
你是不是也有过这种经历:写完一段代码,准备提交,光标停在 commit message 那一行,突然卡住了。feat 还是 fix?scope 要写吗?描述怎么措辞才规范?想了 30 秒,最后打了一个 “update” 了事。第二天回看 git log,完全想不起来这条 commit 到底改了什么。
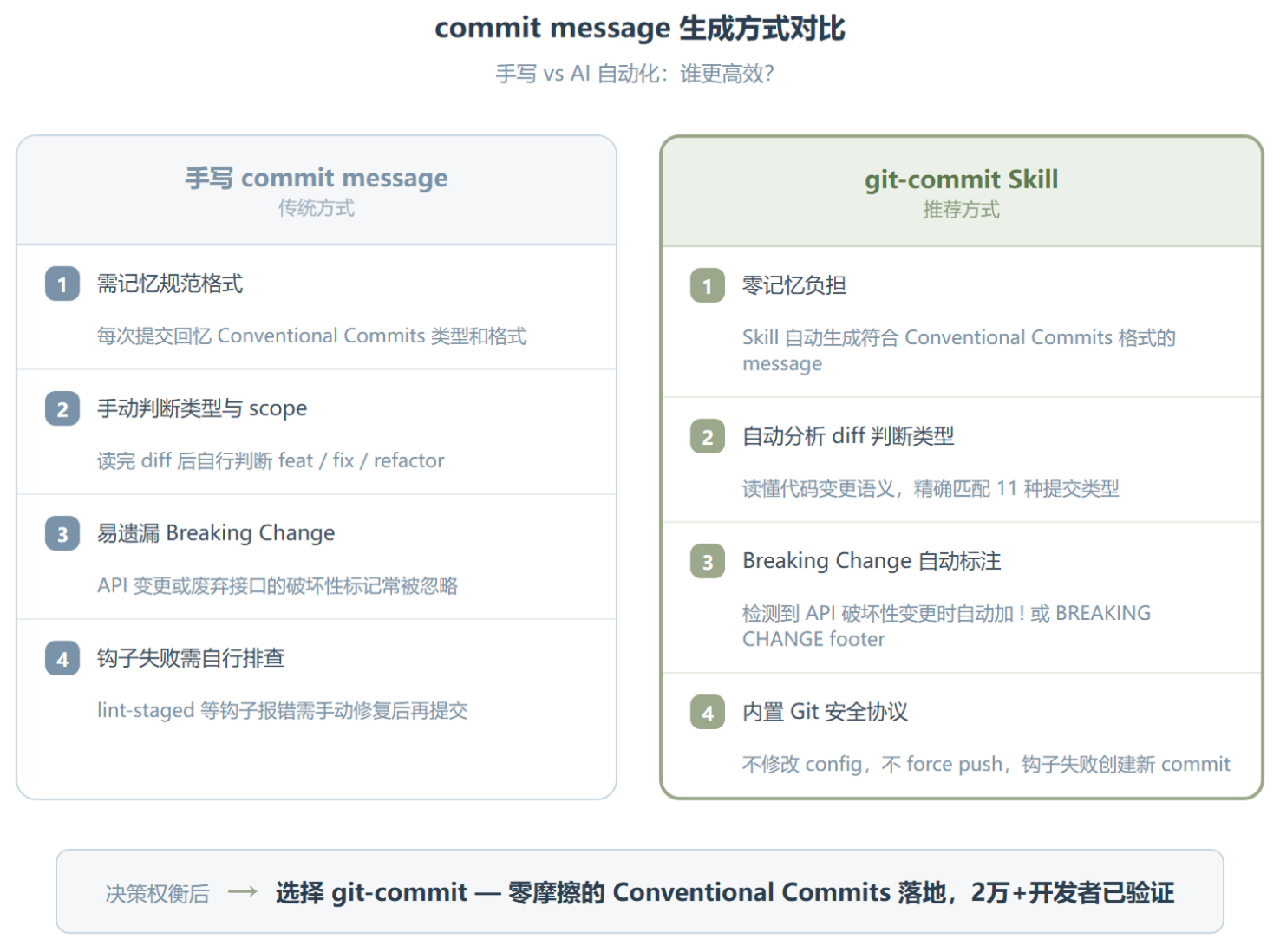
这个问题困扰过几乎所有开发者。Conventional Commits 规范已经存在好几年了,Angular、Vue 这些头部项目都在用,但真正在自己项目里坚持下来的没几个。不是规范不好,是手动遵守太费心力。人在写完代码之后的第一需求是”赶紧提交”,不是”写一篇规范的提交说明”。
git-commit 这个 Smithery Skill 做的事情很简单:你把代码改完,对它说一句”帮我提交”,剩下的它全包了:
-
看 diff:自动分析暂存区或工作区的代码变更 -
判断类型:识别 feat / fix / refactor 等提交类型 -
生成 message:输出符合 Conventional Commits 规范的描述 -
执行 commit:调用 git commit,处理钩子和异常
整个流程从你纠结的两分钟变成了两秒钟。目前在 Smithery 平台上已经有超过 2 万次下载。
说白了这篇文章就想讲明白一件事:Conventional Commits 落不了地的病根不在规范本身,在流程摩擦。git-commit 这种用 AI 读懂 diff 再生成 message 的方式,可能是目前最接近”零摩擦”的解法。往下走一遍它的工作流,你大概就理解为什么这么多人愿意把 commit message 交给一个 Skill 来写了。
环境准备
git-commit 的前置条件比你想象的要少。它不依赖本地安装,不需要 npm 包,不需要在你的项目里加任何配置文件。唯一的硬性要求是你的 AI 编程助手已经接入了 Smithery 平台。目前支持的工具有:
-
Cursor -
Claude Code -
GitHub Copilot -
文心快码、腾讯云 CodeBuddy 等国内平台
获取方式也很直接。在 Smithery 的 Skill 市场里搜 “git-commit”,点一下安装就行。不用配 API key,不用改环境变量,甚至不需要单独注册账号,如果你已经在用这些 AI 编程工具,Skill 直接挂在你的现有工作区里。
验证环境就绪的方式就是直接触发一次。在你的 AI 编程工具里输入 /commit 或者直接说”帮我提交代码”,如果 Skill 响应了并开始询问当前工作区的 git 状态,就是装好了。这一步通常不会卡,但有一个细节值得注意:确保你的工作目录是一个有效的 git 仓库,并且至少有一个文件发生过变更。空仓库或者没有任何变更的工作区会让 Skill 直接返回”nothing to commit”。
还有一个容易踩的坑:git-commit 不会帮你初始化 git 仓库。如果你的项目还没 git init,先手动跑一遍。Skill 的定位是”提交辅助”,不是”git 初始化向导”,这个边界划得很清楚。
操作流程
触发之后,git-commit 的第一个动作不是生成 message,而是先搞清楚你到底改了什么。它会跑两条命令:git diff --staged 看暂存区,git diff 看工作区。如果暂存区是空的,它会自动切到工作区变更。这个”先探查再行动”的逻辑比直接假设”你应该已经 staged 了”要实用得多。
git diff --staged
git diff
git status --porcelain
第二步是智能暂存。这是整个工作流里最容易被低估的环节。git-commit 不是无脑 git add .,它会按逻辑分组暂存。比如你同时改了 Button.tsx 和 Input.tsx,它会识别出这两个文件属于同一个 UI 模块,自动归到一次提交里。如果你还改了一个完全不相关的 auth.ts,它会建议你拆成两次提交。
git add src/components/Button.tsx src/components/Input.tsx
第三步才是生成 message。Skill 会分析 diff 的实际内容来判断类型:新增了函数签名 → feat;修了一个空指针 → fix;改了 README → docs;重构了一堆逻辑但行为不变 → refactor。它不是在做简单的关键词匹配,而是真正在”读”代码变更。生成的 message 类似 feat(ui): add Button and Input base components,格式规范,描述准确。
最后一步执行提交。单行 message 用 git commit -m,多行(带 body 或 footer)用 heredoc 方式传入。如果你的项目配置了 commit 钩子(比如 lint-staged),Skill 会正常触发它们。如果钩子失败了,它会创建一个新 commit 而不是 amend,保持历史记录的完整性。
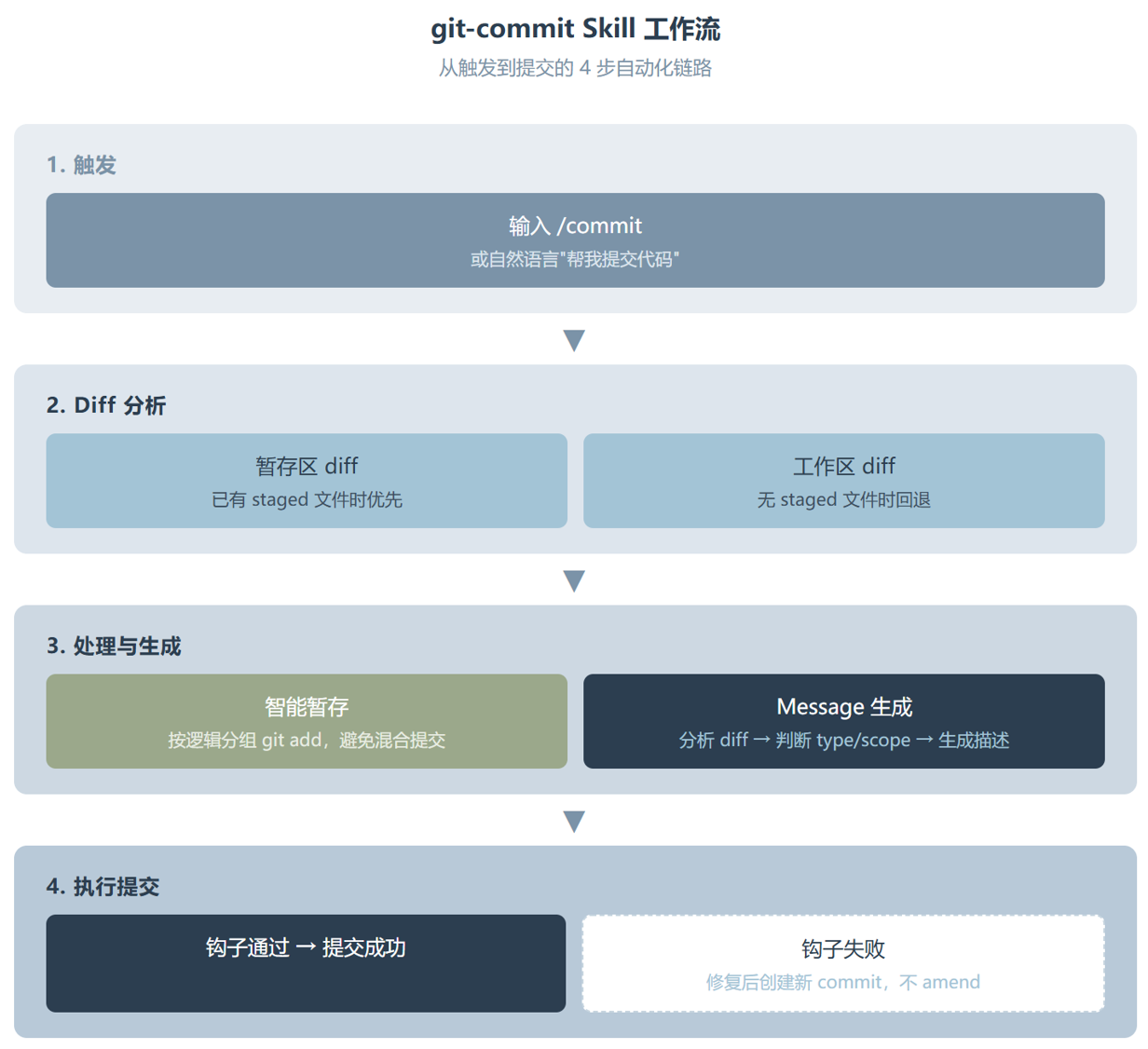
整个流程走下来,你只需要做一件事:告诉它”提交”。剩下的全部自动完成:
-
diff 分析:自动判断变更范围和性质 -
类型判断:feat / fix / refactor 等十一类自动匹配 -
scope 识别:从文件路径推断影响模块 -
message 措辞:生成符合 Conventional Commits 格式的描述 -
暂存分组:按逻辑模块拆分文件,避免混合提交 -
钩子处理:正常触发 hooks,失败时创建新 commit 而非 amend。如果你习惯了手动写 commit message,第一次用的时候会有一种”这就好了?”的不真实感。
关键设计
git-commit 最值得拆的设计不是 message 生成,是它的安全协议。这个 Skill 内置了一整套”不可逾越”的边界:不修改 git config,不执行 force push,不禁用钩子(除非你明确要求),不对 main/master 做危险操作。这些不是建议,是硬编码在 Skill 逻辑里的拒绝规则。
常规提交类型覆盖了全部日常场景:
-
feat/fix/docs/style/refactor/perf/test/build/ci/chore/revert
十一类提交类型听起来多,实际用的时候你不需要记。Skill 会自己判断,你唯一要确认的是它判断得对不对。
Breaking Change 的处理方式也值得单独说。如果你改了 API 签名或者删了废弃接口,Skill 会在 message 里自动加感叹号标记或 BREAKING CHANGE footer。比如你删除了一个旧的 /v1/users 端点,生成的 message 会是 feat(api)!: remove deprecated /v1/users endpoint。这个细节对依赖语义化版本的团队尤其关键,因为它会直接影响版本号的 major 升级判断。
但设计上也有取舍。git-commit 不帮你做交互式暂存(git add -p),它假定你会把代码改到”可以提交”的状态后再触发。如果你习惯在同一个文件里混着改 bug 和新功能,你需要自己先拆好。这是个合理的取舍:让 Skill 替你决定”哪些行该归到哪个 commit”这件事,AI 目前还做不好,强行做反而会引入更多误判。
使用场景
个人项目快速迭代是最直接的场景。你一个人在写一个 side project,commit message 写得再烂也没人看。但用 git-commit 之后你会发现,哪怕只是给自己看的提交历史,规范格式也让回溯效率提高了一大截。三个月后回来改代码,feat(auth): add OAuth2 login 比 update 有用一百倍。
团队协作场景下的价值更明显。新人加入项目不熟悉你们的提交规范,甚至不熟悉 Conventional Commits 本身,没关系,让 Skill 帮他生成。统一格式的 commit history 让 code review 的时候 reviewer 能快速定位每个 commit 的变更范围,不用从 diff 里反推”这一坨到底干了什么”。
开源贡献也是硬需求。给知名项目提 PR,不规范或过于简略的 commit message 会被直接要求修改。git-commit 生成的 message 天然符合 Conventional Commits 标准,你不需要额外学习 Angular 项目或 Vue 项目的提交规范。一次过关的概率远高于手写。
配合 CI/CD 流水线,这套工作流能直接驱动自动发版。semantic-release 之类的工具会解析 commit history 里的 feat / fix / BREAKING CHANGE 标记来自动决定版本号升级(patch / minor / major),完全不需要人工干预版本号。从代码提交到版本发布,全链路自动化。
洞察与反思
从这个 Skill 的设计反推,Conventional Commits 推广了这么多年却落地率不高,根本原因终于浮出水面了:规范本身没问题,问题出在”人”和”规范”之间缺了一层自动化。就像 ESLint 不是因为大家不会写规范代码才流行的,而是因为它把规范检查从”自觉遵守”变成了”自动执行”。
说实话,把 git-commit 跟 commitizen 和 commitlint 放在一起看,差异会更清楚。commitizen 是交互式问答,你得手动选 type、填 scope、写描述,本质上是帮你格式化但不是帮你”思考”。commitlint 是事后校验,你写完了它告诉你对不对,但不帮你写。git-commit 做的是”你改了什么代码,我帮你写成什么 message”,省掉的是”判断”这一步。
但这不是说 git-commit 就完美了。从文档逻辑推断,它在复杂混合变更场景下的表现应该会有波动。如果你一次改了五个文件,分别涉及 feat、fix、refactor 三种类型,Skill 需要做比较复杂的分类判断。目前的最佳实践是”一次只做一件事”,但实际开发中很少有人能做到这种颗粒度的提交拆分。
从趋势来看,这种”AI 读懂代码变更再生成元信息”的模式不太可能只停留在 commit message 上。PR 描述、Release Notes、Changelog 这些跟代码变更紧密相关的内容,理论上都可以用同样的思路自动生成。git-commit 把最难啃的第一块骨头啃下来了。
| 资源 | 地址 |
|---|---|
| Smithery | https://smithery.ai/skills/github/git-commit |
总结
回到开头那个场景:写完代码,光标停在 commit message 输入框,大脑一片空白。git-commit 把这个两分钟的纠结压缩到了两秒。省下来的不是时间,是心力。
如果你已经在用 AI 编程助手,git-commit 几乎是零成本接入。装好之后它安静地待在后台,等你需要提交的时候说一句话就行。不需要学新工具,不需要改工作流,不需要说服团队。你只管写代码,它负责写历史。
但有个前提你得接受:把 commit message 的控制权交出去,意味着你要信任一个 Skill 对代码变更的理解能力。在大多数常规场景下它做得足够好,在极端复杂的混合变更场景下可能需要你手动介入。这跟所有 AI 工具一样,它擅长的是减少”常规决策”的消耗,不是消灭”所有决策”。想清楚这一点,你就知道什么时候用它、什么时候自己来。