

写过跨数据仓库 SQL 的人都知道那种痛苦。PostgreSQL 里
CURRENT_DATE是关键字,Snowflake 里要加括号写成CURRENT_DATE()。BigQuery 没有ILIKE,你得用LOWER(column) LIKE '%pattern%'。Redshift 的DATEDIFF参数顺序跟 Snowflake 一模一样,但日期加减的写法又完全不同。
这些差异不是学一次就能记住的。每次切数据源,你都得重新查文档,或者更现实地,打开三个 StackOverflow 标签页来回翻。Anthropic 开源的 SQL Queries Skill 想解决的就是这个问题:把五种主流数仓的方言差异,塞进一个 Claude 能随时读取的 Prompt 里。
从结构上看,它就是一个 10.9KB 的 Markdown 文件,放在 anthropics/knowledge-work-plugins 仓库的 data/skills/sql-queries/ 目录下。但这个文件的信息密度相当高,覆盖了五种主流数据仓库方言的核心语法差异:
-
PostgreSQL(含 Aurora、RDS、Supabase、Neon) -
Snowflake -
BigQuery -
Redshift -
Databricks SQL
除此之外,还有一套通用的 SQL 模式库和调试指南。
说真的,当 AI 技能越来越倾向于往”自动执行复杂任务”的方向卷的时候,这个 Skill 做了一个反直觉的选择:它不替你写 SQL,它只是给你一套写对 SQL 所需的全部知识。这种”把参考手册装进上下文”的做法,反而比那些试图自动生成查询的工具更靠谱。
环境准备
SQL Queries Skill 的获取方式很简单,本质上就是一个 Markdown 文件的安装。你可以通过 Smithery 平台一键安装到 Claude 环境里,也可以直接用 CLI 拉取:
npx @skills-re/cli install anthropics/knowledge-work-plugins/sql-queries
也可以直接从 GitHub 下载,不需要任何依赖:
git clone https://github.com/anthropics/knowledge-work-plugins.git
Skill 生效后,Claude 会在你写 SQL 相关任务时自动加载这个参考文件,不需要手动触发。安装完成后可以在 Claude 里试一条最简单的查询来验证,比如让它写一段计算用户留存率的 SQL,然后指定用 BigQuery 方言。
有一点需要注意:这个 Skill 是纯 Prompt 增强技能,没有自带工具调用或数据库连接能力。它不连接你的数仓,不执行查询,只负责在 Claude 生成 SQL 时提供方言正确的语法参考。如果你需要一个能真正跑查询的环境,还得配合 MCP 数据库连接器使用。
操作流程
使用这个 Skill 的体验跟传统”写 SQL → 报错 → 搜文档 → 改 → 再报错”的循环完全不同。你在 Claude 里用自然语言描述需求,Skill 在后台提供方言正确的语法保证,生成的 SQL 第一次就跑通的概率明显提高。
具体来说,工作流是这样的:你告诉 Claude “我要从 BigQuery 的用户行为表里算 30 天留存率”,Claude 加载 Skill 中的 BigQuery 专区,查到 DATE_TRUNC 的语法是 DATE_TRUNC(created_at, MONTH),而不是 PostgreSQL 的 DATE_TRUNC('month', created_at)。然后它从通用模式库里匹配到”Cohort Retention”模板,生成完整的留存分析查询。
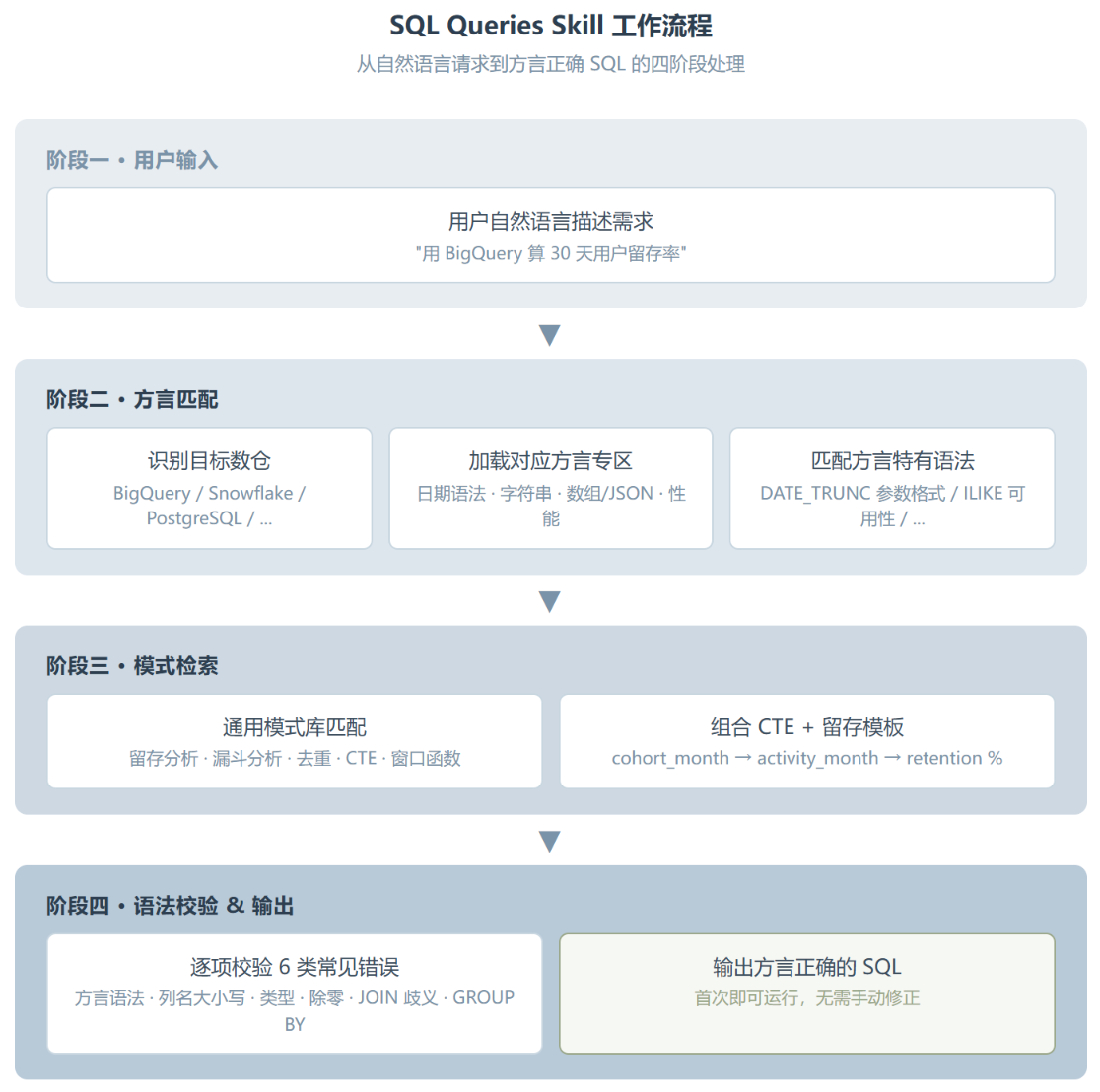
整个流程有几点值得注意。Skill 的”方言专区”是按数仓类型独立组织的,每个专区包含四个固定板块:
-
日期和时间处理 -
字符串函数 -
数组和 JSON 操作 -
性能优化建议
这种组织方式让 Claude 在生成 BigQuery 查询时,不会混入 Redshift 的 GETDATE() 或者 Snowflake 的 SYSDATE()。
更关键的是错误处理指南。当你生成的 SQL 报错时,Skill 会引导 Claude 按顺序检查六个常见问题:
-
方言特有语法差异(如 BigQuery 没有 ILIKE) -
列名拼写和大小写 -
类型不匹配 -
除零错误 -
JOIN 中的歧义列名 -
GROUP BY 遗漏
这个排查顺序是有设计的,从最常见的语法错误开始,到相对少见的逻辑错误,符合实际排错的经验路径。
如果你需要跨方言迁移,比如把一段 PostgreSQL 查询改写成 Snowflake 版本,Skill 的两套并排参考就能让 Claude 逐行对比语法差异。TO_CHAR 的参数分隔符从逗号变成括号,INTERVAL '7 days' 变成 DATEADD(day, 7, date_column),这些转换被 Skill 的结构化组织大幅降低了出错概率。
关键设计
这个 Skill 最值得拆解的设计选择是它的”参考手册”定位。大多数 AI 技能走的路线是”让 AI 替你做事”,自动执行、自动决策。SQL Queries Skill 走的是另一条路:它不试图替你做查询优化,不帮你选索引策略,它只保证 Claude 知道的语法是对的。
这种克制的设计有一个很实际的考量。SQL 语法差异是个确定性知识问题,不是推理问题。ILIKE 在 BigQuery 中不存在,这是一个事实,不是需要 AI “判断”的事情。把这类确定性的参考知识前置到 Skill 里,比指望模型在生成时”记住”所有方言差异要可靠得多。
但反过来,限制也很明显。Performance tips 部分只在对应专区里列了几条建议,比如 BigQuery 的”始终过滤分区列以减少扫描字节数”、Redshift 的”设计 DISTKEY 进行协同 JOIN”。这些建议是正确的,但远不够深入。真正做查询优化的人知道,BigQuery 的分区剪裁策略和 Redshift 的分布键设计是两套完全不同的优化哲学,Skill 目前只给了一个速查级别的覆盖。

通用 SQL 模式库是另一个亮点。五种模式的代码模板都写得很干净:
-
窗口函数(排名、累计、移动平均、同比环比) -
CTE 分层(基础人群 → 用户指标 → 汇总聚合) -
留存分析(按月/按周 cohort 计算) -
漏斗分析(页面访问 → 注册 → 首购转化率) -
数据去重(ROW_NUMBER 取最新记录)
尤其是 CTE 部分,它不是简单给个 WITH ... AS (...) 的语法示例,而是展示了一个三层 CTE 的完整分析链路:基础人群定义、用户级指标计算、汇总级聚合。这种分层写法本身就是一种最佳实践的教学。
使用场景
最典型的使用场景是数据团队的跨数仓查询需求。一个同时用 Snowflake 做数据仓库、用 PostgreSQL 做业务数据库的团队,数据分析师在 Claude 里切换数据源描述时,不需要每次手动纠正方言差异。
举个例子。你需要写一段计算用户漏斗转化率的 SQL,从页面访问到注册完成再到首次购买。用传统方式,你可能先写一版 PostgreSQL 的,然后在 Snowflake 环境里报错四五次,逐一修正 CURRENT_DATE() 的参数、DATE_TRUNC 的引号、窗口函数的细微差异。有了这个 Skill,你只需要说”用 Snowflake 方言写这段漏斗分析的 SQL”,Claude 自动匹配 Snowflake 专区语法,第一次生成的结果就是可运行的。
另一个场景是 SQL 审查。Skill 里的性能优化建议可以作为一个速查清单:BigQuery 里有没有避免 SELECT *?Redshift 的 JOIN 有没有考虑 DISTKEY 对齐?这些检查点虽然不深入,但作为第一道防线是够用的。
但边界也很清楚。它不适合深度性能调优。如果你的 BigQuery 查询扫描了几 TB 数据,Skill 能提醒你加分区过滤,但它不会告诉你现有的分区策略是否合理。要不要重新设计聚类键?它回答不了。复杂的数据建模场景也一样,那需要数据仓库架构层面的知识,不是一个 10KB 的参考文件能覆盖的。至于主流方言之外的数据库,比如 ClickHouse、DuckDB、Trino 这些新兴引擎,目前完全不在覆盖范围内。
洞察与反思
Skill 这种”参考手册型”设计的价值,可能比看上去更大。
AI 编程工具在过去两年最大的进步,是让代码生成越来越”自动”。Cursor 能帮你补全整个函数,GitHub Copilot 能根据注释写一整段逻辑。但 SQL 生成跟代码生成有一个本质区别:代码错了有编译器和 linter 兜底,SQL 错了可能要跑了半天才发现聚合结果不对,或者更糟,静默地算出了错误的数据。
这才是”不替你做、保证你做对”这个设计思路成立的前提。在数据分析场景里,AI 帮你生成一段看似合理但实际有细微语法错误的 SQL,比不生成更危险。你会因为”看起来没问题”而放松检查,然后被错误结果误导。SQL Queries Skill 选择只做知识参考,不做自动生成决策,在数据准确性要求高的场景下反而是更安全的选择。
把这件事放到更大的 Skill 生态里看,也挺有意思。Anthropic 的知识工作者插件仓库里,有做竞品分析的,有做会议记录的,有做邮件处理的。这些 Skill 的共同点是用 AI 的推理能力替代人的判断。但 SQL Queries 反其道而行,它把最不需要”推理”的部分(方言语法差异)标准化,把需要”判断”的部分(查询逻辑设计、优化策略)留给使用者自己。这种”AI 做确定性的,人做判断性的”分工模式,可能是知识工作者类 Skill 的一个被低估的设计范式。
当然,这个 Skill 能走多远,取决于它能不能持续更新。五种方言的语法一直在变。Databricks 的 Delta Lake 功能每季度都有新特性,BigQuery 的 SQL 也在快速演进。一个 2026 年 3 月最后更新的 Skill,到年底可能就有一部分语法过时了。如果你重度依赖它,定期检查 GitHub 仓库的更新频率是个好习惯。
总结
回到开头的问题:把一个 10KB 的 Markdown 文件塞进 Claude 的上下文里,能解决跨方言 SQL 的痛点吗?
答案是”能解决一部分,而且解决的是最容易出错的那部分”。它不承诺让你成为 SQL 优化专家,也没法处理复杂的数据建模。但它把五种主流数仓的语法差异标准化成了一个随时可查的参考,这种”把确定性知识前置”的做法,在数据分析这个”错一点就全错”的领域里,比很多花里胡哨的自动生成方案更靠得住。
如果你日常要在至少两种数据仓库之间切换,这个 Skill 值得装上。它没什么学习成本,不需要配置,装上之后默默帮你兜底那些最容易犯的方言错误。至于更深入的查询优化和架构设计,那是另一个层面的问题,也不是一个 10KB 文件该解决的事。