

如果你用过 Claude Code 或者任何终端里的 AI 编程 Agent,你应该碰到过这样的时刻:Agent 已经在同一个任务上跑了几十轮,前面的决策开始被后面积压的上下文挤掉,它忘了你最开始说了什么,忘了中间改过的设计方向,甚至忘了测试还没跑完就宣布”搞定了”。
这不是模型不够聪明。是 Agent 的”记忆系统”跟不上任务的长度。
小米 MiMo 团队 6 月 11 日开源的 MiMo Code,就是针对这个瓶颈设计的。9 天时间冲到约 9.8k Stars,895 个 Fork,Issue 区堆了 200 多个讨论。5 个人,14 天,一次 vibe coding 的产物。团队负责人罗福莉自己这么说。
但别被这个速度迷惑。MiMo Code 做的事情比”又一个 Claude Code 替代品”要野心大得多。它在尝试重新定义 AI 编程 Agent 对”记忆”这件事的理解,从短时上下文管理升级到跨会话的知识沉淀和流程进化。说白了这篇文章就想讲清楚一件事:这个项目到底是在解决真问题,还是在用免费模型换短期流量。
打动我的几个地方
MiMo Code 基于 OpenCode 分支开发,继承了它的多模型支持和 MCP 协议兼容。但真正让它从一堆 AI 编程 Agent 里跳出来的,是三个方向的设计决策。
持久记忆不是”存得久”那么简单。MiMo Code 的记忆体系有四个层级:Session 记忆负责当前会话,Project 记忆保存项目级知识,Global 记忆跨项目生效,History 以 SQLite FTS5 全文搜索保存每个会话的完整轨迹。听起来像数据库架构,但关键不在存储,在于谁在维护这些记忆。
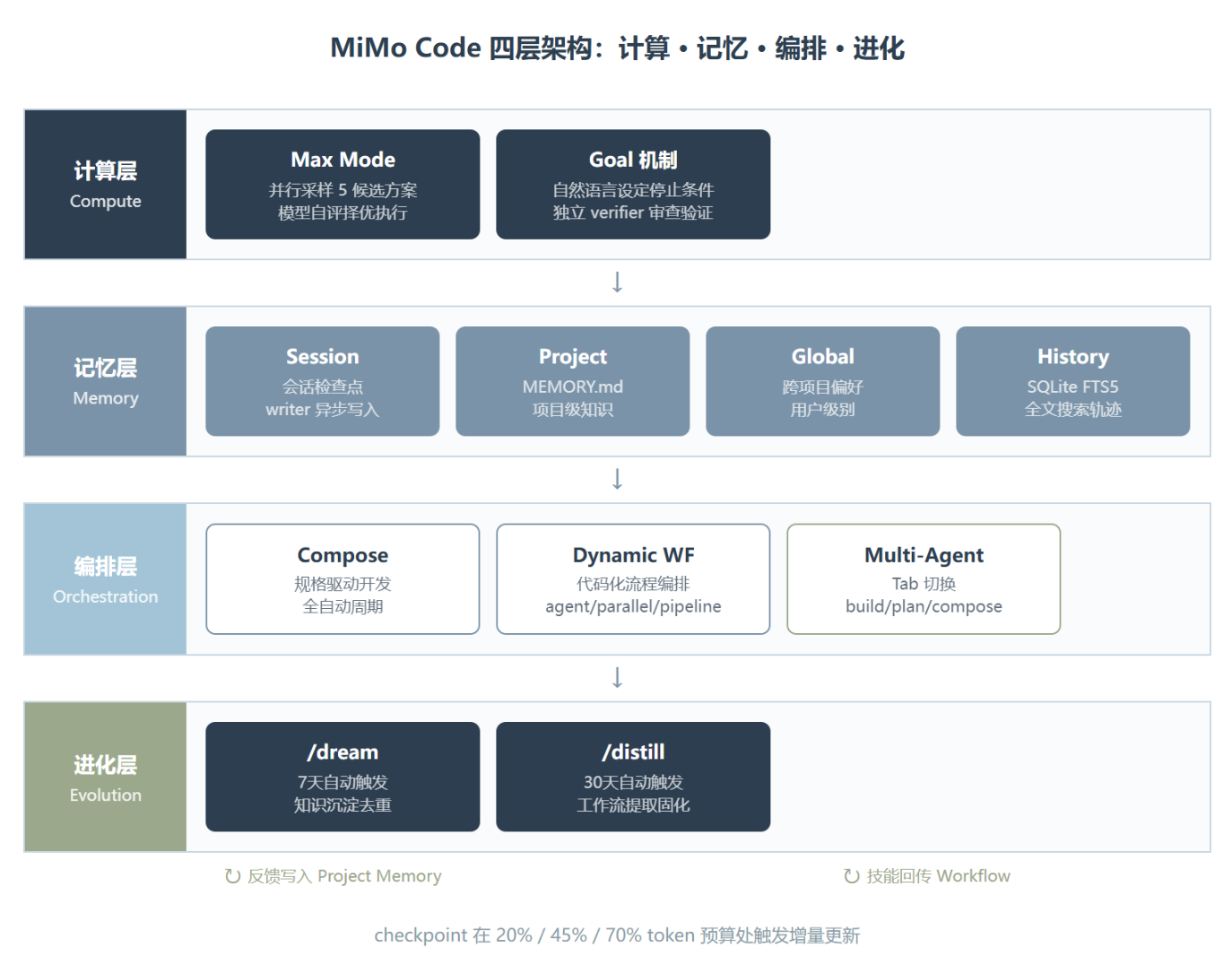
它部署了一个独立的 writer subagent,专职写 checkpoint。这个 agent 不和主 Agent 共享注意力。主 Agent 专心写代码,writer 在后台读对话、提取结构化状态、写入磁盘。当上下文接近窗口上限时,运行时切断当前窗口,用已持久化的文件重建一个新窗口。
checkpoint 在 20%、45%、70% 的 token 预算处触发增量更新,而不是等窗口快满了才仓促压缩。这个设计解决了一个实际问题:让一个正在 debug 复杂 bug 的模型同时维护结构化日志,两件事都做不好。分开之后,每一件事都做得更好。
用独立评判模型做”验收”是第二个聪明的地方。MiMo Code 的 Goal 机制允许用户用自然语言设定停止条件,比如”所有测试通过且代码已提交”。每当 Agent 想结束任务时,系统自动发起一次独立模型调用,审查完整对话历史,判断停止条件是否真正满足。如果没满足,把差距反馈给 Agent 让它继续。这和 Claude Code 的做法不一样。Claude Code 靠主 Agent 自己判断是否不再需要工具调用,加上 max turns 和 context overflow 等系统条件。MiMo Code 把”做事的”和”验收的”分开了,在长任务里尤其关键,因为 Agent 越累越容易提前宣布成功。
第三个设计是 Max Mode,并行采样选优。每一轮生成多个候选方案,默认 5 个,只做推理和工具调用规划不实际执行,然后由同一个模型当 judge 选最优方案。官方数据是在 SWE-Bench Pro 上提升 10% 到 20%,代价是 4 到 5 倍的 token 消耗。目前还是实验功能,需要手动开启。
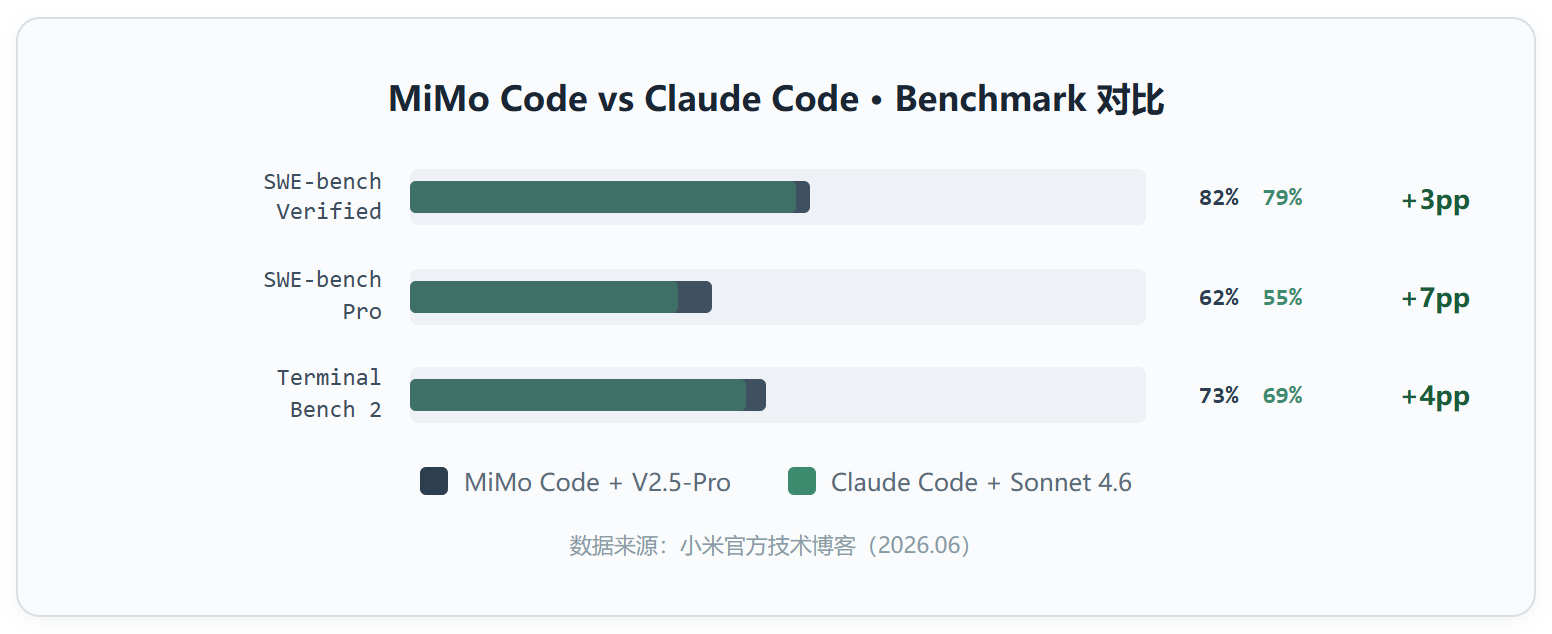
官方给出的 benchmark 数据是这样的:搭配 MiMo-V2.5-Pro 的 MiMo Code 在 SWE-bench Verified 上 82%(Claude Code + Sonnet 4.6 是 79%),SWE-bench Pro 上 62% 对 55%,Terminal-Bench 2 上 73% 对 69%。差距不算压倒性,但方向一致。
更重要的是框架本身的贡献。在运行相同 MiMo-V2.5-Pro 模型的情况下,MiMo Code 在 SWE-bench Pro 和 Terminal-Bench 2 上的得分比 Claude Code 高出约 5 个百分点。576 名开发者参与的 A/B 测试中,200 步以内两者胜率接近 50%,200 步以上 MiMo Code 升至 65% 以上。
但要说明白:这些数据全部来自小米官方博文和内部 Beta 测试,不是独立第三方评测。数据方向是对的,来源需要你自行判断。
这套设计的逻辑链条清晰:计算层(Max Mode)保证单步做对,记忆层(checkpoint + rebuild)保证多轮不断,进化层(Dream + Distill)保证跨会话越来越好。三件事各自独立,目标一致:让 Agent 能处理上百步的长周期任务。
跑起来看看
安装就一行命令,三个平台通用。或者走 npm 路线也行:
curl -fsSL https://mimo.xiaomi.com/install | bash
或者 npm 全局安装 npm install -g @mimo-ai/cli,然后敲 mimo 启动。首次启动会引导配置:MiMo Auto 限时免费通道(零配置,基于 MiMo-V2.5,百万 token 上下文),小米 MiMo 平台 OAuth 登录,从 Claude Code 一键导入配置,或者添加任何 OpenAI 兼容的 API。
但 Issue 区暴露了不少坑,以下是最常见的几条:
- Windows 用户可能遇到 ConnectionRefused,根因是 OPENSSL_ia32cap
环境变量导致 Bun 的 AES-GCM 失败(#1152)
- Termux(Android arm64)安装 @mimo-ai/cli 直接报错(#1139)
- macOS 深色模式下 TUI 界面完全看不清(#1120)
- 粘贴长 JSON 会自动截断发送,接入 DeepSeek API 的用户因此
出现异常扣费(#939)
- MiMo Auto 免费通道登录后凭证未持久化,重启即失效(#1154)
最严重的一条来自 Issue 区的讨论:有用户反馈 MiMo Code 的 Agent 在执行任务时,检测到全局 npm 目录下有 OpenCode 相关包,自动执行了 npm uninstall,导致用户正在使用的 OpenCode 开发环境被破坏。Agent 未经确认就执行删除操作,这在任何能执行 shell 命令的产品里都是红线。
模型接入支持 MiMo 自家模型(V2.5 系列)、DeepSeek、Kimi、GLM 和任何 OpenAI 兼容 API。定价方面,MiMo-V2.5 输入 $0.40/百万 token,输出 $2.00;Pro 版输入 $1.00,输出 $3.00。最刺激的是 UltraSpeed 模式,部分新用户会被随机分配到 1000 tokens/s 的输出速度,基于 MiMo-V2.5-Pro。这个价格在旗舰模型中极有竞争力,翻译过来就是:小米不打算靠 token 差价赚钱,要先圈开发者。
什么时候用,什么时候别用
| 场景 | 典型用户 | MiMo Code 的优势 | 现实局限 |
|---|---|---|---|
| 长周期多步骤开发 | 个人开发者/小团队 | checkpoint rebuild + Goal 验证保证连续性 | V0.1.0 稳定性不足,bug 多 |
| 多项目并行维护 | 独立开发者 | Global 记忆跨项目生效 | 记忆系统学习成本高 |
| 自动化 CI/CD 集成 | DevOps 工程师 | Compose 模式全自动开发周期 | Dynamic Workflow 仍是实验功能 |
| 语音编程 | 偏好免手操作的开发者 | 基于 MiMo ASR 的实时流式语音输入 | 依赖小米语音服务,配置复杂 |
不适用的情况也很明确。你只是想给日常编码加个 AI 补全,不需要 Agent 自主执行复杂任务。用 Cursor 或 GitHub Copilot 更合适,MiMo Code 的设计重心是长周期自动化,日常辅助不是它的主场。你对数据隐私极其敏感。即使关闭遥测,工具仍会自动检查更新。代码上下文需要经过小米服务器(使用 MiMo 模型时)。你的硬件是老款 Mac 或 Windows Server 2019。Issue 区有明确兼容性问题报告。
一个值得注意的信号:MiMo Code 默认开启 telemetry,向 tracking.miui.com 发送包括正在使用模型在内的指标信息。可以通过环境变量 MIMOCODE_ENABLE_ANALYSIS=false 关闭,但”默认开启且命名为 analysis”的设计在开发者社区引发了隐私争议。
社区怎么样了
| 指标 | 数据 | 说明 |
|---|---|---|
| Stars | 约 9.8k | 开源 9 天,增速惊人 |
| 维护团队 | 5 人核心 + 社区贡献 | Bus Factor 偏低,小米背书提供一定保障 |
| Open Issues | 200+ | PR 编号已到 #1158,涌入速度超过处理能力 |
| 协议 | MIT + 使用限制 | 代码开源,使用需遵守额外条款 |
Stars 涨得快,Issue 涨得也快。PR 编号从 #900 跳到 #1158 只用了不到十天。开发者的热情和 PR 审核的瓶颈同时暴露。
有开发者在 Issue 区指出(#1150, #1151),MiMo Code 的文档里还有大量 OpenCode 的痕迹:配置文档引用 OPENCODE_* 环境变量而非 MIMOCODE_*,插件目录文档写的是 .opencode/plugins/ 但实际只读 .mimocode/。这些品牌替换遗漏说明分支切出来之后文档清理没跟上。
InfoQ 报道了一句来自社区的点评:”OpenCode 可能是目前开源 Agent 中最成熟的那一个,只是官方看起来太忙了协调不过来 5000 多个 PR 没人审核,不知道小米那边会怎么搞。”这个担心不无道理。开源项目的 PR 涌入速度已经超过传统人工审核的极限,AI 时代的维护模式本身在被挑战。
但换个角度看,修复速度不算慢。最新提交 6 月 19 日,修复了 claude-origin MCP 跳过逻辑。前提是这个节奏能持续。
我的真实看法
我翻了一圈 MiMo Code 的 README、官方博客、Issue 区和社区讨论,得出的判断比”好”或”不好”要复杂得多。

MiMo Code 的设计方向是对的。长周期编程 Agent 的核心瓶颈确实不是模型推理能力,而是记忆连续性、状态管理和跨任务经验沉淀。checkpoint rebuild、独立 writer subagent、Goal verifier 这些设计,从架构层面解决了 Claude Code 和其他终端 Agent 用”压缩”回避的问题。
但它最大的问题不是技术,是时机。V0.1.0 放出来的太早了。5 人 2 周的 vibe coding 产物,功能骨架有了,肌肉还远没长好。自动删除全局 npm 包这种级别的 bug 出现在一个能执行 shell 命令的编程 Agent 身上,信任成本非常高。
这事还有一种解读:小米可能是故意的。Claude Code 当年也是快速 vibe 出一个产品扔到市场里,靠真实用户反馈迭代到成熟。先占坑再修路,在 AI 编程 Agent 还在抢地盘的阶段,也许比先修路再占坑更理性。但用户不是小白鼠,尤其是在你的 Agent 能删我全局包的前提下。
MiMo Code 的开源正在推动一场有意思的讨论:coding harness 到底有没有护城河。一派认为真正完成代码任务的是底层模型,coding harness 只是体验层能力。另一派指出,不同 harness 的配置、工具设计、审批机制、上下文注入方式,会显著影响最终效果。小米的立场是:harness 应该开源。用开源 harness 圈开发者,用开发者反馈优化模型,用更好的模型吸引更多开发者。这个飞轮如果转起来,可以建立一种新的护城河。
我注意到 Anthropic 走的是另一条路:通过 Claude Code 把大量订阅额度与编程使用场景绑定,不仅赚 token 收入,更是获得高价值软件开发数据。MiMo Code 用开源 + 免费模型的方式,本质上是在拆这道墙。对开发者是好事,对小米的商业化路径是挑战:如果 harness 没有护城河,那护城河只能是数据和生态。
资源地址
说完了,你该干嘛
如果你正在做需要几十轮甚至上百轮交互的复杂开发任务,MiMo Code 值得装一个跑跑看。先从 MiMo Auto 免费通道入手,别急着把生产环境交给它。重点体验 checkpoint rebuild 和 Goal 机制是不是真的让你的长任务体验比 Claude Code 更稳。这是它唯一的差异化赌注。
如果你还在观望,关注两个指标:Issue 关闭速度和 V0.2.0 的发布内容。前者告诉你小米的工程团队能不能跟上社区涌入的速度,后者告诉你团队对自己产品短板的认知是否准确。这两点决定了这个项目能不能从”5 人 2 周的 vibe coding 产物”变成真正可依赖的开发基础设施。
最后说一句我的直觉:MiMo Code 的长期竞争力不在功能列表里,而在定价和开源策略的交汇点。如果一个 coding harness 完全开源、绑定一个极致低价甚至免费的旗舰模型,它会不会重新定义 AI 编程 Agent 的竞争维度?这个问题的答案,比 MiMo Code 本身的代码质量更重要。