
如果你用过 Claude Code 或 Cursor 改一个没见过的中型项目,你一定经历过这个场景:Agent 开始疯狂 grep,打开十几个文件,烧掉几万 Token,最后告诉你”没找到”。不是模型笨,是它每次都在裸眼看森林,没有地图。
codebase-memory-mcp 做的事很直接:提前把整个代码库索引成一张知识图谱,Agent 查图而不是翻文件。节点是函数、类、路由,边是调用、继承、数据流。同样是查”ProcessOrder 是谁调用的”,逐文件搜索要烧 41.2 万 Token,它只要 3,400,省掉 99.2%。
约 1.9 万 Stars,2026 年 2 月才创建,4 个月迭代了 35 个版本。更反常的是,这个面向 AI Agent 的工具,88% 的代码是纯 C。在 2026 年的 Python 海洋里,这选择几乎是一种挑衅。
但我翻了它的架构设计之后,发现这个”反常识”不是噱头。代码索引天生是个吃内存、吃 CPU 的脏活,要扫几万个文件、解析 158 种语言的语法树、把几百万个节点和几千万条边塞进内存。这种活,Python 是真的扛不住。C 加 LZ4 压缩加 mimalloc 分配器,在这个场景下就是最优解。

这张管线图把它的核心流程讲清楚了:源码经过 tree-sitter 语法解析和 Hybrid LSP 语义精炼,建成 SQLite 知识图谱,最后通过 14 个 MCP 工具暴露给 11 个 AI 编程助手。
流程看着简单,但每层下面都有值得展开的设计。下面聊聊真正让我觉得「这个项目不一般」的几个地方。
打动我的几个地方
真正有区分度的不是”它建了一张图”,而是这张图的厚度和精度。
它不只建调用图。除了最基础的 CALLS 和 IMPORTS,它还追踪几种一般代码图工具根本不碰的边类型:
-
HTTP_CALLS:微服务里救命级的跨服务路由匹配,从路由定义反推到调用点 -
DATA_FLOWS:参数级别的数据流向,追踪一个值从哪个函数的哪个参数出发,流经了哪些函数 -
SIMILAR_TO:MinHash 加 LSH 近克隆检测,帮你发现哪些函数其实在做差不多的事 -
EMITS 和 LISTENS_ON:Socket.IO、EventEmitter 的事件通道,8 种语言的常量解析
一张图建完,你问的不是”哪里有这个字符串”,而是”改了这里会波及哪些地方”“哪些函数从来没人调用”。
Hybrid LSP 补上了 tree-sitter 的语义盲区。tree-sitter 能解析 158 种语言的语法树,但它只懂语法,不懂语义。user.profile.display_name() 这行代码,tree-sitter 知道调了 display_name,但不知道它定义在哪个文件的哪个类里。Hybrid LSP 用纯 C 实现了类型推导算法,参考了 tsserver、pyright、gopls、rust-analyzer 的主流算法,但不跑语言服务器进程。
目前覆盖 Python、TypeScript、Go、Rust 等 9 种语言,能追踪泛型、继承、trait 方法。没覆盖的语言退回文本匹配,精度差点,至少不报空。两层架构的好处很明显:第一层语法解析跑得快,158 种语言全覆盖;第二层语义精炼只用在最关键的语言上,把调用边从「可能是」升级到「确认是」。
性能数据不是”挺快”,是快到改变认知。Linux 内核,2,800 万行代码,7.5 万个文件,3 分钟完整索引,生成 481 万节点和 772 万条边。Django 只要 6 秒。Cypher 查询走关系遍历,亚毫秒级。这不是优化,是把检索从”运行时计算”变成了”预计算查询”。
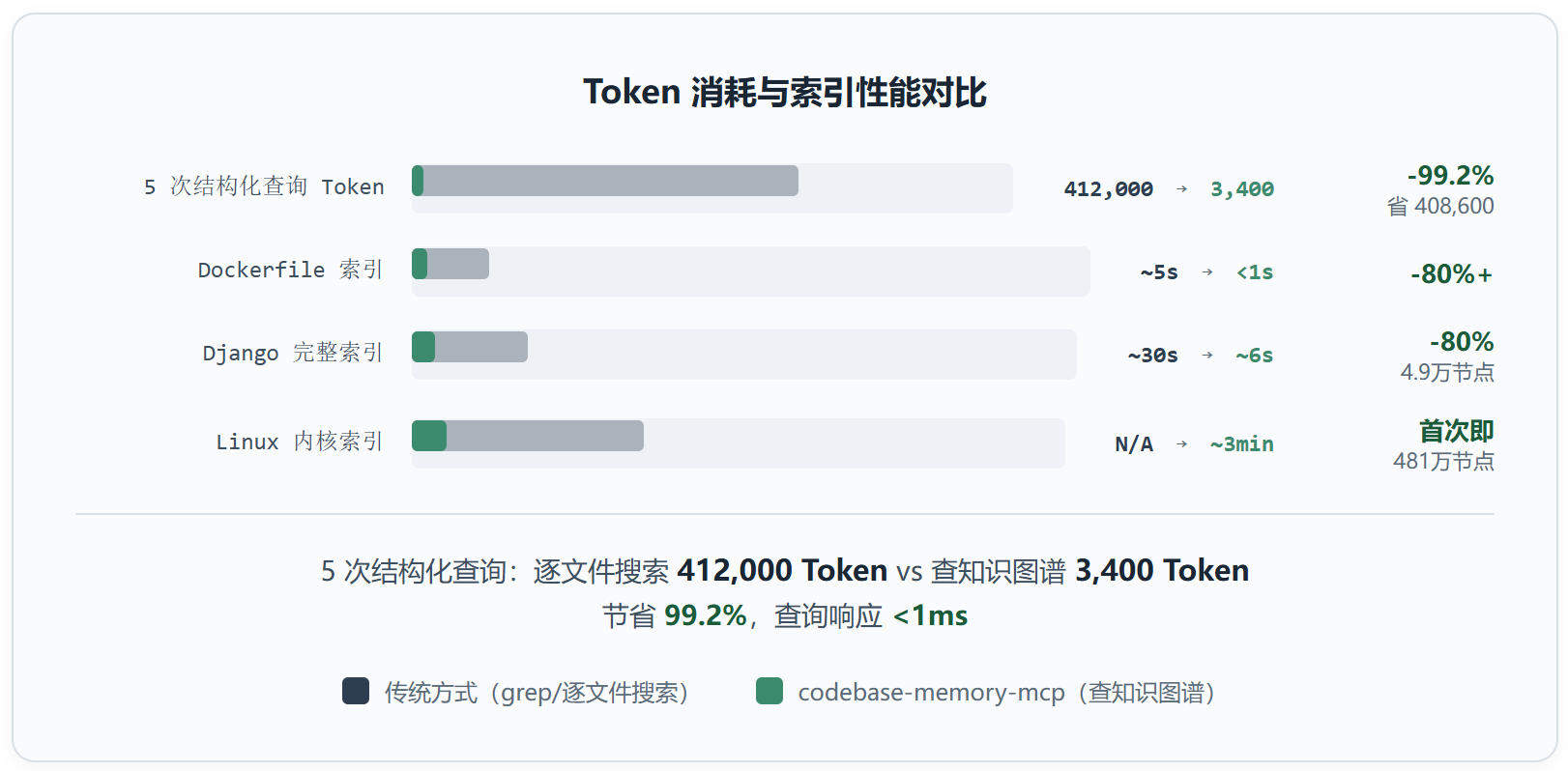
这两组对比数据值得盯着看三秒。左边是五个结构化查询的 Token 消耗:逐文件搜索烧掉 41.2 万,查图只用 3,400。右边是 Dockerfile 索引和 Django 完整索引的时间。差距不是百分比级别的,是指数级别的。
安装体验做得相当顺手。跑一句 install,自动扫描机器上装了哪些 AI 编程助手,给每个配好 MCP 配置、instruction 文件、Skill 和 pre-tool hook。支持 Claude Code、Codex CLI、Gemini CLI、Zed、Aider、VS Code 等 11 个 Agent。
对 Claude Code 还装了一个 PreToolUse hook,拦截 Grep 和 Glob,命中已索引符号时自动注入结构化上下文。hook 设计成非阻塞的,挂了也不影响你正常用。这个克制很专业。不过说真的,11 个 Agent 的自动配置,你上一次见到做得这么干净的工具是什么时候?
团队共享功能被低估了。建完图后压缩快照可以提交到仓库,同事 clone 下来直接解压,增量索引补上本地差异,不用从头建。它还自动加了 merge=ours 的 gitattributes,避免多人并发提交二进制产物时打架。Linux 内核那种 3 分钟的项目,一个人建图,全团队受益。
这四个亮点分开看每个都不算颠覆性创新,但放在一起产生了一个质变:它把代码检索从”运行时计算”变成了”预计算查询”。这个模式一旦跑通,可以迁移到文档库、API 知识库、测试用例库。
跑起来看看
安装简单到不像一个 C 项目:
curl -fsSL https://raw.githubusercontent.com/DeusData/codebase-memory-mcp/main/install.sh | bash
Windows 用户跑对应的 PowerShell 脚本。npm、PyPI、Homebrew、Scoop、Winget、AUR 全有包,选你习惯的就行。装完之后,对 AI 编程助手说一句”Index this project”,它就开始建图。
# 索引一个仓库
codebase-memory-mcp cli index_repository '{"repo_path": "/path/to/your/repo"}'
# 搜索函数
codebase-memory-mcp cli search_graph '{"name_pattern": ".*Handler.*", "label": "Function"}'
# 追踪调用链
codebase-memory-mcp cli trace_path '{"function_name": "ProcessOrder", "direction": "both"}'
索引完就能查了。CLI 模式支持所有 14 个 MCP 工具,你可以在终端直接跑类 Cypher 查询。查死代码、追踪调用链路、看架构概览,get_architecture 一次调用返回语言、包、路由、热点和集群,省掉十几轮 grep。
但实际用起来不可能一帆风顺,下面三个卡点值得提前知道:
-
路径必须用绝对路径,相对路径会失败(README 写了但很多人踩) -
trace_path返回 0 结果时,先用search_graph找到确切函数名再试 -
二进制文件可能不在 PATH 里,需要手动 export PATH="$HOME/.local/bin:$PATH"
这几个坑在 Issue 区被反复提到,好在都有现成的解决方案。
团队共享模式值得一提。建完图后,压缩快照 graph.db.zst 可以提交到仓库。同事 clone 下来直接解压,增量索引补上本地差异。压缩比 8 到 13 倍,对于 Linux 内核那种体量,这意味着几百 MB 的图压到几十 MB,完全在 git 的舒适区内。
适合谁,不适合谁
| 场景 | 典型用户 | 优势 | 局限 |
|---|---|---|---|
| 中型以上代码库开发 | 日常用 AI 编程助手的开发者 | 省 Token、查调用链快 | 小项目收益不明显 |
| 微服务架构维护 | 后端、全栈 | 跨服务 HTTP 路由匹配 | 需逐个服务建图 |
| 代码审查、重构前 | Tech Lead | 影响分析、死代码检测 | 静态分析,不覆盖运行时行为 |
| 新成员 Onboarding | 团队新成员 | 架构概览、快速理解模块关系 | 图很全但不含业务上下文 |
不适用的情况也很明确。你只改几个文件的小脚本,建图的成本比直接 grep 高,没必要。项目主要用 OCaml 或 Haskell,Hybrid LSP 不覆盖,语法解析精度约 70%,图会糙一些。你需要理解业务逻辑,图能告诉你谁调了谁,但不会解释为什么要这么调。
社区怎么样了
| 指标 | 数据 | 说明 |
|---|---|---|
| Stars | 约 1.9 万(截至 2026 年 7 月) | 4 个月增长迅猛,曾登顶 GitHub Trending |
| 核心维护者 | 1 人(Martin Vogel) | Bus Factor 为 1,最大的风险点 |
| 提交与 Release | 1,139 次提交,35 个版本 | 迭代极快,v0.8.1 已相当成熟 |
| 协议 | MIT | 商业友好,无使用限制 |
一个维护者撑起整个项目,1,139 次提交,5,750 个测试零失败。这个产出量不像一个人,但它确实是一个人。Martin Vogel 的 commit 几乎覆盖每天,Issue 响应也很快。但 Bus Factor 为 1 是硬伤。
好在这个项目有学术论文背书(arXiv:2603.27277),在 31 个真实仓库上评估过,83% 答案质量,2.1 倍工具调用减少。论文的存在至少说明设计思路经过了同行评审,不是野路子。
安全方面做得相当认真。SLSA Level 3 构建来源、Sigstore 无密钥签名、VirusTotal 全绿(70+ 引擎零检出)、CodeQL SAST 门禁。所有代码 100% 本地处理,不联网,不传遥测。这个安全标准在同类工具里没有对标。
GitHub Issue 区里,用户反馈最集中的诉求是”希望支持更多语言的 Hybrid LSP”,Ruby 和 Scala 被点名最多。目前 LSP 原创性有守卫脚本确保不抄袭参考语言服务器,这个机制让新语言适配的门槛不低。
社区数据看完了,但数字好看不等于能用得顺手。这个项目到底值不值得跟?
值不值得跟
表面上看,这是一个”代码检索”工具,跟 ctags、Sourcegraph、各种 grep wrapper 是竞品。但深入了解之后,我发现真正关键的不是检索,是它对 AI Agent 工作流的重新定义。
传统的 AI 编程流程是:Agent 需要信息,grep 搜索,读取文件,推理。瓶颈在第二和第三步,大量 Token 烧在找东西上,而不是理解东西上。codebase-memory-mcp 把流程改成:Agent 需要信息,查图,推理。第二步从几十万 Token 降到几千,第三步的上下文也更干净。

从传统工作流到 Map-First 模式,核心变化只有一个:把检索从运行时计算变成了预计算查询。当查询频率远高于变更频率时,这个策略永远赢。
但有一条重要的分界线得说清楚:它只建图,不包含 LLM。它不会帮你把自然语言翻译成图查询,这个翻译工作交给你的 AI 编程助手。作者在 README 里写得很直白,其他代码图工具喜欢内嵌一个 LLM 做翻译,这意味着多一个 API key、多一份成本。用 MCP 的话,你正在聊的那个 Agent 本身就是翻译器。这是个聪明的权衡,前提是你的 Agent 得够聪明。
我一开始觉得”纯 C 加静态二进制”是个营销噱头,但看完索引管线和 LSP 实现之后,发现这个选择是工程驱动的。代码索引的瓶颈在 IO 和内存吞吐,不是逻辑复杂度,C 加 LZ4 加 mimalloc 的组合在这个场景下确实能打。零依赖意味着部署简单到令人发指,下载一个文件,跑一句 install,完事。这在企业环境里是个被严重低估的优势。
从趋势上看,这个项目在快速上升。4 个月 1.9 万 Stars 的速度在 MCP 生态里是第一梯队。迭代节奏健康,几乎每周都有新版本。最大的不确定性就是单维护者,Martin Vogel 如果哪天被收购或者 burnout,项目未来就悬了。好在他把论文发了、安全体系建了、测试覆盖做足了,这些基础设施让 fork 的成本降了不少。
长远来看,这个项目最大的价值不是它本身,而是它验证了一个模式:预建索引替代实时搜索。当查询频率远高于变更频率时,预建索引永远赢过实时搜索。codebase-memory-mcp 把这个模式在代码图上跑通了,而且跑得很漂亮。
聊完了判断,该聊行动了。你该拿它怎么办?
资源地址
| 资源 | 地址 |
|---|---|
| GitHub | https://github.com/DeusData/codebase-memory-mcp |
| 官方文档 | https://deusdata.github.io/codebase-memory-mcp/ |
| 学术论文 | https://arxiv.org/abs/2603.27277 |
说了这么多技术细节和社区判断,最后聊一个更实际的问题:你现在该拿它做什么。
别再让 Agent 裸眼看森林
如果你每天用 AI 编程助手改中型以上的项目,花一个下午装它试试。从 index_repository 开始,跑一次 get_architecture,看看你的项目在它眼里长什么样。那个视角跟你自己理解的,很可能不一样。
还在观望的话,关注两个指标:Hybrid LSP 的语言扩展速度,以及是否有第二个核心维护者加入。前者决定了它的精度天花板,后者决定了它的长期存活率。
一个用 C 写的 AI 工具,在 2026 年拿到了近 2 万 Star。这个现象本身比这个项目更有意思:开发者对”轻量、快速、零依赖”的渴望,远超过对时髦技术栈的追逐。