
写个复杂 Agent 还要等几十秒才能动?Gemini 3.5 Flash 把输出速度干到了 280+ token/秒,直接是 GPT-5.5 和 Claude Opus 4.7 的 4 倍。在编码和智能体基准上,它甚至反过来碾压了自家上一代旗舰 Gemini 3.1 Pro。$1.5 的输入价格、90% 的缓存折扣、默认开启的 Thinking 模式,这个 Flash 系列新王,把”快”和”强”绑在了一起。上手试了一圈,有个感受特别强烈:Flash 和 Pro 的边界,正在被它亲手抹掉。
这到底是什么
5 月 19 日,谷歌在 I/O 2026 上正式发布了 Gemini 3.5 Flash。这是 Gemini 3.5 系列的首个公开模型,由 Google DeepMind 出品,定位极为明确,把旗舰级别的 Agent 和编码能力塞进 Flash 系列一贯的低延迟、低成本框架里。截至发布时,Gemini 应用月活已突破 9 亿,3.5 Flash 直接成为 Gemini 应用和 Google 搜索 AI 模式的默认模型。
官网:https://gemini.google.com/app
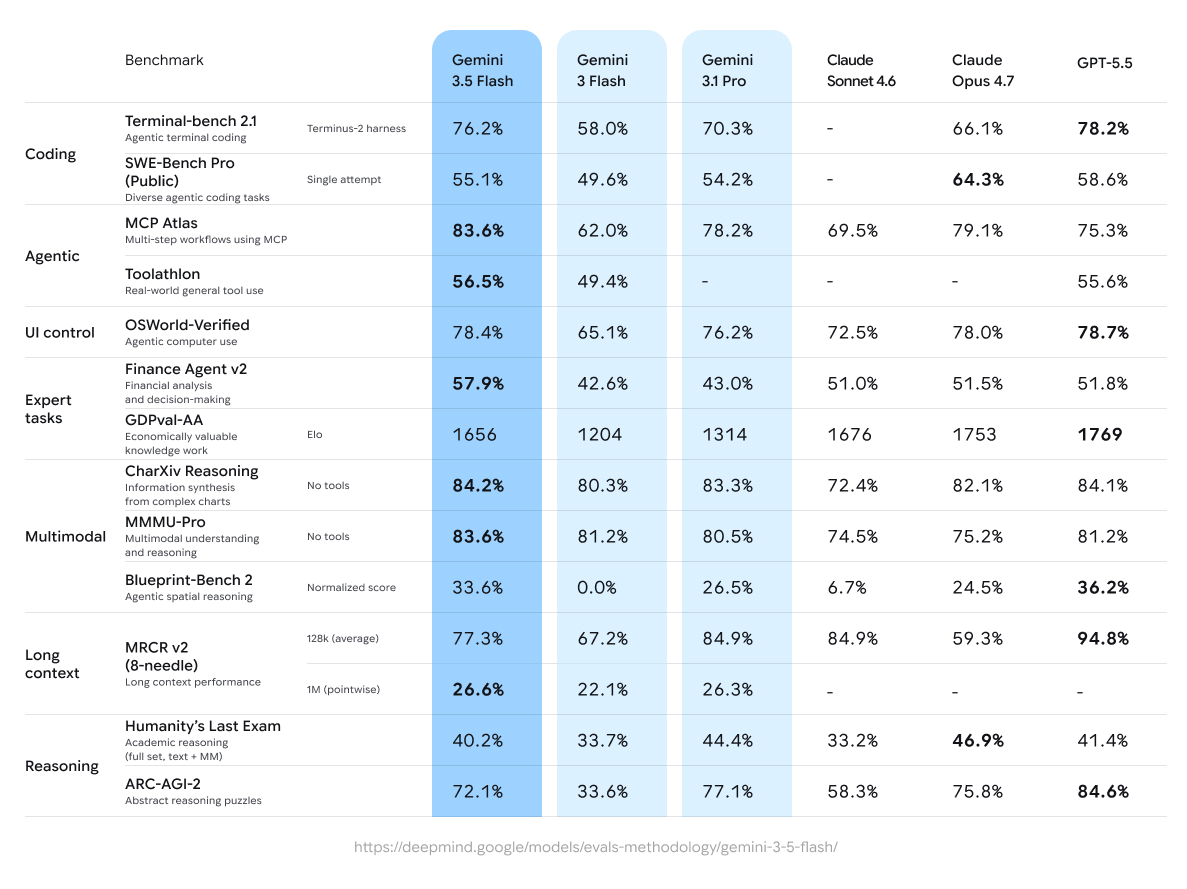
传统上,Flash 系列一直是”性价比之选”,Pro 系列才是性能担当。但这次 3.5 Flash 打破了这条分界线:在 Terminal-Bench 2.1(76.2%)、MCP Atlas(83.6%)、GDPval-AA(1656 Elo)等 Agent 评测中,它全面碾压 3.1 Pro。输出速度快 4 倍、成本不到三分之二,却交出了多数维度更强的成绩单。
到底强在哪
说了一堆概念,那它到底能干什么?我梳理下来,3.5 Flash 的能力可以拆成四个核心层面。
首先是 Agent 任务执行。这是 3.5 Flash 最猛的地方,多步工具调用、子 Agent 编排、长周期自动化。Shopify 用它做并行子 Agent 分析全球商家增长数据,Macquarie Bank 用它处理上百页的金融文档。谷歌还推出了 Managed Agents,一个 API 调用就能启动带隔离 Linux 环境的完整 Agent。
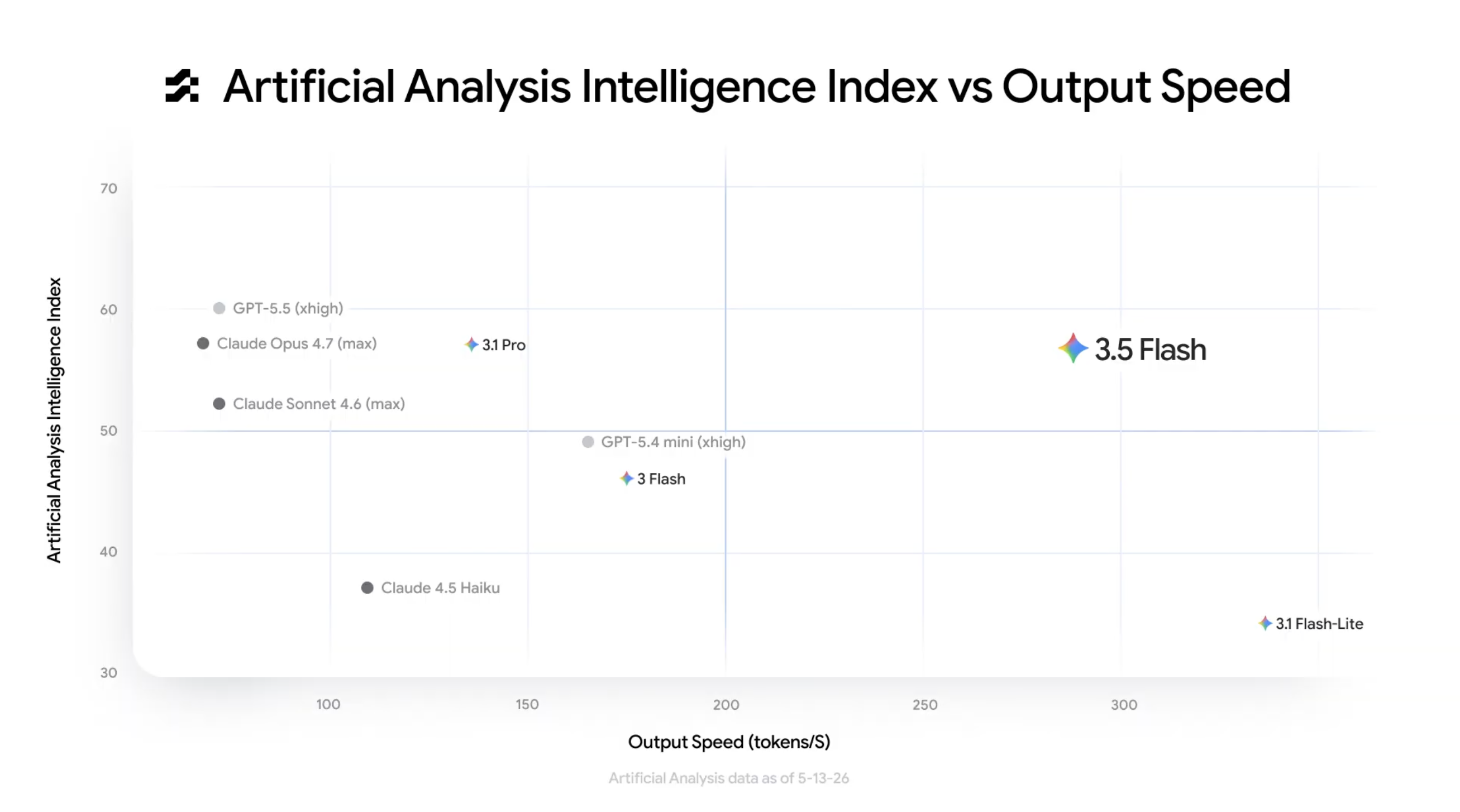
其次是 速度。输出 280+ token/秒是什么概念?GPT-5.5 写完一句话的时间,3.5 Flash 已经输出了一整段。这意味着在需要大量往返的 Agent 场景里,等待感几乎消失,4 倍的速度差在多次调用中会累积成数量级的效率提升。
然后是 1M 上下文。100 万 token 的输入窗口 + 64K 输出,配合 90% 的缓存折扣,处理长文档时的成本优势极其明显。不过 MRCR v2 128K 的召回率(77.3%)低于 3.1 Pro(84.9%),说明窗口满了之后细节抓取有退化。
最后是 多模态理解。支持文本、图像、音频、视频输入,在 CharXiv Reasoning(84.2%)和 MMMU-Pro(83.6%)上表现亮眼。但注意,只有文本输出,还不能直接生成图片或视频。
上手体验
数据看了不少,实际注册用起来更直观。如果你用过 Gemini,这就是无缝升级,浏览器打开 gemini.google.com 或者 Google AI Studio,Google 账号登录,模型默认就是 3.5 Flash。不用配什么参数,直接打字就行。
我第一个试的是编程场景:给它一个 Vue 3 组件需求,让它写出来。第一轮大概是 3 秒出响应,然后持续输出代码,每秒能看到大量字符涌入。几分钟写完了一个带状态管理和 API 调用的完整组件,确实跟发布会上说的”把数天的工作压缩成几小时”对得上。
不过也不是没槽点。在 AI Studio 里直接配 Managed Agents 还是有一些门槛的,文档写得不算友好,新手可能要翻好几个页面才能找到 Agents 入口。免费版有速率限制,高频测试时偶尔会触发节流,需要耐心等一会儿才能继续问。
进阶玩法
基础能力已经很能打,但用好它还有一些偏方:
-
Antigravity 2.0:很多人不知道谷歌出了一个桌面 Agent 编排工具。下载后可以在本地启动并行子 Agent,让不同的 Agent 同时处理调研、编码、测试,最后汇总结果,效率直接翻倍。 -
缓存策略最大化:输入缓存 90% 折扣是 3.5 Flash 被低估的省钱利器。如果你在做长流程 Agent 任务,把共享上下文(系统指令、背景文档)设计为一次性写入,后续每次调用只需 $0.15/1M 的缓存价。高频场景下成本能压到原来的十分之一。 -
Managed Agents 的环境持久化:创建一次 Agent 实例后,环境状态可以持续保留。你可以在一次对话中完成”调研→写代码→测试→部署”全流程,Agent 不会因为上下文超出窗口而失忆。 -
搜索即工具:3.5 Flash 内置了 Google 搜索能力,可以在推理过程中自动搜实时信息。对于需要最新数据的场景(比如今日股价、政策更新),这个功能省去了手动喂资料的麻烦。
竞品对比
当 Flash 系列开始在 Agent 赛道领跑,其他旗舰模型也坐不住了。来直接看硬碰硬的对比:
| 对比维度 | Gemini 3.5 Flash | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|---|
| 输出速度 | 280+ token/s | 约 70 token/s | 约 70 token/s |
| Input 价格 | $1.50/1M tokens | 约 $2.50/1M tokens | 约 $3.00/1M tokens |
| 上下文窗口 | 1M tokens | 待确认 | 200K tokens |
| Agent 能力 | 最强(多项 Agent 榜单第一) | 强 | 强 |
| 缓存折扣 | 90%($0.15/1M) | 无或较低 | 无或较低 |
这张表最扎眼的就是速度。4 倍的差距在单次调用中可能只是”快一点”,但在 Agent 任务里(一次任务几十上百次调用),就是”天壤之别”。谷歌把效率和能力强行绑在一起,这让 3.5 Flash 在性价比上建立了明显的护城河。
用户口碑
刚发布一天,技术社区已经炸开了锅。Reddit 和 Twitter 上讨论度相当高,情绪以正面为主但也有清醒的声音。
“以前 Flash 系列我都是当玩具用的,这次 3.5 Flash 是真的能打。”,很多开发者用这句话表达了惊讶。SWE-Bench 55.1%、Terminal-Bench 76.2% 这些分数,加上编码任务中 4 倍的速度,确实让不少人改变了看法。有人甚至说这是”谷歌今年最值得关注的模型,没有之一”。
吐槽的声音集中在两个方面。一个是纯抽象推理,HLE 40.2%(低于 3.1 Pro 的 44.4%)、ARC-AGI-2 72.1%(低于 3.1 Pro 的 77.1%),在需要深层逻辑的硬推理任务上不如自己的上一代旗舰。另一个是”自汇报”争议,谷歌公布的所有分数都是内部测试结果,外界还没完成独立复现。不过先例来看,谷歌的分数缩水幅度通常不大。
综合打分
分数归分数,从实际使用感受出发,我给 Gemini 3.5 Flash 打出了以下评分:
| 维度 | 评分 | 一句话解读 |
|---|---|---|
| 功能完整性 | ⭐⭐⭐⭐⭐ | Agent + 编码 + 多模态,覆盖面全 |
| 易用性 | ⭐⭐⭐⭐☆ | Gemini 端零门槛,AI Studio 略有门槛 |
| 性价比 | ⭐⭐⭐⭐⭐ | 4 倍速度+缓存折扣,同档位无敌 |
| 创新性 | ⭐⭐⭐⭐⭐ | Flash 超 Pro,Agent 优先架构 |
| 稳定性 | ⭐⭐⭐⭐☆ | 刚上线,长上下文召回待验证 |
| 推荐度 | ⭐⭐⭐⭐⭐ | 开发者和 Agent 场景首选 |
综合评分:9.2 / 10
优点和槽点
优势
-
Agent 能力断层领先:多步推理、工具调用、子 Agent 编排,多项 Agent 榜单第一 -
速度+成本双重碾压:4 倍输出速度、缓存 90% 折扣、输入 $1.5/1M -
1M 超长上下文:配合持久化 Agent 环境,适合长周期复杂任务 -
生态整合完善:Gemini 应用、AI Studio、Antigravity、Vertex AI 全线打通
不足
-
纯推理上限不及 Pro:HLE 和 ARC-AGI-2 落后 3.1 Pro,硬逻辑场景需等待 3.5 Pro -
密集长上下文召回退化:MRCR v2 128K 召回率 77.3% 低于 Pro 的 84.9% -
仅文本输出:不支持图片或视频生成,多模态输出缺失 -
自汇报分数待验证:所有分数为 Google 内部测试,独立复现结果尚未公开
适合谁用
产品和定价都看完了,那它到底最适合哪些人?
-
AI 应用开发者:3.5 Flash 的 Managed Agents 和 Antigravity 2.0 让构建复杂 Agent 变得简单,一个 API 就能启动带隔离环境的完整 Agent。对于需要高频调用的编码 Agent、自动化工作流的团队,速度和成本优势能直接转化为生产力。 -
需要 Agent 自动化的企业团队:Shopify、Macquarie Bank、Xero、Databricks 已经成为第一批企业用户。如果你团队有大量需要”调研→分析→执行”的长周期工作流,3.5 Flash 可以把数天压缩到几小时。 -
高频 API 调用场景的开发者:预算敏感但需要高质量输出的场景,3.5 Flash 的定价在同档位没有对手。如果每天 API 调用量在百万 token 级别,对比 GPT-5.5 或 Claude Opus 4.7,每月能省 40-60% 的费用。 -
不太适合的人:如果你需要深度推理性的一问一答,或者依赖超密集长上下文召回,建议等 3.5 Pro 出来再做判断。目前 3.5 Flash 在这两个维度上不及 3.1 Pro。
定价方案
产品和用户需求对上了,来看看钱包受不受得了:
| 定价项 | 全球价格 | 其他地区 |
|---|---|---|
| 输入 | $1.50/百万 token | $1.65/百万 token |
| 输出 | $9.00/百万 token | $9.90/百万 token |
| 缓存输入 | $0.15/百万 token | $0.165/百万 token |
作为参考,前代 Gemini 3 Flash Preview 的定价是 $0.50/$3/百万 tokens,3.5 Flash 是其 3 倍。但它比 Gemini 3.1 Pro($2.50/$15)便宜 40%。缓存 90% 折扣是真正的核心优势,在 Agent 场景中共享上下文是常态,这会让高频用户的实际成本比表面价格低得多。Gemini 应用端仍然免费可用,适合先体验后付费。
常见问题
Q1:Gemini 3.5 Flash 完全免费吗?
A1:Gemini 应用端免费可用,但 API 调用需要付费。 Gemini 对话界面直接用 Google 账号登录就行,没有任何使用费。但如果要通过 API 集成到自己的应用中,按量计费:输入 $1.50/百万 token,输出 $9.00/百万 token。
Q2:3.5 Flash 的中文能力怎么样?
A2:中文理解流畅,但发布当天还没有专门的中文基准数据。 实测下来,中文编码、文档总结、日常对话都没有明显问题。谷歌在训练数据中包含了大量中文语料,整体感觉和其他主流英文模型的中文水平相当。
Q3:它支持生成图片吗?
A3:不支持。3.5 Flash 只能输出文本。 它确实能理解图像输入(分析图表、看懂截图),但输出模态目前只有文字。如果需要生成图片,可以配合谷歌的 Image Gen 能力或者第三方工具。
Q4:跟 3.1 Pro 比,到底哪个更强?
A4:看场景。Agent 和编码任务 3.5 Flash 更强,抽象推理和长上下文召回 3.1 Pro 更好。 谷歌的定位很明确:Agent 优先场景选 3.5 Flash,纯推理或密集文档分析等 3.5 Pro 出来再做决定。
Q5:缓存折扣到底省多少?
A5:缓存输入的定价只有正常输入的 10%——$0.15 对比 $1.50/百万 token。 如果你在做长上下文 Agent 任务,把共享 Prompt 和背景文档设计为缓存命中,成本能降到原来的十分之一。对于日调用量大的团队,这是最大的省钱杠杆。
Q6:结果能商用吗?
A6:可以商用。谷歌的 Gemini API 服务条款允许将模型输出用于商业用途。 具体来说,通过 API 生成的内容版权归用户所有,但需要遵守谷歌的可接受使用政策,不能用于生成违法或有害内容。
Q7:知识截止到什么时候?
A7:知识截止日期为 2026 年 1 月。 如果需要查询更新信息,可以使用内置的 Search-as-a-tool 功能让模型自动联网搜索实时数据。
Q8:需要下载安装吗?
A8:不用。网页端登录 gemini.google.com 即可使用。 开发者可以用 Google AI Studio 或 API 直接调用。如果想要桌面端体验,可以下载 Antigravity 2.0 来做 Agent 编排。
Q9:免费版有哪些限制?
A9:有速率限制。免费 tier 的 API 调用频率和 token 量受限制。 在 Gemini 应用中使用时还没有明显限额,但高频测试可能在 AI Studio 中触发节流措施。如果生产环境需要高并发,建议升级到 Standard 或 Priority tier。
Q10:3.5 Flash 是什么时候发布的?
A10:2026 年 5 月 19 日,在 Google I/O 2026 大会上正式发布。 同日面向全球开放,没有 Preview 阶段,直接 GA。模型 ID 为 gemini-3.5-flash,内部快照版本为 3.5-flash-05-2026。
最后的结论
Gemini 3.5 Flash 是一个打破常规的模型,它把本该属于 Pro 系列的 Agent 和编码能力塞进了 Flash 的定价体系里。速度 4 倍碾压、Agent 榜单全面登顶、1M 上下文配合 90% 缓存折扣,这让它在高频调用的生产场景中很难被替代。
如果你靠 API 吃饭,3.5 Flash 值得成为第一默认选项。但纯推理深度不够和长上下文召回退化这两刀,砍得也很精准,硬核推理党,还是再等等 3.5 Pro。