
你用过 Claude Code。Agent 开始工作了,它跑
git status,输出 150 行;跑npm test,输出 400 行;跑grep -r "export" src,200 行。一次操作,近两万 Token 已经烧掉了。这里面对 Agent 真正有用的可能不到 200 个。
这不是你的 Prompt 写得不好,是 Agent 没有能力从一堆命令输出里只看它需要的部分。它会把整坨输出全部吞进上下文窗口。在一个 200K 的窗口里,这种噪音轻松占掉一半以上。Patrick Szymkowiak 算了一笔账:一次 30 分钟的 Claude Code 编码会话,CLI 命令产生的 Token 噪声约 118,000 个,占到上下文窗口的 59%。留给代码推理的空间,没有你想象的那么多。
RTK 就是被这个痛点逼出来的。2026 年 1 月 22 日,Patrick 在 GitHub 上 push 了第一行代码。项目描述极短:一个 Rust 写的 CLI 代理,能在开发者命令上减少 60-90% 的 LLM Token 消耗。4 个月后,超过 6.3 万 Stars。不是营销,不是偶然,是每一个重度 AI 编码用户都被这个问题折磨过,而 RTK 是第一个正面朝它开刀的工具。
翻完它的架构设计和社区讨论之后,我发现它做的事情比我最初想的更有意思。节约 Token 只是表象,真正关键的是它在 Agent 和 shell 之间建立了一个智能代理层。这个位置能做的事,远远不止压缩。
问题来了:为什么说它不是简单的”压缩工具”?
为什么它不只是”压缩工具”
RTK 的核心机制说起来简单:在 Agent 调用 shell 命令时,把命令输出在半路截住、过滤压缩、再把干净的结果交给 Agent。但每个设计决策的背后,都有判断。
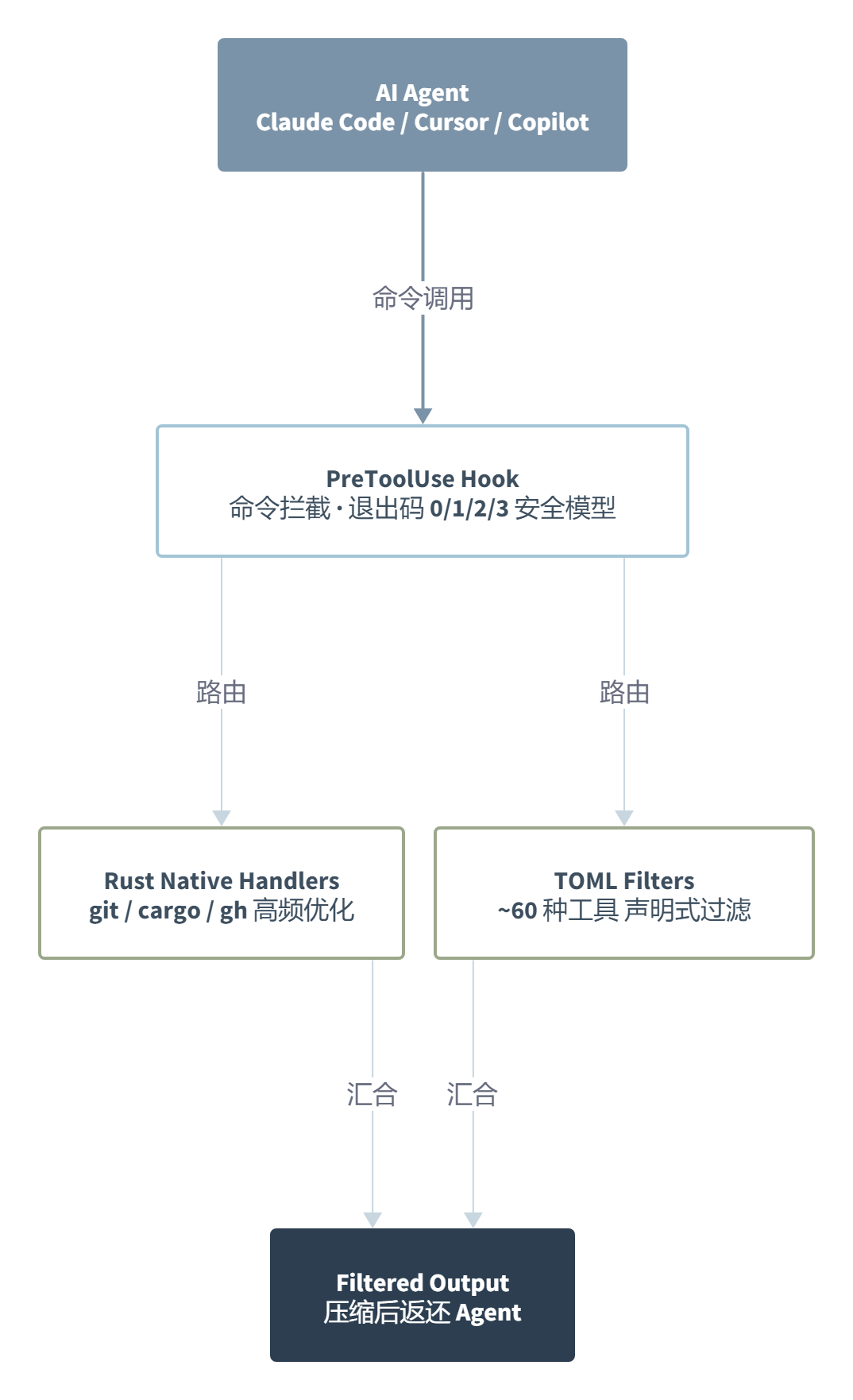
第一个关键选择,是它在工具执行层拦截,而不是在 Prompt 层做手脚。市面上大部分上下文管理策略的思路是在 Prompt 里告诉 Agent”请简洁一点”或者”忽略无关输出”。RTK 不跟 Agent 商量。它直接 hook 到 Claude Code 的 PreToolUse 钩子,在 Agent 调用 git status 之前把命令字符串重写成 rtk git status。Agent 从始至终不知道自己调的命令被改写了,它只看到”我调了 git status,收到了一个异常干净的回执”。零配置、零心智负担、零 Agent 兼容性问题。这种做法比任何 Prompt 工程都暴力,也比任何 Prompt 工程都可靠。
第二个值得聊的设计是退出码安全模型。RTK 的 Proxy 执行完后,用退出码来告诉 hook 系统发生了什么事。0 表示已重写且安全,直接放行。1 表示这个命令没有对应的过滤器,原样透传。2 表示这是个危险命令(比如 rm 和 sudo),拒绝执行并交给 Agent 自己判断。3 表示已重写但需要 Agent 人工确认。这四层语义让 RTK 同时扮演了压缩器和安全守卫两个角色。Agent 不会先跑了 rm -rf 看到报错才意识到搞砸了,RTK 在它跑之前就把门关上了。
然后是混合架构。对于 git、cargo、gh 这类高频命令,RTK 写了手优化的 Rust 原生处理器。以 git diff 为例:先跑 git diff --stat 拿文件级摘要,再跑真实 diff 做压缩,最后合并两个输出。这是明确的有损压缩——Agent 不需要知道 delta 压缩用了 8 个线程。对于长尾命令(Terraform、Ansible、make、Rails 等约 60 种),用 TOML 声明式过滤规则,编译阶段嵌入二进制。高频路径追求极致速度,长尾路径追求可配置性。两类场景各自用了最优方案,没有为了”优雅”牺牲实用性。
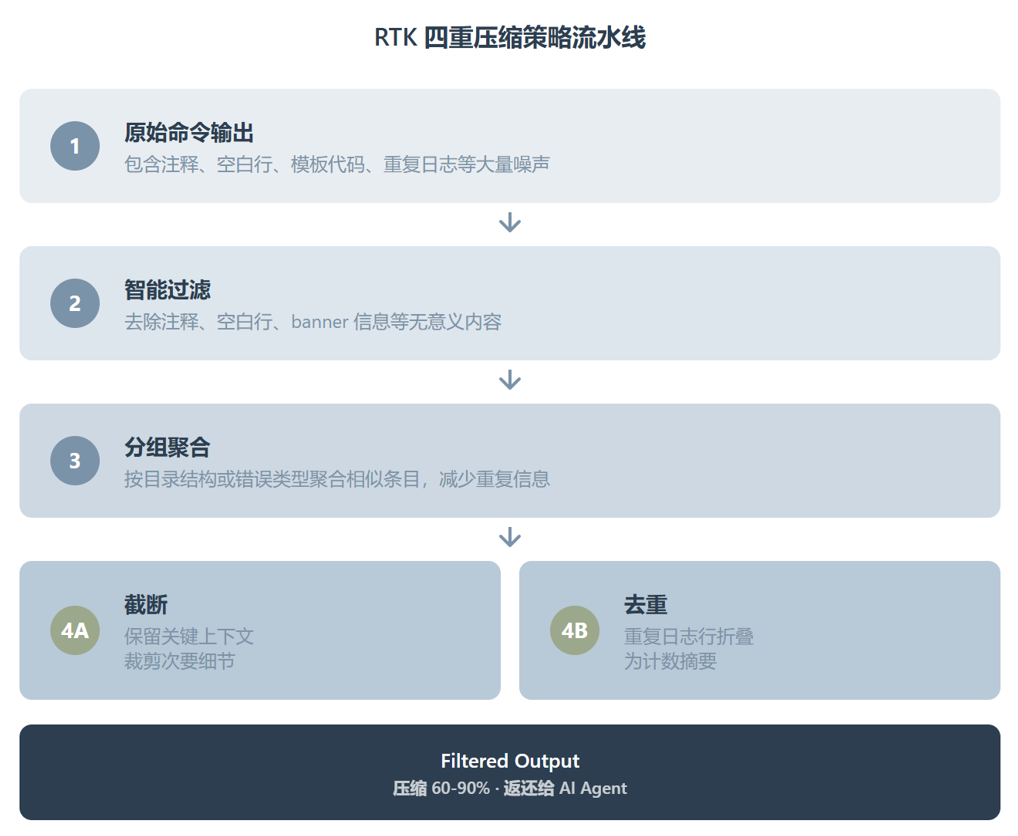
压缩本身分四层:智能过滤去掉注释、空白和模板代码;分组聚合按目录或类型合并相似条目;截断保留关键上下文裁掉次要细节;去重把重复日志行折叠为计数。四层的顺序不是随便排的,先砍掉无意义内容,再归并相似内容,然后裁剪冗余,最后折叠重复。每一步的输入都是上一步精炼后的结果。
还有一个容易忽略的设计是 Tee 安全机制。压缩意味着丢掉了一些东西,但如果丢掉的恰好是 Agent 需要的关键信息呢?RTK 的处理方式是:当 mode = failures 且命令退出码非零时,把完整原始输出保存到本地文件。Agent 拿着压缩版做快速判断,发现异常时可以回看完整日志。有损压缩加完本存档,这个平衡拿捏得很稳。
但架构说得再好,也不如自己跑一下有感觉。
跑起来看看
安装有多简单?macOS 上直接 Homebrew,一条命令搞定:
brew install rtk
不用 Homebrew 的话还有三条备选路径:curl 快速安装脚本、cargo install 从源码构建、直接下载预编译二进制(macOS/Linux/Windows 全平台覆盖)。Windows 用户注意:auto-rewrite hook 依赖 Unix shell,原生 Windows 上会回退到 CLAUDE.md 注入模式,完整功能建议 WSL。
装完之后集成 AI 工具也简单,给哪个工具用就指定哪个 flag:
rtk init -g # Claude Code / Copilot
rtk init -g --gemini # Gemini CLI
rtk init -g --codex # OpenAI Codex
rtk init -g --agent cursor # Cursor
重启 AI 工具后生效。你再打 git status,它会被自动重写成 rtk git status。你感觉不出任何变化,直到下一次看到 Token 账单。

RTK 还提供了分析面板,能直观看到自己省了多少:
rtk gain # 节省统计摘要
rtk gain --graph # ASCII 图表,看最近 30 天趋势
rtk discover # 发现还没被优化的命令
rtk session # 显示当前会话的采用率
常见卡点有两个。一是如果你的 AI 工具配置目录不在标准位置,RTK 可能找不到,需要手动指定路径。二是个别内部工具的命令输出被压缩得过于激进,建议在 TOML 配置里给特定命令调低压缩力度。GitHub Issue 区关于这两类问题的讨论比较活跃,团队也在持续优化 filters 的精度。
好用归好用,关键还是看适不适合你自己的场景。
什么时候用,什么时候别用
| 场景 | 典型用户 | 优势 | 局限 |
|---|---|---|---|
| 重度 AI 编码(Claude Code/Cursor 日常使用) | 全栈/前端/后端 | Token 节省立竿见影,零配置 | Windows 需 WSL |
| 团队 AI 工具预算管理 | 技术负责人/CTO | 降本可量化,有分析面板 | 企业版定价处于早期 |
| CI/CD 中 AI Agent 调用 | DevOps 工程师 | 减少流水线 Token 开销 | 复杂日志需手动调参 |
| 偶尔用 AI 辅助编码 | 轻度用户 | 装一次永久生效 | Token 节省绝对值有限 |
不适用的情况也很明确。如果你一个月用 AI 工具不到 20 次,装 RTK 省下的 Token 钱可能不够你看 README 花的时间。如果你重度依赖精细的编译错误堆栈来调试,RTK 的截断和去重可能让你错过关键信息(不过 Tee 机制在非零退出时会保留完整日志,能缓解一部分)。如果你的环境是纯 Windows 且没有 WSL,体验会打折扣——auto-rewrite 不可用,只能靠 CLAUDE.md 注入模式做手动管理。
场景聊完了,但可持续性才是判断一个开源项目能不能跟的核心依据。
社区怎么样了
先看看几个关键指标,数字本身会说话:
| 指标 | 数据 | 说明 |
|---|---|---|
| Stars | ~63,000 | 截至 2026 年 6 月,4 个月从零冲到 6 万+ |
| 核心维护者 | 4 人 | Patrick Szymkowiak、Florian Bruniaux、Adrien Eppling、Nicolas Le Cam |
| 贡献者 | 110 人 | 社区参与积极,非一人项目 |
| 协议 | Apache-2.0 | 商业友好,最初为 MIT 后切换 |
| Release | 213 个(v0.42.2) | 高频迭代,release-please 自动化管理 |
Stars 增速是 2026 年上半年 GitHub 上最漂亮的曲线之一。但更有说服力的不是绝对数字,而是增长结构:1 月到 4 月冲到 2.6 万,5 月破 5 万,6 月继续上行到 6.3 万且没有出现断崖。这说明增长不只是一波 HN 流量驱动,它在持续扩散。
4 人核心团队面对 110 人外部贡献者池,Bus Factor 偏低是事实。但 release-please 自动化发布、Security Check CI、清晰的贡献指南已经搭好,这些基础设施降低了对个人的依赖。从 commit 频率看,2026 年 Q2 以来每周有至少 2-3 次实质性的合并,节奏稳定。
社区声音方面,Hacker News 和 Reddit 上关于 RTK 的讨论集中在两个方向。一种实用主义派:“装了就不用管了,省到就是赚到”。另一种是警惕派:“压缩总有损,为了省 Token 丢关键信息不值得”。从 Issue 区看,团队对两类反馈都有回应,Tee 机制的引入就是应对警惕派诉求的成果。Discord 社区里有超过千人在讨论配置优化和自定义 filter,氛围比大多数同量级开源项目活跃。
聊完了社区和数据,该聊点真的了。
我的真实看法
回到那个核心问题:RTK 值不值得装?如果 10 分满分,我打 8 分。扣掉的 2 分不在技术上,在团队规模上。4 个人维护一个覆盖 100+ 命令、集成 14 个 AI 工具的项目,还要同时做 SaaS 商业化,这个负荷不小。但到目前为止,这 4 个人的交付质量让我愿意持有保留的乐观。
趋势判断上,RTK 现在的定位像一个”省钱工具”,但这绝不是它的终点。它的 PreToolUse 钩子架构本质上是 Agent 和 shell 之间的智能代理层。在这个位置上,能做的事远不止压缩:命令安全审计、执行策略控制、跨工具统一上下文管理、Token 预算实时分配。这些方向在团队的 Roadmap 和官网 vs 页面里已经陆续浮现。Token 优化正在从一个技巧变成一个基础设施品类,RTK 是这个品类最早的开跑者,而且领先幅度不小。
有一个实际的问题:RTK 的 SaaS 免费版每月 400 次高级请求的限制,对重度 AI 编码用户不够用。一个全天靠 Claude Code 写代码的工程师,400 次可能一周就没了。企业版 $39/用户/月的定价很克制,但对个人开发者的中间阶梯不够平滑。希望后续有 Pro 个人版计划。
最大的风险不在技术,在窗口期。Claude Code、Cursor、Copilot 这些 AI 工具迟早会内置自己的输出过滤能力。如果 Anthropic 在 Claude Code 里加了一个输出压缩开关,RTK 的独特价值会被大幅削弱。但这种事短期不会发生,理由是:RTK 的价值不在于某一个 AI 工具的压缩功能,而在于跨工具的统一管理。你换了 AI 工具,RTK 一样工作。内置优化做不到这一点。只要开发者同时在用多个 AI 工具,RTK 就有生存空间。
资源地址
| 资源 | 地址 |
|---|---|
| GitHub | https://github.com/rtk-ai/rtk |
| 官方文档 | https://www.rtk-ai.app/ |
| Discord 社区 | https://discord.gg/RySmvNF5kF |
分析了这么多,该落到行动上了。
说完了,你该干嘛
如果你已经在用 Claude Code、Cursor 或 Copilot 做日常开发,而且一个月消息量超过 500 条,RTK 值得立刻装。5 分钟安装成本,每次会话省下 60-80% 的 CLI 命令 Token。这个投入产出比在开源工具里不算常见。
还在观望的话,关注两个指标。一是 Claude Code 是否会在 2026 年下半年推出内置的输出过滤——这决定了 RTK 的护城河宽度。二是 RTK 团队的人手扩张速度——4 个人撑一个 6 万星项目能撑多久。前者决定天花板,后者决定底线。
这个项目让我重新想了一件事:在 Agent 时代,上下文窗口的珍贵程度远高过算力成本。上下文是你和 Agent 共享的”工作内存”,被噪声污染意味着思考质量下降,不只是账单变厚。RTK 解决的,本质上不是成本问题,是认知问题。