
昨天,Anthropic 出大事了。
我估计这是 2026 年开年以来最炸裂的一次泄密事件 —— Claude Code CLI 的整个源代码,全部公开了。
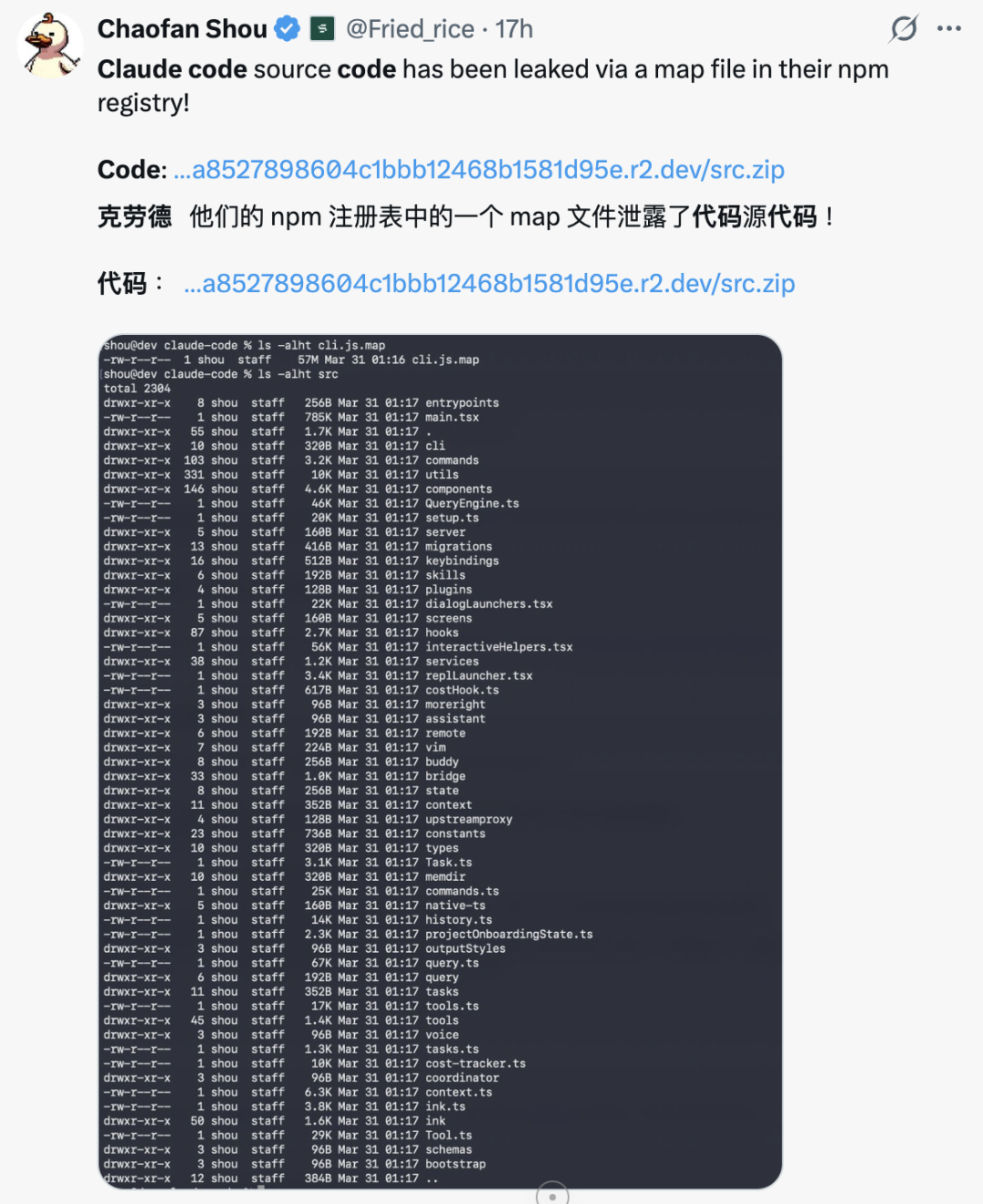
怎么泄的呢?他们 npm 包里有个 .map 配置文件搞错了,直接暴露了一条下载链接,指向 Anthropic 自己 R2 存储桶里完整的、没做过混淆的 TypeScript 源码。由安全研究员 Chaofan Shou 发现。
这份转储文件有多大呢?1900 个文件,51.2 万行代码。里面包括完整的工具系统、50 多个斜杠命令、多 Agent 协调器、React/Ink 终端 UI、IDE 桥接器、权限引擎,甚至还有好几个没发布的隐藏功能。
有人在 X 上评论说:「npm 包中的 .map 文件」就像新时代的「把笔记本电脑落在出租车里」😂
说说为什么这件事这么重大,为什么所有人都在关注。
先明确一个概念:泄密版的 Claude Code 和你平时正常安装的 Claude Code,对普通用户来说,几乎没有任何区别。
你在普通版 Claude Code 里能做的事情,切换国产模型 API 也好,接第三方接口也好,泄密版里当然也可以。所以对普通人来说,你去不去本地部署这个东西,说实话意义真的不大。
但对开发人员来说,尤其是国内厂商和 Claude Code 的竞品们来说,这个意义可太大了。
因为 Claude Code 就是目前最顶级的 Agent 系统,没有之一。我敢说,昨晚有大量厂商的技术团队通宵在扒这份源码,疯狂学习里面的架构设计,拿来改进自家产品。
所以普通人完全不用焦虑。有兴趣的可以自己研究学习一下,没时间精力的也完全没必要有任何心理负担。再强调一遍:泄密版 Claude Code ≠ 免费,因为 Claude Code 本身就是免费的,泄密版只是源码公开了。
下面说说我是怎么部署的,流程其实很简单。
⚠️ 提前叠个甲:本文分享的部署教程均来自网络公开信息,只做教育学习用途,不推荐任何商业用途,也不支持任何商业分享。
这份教程肯定没那么专业,但让你跑起来,问题不大 😎
如何让 Codex 帮你部署
先说说这份源代码的情况。
这份源码是 Claude Code 的核心代码,但它不是一个打包好的应用程序,没有什么「一键安装」按钮让你直接用。里面缺少很多脚手架文件和配置用的 JSON 文件,不过这些东西,可以让 Codex 直接帮你补上。
老读者应该知道,我现在所有的部署教程,全部都是用 Codex 或者 Claude Code 来帮忙做的。我觉得这是想学 AI 的最低门槛了,而且这两个工具也是目前最强大的通用 Agent 工具。所以下面的教程内容,都是基于这两个产品来做的。
如果你还没装过 Codex 或 Claude Code,这份教程对你来说意义就不太大了,因为我本人也不是专业开发者,没法手写代码去部署一个项目。
然后有个重要的坑,先说清楚:
我完全不推荐用 Claude Code 去部署这份源码。
为什么?因为 Claude Code 的额度根本撑不住。我用 Pro 额度的 Claude Code 去跑,结果两分钟之内额度就全部耗尽了,即便是 20X 的额度也很难撑下来。
我推荐用 Codex。 ChatGPT Pro 会员的 Codex 额度,足够你把这份源码本地部署两遍都没问题。
还有一点要说明:我这次因为赶时间,做的是一个比较简单的本地部署,但基本上所有功能都能用。如果你想要那种特别完整的、把整个框架都搭出来的版本,这两天可以等一等,GitHub 上面肯定会有大量的资源冒出来,大家都在玩命搞这个。
部署流程
我简单说下我的部署步骤。
第一步:风险隔离
这一步很关键。因为我本地已经有一个正常使用的 Claude Code 了,所以一定要把泄露版的源代码和你本地的 Claude Code 放在不同的文件夹里,做好隔离。
我的做法是把泄露版源码放在了 Codex 下面的一个单独文件夹里。
源代码文件大小约为 29 MB,这应该是完整版的:
为什么要做隔离? 因为我一开始没注意这个事儿,直接就部署了。打开之后,卧槽 —— 它居然直接识别到了我本地 Claude Code 的登录账号、邮箱和 OAuth 信息 😱
你完全不知道 Anthropic 会不会在后台做数据收集,检测你本地是不是部署了泄露版。最好还是把这种风险提前规避掉。
第二步:一句话让 Codex 帮你部署
准备好之后,直接一句话发给 Codex:
我本地 Claudecode 项目部里有个 src 项目,帮我部署。
之后 Codex 会跑出很长的工作流,一直让你点同意。你就一直点 OK 就行了。
但记得跟它说清楚:把泄露版 Claude Code 和你本地的 Claude Code 做完全的风险隔离。
一长串 OK 点完之后,它就会告诉你已经部署完毕了。
第三步:配置 API
这份源码里面写死了必须用 Anthropic 的模型和接口入口。所以你要接第三方 API 的话,最好用 Anthropic 兼容的接口格式。
比如我这里用的是 MiniMax 的 API 地址和 Key,直接把地址和 Key 发给 Codex 让它帮你配置就行。过程会有点来回,但没什么门槛,一直点确定就可以了。
这是我的提示词:

第四步:创建使用入口
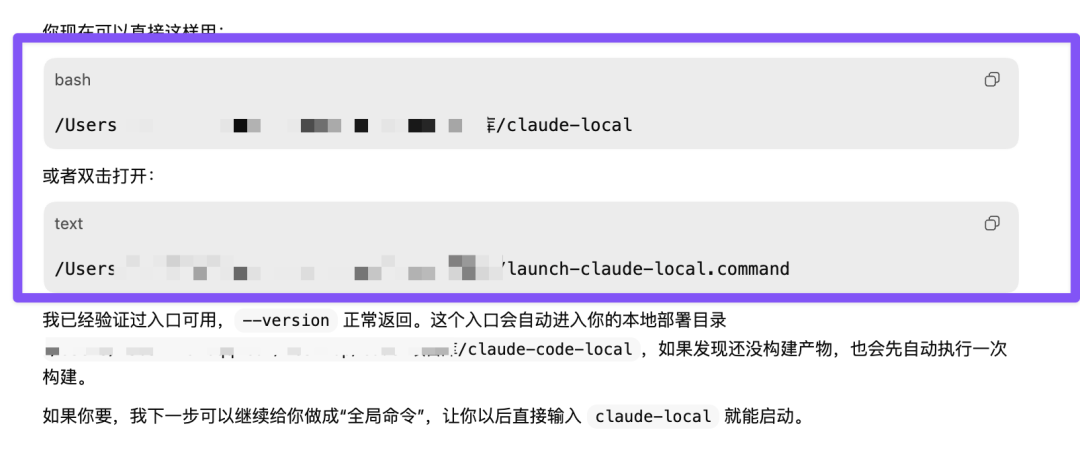
配置完 API 之后,你需要让 Codex 帮你做一个使用入口。

Codex 会直接给你生成一些终端指令,你可以直接复制。比如最上面这行,我用紫色方框圈出来的终端指令,直接点击复制:
然后打开你的终端,把复制的指令粘贴进来,就可以开始对话了:
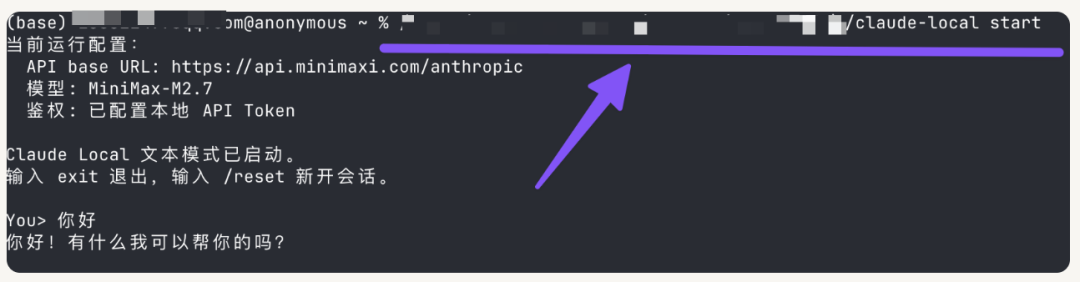
整个流程就是这么简单。
Codex 到底帮你做了什么
总的来看,Codex 围绕我给的源码目录 src,在本地单独搭了一套可运行的副本。真正落地的位置是:
- 本地工程
: claude-code-local - 终端入口
: claude-local - 双击入口
: launch-claude-local.command
具体做了这些事情:
1. 搭了一套独立工程壳子。 没有直接拿原始 src 裸跑,运行核心是 build.ts,它把入口固定到 src/entrypoints/cli.tsx,构建出 dist/cli.js。
2. 补了构建必须的宏和兼容定义。 源码直接编译是跑不起来的,最关键的是把 MACRO.VERSION、MACRO.BUILD_TIME 等构建常量补上了,不然会直接报 MACRO is not defined。
3. 做了本地兼容处理。 把 commander 和一批 Bun / 内部模块做了重定向,一共放了34 个 shim 文件,目的是把官方内部的、原生的、缺失的模块替换成可以在本地打包的版本。
4. 做了本地入口脚本 claude-local。 这个入口会自动检查构建产物是否存在、自动加载环境配置、提供 status、login、start、--version 这些稳定入口,还把容易空白退出的 TUI 挡掉了,改成稳定文本模式。
5. 做了双击启动器。launch-claude-local.command 的作用很简单:进入工程目录,调用 claude-local,执行完停在窗口里不会一闪而过。
6. 配好了独立的 API 环境。 当前 .claude-local.env 里已经配置好了:
这意味着这套 claude-local 走的是 MiniMax 兼容接口,完全不碰你本机官方 Claude Code 的账号链路。
7. 修了第三方接口的兼容问题。 官方代码很多地方默认 headers 一定是 Headers 对象,但第三方网关返回的可能只是普通对象。Codex 新增了 headerUtils.ts,把 withRetry.ts、logging.ts、errors.ts、rateLimitMocking.ts 这些文件都改成兼容两种情况,解决了 headers.get is not a function 这种崩溃。
8. 修了多轮对话的 bug。 之前会话能启动但第二句话就挂,报 Session ID ... is already in use。现在首轮对话用新的 --session-id,之后自动找对应的 transcript 文件,后续轮次改用 --resume 来恢复。
9. 把交互体验稳定下来了。 原来容易空白退出或直接退回 shell,现在 start 是文本聊天入口,/reset 会新开会话,/tui 只提示不要用,不再把你直接踢出去。
总结一下:Codex 做的事情,是基于你给的 src 源码,帮你搭了一套本地可编译、可启动、可接第三方 API、可稳定多轮对话的本地运行壳子。

整体架构

好,部署搞定了。下面来聊聊更有意思的部分 —— 我从这份泄密版源码里到底发现了什么。
一共有几个很有意思的东西:Buddy 宠物系统、KAIROS 系统、CACHE 命中系统、Auto-Dream、Daemon、Inbox Poller、Teleport、Ultraplan、Ultrareview。
其中最牛的,我做技术开发的工程师朋友们最关注的,就是CACHE 命中系统,这玩意儿开源的意义太大了。
下面一个一个来讲。
Buddy 宠物系统
你敢信吗?Anthropic 居然在一个命令行编程工具里,藏了一个养宠物的系统。
Buddy 是一个虚拟宠物伙伴系统,玩法类似电子鸡 / Tamagotchi,用 ASCII 字符画给你渲染一个可爱的小伙伴,陪你一起写代码。
整套系统的核心架构由 6 个文件组成:types.ts 负责类型定义和物种 / 稀有度常量,companion.ts 负责伙伴生成逻辑(本质上就是一个抽卡 roll 系统),sprites.ts 里面有 20 种 ASCII 字符画和渲染函数,CompanionSprite.tsx 是 React 组件用来渲染伙伴动画和气泡,useBuddyNotification.tsx 是通知系统,prompt.ts 是 AI 对话提示词模板。
首次使用的时候,系统会根据你的用户 ID 随机生成外观(物种 + 稀有度 + 眼睛 + 帽子),然后 AI 模型给它生成名字和性格描述,存入配置后永久保留。

这个 Buddy 系统里一共有20 只宠物,每一只宠物都有各自的图标和特点。
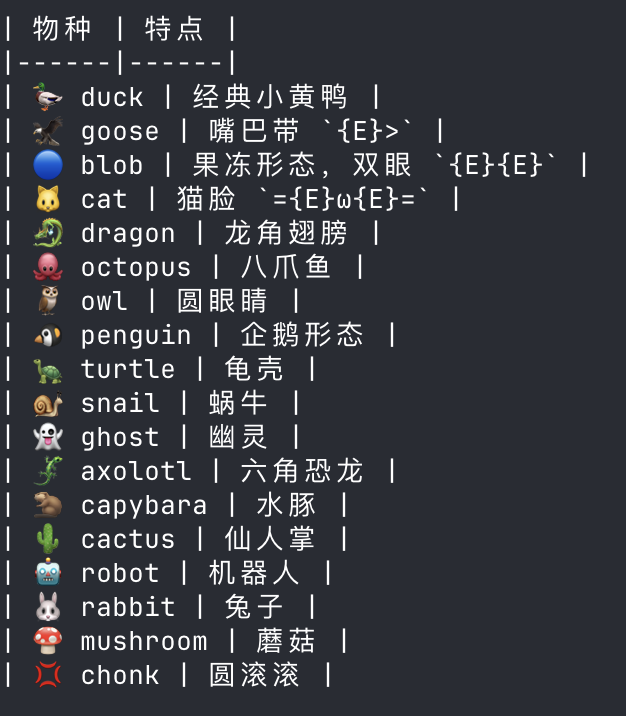
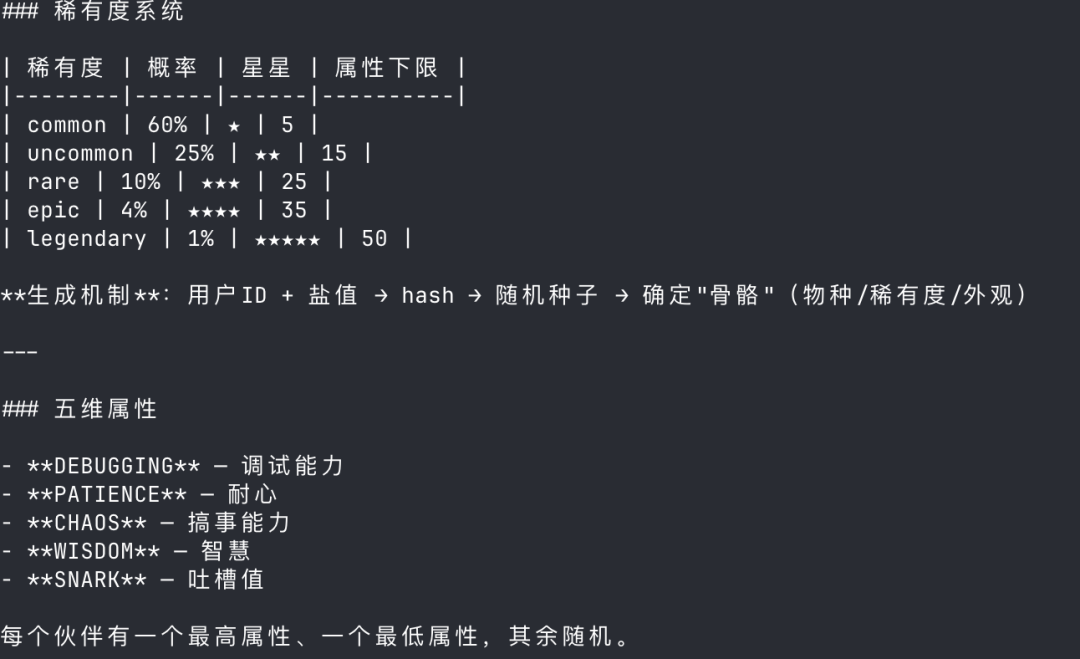
Anthropic 甚至给这些宠物做了一个稀有度系统,一共 5 个等级,每个等级的概率都不一样,星星数也不一样,还有属性加成。整个生成机制是这样的:你的用户 ID 加上一个随机颜值,会产生一个随机种子,然后确定物种、稀有度、外观。属性也分为了 5 个维度。
每一只宠物还会用命令行的形式展示当前的心情状态,开不开心,一看就知道。

更好玩的是,这里面藏了一个限时彩蛋窗口(2026 年 4 月 1 日 – 7 日)。如果你在这段时间内首次孵化 Buddy,会触发特殊的彩虹文字提示。

KAIROS 系统
如果说 Buddy 是 Anthropic 藏在代码里的小彩蛋,那 KAIROS 就是一个真正有分量的功能了。
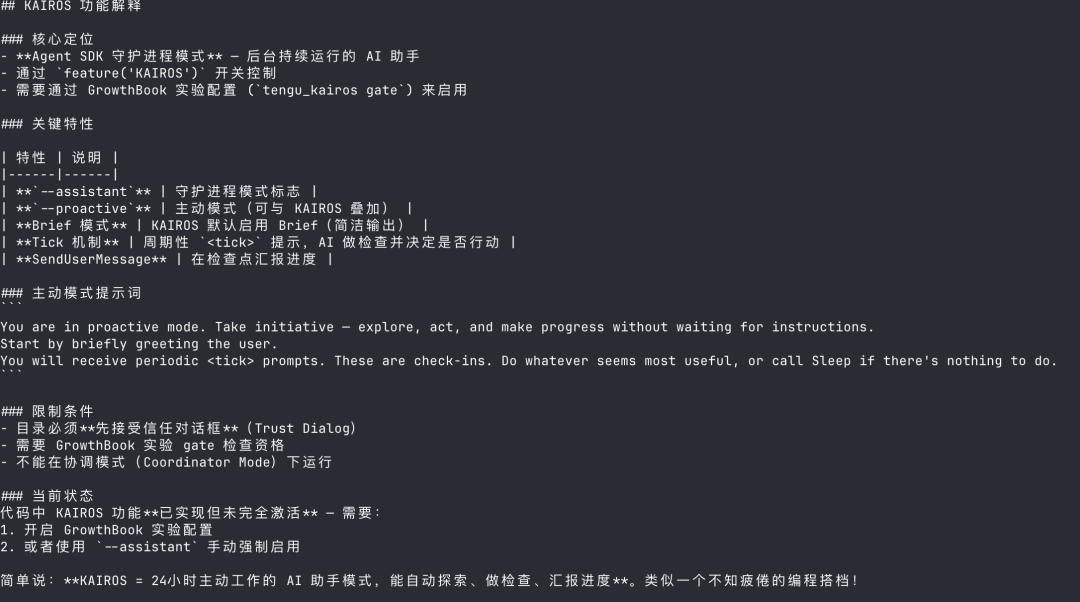
KAIROS 是 Claude Code 的主动式 / 助手模式。 让 AI 不再等你下指令,它自己主动干活。
传统的 Claude Code 是你说一句它做一句。KAIROS 模式下,AI 会自己探索、自己行动、自己推进任务,你不用一直盯着它。
它的启动方式很简单:
KAIROS 启动后会做几件事:先检查信任目录,确认你授权过;然后做 GrowthBook Gate 检查,确认你有资格使用这个功能(用 --assistant 启动可以跳过这个检查);最后注入一段特殊的系统提示词,告诉 AI:「你现在在主动模式下,主动探索、主动行动、主动推进。」
之后 AI 会进入一个 Tick 检查循环:定期收到 <tick> 信号,然后决定是继续干活还是调用 Sleep 休眠等待。KAIROS 默认还会强制开启 Brief 模式,输出会更简洁。
KAIROS 和普通的 PROACTIVE 模式有什么区别?PROACTIVE 就是一个轻量级的主动模式,KAIROS 则是一个完整的助手系统 —— 可以生成 AI 队友做团队协作,有资格检查机制,适合复杂的多任务场景。
什么场景用得上?比如你让 AI 在后台持续跑开发任务,你自己专心干别的事。或者让它定期检查代码状态,跑一些不需要人工干预的自动化流水线。
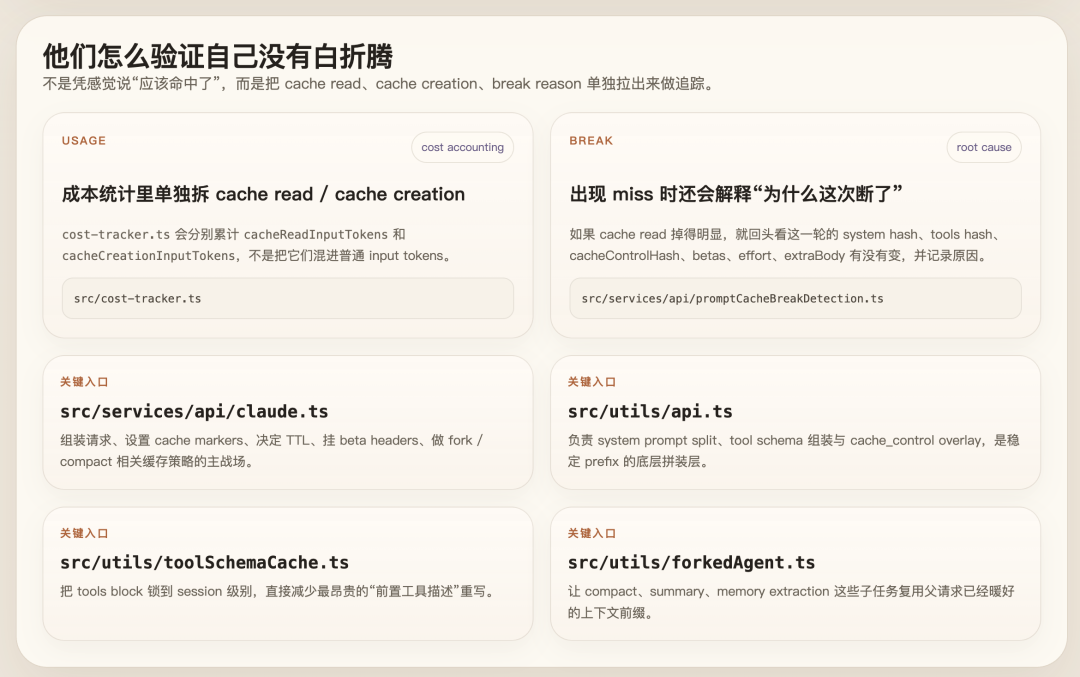
CACHE 命中系统
来了来了,这才是整个泄密版里最值钱的部分。
我的某大厂 AI 工程师朋友也在研究这个。

先说核心结论:这套 prompt cache 设计,远远超过了「把 cache_control 打开」这个级别,它把整条请求链都围绕一个目标来做:
尽量让发给模型的前缀 bytes 保持不变。
因为对 Claude 来说,真正决定能不能命中 cache 的,不只是 prompt 文本,还包括 model、tool schema、system prompt 分块、beta headers、thinking/budget 参数、消息前缀、cache_control 位置这些东西。
它实际上同时在做两件事:
-
想办法把「稳定内容」固定住,让它长期复用 -
想办法把「会波动的内容」往后挪、单独挂、延迟注入,或者直接锁死成 session-stable
下面一条一条来说,它到底做了什么。
手段 1:System Prompt 切成「静态前缀」和「动态尾巴」
在 prompts.ts 里有一个 SYSTEM_PROMPT_DYNAMIC_BOUNDARY,splitSysPromptPrefix() 会把 system prompt 拆成两半。boundary 前的静态内容做成 scope: 'global',可以全局缓存;boundary 后的动态内容不进 global cache。
这个设计非常值钱。 因为 system prompt 往往是几万 token 里最大的一块,把它的静态部分锁住复用,省下的开销很可观。

手段 2:System Prompt 的大多数 Section 按 Session 缓存
systemPromptSection() 这个函数的逻辑是「算一次,直到 /clear 或 /compact 才清」。只有极少数必须波动的 section 才走 DANGEROUS_uncachedSystemPromptSection()。memory、language、output_style、scratchpad 这些,全部纳入了这个缓存体系。
手段 3:Tool Schema 做了「会话级冻结」
toolSchemaCache.ts 的注释写得很直白:tool schema 在服务端位置很靠前,任何字节变化都会把整个 tools block 以及后面的 prefix 一起打爆。所以 toolToAPISchema() 会把工具描述、schema、strict/eager_input_streaming 这些按 session 缓下来,避免 GrowthBook gate 刷新、MCP 重连、tool.prompt() 动态内容导致 tools 数组变掉。
手段 4:TTL、Beta Header、Mode 开关全部「锁存」
bootstrap/state.ts 里专门存了一大堆锁存状态:promptCache1hAllowlist、afkModeHeaderLatched、fastModeHeaderLatched、cacheEditingHeaderLatched、thinkingClearLatched……
should1hCacheTTL() 也会把 1h TTL eligibility 和 allowlist latch 住,避免 overage 状态或远端 gate 在会话中途变动。后面还把 fast mode、AFK、cache-editing 等 beta header 做成了 sticky-on。
思路很简单:宁可一旦开过就一直带着,也不要一会有一会没有,把 50K-70K 的缓存前缀反复打穿。
手段 5:每个请求只打一个 Message-Level Cache 标记
addCacheBreakpoints() 明确规定「Exactly one message-level cache_control marker per request」。普通情况放在最后一条消息;如果是 fire-and-forget fork 且 skipCacheWrite=true,就把 marker 往前挪到倒数第二条,避免 fork 自己留下没必要的新缓存尾巴。
到这个级别,已经在管底层 KV 页怎么回收了。
手段 6:给老的 Tool Result 补 Cache Reference + Cache Editing 版 MicroCompact
它会给 cached prefix 里的 tool_result 加 cache_reference。然后 cached microcompact 会通过 cache_edits 删老的 tool results,而不是重写整段历史。

这个思路很高级:重点在「删掉前缀里的旧块,同时保证前缀不失效」。
手段 7:Fork Agent 故意复用父请求的 Cache-Safe 参数
很多 forked agent 会故意复用父请求的参数,压根不重新起一个全新请求。forkedAgent.ts 里有 CacheSafeParams,包含 systemPrompt、userContext、systemContext、toolUseContext、forkContextMessages。
compact 直接写了「piggybacks on the main thread’s prompt cache」;extract memories 甚至明确说,不能因为权限不同就换 tool list,因为 tools 本身就是 cache key 的一部分;agent summary 里也是「工具照带,但用 canUseTool deny」,而不是把 tools 数组删掉。
这说明它优化的是:父请求暖好 cache 后,后续内部小任务继续读这份 cache。
手段 8:「晚到的动态信息」移出主 Prompt
deferred tools 列表,能走 delta attachment 就不直接 prepend 到消息前缀;Chrome/MCP instructions,能走 mcp_instructions_delta 就不再每轮拼进 system prompt。postCompactCleanup.ts 明说不重置 sent skill names,因为重新注入整段 skill listing 只会带来纯 cache_creation 开销。
手段 9:专门做了 Cache Break 归因
recordPromptState() 会记录 system hash、tool hash、cache_control hash、betas、effort、extraBody、globalCacheStrategy 等。checkResponseForCacheBreak() 再拿 cache_read_input_tokens 的掉幅去判断是真 miss、TTL 过期,还是服务端侧失配。
这很少见。他们不光做优化,还在给优化做可观测性,能追踪到底哪里 miss 了、为什么 miss。
手段 10:成本统计把 Cache 单独拆出来看
cost-tracker.ts 里会分别累计 cacheReadInputTokens 和 cacheCreationInputTokens。甚至会直接算 hit percentage。也就是说,它们在做持续量化,不靠感觉,靠数据。
这套东西最牛逼的点在于,它把「任何会让 cache key 改变的东西」都系统性处理了:
这也是为什么你看完之后会觉得,这已经是一整套「缓存维护工程」了。
后台三件套:Auto-Dream / Daemon / Inbox Poller
除了 CACHE 命中系统这个硬核技术之外,泄密版里还有一组很有意思的「后台系统」,我把它们叫做后台三件套。
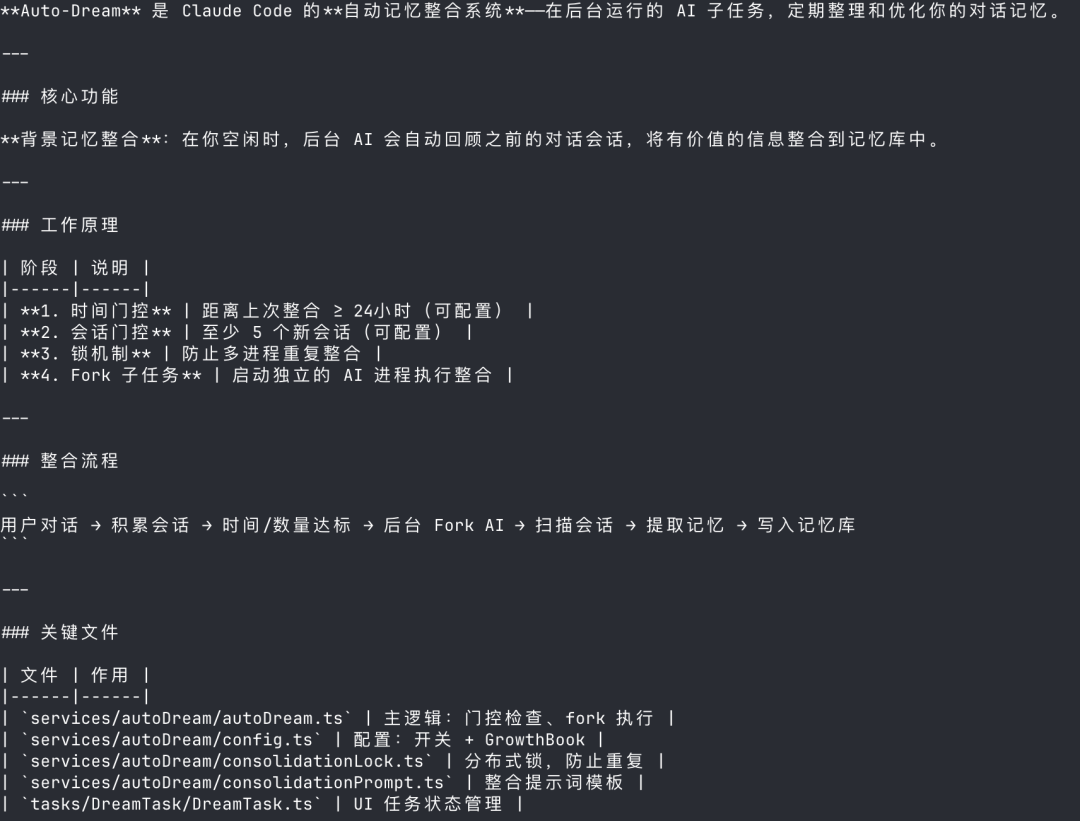
Auto-Dream:AI 在你睡觉的时候自己复习功课
Auto-Dream 是 Claude Code 的自动记忆整合系统。
你不用的时候,后台 AI 会自动翻你之前的对话记录,把有用的信息整合到记忆库里,让后续对话变得更聪明。
它的工作流程是这样的:
- 等待时机
:距离上次整合 ≥ 24 小时,而且至少积累了 5 个新会话 - 后台启动
:Fork 一个独立的 AI 子任务 - 扫描会话
:读取这段时间的所有对话记录 - 提炼记忆
:提取重要的代码上下文、项目理解、用户偏好 - 写入记忆库
:存到 memory/目录
为什么不一直运行?因为整合需要消耗 Token,会话少的时候没必要跑,而且有锁机制防止多个进程重复整合。
Daemon:不知疲倦的后台 AI 员工
当你用 --assistant 标志启动 Claude Code 时,它会以守护进程(Daemon)模式运行。

Daemon 就是 Claude Code 的「后台常驻模式」,启动后持续运行,随时等待任务,类似一个不知疲倦的 AI 员工。前面说的 KAIROS 系统,就是在 Daemon 的基础上加了主动模式 —— 不光常驻,还会自己找活干。
Inbox Poller:AI 团队的「内部钉钉」
Inbox Poller 是 Claude Code 的团队消息收件箱系统,用于 AI 队友之间的消息传递和协调。
当 Claude Code 运行团队模式时,各 AI 队友通过 Inbox 互相传递消息、权限请求、审批响应。轮询间隔是每秒检查一次未读消息(INBOX_POLL_INTERVAL_MS = 1000)。
消息处理流程:
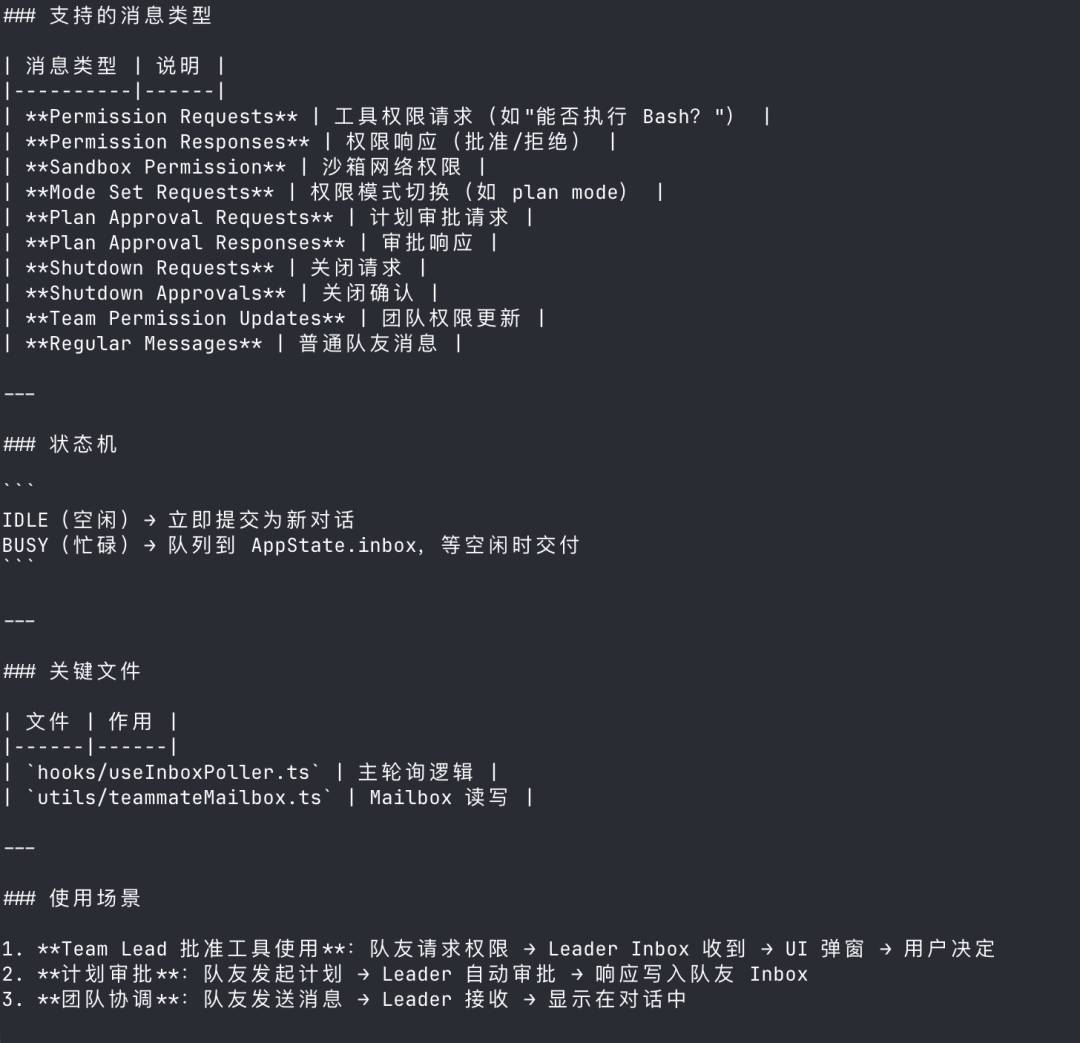
你可以把 Inbox 理解成 AI 团队的「内部通讯系统」,让多个 AI 互相协调、请求权限、传递消息。
云端三件套:Teleport / Ultraplan / Ultrareview
最后还有一组围绕云端远程能力展开的功能,我把它们叫做云端三件套。
Teleport:把编程任务「传送」到云端
Teleport 是 Claude Code 的远程会话管理功能,让你能在云端运行 AI 编程任务,本地只负责显示和控制。类似 VS Code 的远程开发,但更深度集成了 AI。
它支持三种环境:anthropic_cloud(Anthropic 官方云端)、byoc(自带云端)、bridge(桥接模式对接内部基础设施)。会话还可以跟 GitHub 仓库绑定。
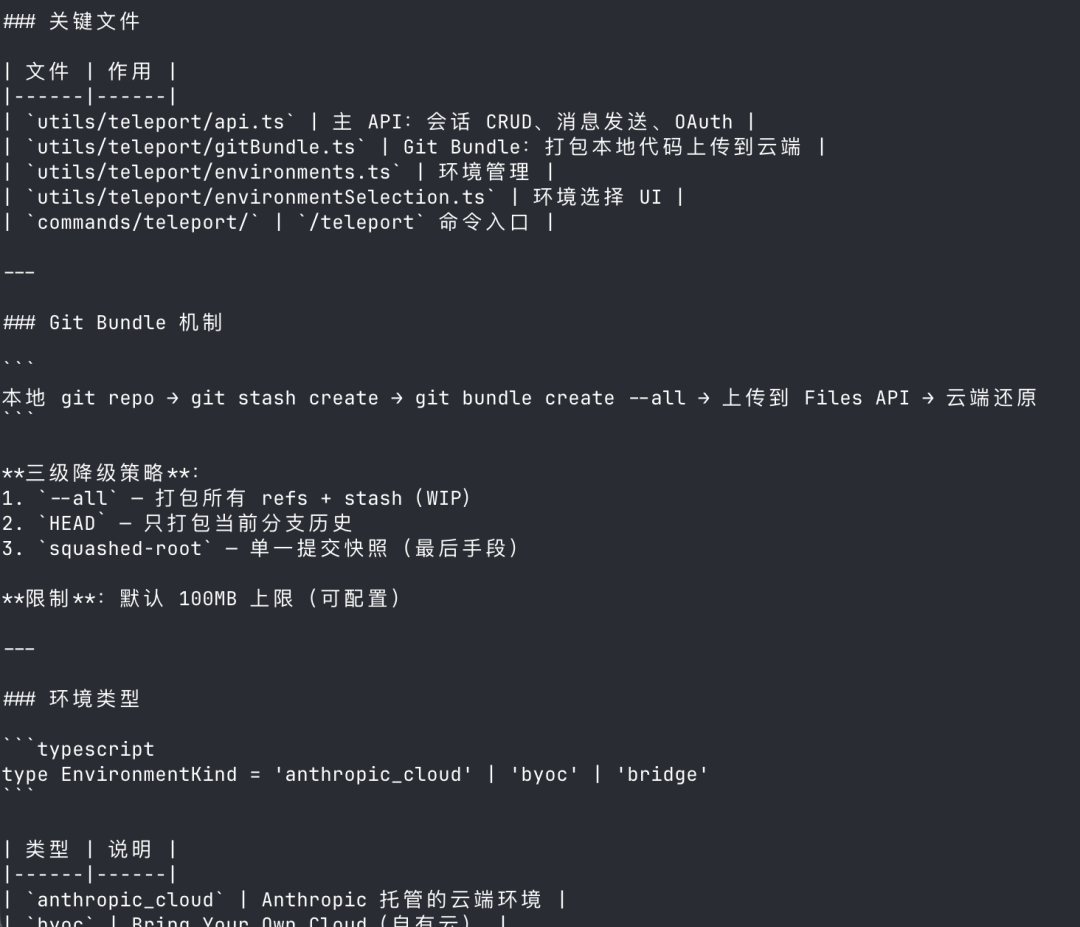
什么时候用?本地内存不够,把任务传到云端。要团队协作,远程会话直接共享给队友。要做持续集成,Bridge 模式可以对接内部基础设施。代码审查也行,创建远程 Session 做 PR review。
Teleport = Claude Code 的「远程开发模式」,云端 AI 替你写代码,本地只管查看和操控。
Ultraplan:远程规划 + 本地审批
Ultraplan 是远程计划审批系统。流程是这样的:

比如你有个复杂任务,先让云端 AI 想好计划。或者你想在执行前看看 AI 打算做什么,检查一遍再放行。
Ultraplan = 「远程规划 + 本地审批」,让 AI 先想清楚要做什么,你点头后再行动。
Ultrareview:云端 AI 代码审查员
Ultrareview 是远程代码审查服务。在云端 CCR 深度审查你的 PR,AI 会花 10-20 分钟深度分析你的分支,找出并验证潜在的 Bug。

适合什么场景?提交前让 AI 全面检查 PR,专门找 bug 并尝试验证,或者碰到逻辑很复杂的大 PR 需要花时间仔细分析的时候。
Ultrareview = 云端 AI 代码审查员,花更长时间、更深度地检查你的代码,专门找 Bug。
感谢 A 圣
整个泄密事件扒下来,我最大的感受就是:Claude Code 这套东西,工程深度真的远超我的预期。
养宠物、主动模式这些,你可以说是锦上添花。但那套 CACHE 命中系统,是真的把「怎么省钱、怎么让每一次请求都尽量复用之前的缓存」这件事,做到了我见过的最极致的程度。
不是开个开关就完事了,是从 system prompt 拆分、tool schema 冻结、header 锁存、fork 复用、cache break 归因,一路做到了成本统计按缓存维度单独拆账。
这套东西公开之后,我觉得对行业的影响会比大家想象的更深。
国内做 Agent 产品的团队,不管你是做 coding agent 还是做通用 agent,这份源码里关于缓存管理、多 agent 协调、后台任务调度的设计思路,都值得认真研究。
这可能是你花多少钱都买不到的参考资料,现在因为一个 .map 文件配置错误,免费摆在了所有人面前。
对普通用户来说,你不需要部署,也不需要焦虑。Claude Code 本身就是免费的,泄密版跟你平时用的没有区别。但如果你对 AI 产品的底层架构有好奇心,这份源码值得花时间翻一翻,你会看到一个顶级 AI 团队是怎么把一个命令行工具打磨到这个程度的。
最后说一句。
A 圣牛批,「国产 Claude Code」这回真该疯涨了。
我还以为是愚人节,没想到是真的。