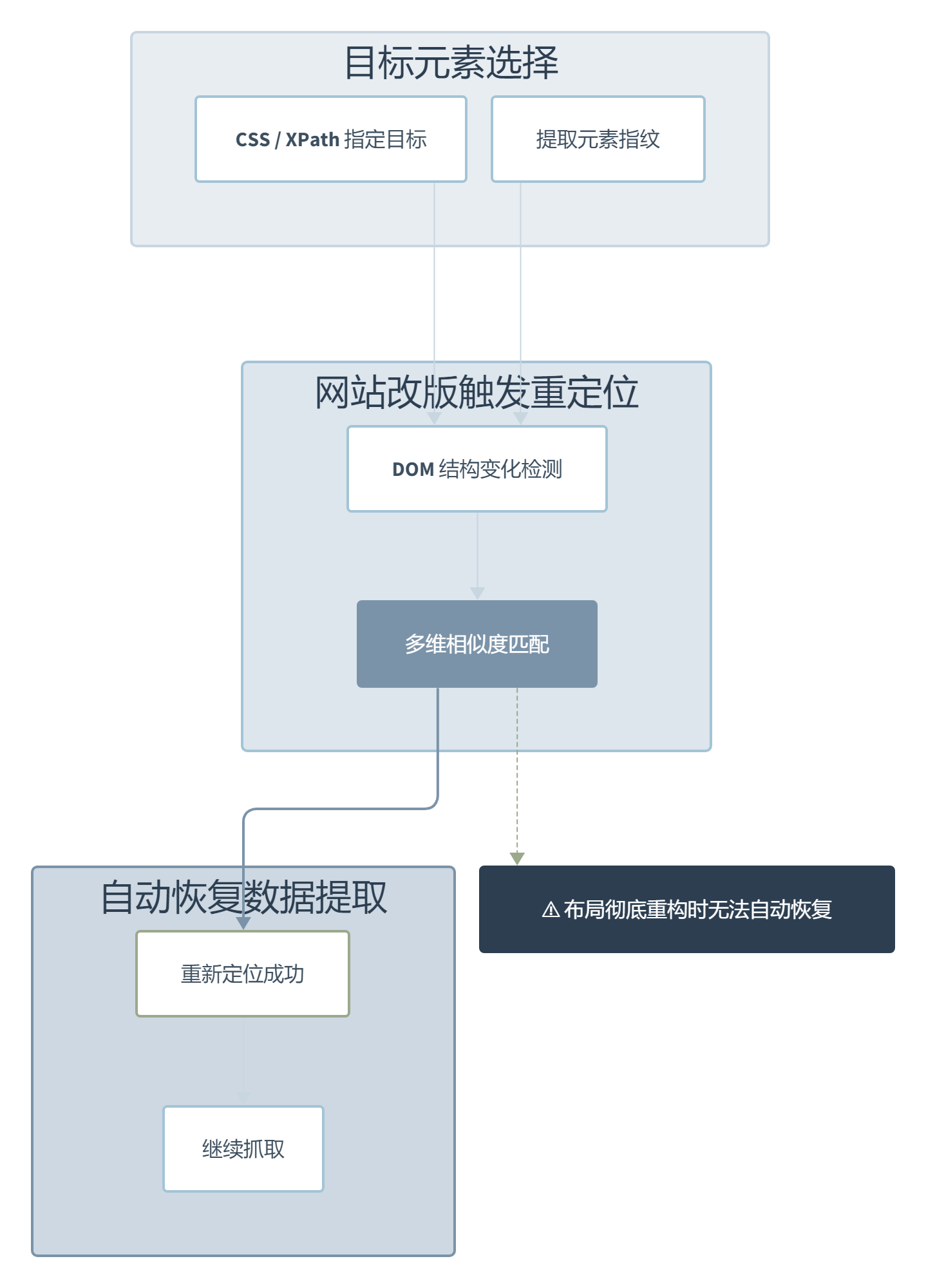
这个流程看着简单,但它在工程上的价值比看上去大得多。它把爬虫维护员最痛苦的那个循环——发现报错、打开浏览器 DevTools、找到新的选择器、改代码、重新部署——压缩到了零。不是”自动适配所有变化”,而是”大多数微调不会让你半夜爬起来修 bug”。
在爬虫这个方向上,Scrapling 代表了自适应和一体化两个趋势的交汇。传统爬虫框架解决的是”怎么抓得快”,Scrapling 回答的是”怎么能一直抓着不崩”。前一个问题靠工程优化,后一个问题靠设计理念。
跟 Scrapy 比,Scrapling 的社区生态和扩展性还差得很远,但它在”开箱即用”这件事上赢了。跟 Crawlee 比(Node.js 生态的”电池全包”框架),Scrapling 在 Python 生态里的反爬能力和自适应解析上更有优势。跟 BS4+Requests+Selenium 手工拼装比,Scrapling 的学习曲线更陡(你得理解它的三层架构),但维护成本更低(不用管五个库的版本兼容)。
资源地址
| 资源 | 地址 |
|---|---|
| GitHub | https://github.com/D4Vinci/Scrapling |
| 官方文档 | https://scrapling.readthedocs.io/en/latest/ |
| Docker Hub | https://hub.docker.com/r/pyd4vinci/scrapling |
聊完了,你的下一步
如果你已经在维护一个反爬敏感的爬虫项目,不妨拿 Scrapling 的 StealthyFetcher 替换你当前的请求层。这是风险最小的切入点,你不需要动现有的解析和调度逻辑,只需要换一个能自动绕过 Cloudflare 的请求入口。
如果你还在观望,盯紧两个指标:维护者的数量和 Issue 关闭速度。Scrapling 现在的状态是”一个牛逼的人在维护一个牛逼的项目”,但从个人项目变成社区项目的这一步,不是靠技术能力能迈过去的。这一步走通了,它会成为 Python 爬虫生态的默认选择之一;走不通,它就是一个功能惊艳但不可长期依赖的实验品。
Scrapling 让你不再需要写 try-except 包裹每个选择器,这件事本身就已经值回学习成本了。