
让 AI Agent 给你做一张财务报表,它大概率会给你一个”看起来还行”的表格。但仔细一看,所有数字都是硬编码的。没有公式,没有引用关系,改了输入值其他格子纹丝不动。
这其实不是模型能力的问题。Agent 在操作电子表格时,默认行为就是”把数据填进去”,而不是”用公式把数据连起来”。openpyxl 确实能写公式,但 Agent 通常不会主动选择这样做,它需要一个明确的技能框架来告诉它:做表格的时候,公式是默认选项,不是高级功能。
openai/spreadsheet 这个 Skill 要解决的就是这件事。它不是另一个”用 Python 操作 Excel”的封装,而是一套完整的电子表格行为规范:
-
什么时候用 openpyxl,什么时候切 pandas -
公式引用怎么写,绝对引用和相对引用怎么选 -
格式怎么保留,不被 pandas 覆盖 -
交付前怎么验证,布局有没有问题
把它想成一个 Agent 专用的”电子表格 SOP”。7,309 次浏览、135 次安装,在 Smithery 上不算爆款,但属于那种用对了场景立刻能感觉到差异的工具。
说真的,这篇文章不打算逐行翻译它的 SKILL.md。我会拆它的工作流、点出几个关键设计、讲清楚它在真实场景里到底怎么改变 Agent 处理表格的方式。如果你正在让 Agent 做数据报表或财务模型,这里面的取舍应该能帮你省不少折腾。
环境准备
这个 Skill 的依赖分两层。核心层是 Python 的 openpyxl 和 pandas,处理 .xlsx 文件的读写和数据分析。渲染层是可选的。LibreOffice 把 .xlsx 转成 PDF,Poppler 再把 PDF 转成图片,让 Agent 能在交付前”看到”表格长什么样。
安装本身很简单:
npx skills add https://github.com/openai/skills --skill spreadsheet
如果你在本地手动配,Python 依赖两行搞定:
uv pip install openpyxl pandas
渲染工具需要系统级安装。macOS 上 brew install libreoffice poppler,Ubuntu 上对应 apt-get。Windows 和纯服务器环境就比较麻烦,LibreOffice 的 headless 模式需要完整的桌面依赖包。
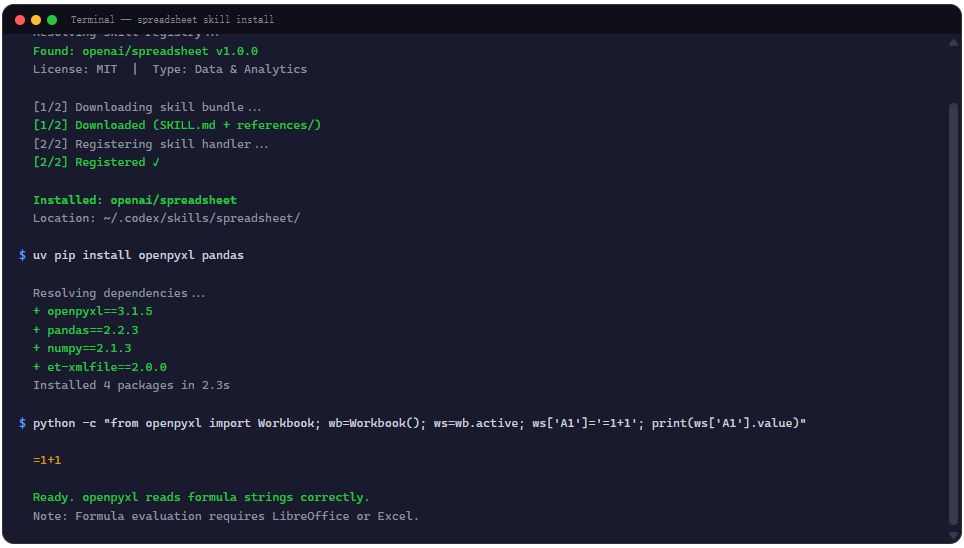
验证也直接。让 Agent 跑一段最简单的代码:创建一个 workbook,在 A1 写 =1+1,保存后用 openpyxl 读回 A1 的值。如果读到的是公式字符串 =1+1 而不是计算值 2,说明环境就绪(openpyxl 不会计算公式,这正是后面设计章节会讲到的关键点)。渲染层不存在的话也不影响核心功能,Agent 会在交付时提醒你:布局需要本地复查。
操作流程
这个 Skill 的工作流可以概括为五步,但真正有意思的不是步骤本身,而是每步里隐含的”判断点”。
第一步是确认任务类型和文件格式。新建还是修改?是 .xlsx 还是 .csv?这一步看起来简单,实际上决定了后续整个工具链的选择。新建 .xlsx 用 openpyxl 最合适,批量数据分析切 pandas 更高效,修改已有文件则两种工具可能要交替使用。这个判断如果错了,后面的操作效率会差一个数量级。
第二步是创建或修改。写 .xlsx 文件时用 openpyxl 保持格式感知。原有文件中的这些元素不会因为你的写入而丢失:
-
字体和字号 -
单元格颜色和填充 -
边框样式 -
列宽和行高
数据分析场景用 pandas 做过滤、聚合、透视,然后写回 .xlsx。这里有个很多人踩过的坑:pandas 写回 .xlsx 时默认会覆盖所有已有格式。Skill 的做法是先读原始文件的结构,再用 openpyxl 引擎做增量写入,避免 pandas 的”格式炸弹”。
第三步是公式处理。这是整个 Skill 最核心的差异化能力。Agent 不再写死数字,而是写真正的 Excel 公式。规则很明确:
-
衍生值一律用公式,不硬编码结果 -
禁用 FILTER、XLOOKUP、SORT等动态数组函数(兼容性) -
避免 INDIRECT、OFFSET等易失函数(性能) -
用绝对引用 $B$4和相对引用B4精确控制公式复制行为 -
复杂逻辑拆成辅助列,单公式尽量简单可读
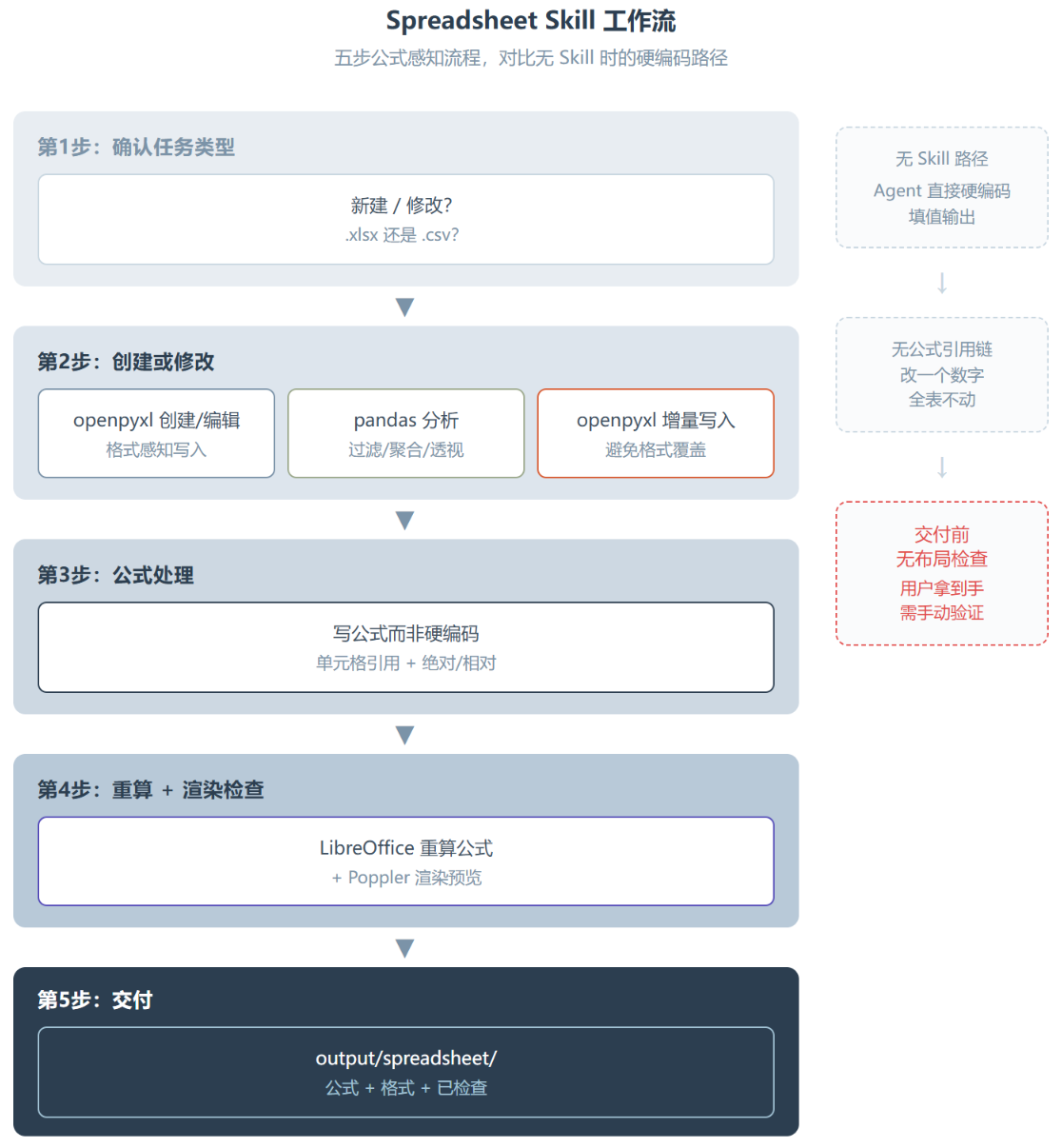
第四步是重算和渲染。openpyxl 的一个先天限制是不计算公式,它只读写公式字符串,从来不去算结果。这意味着你用一个写满公式的 .xlsx 发给别人,对方打开 Excel 或 LibreOffice 时公式才会被算出来。如果能在交付前让 Agent 自己跑一遍 LibreOffice 做重算,然后截图检查布局,就能在问题到达用户之前拦截掉。这是渲染环节存在的真正原因。
第五步是保存和清理。中间文件放 tmp/spreadsheets/,最终产物放 output/。文件名保持稳定,有描述性。听起来是细节,但在 Agent 自动化流程里,文件命名混乱是导致”找不到输出”的第一大原因。
关键设计
如果把市面上所有”让 AI 操作 Excel”的方案拉出来,大部分走的是”导出数据”路线。Agent 算好结果,扔进 CSV 或 pandas,输出完事。spreadsheet 这个 Skill 选了另一条路:保留电子表格的完整语义。
这个选择直接决定了它的技术栈。openpyxl 负责”格式感知”。它能读写以下 pandas 完全不支持的元素:
-
合并单元格 -
条件格式 -
图表 -
命名范围
但 openpyxl 不会算公式。所以 Skill 加了一层 LibreOffice 重算 + Poppler 渲染,补上 openpyxl 的盲区。pandas 是第三件工具,专门处理 CSV/TSV 和大批量数据分析场景。三件工具各司其职,而不是试图用一个包解决所有问题。
这里有一个容易被忽略的设计:Skill 明确要求 Agent 使用公式后,必须引用的不是”数字”而是”单元格”。换句话说,=H6*(1+$B$3) 而不是 =H6*1.04。这个区别对 Agent 来说不是天然的,它天然倾向于把计算结果写进去,而不是保留”这个数字从哪来”的推导链。强制引用单元格地址,等于强迫 Agent 保留了数据之间的逻辑关系。
另一层设计在格式化规则上。新文件有一套完整的颜色约定:
-
蓝色:用户输入 -
黑色:公式推导 -
绿色:外部链接 -
灰色:常量 -
红色:错误或风险标志
这不是为了好看。当 Agent 审查一个它生成的财务报表时,它可以通过颜色快速定位”哪些数字我需要检查”,蓝色格子的值来自用户输入,可能用错了;黑色格子是公式推导的,需要验证公式逻辑;红色格子是出错标记,必须修正。

值得注意的还有这个 Skill 对投资银行场景的专门优化。总行数直接在数值区域上方求和,网格线隐藏后用水平边框标注合计行,节标题用深色填充白字合并单元格,子指标缩进排列在父指标下方。这些不是花活,是真的影响投行分析师阅读习惯的排版规则。一套 DCF 或 LBO 模型如果排版不符合这个范式,审阅的人第一反应就是”不对”。
实战场景
这个 Skill 最强的使用场景是财务建模。找个例子就清楚了:你让 Agent 做一套简单的 DCF 估值。
传统方式下,Agent 会拿到你的假设参数(增长率、折现率和预测期),然后逐行算出每年的自由现金流、终值和折现值,全部硬编码填入单元格。你拿到文件后想把增长率从 5% 改成 6%,整张表要全部重算,因为你改的只是一个数字,不是公式里的参数。
用 spreadsheet Skill 之后,Agent 的行为变了。增长率写在 B3 单元格,每年的预测自由现金流用 =H6*(1+$B$3) 引用这个格子。你改 B3,后面五年的数据自动刷新。这听起来像 Excel 的基础操作,但对 Agent 来说是质变:它从”制造结果”变成了”建立模型”。

第二个典型场景是 CSV 到带格式报表的转换。很多企业的数据系统只能导出 CSV,但汇报需要的是带了以下格式的 .xlsx 文件:表头样式、边框、千分位数字格式和条件着色。传统做法是手工打开 CSV 逐一调整,再保存。这个 Skill 能让 Agent 把整个过程自动化:读 CSV → pandas 做数据清洗和聚合 → openpyxl 写带格式的 .xlsx → LibreOffice 渲染检查布局 → 交付。
第三个场景是公式审计。拿到一个别人做的 .xlsx,里面有十几个 sheet、几百个公式,你想快速找出 #REF!、#DIV/0! 或循环引用的位置。Agent 加载文件后扫描所有公式单元格,用 openpyxl 检测错误类型,输出一个按 sheet 分组的问题清单。这跟 Excel 自带的”公式审核”工具做的事情类似,但 Agent 可以同时做跨 sheet 的引用链追踪,比手动点来点去快得多。
对了,这个 Skill 在纯服务器环境(没有 LibreOffice)里会降级运行。公式照样写,格式照样保留,但渲染检查这一步就没了。Agent 会在交付时提醒你”布局需要本地复查”。这不是缺点,是诚实的边界处理,比很多工具假装自己能渲染然后返回空白截图强。
洞察与反思
回头看这个 Skill 的设计,我越来越觉得它揭示了一个更大的趋势:Agent 的工具能力不需要多”聪明”,需要的是”专业化的行为约束”。
openpyxl 和 pandas 早就在那儿了,任何一个有 Python 执行权限的 Agent 都能用。但大多数 Agent 不会主动用公式写表格,因为它们没有被训练或提示成”先想公式再填值”。spreadsheet 这个 Skill 本质上不是一个新工具,是一套行为框架,它教 Agent 用已有工具的正确方式。
这个框架里最有价值的可能是”渲染检查”这个环节。让 Agent 在交付前看一眼自己生成的表格,这个动作的成本不高(多跑两行命令),但对输出质量的提升是决定性的。我自己在跑类似的表格自动化时,最常见的翻车原因不是逻辑错误,是布局问题:列宽不够导致数字显示为 ####、合并单元格错位、条件格式把整列染成同一种颜色。这些问题如果不预览,用户拿到手就是废的。
对比一下同类做法。Excel 的 Python 集成(Microsoft 365 里的 Python in Excel)和 Google Sheets 的 Apps Script 都能做自动化,但它们绑定特定平台。spreadsheet 这个 Skill 的优势是平台无关,生成的是标准 .xlsx 文件,发给任何用 Excel 或 LibreOffice 的人都能打开,公式不丢,格式不乱。代价是渲染依赖 LibreOffice,部署环境受限制。
我不太满意的是它对复杂图表的支持还很初步。openpyxl.chart 能做原生 Excel 图表,但 Skill 文档里只是提了一句”需要时使用”,没有给具体的图表生成规范。如果让 Agent 自己发挥,大概率会生成一堆丑到没法用的柱状图。这是下一步该强化的方向,给 Agent 一套”好看图表的判定标准”,而不仅仅是”生成图表的能力”。
资源地址
| 资源 | 地址 |
|---|---|
| 官网 | https://smithery.ai/skills/openai/spreadsheet |
| GitHub | https://github.com/openai/skills/tree/main/skills/.curated/spreadsheet |
总结
把 spreadsheet Skill 从头到尾走了一遍,最深的印象不是它做了什么,而是它刻意不做什么。
它不追求一次性搞定所有表格操作。它把工具链拆成三件:openpyxl 管格式,pandas 管分析,LibreOffice 管渲染。每件只做自己最擅长的那部分,不强求统一。它也不追求 Agent 能”聪明地”自己决定公式怎么写,而是给了一组硬约束:用单元格引用、不用动态数组函数、不用易失函数。这些约束看起来是限制,实际上是在帮 Agent 做正确的决策。
如果你想让 Agent 做的表格不只是数据填填,而是真正能”跑起来”的模型,这件事值得投入。花半小时配好环境,看完 SKILL.md 的规则清单,之后每一次让 Agent 做表格时,你拿到手的都是一个有公式、有格式,被渲染检查过的产物,而不是一个等着你手动重算的硬编码壳子。