

做数据可视化的时候,最花时间的环节是什么?不是写代码。matplotlib 那几行画图代码闭着眼都能敲出来。真正让人卡住的,是站在一堆数据面前不知道选什么图。
常见图表类型你都认识:
-
折线图 -
柱状图 -
散点图 -
热力图 -
箱线图
但”这个数据到底该用哪个”这件事,大多数人靠的是经验和直觉。直觉不靠谱的时候,就来回试,试到看得顺眼为止。这种”凭感觉选图”的工作方式,效率低不说,还容易选错。选错图的后果比没画图更糟,它会把正确的数据包装成错误的结论。
Anthropic 在它们开源的 skills 仓库里放了一个叫 data-visualization 的 Skill。表面上看是个教 Claude 画图的工具包。但翻完它的 SKILL.md 之后发现,这玩意教的根本不是画图。它在教”怎么想”,拿到一组数据之后,从哪个角度拆、用哪种关系呈现,才能让读者一眼看明白。
说真的,这篇文章不打算把这 Skill 当说明书讲。我是想把它的设计思路拆开给你看:它怎么把选图这件靠直觉的事,变成一套可以复制、可以检查、可以教给别人的规则。如果你也在频繁做数据可视化,这套方法论能让你少踩不少坑。
环境准备
这个 Skill 出自 Anthropic 官方的 skills 仓库。整个仓库 2026 年 5 月 17 日开源,三天冲到 138k Star。data-visualization 属于其中的 knowledge-work-plugins 子集,在 Smithery 平台上有 146 次安装,安全评分 100 分,GitHub 上关联的仓库更是积累了超过 11k Star。
安装不复杂,前提条件也少。需要的就是 Python 环境加三个库:
| 依赖 | 用途 |
|---|---|
| Python 3.x | 运行环境 |
| matplotlib + seaborn | 静态图表生成 |
| pandas | 数据处理 |
| plotly(可选) | 交互式图表 |
在 Claude Code 里跑一行命令就装好了:
npx skills add https://github.com/anthropics/knowledge-work-plugins --skill data-visualization
Claude.ai 付费用户更省事,这个 Skill 已经预置在系统里,不用手动装。如果你的环境里缺了上文那几个 Python 库,pip install 一条龙补上就行,两分钟的事。唯一可能卡住的是网络环境,GitHub 拉不下来就得多试几次。
操作流程
这个 Skill 的核心使用流程分四步。每一步单独看都不复杂,但连起来是一条完整的”从数据到图表”的决策链。
第一步,也是最容易跳过的,是判断数据关系。大多数人的习惯是拿到数据脑子里直接蹦出一个图类型,然后开始写代码。但 Skill 强制你先回答一个问题:“这组数据在讲什么?”
-
趋势变化 -
类别对比 -
分布形态 -
相关性
这个问题答对了,后面的每一步都是水到渠成。答错了,技术再漂亮也是白搭。
SKILL.md 里给了一张 13 种数据关系的对照表,每种关系对应首选图表和备选方案。这张表本身就是一个浓缩版的选图方法论:
| 展示什么 | 首选 | 备选 |
|---|---|---|
| 随时间变化的趋势 | 折线图 | 面积图 |
| 类别间的对比 | 纵向柱状图 | 横向柱状图、棒棒糖图 |
| 排序 | 横向柱状图 | 点图、斜率图 |
| 部分与整体构成 | 堆叠柱状图 | 树图、华夫图 |
| 随时间变化的构成 | 堆叠面积图 | 百分比堆叠柱状图 |
| 分布形态 | 直方图 | 箱线图、小提琴图 |
| 双变量相关性 | 散点图 | 气泡图 |
| 多变量相关性 | 热力图 | 配对图 |
| 地理分布 | 等值线地图 | 气泡地图 |
| 流程或过程 | 桑基图 | 漏斗图 |
| 关系网络 | 网络图 | 弦图 |
| 绩效对标 | 子弹图 | 仪表盘 |
| 多指标一览 | 小多组图 | 多图仪表板 |
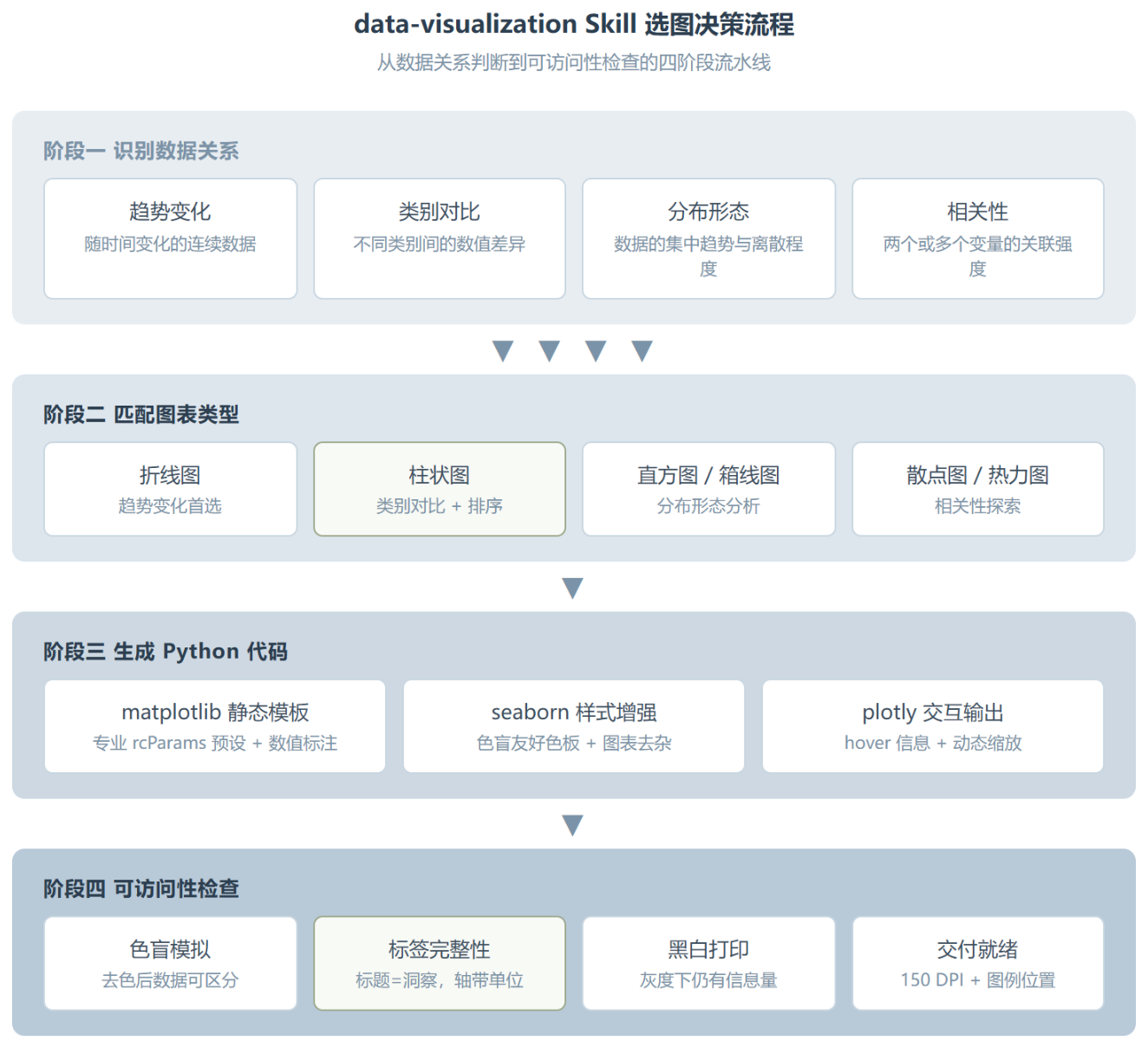
第二步和第三步是写代码、调样式,基本是流水线操作。Skill 给每种图表都配了完整的 Python 代码模板,不是那种入门示例级别的,而是带了全套配置的成品代码。你仔细看会发现它做了几件事:
-
预设了色盲友好的专业色板 -
去掉了不必要的图表垃圾(边框、背景网格) -
在关键数据点上加了数值标注 -
统一了 rcParams 预设,字号、线宽、DPI 全部标准化
你把数据塞进去,图表直接就能用,不需要再从零调样式。
第四步容易漏掉:可访问性检查。色盲友好吗?去掉颜色还能区分数据系列吗?标题说的是”洞察”还是”废话”?打印出来黑白的能看吗?这些检查项列成了一个清单,每完成一张图过一遍。这种”交付前检查”在数据可视化工具里很少见,但你仔细想想,它应该是标配。
关键设计
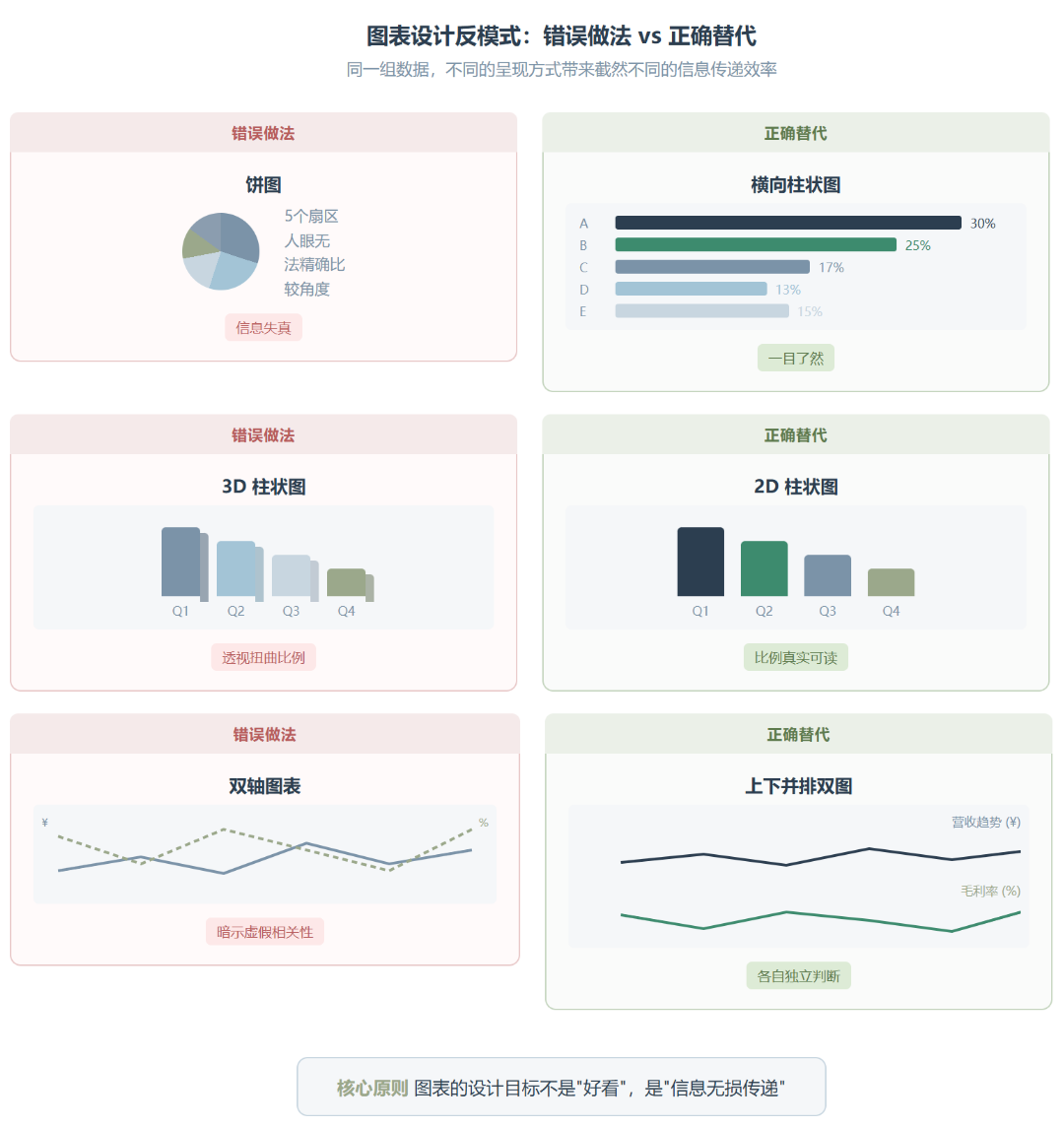
翻完这个 Skill 的完整内容,有一个设计选择让我觉得特别聪明。它没花太大篇幅告诉你”应该用什么”,而是用大量篇幅告诉你”千万别用什么”。SKILL.md 里列了一组反模式,每个都绑定了具体的后果:
-
饼图:人类不擅长比较角度。超过 6 个扇区基本只能看出最大的那个。用柱状图替代 -
3D 图表:永远别用。它只加了一个维度的”深度幻觉”,但扭曲了真实的数据比例 -
双轴图表:容易暗示不存在相关性。如果非要用,两条轴必须明确标注 -
堆叠柱状图加多类别:中间段几乎无法比较。换成小多组图或分组柱状图 -
环形图:问题跟饼图一样。最多用来展示单个 KPI
这种”禁止清单”式的设计比”最佳实践清单”高效得多。最佳实践是散的,几十条堆在一起没人记得住。但”别干这些蠢事”每一条都记得特别牢,因为每条都连着一个具体的翻车场景。换句话说,它在用”可怕后果”驱动记忆,不是用”正确做法”。
另一个设计决策也很有意思:可访问性被放到了和设计原则同等的位置。色板里专门配了色盲友好的六色调色板,代码里写了”绝不要只靠颜色区分数据系列”的红线规则,甚至要求测试黑白打印效果。这不是为了政治正确,是实用主义:8% 的男性受众有色觉障碍,你的图他们可能完全看不懂。这种把”可访问性”从附加项升级为必检项的做法,在开源工具里相当少见。
使用场景
这个 Skill 最对口的场景是数据分析师的日常。假设你刚跑完一个季度的用户行为数据,需要在周会上展示。以前的做法是打开 Notebook,凭直觉拉几张图,老板问”为什么用折线不用柱状”的时候含糊过去。现在把数据扔给加载了这个 Skill 的 Claude,它先判断每段数据适合什么图表类型,再吐出带注释的 Python 代码。你不用在 matplotlib 文档和 Stack Overflow 之间来回跳了,专心想”这组数据到底要说明什么”就行。
另一个容易被忽略的场景是技术写作。开发者写技术博客或项目报告时经常需要配数据图,但大多数人的图表审美停留在”柱子能看出来高低就行”。这个 Skill 的代码模板自带专业样式和色盲友好的配色,生成的图直接就能塞进文章里。对比一下,一个是从零开始手写 matplotlib 还要来回调样式,一个是代码模板塞数据就跑,效率差不少。
局限也得说清楚。两点比较明显。第一,它假设你的数据已经是干净的 pandas DataFrame。现实中的数据往往是乱的、缺的、格式不对的,这些预处理它不管,你得自己搞定。第二,交互式图表的支持弱一些,虽然提供了 plotly 的代码模板,但远没有静态图表部分做得那么细致和全面。
洞察与反思
看完这个 Skill 之后最大的感受:它做的最好的一件事,不是提供了多少代码模板,而是把”选图”这件依赖经验和直觉的事,外化成了可传播的规则。
在数据可视化这个领域,大量隐性知识藏在资深分析师和设计师的脑子里。“这个场景用堆叠面积图比折线图好”“饼图超过五个扇区就废了”“颜色别只用红绿,色盲看不见”,这些经验以前只能靠口口相传和踩坑积累。这个 Skill 用一张对照表加一个反模式清单,把这些东西全系统化了。

这让我重新想了一件事:Skill 的核心价值可能不是”让 AI 替你干活”。更有价值的用法是”把人类专家的隐性知识结构化”。一个 Skill 写得越好,它越像一个经验丰富的前辈在旁边告诉你”这个别用,那个可以试试”。数据可视化尤其适合这种形式,因为它的知识结构不是线性的,是一个多条件匹配的决策网络。
但退一步讲,这个 Skill 也暴露了 Skill 模式的一个天然局限:它无法替代审美判断。选对了图类型、用对了色板、检查了可访问性,图仍然可能不好看。数据可视化的最后一步永远是人的审美直觉,这个部分目前没有任何 Skill 能覆盖。它能保证你不出错,但不能保证你出彩。这个差距短期内看不到被填平的可能性。
| 资源 | 地址 |
|---|---|
| Smithery | https://smithery.ai/skills/anthropics/data-visualization |
| GitHub | https://github.com/anthropics/skills |
总结
回到开头那个问题:做数据可视化最花时间的到底是什么?不是代码,不是选配色,是”判断”本身。判断这组数据在讲什么故事,判断哪个图表类型最擅长讲这个故事,判断这张图有没有把信息完整地传出去。
这个 Skill 做的就是把判断过程拆开,每一步给出明确的规则。它不替你做决定,但它给了你做决定的框架。对于每天都在跟数据打交道的人来说,这个框架的价值比任何代码模板都大。它让你从”我感觉应该用折线图”变成”这组数据显示的是趋势变化,折线图是标准选择”。
退一步看,这件事本身也挺有意思的:AI 用了一个 Skill,反过来帮人类把”怎么用 AI 做好数据可视化”这件事搞清楚了。技术演进有时候就是这么绕,你以为看到的是新东西,仔细一看,干的还是那件老事:把经验变成方法。