

你刚改完一个前端页面,提交前想确认登录流程没出问题。手工点一圈要五分钟,还得把后端先跑起来。做了一个下午的开发,最后这点验证反而是最烦人的环节。说实话,谁都不想在这上面花时间,但你又不能跳过它。
webapp-testing 就是为这个场景设计的。它是 Anthropic 官方发布的 Skill,让 Claude 这类 AI Agent 直接用 Playwright 操控浏览器,自动测试本地运行的 Web 应用。重点不在”又一个测试框架”,而在于测试脚本不是你写的,是 AI 根据你的自然语言指令自己写的、自己跑的。
GitHub 上 145k Star 证明了需求真实存在。在 Claude Skills 的十几个官方 Skill 里,它不是最炫的,不是最能秀肌肉的,但痛点抓得最准确。前端测试这件事,熟练工嫌无聊,新手嫌麻烦,正好是 AI 该无缝接手的活。
说真的,这篇文章不打算罗列所有功能。我就是把它的设计思路和工作模式拆了一遍,哪些地方做得聪明,哪些地方有局限,实际能用在什么场景里。如果你在做前端开发,或者正在搭 AI Agent 工作流,看完应该能帮你判断这个东西值不值得装。
环境准备
webapp-testing 运行在 AI Agent 环境里(Claude Code、Cursor、Windsurf 都支持),不依赖特定操作系统。核心依赖两条:Python 3.8 以上,以及 Playwright 浏览器自动化库。没有数据库,没有 Docker,外部依赖极简。
前置条件用一张表讲清楚就够了:
| 条件 | 最低要求 |
|---|---|
| Python | 3.8+ |
| Playwright | pip install playwright |
| Chromium | playwright install chromium |
| AI Agent | Claude Code / Cursor / Windsurf 等支持 Skill 的环境 |
安装 Playwright 并拉下 Chromium 浏览器之后,Skill 本身的获取方式取决于你用什么 Agent。在 Claude Code 里注册 Anthropic 的官方 Skill 市场,选择安装 example-skills 插件即可。在 Cursor 里更直截了当,把 SKILL.md 放进 .cursor/skills/ 目录,Agent 重启后自动识别。其他工具也差不多是这个流程,本质都是让 Agent 能读到这个 Skill 的指令文件。
装完之后没法像普通 CLI 工具那样跑个版本号验证。最直接的方式是在 Agent 里说一句”用 webapp-testing 帮我打开 localhost 首页,截个图”。Agent 能执行,环境就没问题。如果你用的是 Windows,建议在 WSL 或 Git Bash 里操作,PowerShell 的路径处理和 with_server.py 的 server 启动命令偶尔会打架。
操作流程
webapp-testing 的工作模式可以归结为一个决策树。看起来简单,实际上解决了一个根本问题:AI Agent 打开一个网页之前,它不知道上面有什么按钮、什么输入框。传统自动化测试靠预定义的 CSS 选择器,但 AI 需要先”看到”页面才知道怎么操作。
整个流程的入口是判断页面类型。静态 HTML 走快通道。Agent 直接读 HTML 源码找标记,生成 Playwright 脚本用 file:// 协议加载,不启动任何服务器。
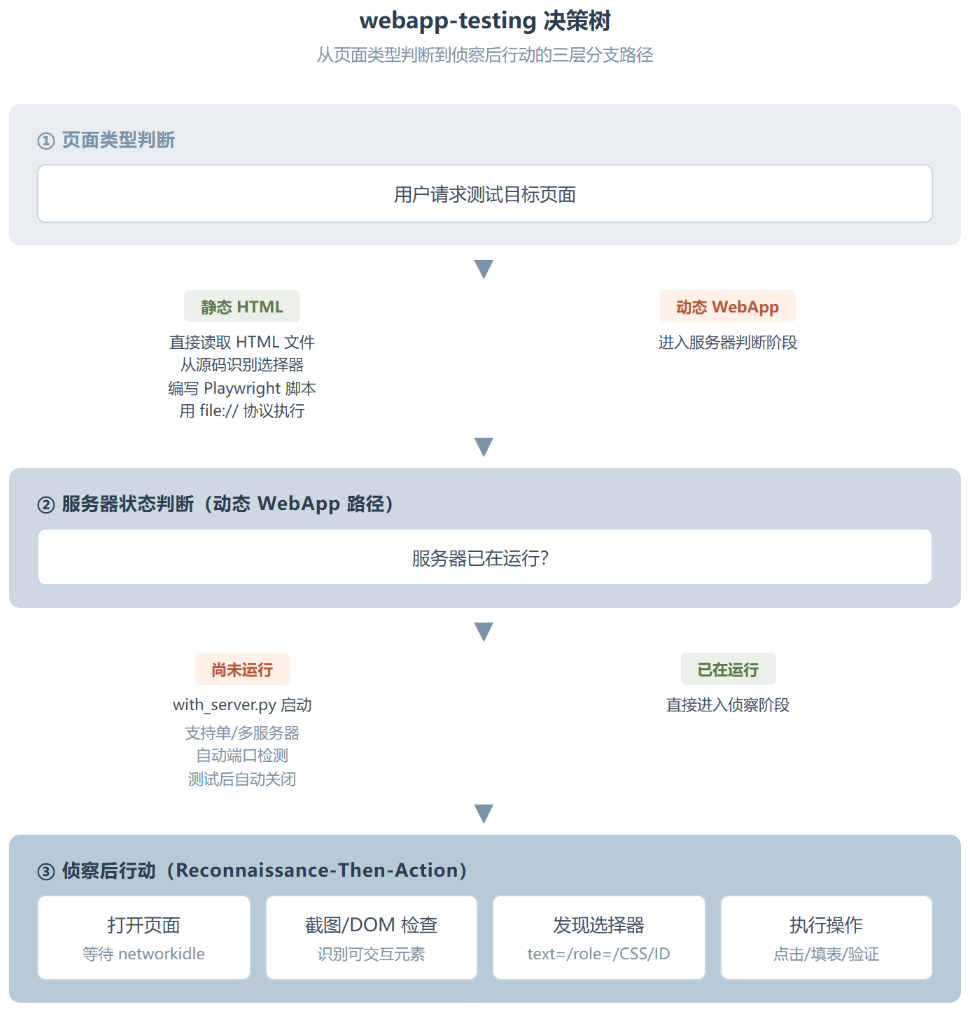
但绝大多数实际场景是你面对 React、Vue、Next.js 这种动态 WebApp。此时决策树进入第二个判断:服务器已经在跑了吗?如果没跑,用 with_server.py 一键启动:
python scripts/with_server.py --server "npm run dev" --port 5173 -- python your_test.py
这条命令做的事很干净:启动开发服务器,等 5173 端口就绪,执行你的测试脚本,测试完自动关服务器。前后端都要跑的情况也支持,加第二个 --server 参数,后端先启动再启动前端。
服务器就绪之后,进入整个 Skill 最核心的模式:侦察后行动。Agent 打开页面,等 networkidle 让所有 JS 执行完,然后截图或者 dump 出 DOM 结构。拿到渲染后的真实元素信息,才知道页面上到底有什么可交互的,最后基于实际内容生成操作脚本。
这里藏着一个很容易踩的坑。如果你在动态页面上不等 networkidle 就去读 DOM,拿到的很可能是 JS 还在跑的半成品页面,测试脚本大概率找错元素。SKILL.md 里用两段代码把这个警告讲得很透,正确做法是先等再读,顺序不能反。
这个模式在实际使用里比预期要稳。因为每一步都遵循”先看、再判断、再动手”,Agent 不是盲写选择器然后祈祷它能命中。多了一步截图或 DOM 读取的开销,但对可靠性来说,这步不可或缺。
关键设计
把 webapp-testing 的 SKILL.md 和辅助脚本拆开看,能读出几个很明确的设计意图。每一个都不是拍脑袋决定的,背后有对 AI Agent 工作方式的深刻理解。
第一个是黑盒原则。SKILL.md 反复强调先 --help 看用法、不要读源码。with_server.py 可能有数百行代码,但 Agent 只通过命令行参数跟它交互。这背后的判断很务实:Agent 的上下文窗口宝贵,把几百行 Python 塞进去只会挤占真正有用的思考空间。辅助逻辑封装成黑盒命令,Agent 只用知道调用方式,不用理解实现。
第二个是同步 API 的坚持。SKILL.md 明确要求 sync_playwright() 而非异步版本。AI Agent 写测试脚本时,它自身的推理已经是异步的了,再来一层 Python 的 async/await 只会把思考链路搞复杂。同步代码的执行顺序跟 Agent 的线性推理天然对齐:
-
打开页面 -
等待加载 -
点击按钮 -
检查结果
每一步都是上一步完成后再走下一步,不需要 await 心智模型。
第三个设计最值得拆开说:为什么要先侦察再行动,而不是直接给 Agent 可用的选择器清单?答案在动态页面的本质里。React 页面渲染后的 DOM 和源码里的 JSX 可能天差地别,CSS Modules 编译后的 class 名面目全非,有没有 data-testid 取决于开发者的习惯。没有任何通用方法能在渲染前预测选择器。侦察模式把这个不确定性转移给 Playwright 运行时,让 AI 从渲染结果里挑,而不是从源码里猜。
这几个取舍的方向很清晰:
| 设计选择 | 优势 | 代价 |
|---|---|---|
| 黑盒脚本 | 节省上下文窗口,减少 Agent 推理负担 | 定制化能力受限于命令行参数 |
| 同步 API | 代码线性可读,与 Agent 推理顺序对齐 | 无法并发操作多个页面 |
| 侦察先行 | 选择器总是基于真实渲染结果,不会跑偏 | 多步复杂流程的额外开销累加明显 |
这个设计也有明显局限。侦察步会额外增加页面加载和截图开销,对于单页应用还好,对于需要登录再多次导航的复杂流程,每一步都先侦察再行动会让整体速度明显下降。测一个完整的业务链路,比如先登录,然后点开三个菜单,再填五个表单字段,就可能出现多次重复截图。SKILL.md 没有给出复杂流程的优化策略,这是一个明显的留白。

使用场景
webapp-testing 最适合的定位不是替代你的 Cypress 或 Playwright 测试套件,而是填补测试套件覆盖不到的那些日常间隙。这些场景每天都在发生,但很少被正式测试覆盖。
开发过程中的即时验证是最高频的场景。你写了一个表单组件,想看邮箱格式不对时红色提示能不能正常显示。正常流程有几步操作:
-
切到浏览器窗口 -
手动填一个错误的邮箱 -
点提交按钮 -
看红色提示有没有出来
用 webapp-testing 一句话就能跳过这几步:“帮我在登录页用错的邮箱格式提交,确认提示变红”。Agent 会把整个过程自动跑完:
-
启动本地开发服务器 -
写 Playwright 测试脚本 -
模拟填表提交 -
截图返回结果
不需要等 CI,不需要写测试用例。
回归验证是另一个顺手的事。改了一个公共组件之后,需要在五六个页面上确认没崩。手工点一轮十分钟起步,Agent 替你跑一遍,只需要看最后结果。AI 跑测试的速度不比人快,但它不会漏页面,也不会因为烦了而跳过某个边缘情况。从实际体验来看,这种”批量确认”是这个 Skill 最有粘性的用法。
代码审查时的辅助验证是个容易被忽略的场景。Review 别人的 PR,看到前端改动,在 Agent 里说一句”用 webapp-testing 跑一下这个 PR 涉及的三个页面的关键交互,截图给我”。不用切分支拉代码装依赖,Agent 帮你全干了。社区反馈里,这恰好是用户复购率最高的场景,因为审代码时切上下文成本最高,任何一个帮你留在当前上下文里的工具都值得用。
但界限也要清楚。如果你的项目已经有完整的 E2E 测试套件,CI 里跑得稳,那 webapp-testing 的增量价值有限。它也处理不了需要 mock 外部 API 的复杂集成测试,with_server.py 只管本地服务器启动,不负责 mock 服务或数据构造。它的定位是轻量、即时、对话式的验证,不是取代测试基础设施。
洞察与反思
拆完这个 Skill 之后,一个感觉越来越强烈:Anthropic 在设计 Skills 体系时,比外界想象的要务实得多。
webapp-testing 没有炫技。它没有定义新的测试 DSL,没有提供复杂的配置格式,甚至只有 Chromium 一种浏览器引擎。它做的事极其朴素:把”AI 操控浏览器”拆成启动服务器、看页面、操作页面三步,每一步只有一个推荐做法,没有备选方案。这不是偷工减料,是理解到对 AI Agent 来说,灵活性不是资产,是噪音。选项越少,Agent 越不容易跑偏。
这恰好刺中了 AI 工具设计里一个常见的盲区。做给 AI 用的工具,设计者第一反应往往是”既然 AI 很聪明,那就什么都让它选”。但 webapp-testing 反其道而行,它把自由裁量的空间压到无法再压。Agent 不用纠结”选 CSS 选择器还是 text 选择器”,SKILL.md 直接拍板四个可用的选择器类型,各自有明确适用场景。
有一件事让我略感意外。这个 Skill 对错误处理的指导几乎是空白。Playwright 脚本跑失败了怎么办?元素没找到怎么办?超时了怎么办?SKILL.md 没有给出任何错误恢复模式或重试策略。如果 Agent 是 Claude 还好,Claude 自身的容错能力能兜底。但如果在其他 Agent 平台上使用,缺少错误处理指引可能导致脚本一步失败全盘停止。这也许是 Anthropic 默认了使用者是自己的模型,但这恰好是跨平台推广时的隐性障碍。
从整个 Skills 生态的视角看,webapp-testing 代表了一种新的工具设计范式:不为人类设计 UI,为 AI 设计 API。传统测试工具面向的是坐在屏幕前的开发者,界面里有 Test Runner、Trace Viewer、时间线回放。webapp-testing 的界面是一个 Markdown 文件里的纯文本指令,它的人类用户不直接操作它,而是通过 Agent 间接使用。这个范式如果继续成立,未来会有更多工具用同样的思路重新设计接口。
资源地址
| 资源 | 地址 |
|---|---|
| Smithery 页面 | https://smithery.ai/skills/anthropics/webapp-testing |
| GitHub 仓库 | https://github.com/anthropics/skills/tree/main/skills/webapp-testing |
| Agent Skills 标准 | https://agentskills.io |
总结
webapp-testing 做的事情不复杂,但方向足够精准。AI Agent 能操控浏览器这件事一旦稳定下来,能省掉前端开发里大量零碎却必要的验证工作。它不是来替代 Cypress 或 Playwright 测试套件的,而是来填补”手动点几下确认没问题”和”等 CI 跑完测试”之间的那片空白地带。
如果你已经在用 Claude Code 或 Cursor,装一个试试,不需要配置文件,不需要额外依赖,说一句话就能跑。在切分支改组件审 PR 的时候让 Agent 帮你验证,省下来的时间留给真正需要你判断力的事。
把这个问题留给你:你现在项目里手工验证占开发时间的比例是多少?如果 AI 能替你跑掉一半,剩下的时间你会拿来做什么?