
你有没有在选股的时候,被 ROE、流动比率、EV/EBITDA 这些指标绕晕过?数据都摆在那,利润表、资产负债表、现金流量表三张表看着挺全,但一到手算比率就烦。不是不会算,是每次都要翻公式、建 Excel 模板、再人工核对,一套流程下来半小时没了。
Anthropic 在 claude-cookbooks 仓库里放了一个叫 analyzing-financial-statements 的 Skill,专门解决这个痛点。它的核心逻辑很简单:你给财务数据,它吐出六大类比率加解读。不需要开 Excel,不需要背公式,直接在 Claude 对话里完成整条分析链。
说真的,这个 Skill 本身的代码量很小,两个 Python 脚本加起来不到 500 行。但它的设计思路挺值得拆一拆的,尤其对于想在 AI Agent 里嵌入轻量金融分析的人。这篇文章就从安装开始,一步步拆它的工作流、架构设计和实际表现。
环境准备
这个 Skill 不挑环境,不依赖外部 API,不需要数据库。本质上就是一个纯 Python 的财务比率计算器,运行在 Claude Agent 的代码执行沙箱里。两个核心脚本 calculate_ratios.py 和 interpret_ratios.py 不访问网络、不读写文件、不调用外部命令,Skillstore 的安全审计给了全部通过。
获取方式有三种。最直接的是 Claude Code 插件市场,一行命令注册:
/plugin marketplace add anthropics/skills
然后搜索 analyzing-financial-statements 安装就行。Claude.ai 付费用户已经内置了这些 Skill,不需要额外安装。如果你用的是其他支持 Agent Skills 的客户端,从 Smithery 或 Skillstore 下载 ZIP,扔到项目的 skills 目录里就行。
唯一的前置条件是你得有财务数据。这个 Skill 支持四种输入格式:
-
CSV,带财务行项目 -
JSON,结构化财务报表 -
纯文本,描述关键财务数字 -
Excel 文件,含财务报表
从源码的数据结构设计来看,它期望的 JSON 格式分了四个独立模块:
-
income_statement(利润表) -
balance_sheet(资产负债表) -
cash_flow(现金流) -
market_data(市场数据)
如果你的数据只有一个净利润数字和股价,它能算 P/E,但大部分比率需要更完整的输入。准备数据的时候,至少要把利润表的收入和净利、资产负债表的流动资产和负债、以及市场数据的股价和流通股数这几个字段填上。
操作流程
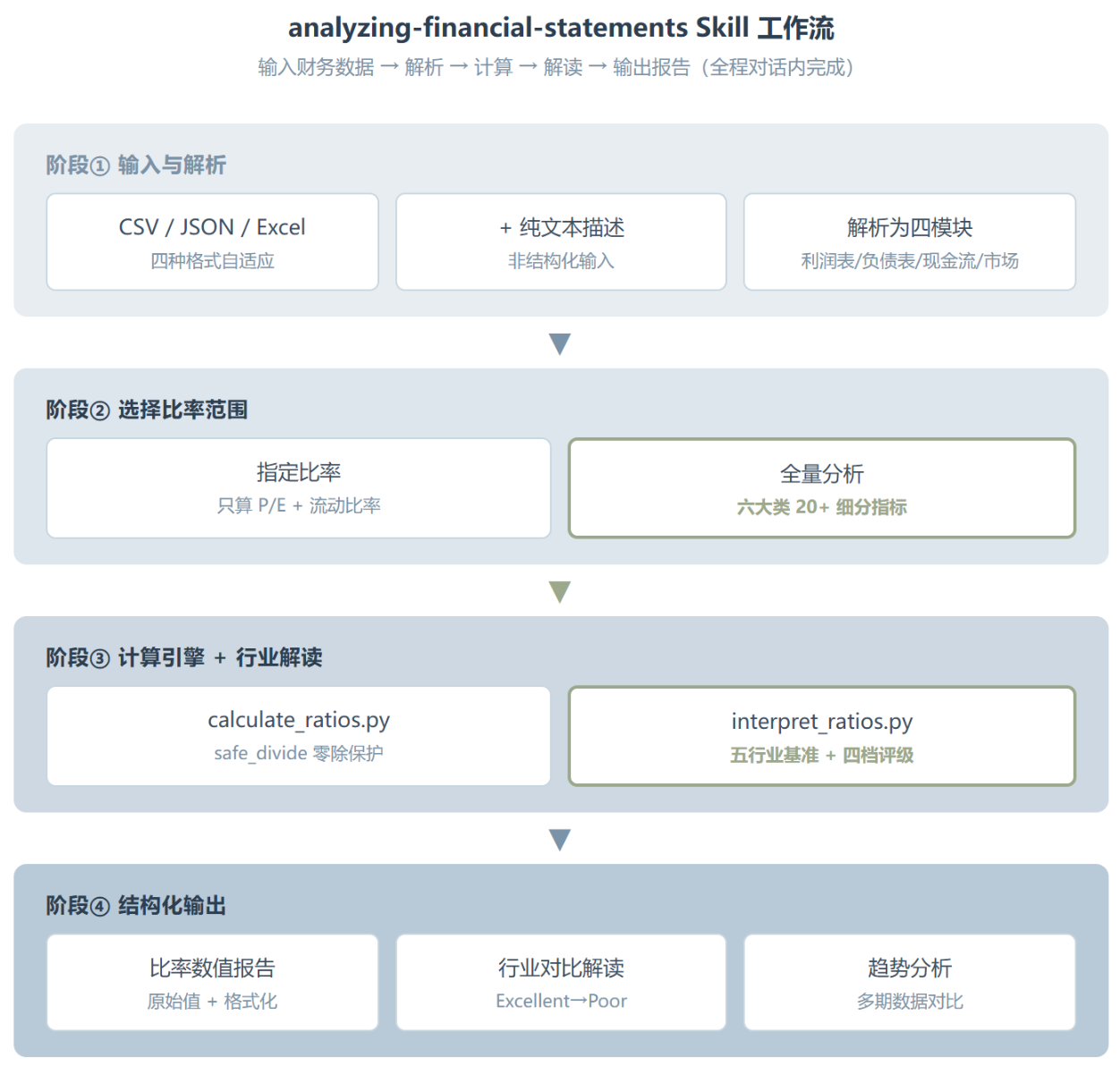
整个 Skill 的运作链路比表面看起来多一层,这也是它和”直接让 AI 算”的核心差异。
第一步,输入数据。不管你是贴 Excel 还是丢 JSON,Agent 先把数据解析成规范化的四个字典,income_statement、balance_sheet、cash_flow 和 market_data。这个设计有个细节,cash_flow 在当前的比率计算里其实用不上,calculate_ratios.py 里没有引用 cash_flow 模块。它被预留出来,大概是给未来的自由现金流分析留的口子。
第二步,选择要算的比率。你可以指定只算 P/E 和流动比率,也可以让 Skill 跑全量分析。全量模式会覆盖六大类:
-
盈利能力(ROE、ROA、毛利率、营业利润率、净利率) -
流动性(流动比率、速动比率、现金比率) -
杠杆(D/E、利息覆盖倍数、偿债保障比率) -
效率(资产周转率、存货周转率、应收周转率) -
估值(P/E、P/B、P/S、EV/EBITDA、PEG) -
每股指标(EPS、每股账面价值、每股股息)
总共 20 多个细分比率。看源码会发现每个比率都用 safe_divide 包装过,除零不崩,返回 0.0 并继续算下一个。
第三步是计算加解读,也是最值得讲的一层。计算本身没什么黑科技,就是标准金融公式的 Python 实现。但计算完成后,interpret_ratios.py 接手做了一个大部分手工分析懒得做的事:行业基准对比。它在代码里硬编码了五个行业的基准值:
-
科技 -
零售 -
金融 -
制造 -
医疗保健
每个行业对以下五个核心比率各有一套四档评级(Excellent / Good / Acceptable / Poor):
-
current_ratio(流动比率) -
debt_to_equity(负债权益比) -
roe(净资产收益率) -
gross_margin(毛利率) -
pe_ratio(市盈率)
举个例子,零售行业流动比率 1.5 是 Good,但放到科技行业只是 Acceptable,因为科技公司天生轻资产、现金多,基准线划在 1.8。这个差异如果你不熟悉对应行业,自己算完比率很可能误判。Skill 把这个环节自动化了,省掉了查行业 benchmark 的时间。
整条链路跑完,输出是一个结构化的 JSON 结果,包含原始值、格式化数值和文字解读。如果给了多期数据,还会附上趋势分析,标注每个比率是改善还是恶化。
关键设计
两脚本分离的设计是这个 Skill 最巧妙的地方。calculate_ratios.py 只管数学,interpret_ratios.py 只管语义,两者通过 dict 交互,互相不依赖。这带来了一个实际好处:你可以只换一个模块不换另一个。如果你想用自己的行业基准数据,改 interpret_ratios.py 的 BENCHMARKS 字典就行,计算层完全不受影响。
硬编码行业基准这个选择挺有意思,它暴露了这个 Skill 的定位边界。五个行业的基准值显然覆盖不了所有场景,金融行业还好,制造和医疗也算常见,但如果分析的是 SaaS 公司,科技行业的基准可能就不够精准。这不是偷懒,是故意把复杂度控制在”够用就行”的水平。你要更精细的,自己加一行字典的事。
safe_divide 这个函数只有四行代码,但它是整个计算引擎的基石。所有比率计算都通过它走,除零返回 0.0,不会因为缺数据让整条链路崩掉。不过这里也有一个值得注意的选择,返回 0.0 而不是 None 或 NaN,意味着你没法从结果上区分”这个比率本身就是 0″和”分母缺数据所以返回默认值”。从实用角度看,大部分场景下影响不大,但做严谨量化分析的时候得留个心眼。
另一个设计亮点是 summary 生成逻辑。generate_summary 函数从几大类比率中各挑一个最关键的指标,拼成一段英文摘要。代码里写死了文案模板,每个比率的值映射到固定的评级词 strong / moderate / potential / conservative。结果就是同样的 D/E 0.33,不管分析哪个公司,输出都是”indicates conservative leverage”。模板化在这里不是 bug,是 feature,保证了一致性,也避免了 AI 生成摘要时可能出现的幻觉。

使用场景
最直接的应用场景是快速股票筛选。假设你在做一个基本面扫描,手里有几十家公司的财务数据,每家手动算 ROE 和流动比率再对比行业基准,一套下来几个小时。用这个 Skill,把数据整理成 JSON 丢进去,一次性跑全量比率加行业解读,几分钟的事。
举个例子,给一段标准财务数据:
{
"income_statement": {"revenue": 1000000, "net_income": 150000, "cost_of_goods_sold": 600000, "operating_income": 200000},
"balance_sheet": {"total_assets": 2000000, "current_assets": 800000, "current_liabilities": 400000, "total_debt": 500000, "shareholders_equity": 1500000},
"market_data": {"share_price": 50, "shares_outstanding": 100000}
}
Skill 输出的核心比率:
-
ROE:10.0%(偏低,低于行业平均) -
流动比率:2.00(流动性强) -
D/E:0.33(低杠杆,保守) -
净利率:15.0%(高于行业平均)
这种交叉判断手动做起来麻烦,自动化之后就是一句话的事。
第二个场景是财务健康快速诊断。给一家公司的三张表,Skill 按四档打分制输出每个比率的评级,Excellent / Good / Acceptable / Poor。跑完一看,盈利能力全是 Good 以上但流动性亮了红灯,问题就锁定了。比从头到尾翻财报快得多,特别适合投资研究里的第一轮过滤。
不过它不适合做深度建模。DCF 估值、蒙特卡洛模拟、情景敏感性分析这些,不是这个 Skill 的设计范围。它的核心使用场景就是”给我一个快速的、有行业对比的比率概览”,仅此而已。把它当轻量基本面扫描工具用,定位是对的;当专业金融终端用,会失望。
洞察与反思
从架构角度看,这个 Skill 的设计哲学很明显:克制。两个脚本、五个行业、四档评级,没往上堆功能。对比市面上一些金融数据分析 Skill,动辄声称覆盖几百个指标、集成实时行情,结果连基础的零除保护都没做好。这个 Skill 在”知道自己能干什么”这点上做得很清醒。
但硬编码基准确实是个双刃剑。五个行业的 benchmark 更新全靠人工改 Python 源码,没有动态更新机制。2025 年的基准放到 2026 年底,某些行业的 D/E 合理区间可能已经变了。特别是在利率周期剧烈波动的环境下,基准的时效性是个真实存在的风险。Skill 文档自己也说了”行业基准仅为一般性指导”,这话不全是免责声明。
比较反直觉的一点是它没用到 cash_flow 模块。conventional wisdom 告诉我们自由现金流是估值里至关重要的变量,但这个 Skill 的估值模块只用了利润表的 EBITDA 和净利。FCF 相关的指标要你自己加。不是做不到,是设计者选择先把基本盘做好。从产品角度,这个选择是合理的,一旦开始加 FCF,就得面对经营现金流调整、资本支出分类这些远比比率计算复杂的问题。
对普通投资者或非金融背景的 AI 用户来说,这个 Skill 最有价值的不是”它算了什么”,而是”它告诉你的这些比率是什么意思”。大部分人知道 P/E 越高越贵,但不知道科技行业 P/E 45 可能只是合理溢价、而零售行业 P/E 35 已经偏贵。行业基准层把这种隐性知识显性化了。
我对这个 Skill 最大的保留意见不在功能上,在于它的交互设计。目前的所有输出是 JSON 字典,没有可视化,没有图表。一堆数字放在那,解读文本虽然有用但不够直观。如果能加一个简单的 matplotlib 图表输出,把比率随时间的变化画出来,实用价值会高很多。这不是复杂功能,但比再多加 10 个比率的边际收益大得多。
资源地址
总结
analyzing-financial-statements 是个轻量但认真做事的 Skill。它不试图取代专业金融终端,而是在”快速比率分析加行业解读”这个窄切口上做到了可靠。两脚本分离的架构让它易于定制,硬编码基准虽然不够灵活但保证了门槛足够低。
如果你日常做轻度基本面分析,特别是需要跨行业快速对比的时候,这个 Skill 能省不少重复劳动。但如果你需要的是 DCF 建模、FCF 深度拆解或者实时行情联动,它不是你该选的工具。
把它当成财务分析的”快速筛选层”来用,定位就对了。真正值得深挖的公司,还是要回到完整的模型和数据里去。这个 Skill 帮你的,是在那之前帮你筛掉 80% 不值得花时间的标的。