
你刚刚花了四十分钟,跟 Claude Code 解释清楚了你这个 NestJS 项目的分层架构、自定义中间件怎么挂载、Prisma Schema 里哪些字段不能动。Session 结束。明天打开新会话,它又问你”这个项目是做什么的”。
这不是你的 Prompt 写得不好。这是 AI 编程 Agent 一个结构性缺陷:每次会话都是一个全新的脑子。MEMORY.md、CLAUDE.md、Cursor 的 notepad,这些都是给你手动往里塞东西的草稿本,不是真正的记忆系统。
AgentMemory 做的事就是填这个坑。截至 2026 年 6 月,它在 GitHub 上有约 23k Stars,被 AlphaSignal(18 万技术订阅者)专题报道,进了 Trendshift 新项目榜第 19 位。但 Star 数不是重点。重点在于它拿出的 LongMemEval-S 基准成绩是 95.2% 的 R@5 召回率,比 Mem0 高了近 14 个百分点。
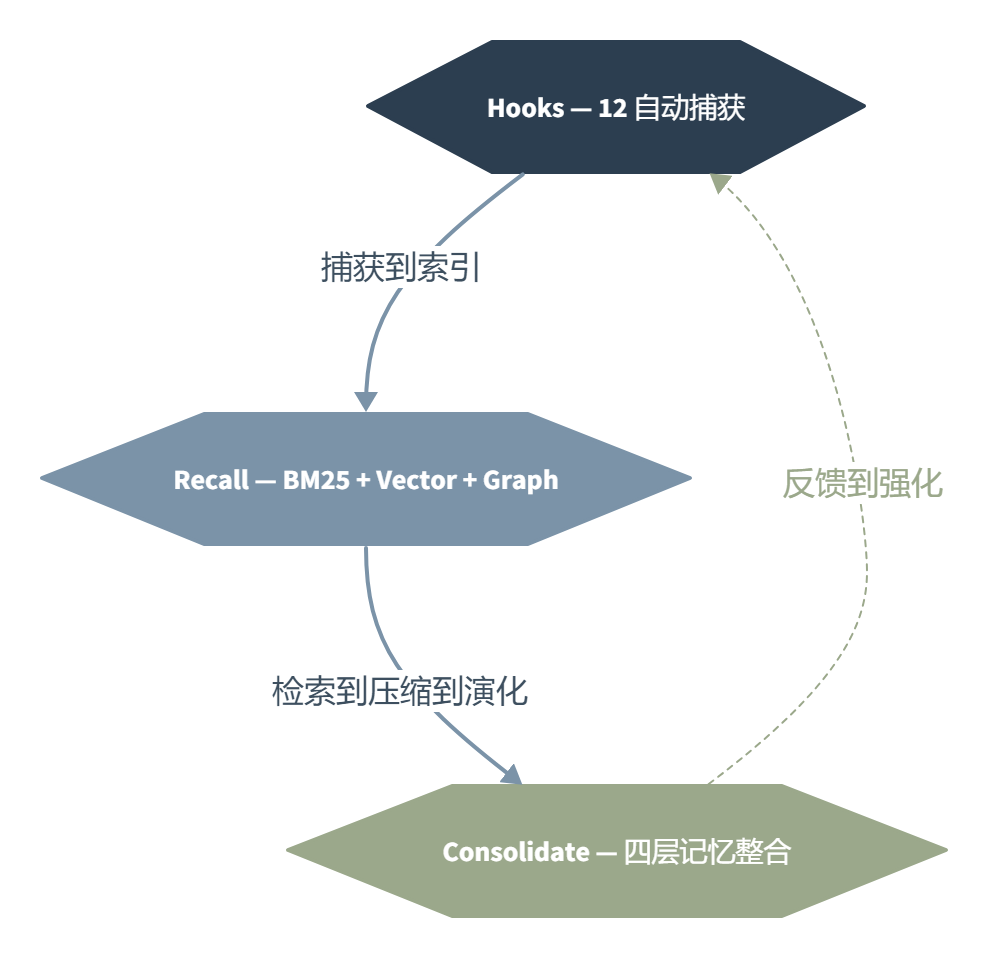
这张图概括了它的设计骨架:三个原语(Hooks、Recall、Consolidate)构成一个闭环。Agent 干活的时候自动捕获上下文,检索的时候走混合搜索,后台定期把碎片压缩成结构化记忆。不是给 Agent 塞一本手册,是让它自己长出一个会学习的记忆层。
不过画架构图容易,真把东西跑起来看输出才知道值不值。翻完 Issue 和 commit 历史,有几件事让我印象很深。
打动我的几个地方
翻完 Issue 区和 commit 历史,真正让我觉得这个项目不一般的地方有三个。
第一个是它的 12 个自动 Hook。这是 AgentMemory 和竞品最根本的分界线。Mem0 也好、Letta 也好,都需要你(或者你的 Agent)主动调用 add() 来存记忆。AgentMemory 不需要。SessionStart、PreToolUse、PostToolUse、Stop 等 12 个生命周期 Hook 自动接管了你 Agent 的每一个动作。你用 Claude Code 跑了一个 git diff,AgentMemory 就记下来了——不是记命令本身,是压缩成一个 Observation:这个项目在 auth 模块有修改。
更关键的是隐私过滤。API Key、Secret、<private> 标签包裹的内容在存储前就被剥离了。SHA-256 哈希去重,5 分钟滑动窗口。不是粗暴地记一切,是记该记的。
第二个是它的三流混合检索。检索这件事,大多数竞品只做向量(Mem0)或向量+图谱(Cognee)。AgentMemory 走的是 BM25 词法 + 向量语义 + 知识图谱三条线并行,然后用 Reciprocal Rank Fusion(RRF)融合排序。词法搜能抓到精确的函数名和类名,语义搜能理解”用户想改认证逻辑”和”auth 模块修改过”的关联,图遍历在检测到已知实体时补上关系链。
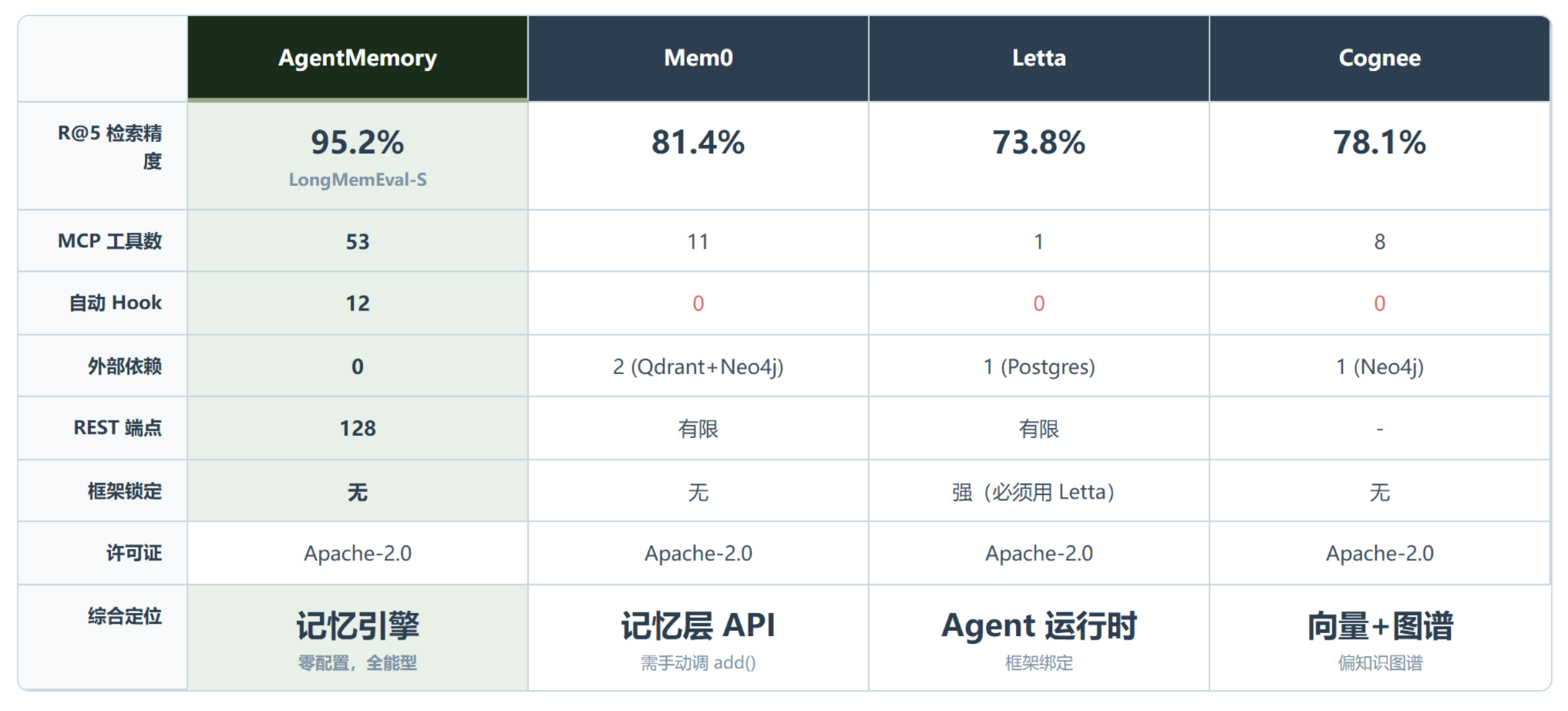
从对比卡片能看出来,AgentMemory 在记忆捕获的自动化程度和检索精度上对竞品是碾压级别的。它不是”更好用的 Mem0″,它解决了一个 Mem0 根本没解决的问题:谁来负责存记忆?
第三个是它的零外部依赖设计。整个运行时是一个 Node 进程,SQLite 做持久化,内存向量索引做嵌入。不需要 Redis,不需要 Kafka,不需要 Postgres、Qdrant、Neo4j。一行 npx @agentmemory/agentmemory 就跑起来了——API 在 3111 端口,实时 Viewer 在 3113 端口。这个部署门槛,对于一个记忆系统来说低得离谱。
一个容易忽略的亮点是它的四层记忆整合模型。Working 记忆(原始观察)被压缩为 Episodic 记忆(会话摘要),再提炼为 Semantic 记忆(事实和概念),最终固化为 Procedural 记忆(工作流和最佳实践)。整个过程有艾宾浩斯衰减机制:不被访问的记忆降低重要性分数,被频繁检索的记忆加强保留评分。不是死记,是活的、会进化的记忆。
亮点说完,实际装起来跑一下是什么体验?
上手什么感觉
安装不用纠结,一条命令的事。
npm install -g @agentmemory/agentmemory
agentmemory
服务器在 3111 端口跑起来之后,先跑一遍 demo:
agentmemory demo
这个 demo 会塞入 3 个示例会话,让你立刻验证混合检索的效果——搜索一个概念,看看能不能跨会话召回。
接下来把你日常用的 Agent 接上。Claude Code 用户最简单:
agentmemory connect claude-code
Codex CLI 和 Copilot CLI 同理,把 claude-code 换成 codex 或 copilot。Cursor 和 VS Code 用户可以用 MCP 的一键 Deeplink 安装,其他 MCP 兼容客户端(Windsurf、Cline、Roo Code、Gemini CLI 等十几种)用通用 JSON 配置就行。
但有几个坑必须提前说清楚。第一个,LLM 压缩默认是关的。不开它的时候只有 BM25 词法检索工作,R@5 从 95.2% 掉到 86.2%。要开压缩,需要配一个 LLM provider——Anthropic API、Gemini(免费层可用)、OpenRouter 都行。推荐用 Gemini,免费额度足够日常用,而且嵌入和 LLM 一个 Key 搞定。
第二个坑是 Windows 上的路径问题。GitHub Issue 里有人反映 Windows Terminal 里初次启动偶尔报端口占用,重启一下一般就好了。作者比较实在,README 里写了三种 Windows 部署方案,从 npm 全局安装到 Docker Desktop 到预编译二进制都有。
第三个,知识图谱抽取需要额外开 GRAPH_EXTRACTION_ENABLED=true,也需要 LLM 支持。默认不开不是因为不好用,是因为它会让每次压缩调用多一次 LLM 请求,Token 消耗翻倍。如果你不在乎每天多花几毛钱,开了以后检索体验会明显提升。

完整的记忆流水线大概长这样。Hook 捕获后先过 SHA-256 去重和隐私过滤,然后可选地走 LLM 压缩(提取事实、概念、叙述),接着 BM25 分词建立倒排索引,同时嵌入模型生成向量。检索的时候三条流并行跑,RRF 融合后注入 Agent 上下文。
跑起来的坑说清楚了,更关键的问题还没回答:这东西到底适合谁用?
什么时候用,什么时候别用
| 场景 | 典型用户 | 优势 | 局限 |
|---|---|---|---|
| 日常用 Claude Code/Cursor 写代码 | 全栈/后端开发者 | 12 Hook 自动管,零维护 | Windows 偶尔端口冲突 |
| 长期维护同一个项目 | 项目 Owner | 跨会话积累项目知识 | 频繁切换项目时记忆噪声上升 |
| 团队共用 Agent 记忆 | 小团队(2-5 人) | Mesh 联邦同步 | 缺少 RBAC 权限控制(路线图 Q4 2026) |
| 想省 Token | 重度 AI 编程用户 | 年省 92% Token(~170K vs 19.5M) | LLM 压缩开启后成本略增 |
不适用的情况也直接说清楚。
你只是想给 Claude Code 加几条固定的项目约定,写一个 CLAUDE.md 就够了。AgentMemory 是给那种”Agent 每天都在帮我干活,但每天都跟第一天上班一样”的场景用的。
你的主要工具是 Cursor Chat 而不是 Cursor Agent 模式,AgentMemory 的 Hook 系统帮不上什么忙——Chat 模式的生命周期事件太少了,捕获的东西很稀疏。
你的项目涉及严格的合规要求(SOC2、HIPAA),AgentMemory 目前的数据存储是明文本地 JSON,没有加密静态存储。这不在它 Q2-Q3 2026 的路线图里。
场景聊完了,还有一个维度决定你能不能长期依赖它:这个社区靠不靠谱。
社区怎么样了
| 指标 | 数据 | 说明 |
|---|---|---|
| GitHub Stars | ~23k(截至 2026.06) | 周增 500+,增速健康 |
| 核心维护者 | 1 人(Rohit Ghumare) | Bus Factor = 1,这是最大风险 |
| 版本 | v0.9.27 | 未到 1.0,接口可能变化 |
| 许可证 | Apache-2.0 | 商业友好,无限制 |
| Open Issues | 800+ | 数量偏高,但大多为 feature request |
| CI 测试 | 1428 通过 | 覆盖充分,质量门禁严格 |
说实话,Bus Factor = 1 是我对这个项目最大的顾虑。Rohit 的提交频率极高,Issue 响应也很快,但你去看 contributor 列表,核心代码几乎全是他的。如果他被某家大厂挖走或者精力转向别的项目,这个仓库会面临很大的维护风险。
社区声音方面,Product Hunt 上的几个真实反馈值得参考。Peter Neyra 说他”回填了一个月的 Cursor 会话记录,AgentMemory 的召回出乎意料地准,连他已经放弃的一些技术方向都翻出来了”。Pranav Prakash 用了两周后的反馈是”确实看到了改进”。Alper Tayfur 的评价更一针见血:“它解决的是编程 Agent 最大的痛点:在会话间丢失有用的项目上下文,同时不撑爆上下文窗口”。
但 Reddit 和 HackerNews 上也有质疑声。有人觉得”这就是一个强化版的 grep + embedding”——不算全错,BM25 确实是词法搜索,AgentMemory 的差异化在于自动捕获和三流融合,不是某个单一技术有多新奇。
社区数据摊开看完了。现在可以聊点真的了:综合所有信息,这个项目到底值不值得跟。
我的真实看法
我对 AgentMemory 的判断经历了一个”从有用到担忧”的过程。
一开始我觉得这个东西是刚需。AI 编程 Agent 没有记忆,等于每次都在裸奔。AgentMemory 用 12 个 Hook 解决了”谁来存记忆”这个竞品都没回答的问题,这是真正的差异化。95.2% 的检索精度和零外部依赖的设计,也是实打实的工程成就。
但越深入了解,我越意识到它现在还不是一个”装了就完事”的方案。LLM 压缩要配 API Key,知识图谱要手动开,四个记忆层之间的演化策略(衰减率、合并阈值、TTL)全是默认值,没有暴露微调接口。这对高级用户来说不够。你想让某些类型的记忆保存更久?想调整 Working→Episodic 的压缩粒度?目前做不到。
更大的隐忧是单维护者模式。23k Stars 的仓库只有一个人在写核心代码,这在开源世界不是新闻,但放在一个”记忆系统”这种基础设施级的产品上,风险被放大了。如果 Anthropic 或者 OpenAI 决定把 AgentMemory 的核心能力内置到自己的 Agent 里,这个项目还能不能活?
不过从趋势上看,AgentMemory 处在上升通道。周增 500+ Stars,Product Hunt 上线后的热度还没退,Linux Foundation 旗下的 Agentic AI Foundation 把它列为 featured project。Rohit 的路线图(Q2 深度 → Q3 广度 → Q4 信任 → Q1 2027 v1.0)规划得也很清晰。如果 Q4 的多维护者治理模型和 SSO/RBAC 按时落地,Bus Factor 的风险会大幅降低。
一个值得关注的反直觉信号:AgentMemory 明确排除了云托管 SaaS 和付费订阅。Rohit 在 README 里写得很直白:“不收费,不上云,不锁平台”。对于一个基建项目来说,这种声明既是承诺也是风险——承诺你的数据永远在你机器上,风险是作者的激情能不能支撑到 v1.0 甚至 v2.0。
资源地址
| 资源 | 地址 |
|---|---|
| GitHub | https://github.com/rohitg00/agentmemory |
| 官方网站 | https://www.agent-memory.dev |
| NPM | https://www.npmjs.com/package/@agentmemory/agentmemory |
话说到这份上,剩下的就是行动了。
说完了,你该干嘛
如果你日常用 Claude Code 或 Cursor Agent 模式写代码,AgentMemory 值得花十分钟装一下。从 agentmemory demo 开始跑一遍,看看它能不能在三个示例会话里准确召回你要的东西。如果 BM25 的基础召回就够用,那连 LLM Key 都不用配,零成本。
如果你在观望,盯住两个指标:ROADMAP 里的多维护者治理模型什么时候落地、Bus Factor 什么时候从 1 变成至少 3。这两个变化决定了 AgentMemory 能不能从一个好用的个人工具变成一个靠谱的基础设施依赖。
说实话,AI 编程 Agent 的记忆问题,迟早会被解决——不管是 AgentMemory 做到 v1.0,还是 Claude Code 或 Codex 自己内置了等价的能力。在这之前,AgentMemory 是你今天就能用的、做得最好的那个选项。