

上一期你学会了指挥 AI 做分析,这一期你学会放手。

前言
上一期我们聊了用 TRAE 做数据分析的基础流程:把数据丢进去,告诉它“帮我清洗一下”、“按月份画个趋势图”、“算一下同比增长”,一步步指挥,一步步出结果。
如果你已经用起来了,可能会发现一个问题:简单分析很爽,但任务一复杂就累了。
比如:数据不是现成的,需要先从某个平台获取;需要同时分析好几份数据做对比;分析做完了不确定结论有没有问题;下个月同样的分析又得重新来一遍……
每次都手把手指挥每一步,链路一长就觉得:“我好像在给 AI 当保姆”。
这一期,我们升级玩法。核心理念就一句话:你负责想,AI 负责做。
上一期的模式是“你说一步,AI 做一步”:你既是思考者,也是指挥者。
这一期的升级是:你只负责定方向、定标准、做判断,剩下的规划路径、获取数据、拆分任务、检查质量、沉淀复用:全部交给 AI。
SOLO 里的 Agent 之所以能承接“做”的部分,是因为它具备三个关键特性:
-
自主决策能力:它每执行一步都会看到结果,然后根据结果决定下一步做什么:不是死板地执行脚本,而是“感知→判断→行动”的循环
-
完整的执行环境:能写代码、跑代码、装依赖、读写文件,不需要你帮它搭环境
-
持久化的工作空间:所有中间过程(代码、数据、图表)都保存在工作空间里,方便回溯、审查和复用
接下来 5 个进阶技巧,就是教你怎么把“做”的部分彻底交出去。
本文所有内容都用 SOLO MTC 模式演示。

技巧一:数据采集+分析一体化 – 没有数据?让 AI 自己去拿
很多时候你想做一个分析,第一个卡点不是”不会分析”,而是“数据还没拿到手”。
-
传统流程是:先去某个平台后台选日期 → 勾筛选条件 → 点导出 → 等半天 → 下载 CSV → 再丢给 AI 分析。光是”拿到数据”这一步就花了你 15 分钟。
-
进阶做法:连“找数据”这一步也让 Agent 操心。
比如你想看几只股票最近的走势对比,你手上没有数据。直接跟 Agent 说:
帮我获取贵州茅台、宁德时代、比亚迪最近半年的股价数据,做趋势对比分析,计算各自的波动率和最大回撤,告诉我哪只最稳、哪只波动最大,并画出走势对比图。你没有给它任何数据文件,但 Agent 会自己搞定全流程:
-
判断用什么工具获取数据(这次它选择了 yfinance 库 + A 股 ticker)
-
自动安装依赖(`pip install yfinance`)
-
自己查文档,了解 A 股的 ticker 格式(600519.SS / 300750.SZ)
-
写代码调用 API,获取半年日线数据
-
做指数化处理(起点=100),方便不同价位的股票直接对比
-
计算年化波动率和最大回撤
-
画对比走势图
-
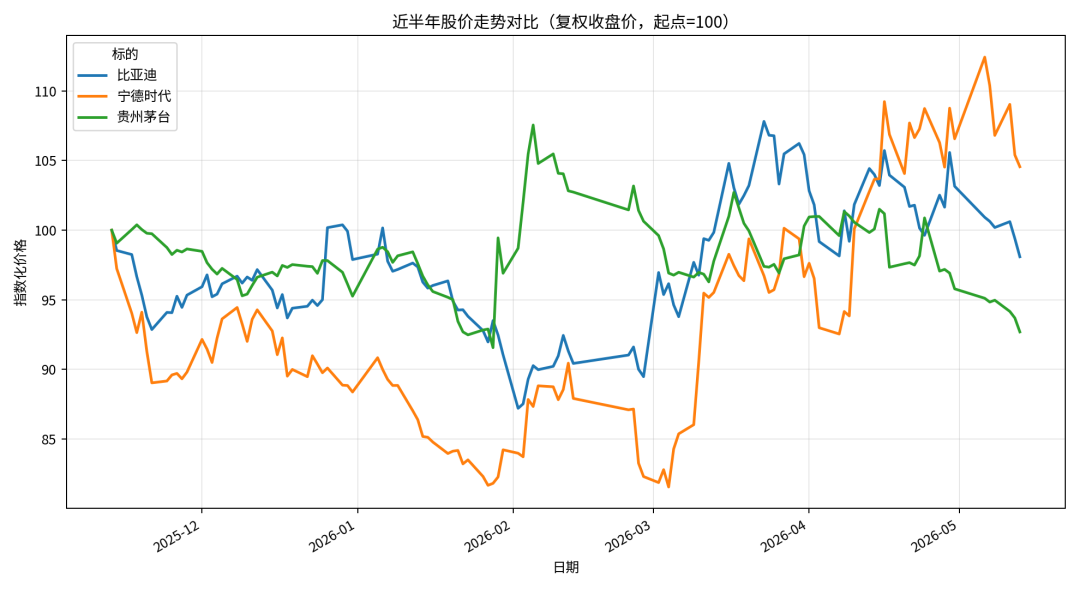
给出明确结论:贵州茅台最稳(波动率 23.27%),宁德时代波动最大(33.44%)
全程你只说了一句话,Agent 自己操心了所有中间环节。
▼ 图:一句话 Prompt → Agent 自主完成全链路(自动装库、查文档、调 API、出图)
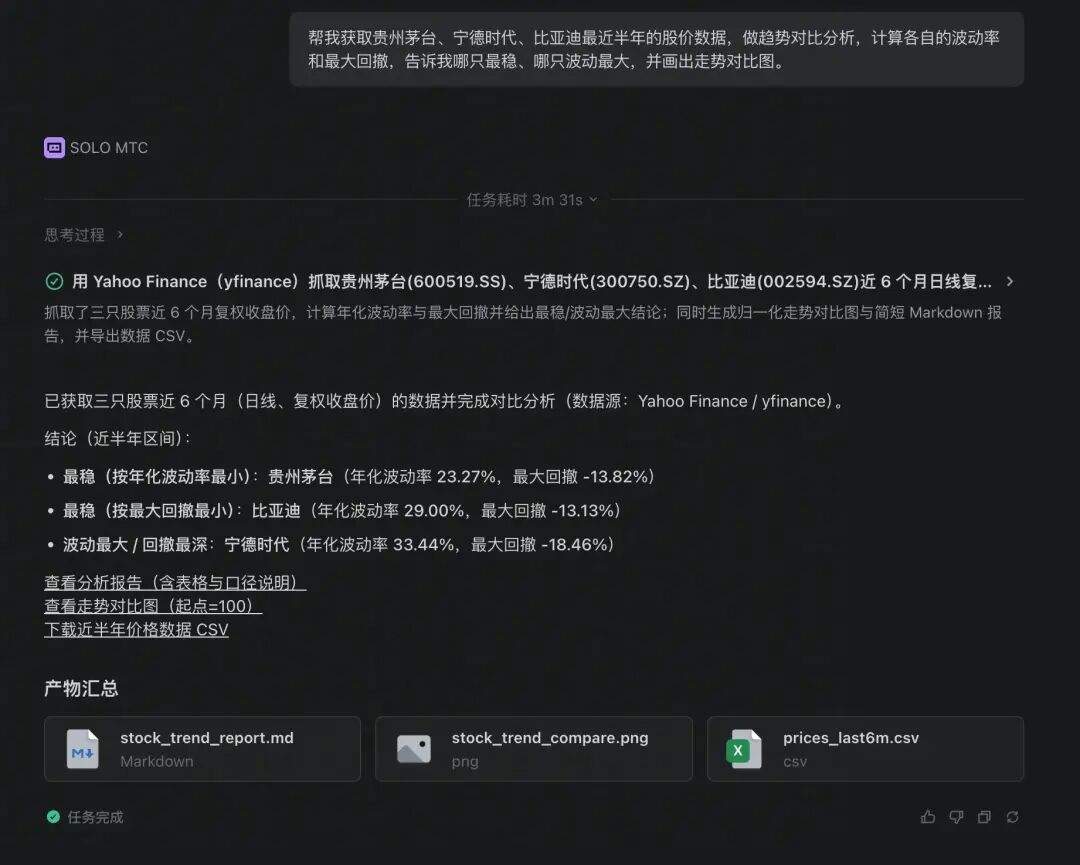
这件事的前提是 SOLO 的执行环境:Agent 能自己装库、自己写代码、自己跑。遇到 API 报错,它还会自动调试重试。你不需要懂任何编程或 API 的知识。
更强的是,Agent 不只是“会调 API”,它还会自己去查怎么调。比如这个 Case 里,你没告诉它 A 股在 yfinance 里的 ticker 格式是什么,它自己查了文档搞清楚了”贵州茅台=600519.SS””宁德时代=300750.SZ”。你不需要提前帮它找好文档或告诉它接口长什么样。
▼图:最终产出 — 三只 A 股近半年走势对比(指数化,起点=100),一眼看出谁稳谁波动

技巧二:多 Agent 协作 – 一个人忙不过来,派个团队
前面的技巧里,你跟一个 Agent 打交道就够了。但当分析任务变大:数据量上千条、需要逐条做语义理解:单个 Agent 串行处理就慢了。
这时候你需要的不是一个更强的 Agent,而是一个团队。
为什么数据分析特别适合多 Agent 协作?
因为数据分析的子任务之间天然耦合度低:第 1-100 条评价的情感分析和第 101-200 条互不依赖,A 区域和 B 区域的销售分析互不依赖。这种“天然可并行”的特性,让多 Agent 的收益特别明显。相比之下,写代码往往前后强依赖(数据模型没定就写不了接口),并行空间有限。
而 SOLO 之所以能支持这种协作,是因为它的工作空间是共享的:所有 Agent 都能读写同一组文件。一个 Agent 产出的中间结果,另一个 Agent 可以直接接着用。
实战演示:400 条餐厅评价并行打标
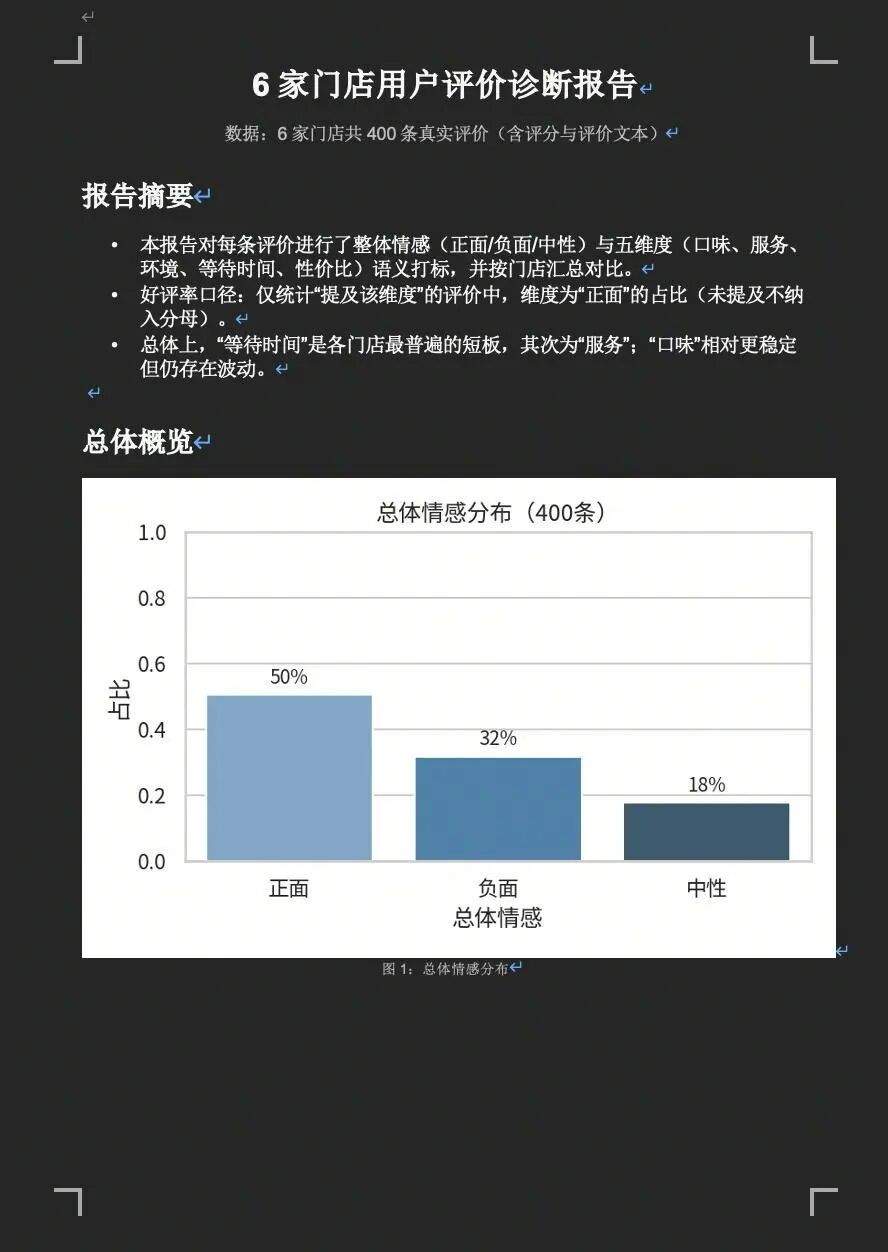
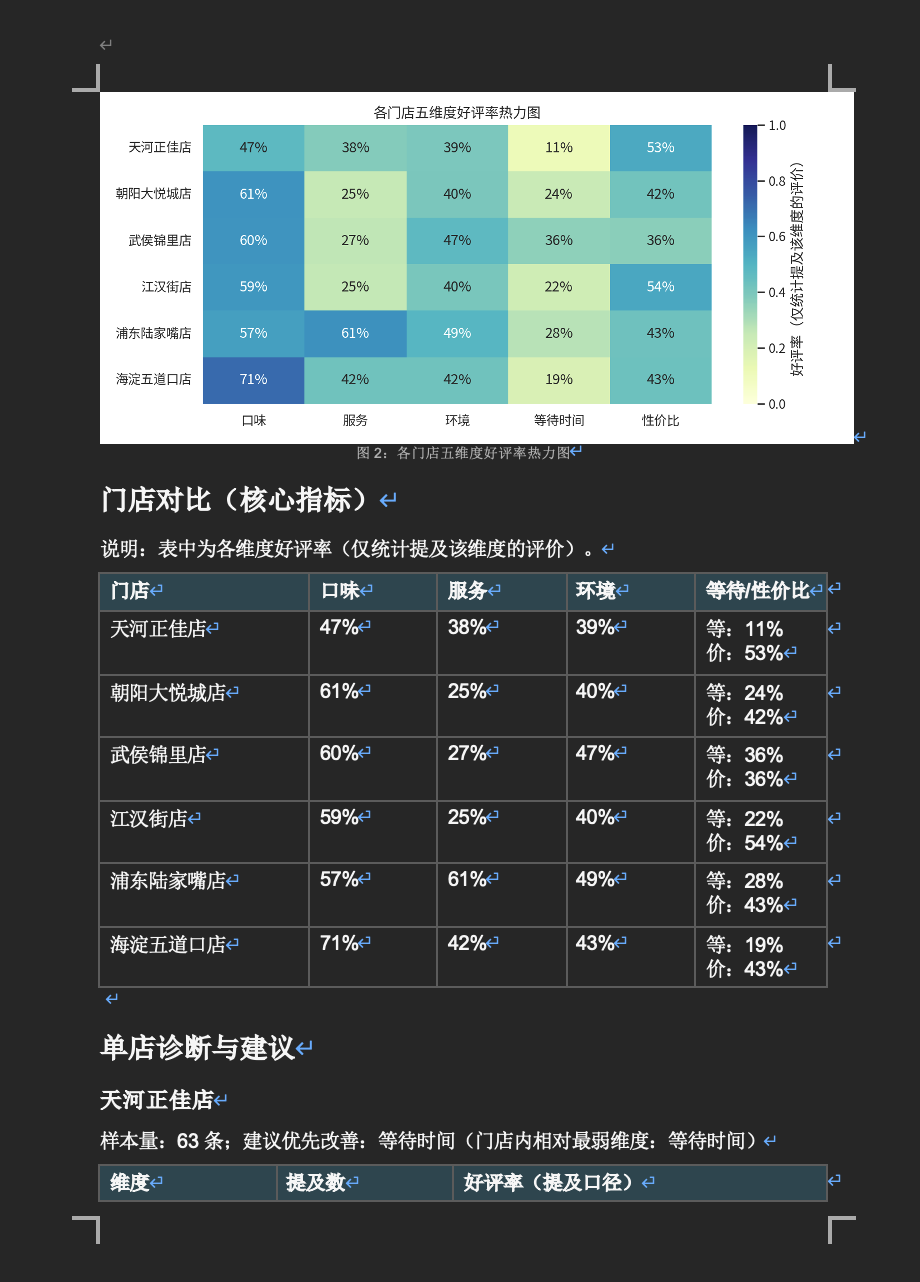
我们有 6 家门店共 400 条真实用户评价,需要对每条做情感分析(正面/负面/中性)+ 五维度打标(口味、服务、环境、等待时间、性价比),然后按门店汇总出诊断报告。
如果串行处理,400 条评价逐条做语义分析会很慢。这里直接告诉 Agent 用并行方式:
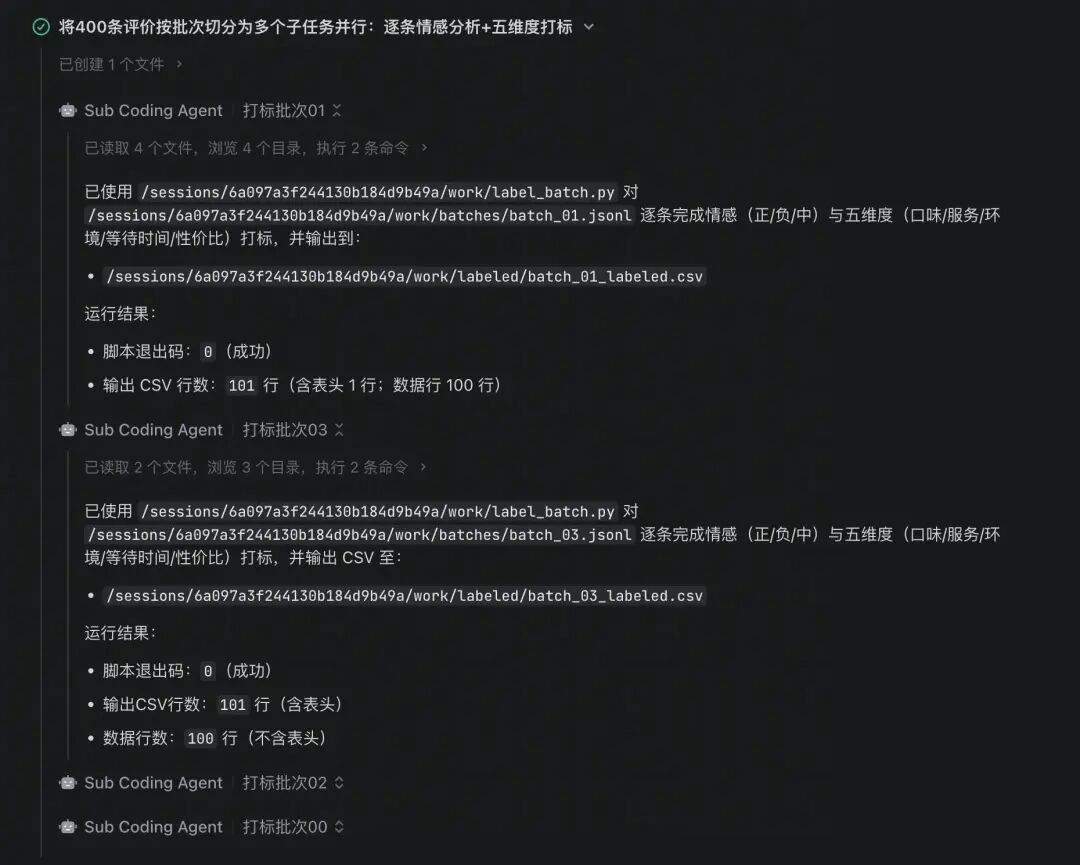
Agent 拿到任务后自动拆分为 4 个批次(每批 100 条),启动 4 个 SubAgent 同时处理,最后汇总结果、按门店统计、生成诊断报告。总耗时 18 分 42 秒:如果串行处理估计得翻倍。
▼ 图:一条 Prompt,Agent 自动拆成 4 批并行处理(总耗时 18m42s)

▼ 图:4 个 SubAgent 各自处理 100 条评价,互不干扰同时执行
▼ 图:最终产出 — 6 家门店诊断报告(含情感分布、五维度好评率热力图、改进建议)
左右滑动查看更多精彩内容
除了 SubAgent 并发,还有两种协作模式值得了解:
-
独立多 Agent:你手上有几份完全独立的数据,各自需要完整分析。直接开多个 Agent 会话并行处理,互不干扰。比如线上数据和线下数据各开一个 Agent,同时跑各自的分析
-
Plan → Execute:复杂项目先让一个 Agent 出分析方案(保存为文档),你审核确认后,再开新 Agent 按方案执行。规划和执行分离,避免做到一半发现方向不对

技巧三:目标驱动 – 说你要什么,不说怎么做
用基础玩法做分析时,你可能习惯了这样跟 Agent 对话:
-
“先帮我看一下各品类的平均售价和销量 ”
-
“再算一下每个品类的利润率”
-
“试试美妆品类提价 10% 利润会怎么变”
-
“再试试降价 5% 呢”
-
“把所有品类的最优价格都算一遍”
一步一步喂指令,本质上是你在思考策略,AI 只是帮你按计算器。
进阶的做法是:把目标直接丢给它,让它自己去想办法。
比如同样是定价分析,你可以这样说:
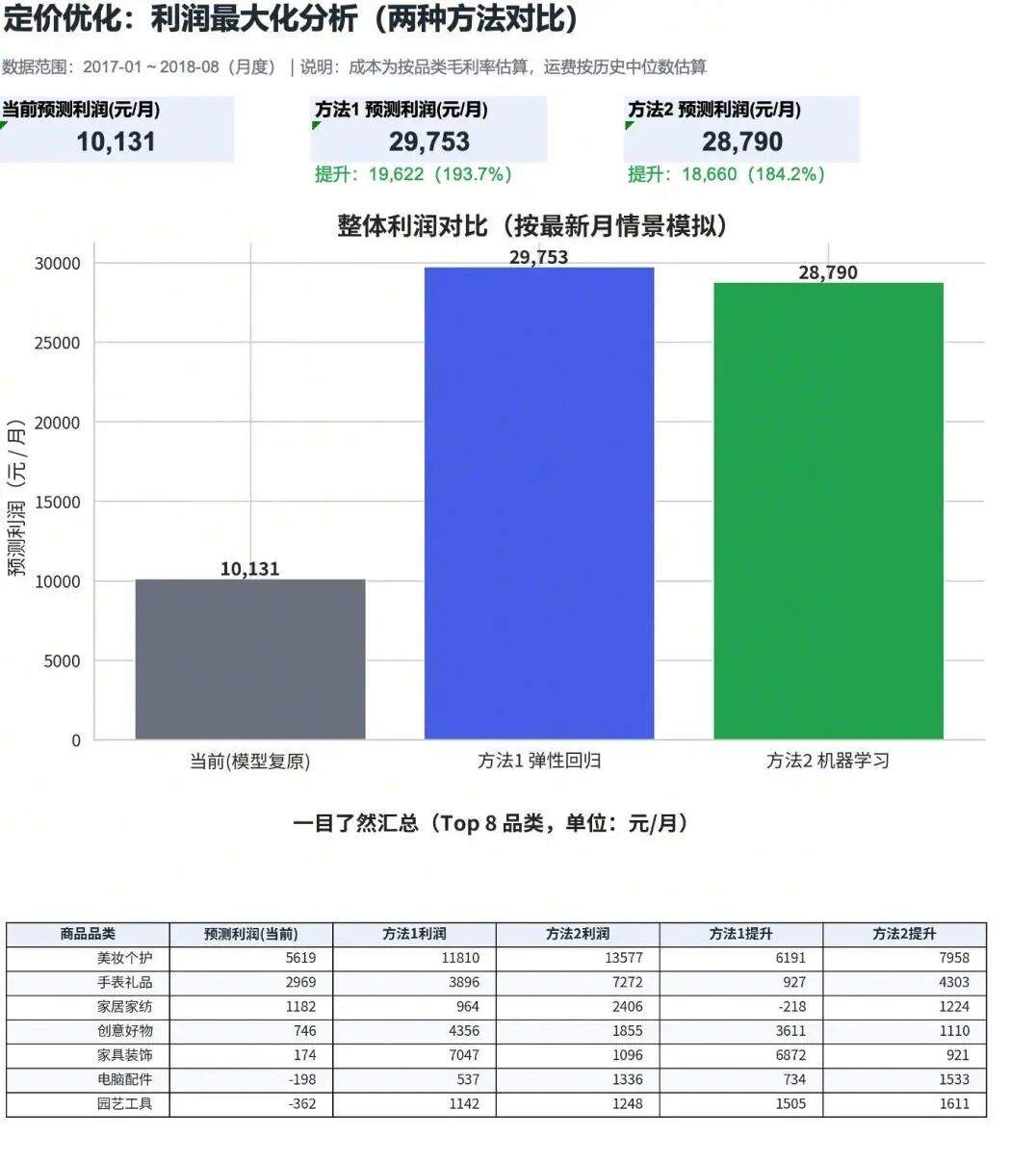
一句话说完,Agent 自己展开了一整套动作:读取数据 → 按行业常识给 9 个品类设定合理毛利率 → 用两种方法(价格弹性回归 + 机器学习模型)分别建模 → 找到各品类利润最大化的定价区间 → 交叉验证两种方法的结果 → 产出 Excel 报告和可视化图表。全程 7 分 40 秒,你只说了一句话。
▼ 图:一句话目标式 Prompt → Agent 自主完成全流程(耗时 7m40s,自动选择两种分析方法)

为什么 Agent 能做到?
因为它不是按固定脚本执行的:它每跑一步代码都能看到结果,然后根据结果自主决定下一步做什么。比如这个 Case 里,Agent 发现数据中没有成本字段,就自己按行业常识补上了毛利率假设;发现某些品类样本量不足以支撑复杂模型,就自动降级为更稳健的方法。
这就是 Agent 的核心能力:感知→判断→行动→再感知的循环:不是执行你写好的剧本,而是根据实际情况自主规划路径。
▼ 图:Agent 产出的分析看板 — 两种方法对比,利润预期提升 193.7%
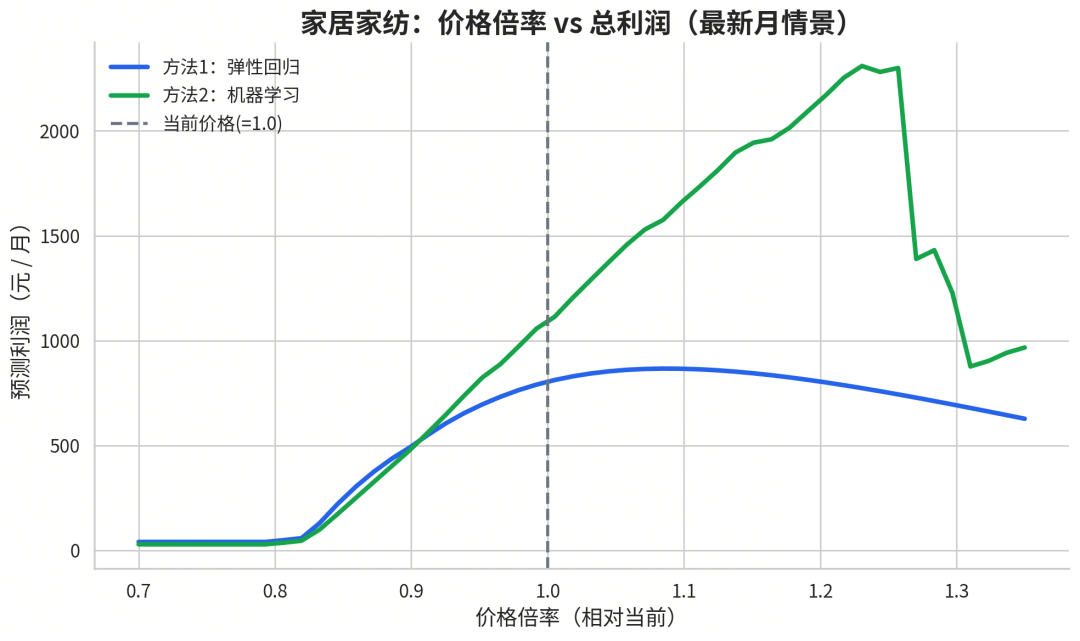
▼ 图:重点品类的价格-利润曲线 — 方法1(弹性回归)vs 方法2(机器学习),直观看到最优定价区间
怎么用好目标驱动?
-
描述终态,而不是描述步骤:“找到利润最大化的定价策略” 比 “先算A再算B再对比” 更能释放 Agent 的自主性
-
加约束条件:给 Agent 自由度的同时划好边界:“至少对比两种方法” “要靠谱点” “数据没成本你自己加合理假设”
-
建议尝试方向:你不必规定每一步,但可以提示 Agent 值得探索的方法或参数组合:比如”可以试试价格弹性分析和机器学习对比”。这样既给了自主权,又降低了 Agent 走弯路的概率
-
你仍然是审核者:Agent 操心“怎么做”,你把控“做得对不对”:看它的推理过程和结论是否合理

技巧四:AI 校准 – 出报告前,让 AI 自己查一遍
分析做完了,结论出来了,图表也画好了。你准备把报告发给老板:但心里总有点不踏实:数据有没有算错?前后引用的数字是不是一致的?结论有没有逻辑漏洞?
传统做法是你自己逐行检查,或者找同事帮你 review 一遍。但如果分析链路比较长(清洗→建模→多方法对比→可视化→结论),人工逐步核对既费时又容易漏。
进阶做法:让 Agent 自己审查自己的工作。
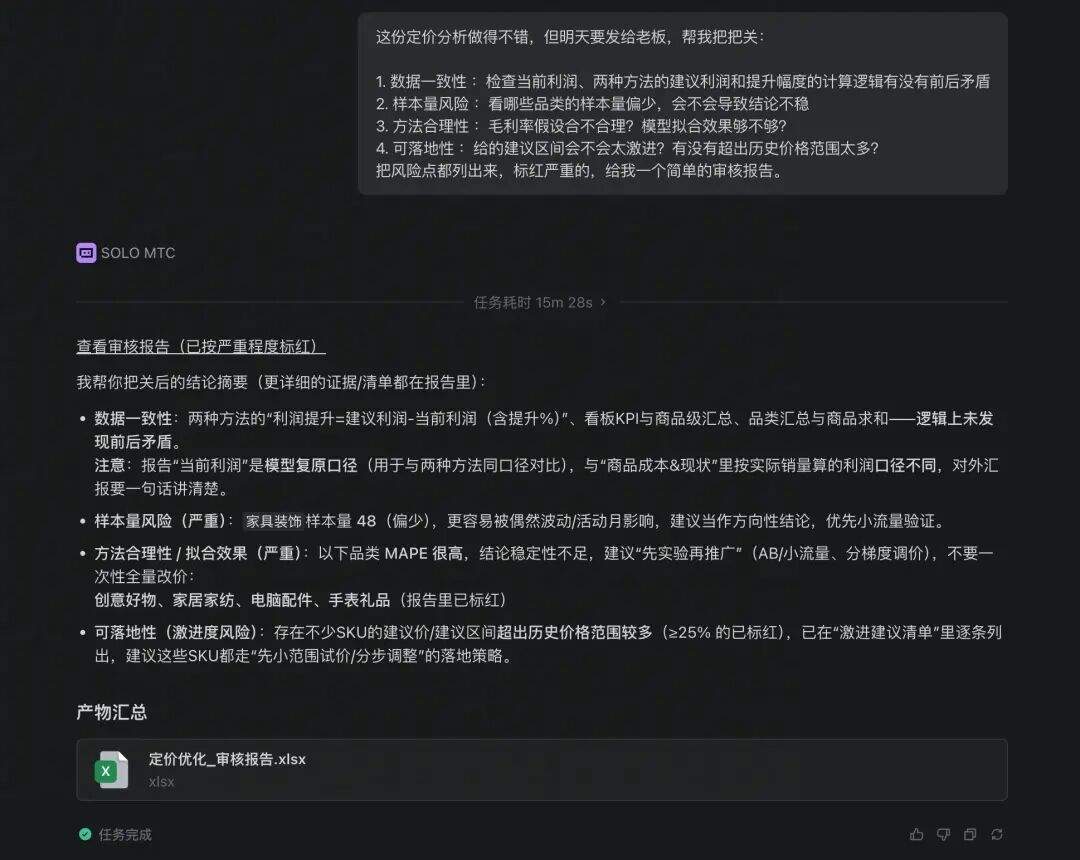
还是拿技巧三的定价分析来举例。分析报告做完了,明天要发给老板,你加一句:
这份定价分析做得不错,但明天要发给老板,帮我把把关:1. 数据一致性:检查当前利润、两种方法的建议利润和提升幅度的计算逻辑有没有前后矛盾;2. 样本量风险:看哪些品类的样本量偏少,会不会导致结论不稳;3. 方法合理性:毛利率假设合不合理?模型拟合效果够不够?4. 可落地性:给的建议区间会不会太激进?有没有超出历史价格范围太多?把风险点都列出来,标红严重的,给我一个简单的审核报告。Agent 花了 15 分钟,回去翻了之前所有的代码、数据文件和产出的 Excel,逐项做了实打实的核对,结果还真揪出了问题:
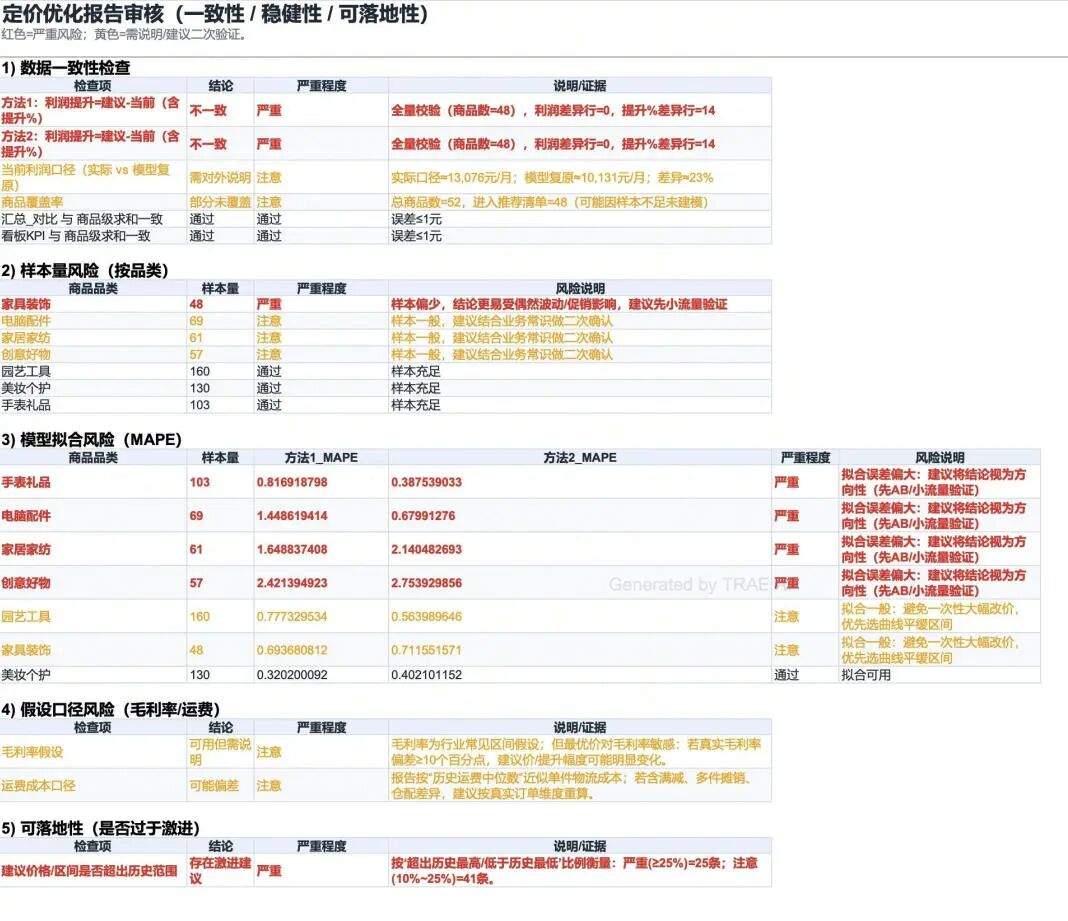
-
数据一致性:发现“利润提升%”有 14 行数据的计算结果和看板 KPI 口径不一致(看板用的是模型复原口径,明细表用的是实际销量口径)
-
样本量风险:家具装饰只有 48 条记录,结论更容易受偶然波动影响,建议先小流量验证
-
模型拟合风险:4 个品类的 MAPE 偏高(>1.0),结论应视为方向性参考而非精确建议
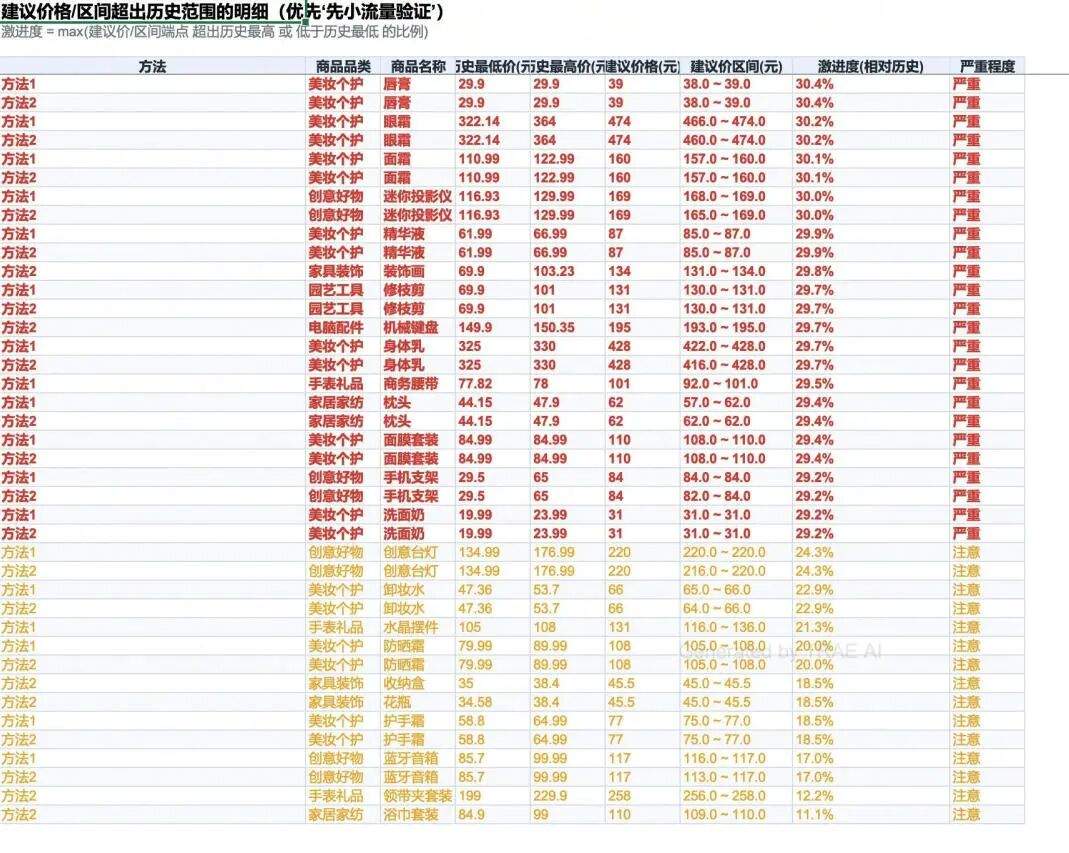
-
可落地性:25 条商品的建议价超出历史范围 ≥25%,标为“严重”:建议这些先小范围试价,不要一次性全量改价
▼ 图:一句话让 Agent 审查分析报告(耗时 15m28s)— 按严重程度标红输出
▼ 图:审核摘要 — 5 个维度逐项检查(数据一致性/样本量/模型拟合/假设口径/可落地性)
▼ 图:激进建议清单 — 逐条列出”建议价超出历史范围”的商品,红色=严重,需先小范围试价
为什么 SOLO 特别适合做这件事?
因为 SOLO 会保留完整的执行过程:每一步用了什么数据、代码逻辑怎么写的、中间产出了什么文件,全部在工作空间里可追溯。Agent 不是凭记忆审查,而是可以回去翻代码和数据文件做实打实的核对:所以才能发现“看板口径和明细表口径不一致”这种细节问题。

技巧五:Skill 沉淀 – 做一次好活,永远不用重复
你花了 8 分钟跟 Agent 对话,从数据清洗到趋势分析到区域下钻到生成完整报告,终于得到了一份满意的 2022 年度销售分析。
然后 2023 年的数据来了。你发现:得重新来一遍?
如果每次都从头开始,那 AI 只是帮你”加速了一次”,并没有帮你”解决重复劳动”。
进阶做法:把成功的分析流程沉淀下来,下次一键复跑。
实战演示:年度销售分析的 Skill 沉淀与复用
我们用的是一份超市销售数据(含区域、品类、子类别、销售额、利润、折扣等 20 个字段),按年拆成了 2022 / 2023 / 2024 三份。
第一步:首次完整分析(2022年数据)
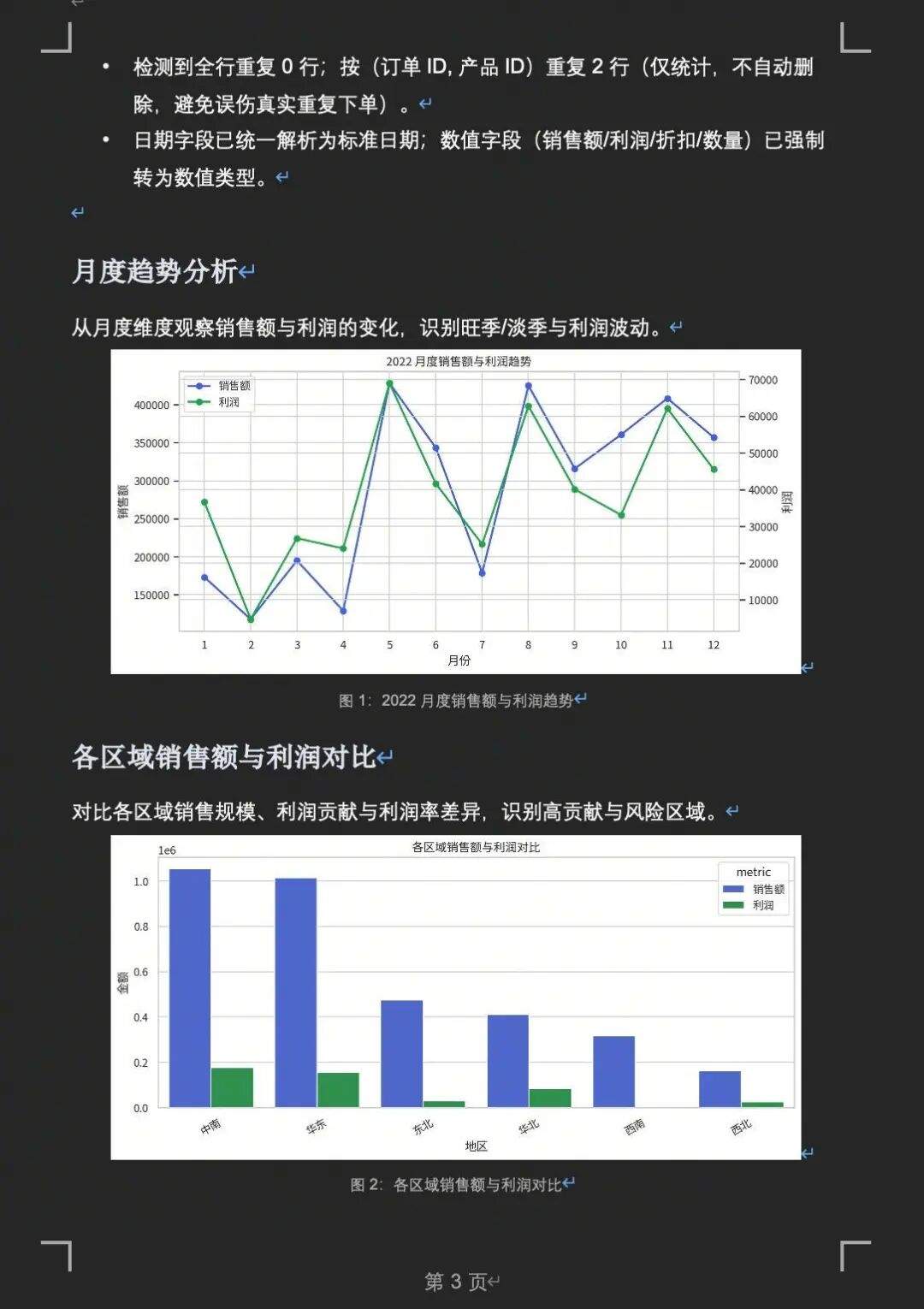
这是我们公司 2022 年的销售数据。帮我做一份完整的年度销售分析报告:1)数据概览和清洗;2)月度趋势图;3)各区域销售额和利润对比;4)各品类表现分析;5)找出表现异常的区域或品类并分析原因;6)生成一份包含关键发现和建议的分析报告。Agent 花了 8 分 29 秒,完成了完整分析链路:月度趋势分析 → 区域销售利润对比 → 品类利润率排名 → 子类别 Top / Bottom 排名 → 区域×月份利润热力图 → 生成 Word 格式报告 + 5 张可视化图。
▼ 图:首次分析的对话(耗时 8m29s,一句话出完整报告)

▼ 图:2022年度分析报告产出 — 月度趋势 + 区域对比 + 品类排名

第二步:沉淀为 Skill
分析结果满意后,告诉 Agent:
帮我把刚才的分析流程沉淀成一个可复用的 Skill,以后每年新数据来了可以直接调用。Agent 会把整个分析过程中的脚本(数据清洗逻辑、指标计算代码、图表生成代码、报告模板)打包成一个结构化的 Skill。
▼ 图:Skill 沉淀 — Agent 把分析脚本、图表逻辑、报告模板打包为可复用资产
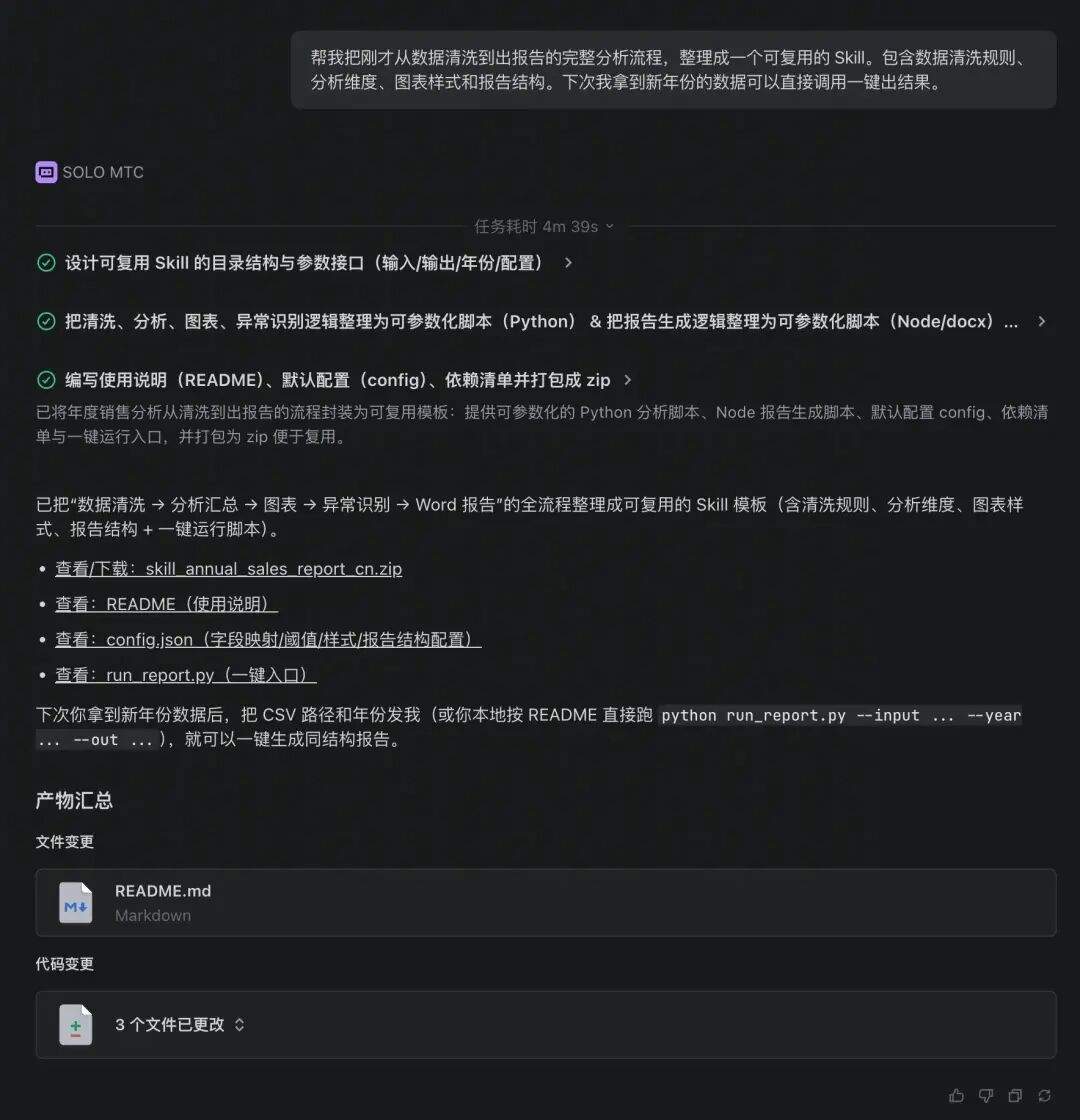
第三步:新数据来了,一键复跑
2023 年数据到了,你不需要重新描述分析需求,直接调用 Skill:
用刚沉淀的年度销售分析 Skill,对 2023 年数据跑一遍。Agent 按照之前沉淀的“说明书”自动走完全流程:同样的清洗逻辑、同样的分析维度、同样的图表风格、同样的报告格式。耗时从首次的 8m29s 降到 1m28s,你只说了一句话。
▼ 图:Skill 一键复跑(耗时仅 1m28s)— 同样的分析质量,十分之一的时间
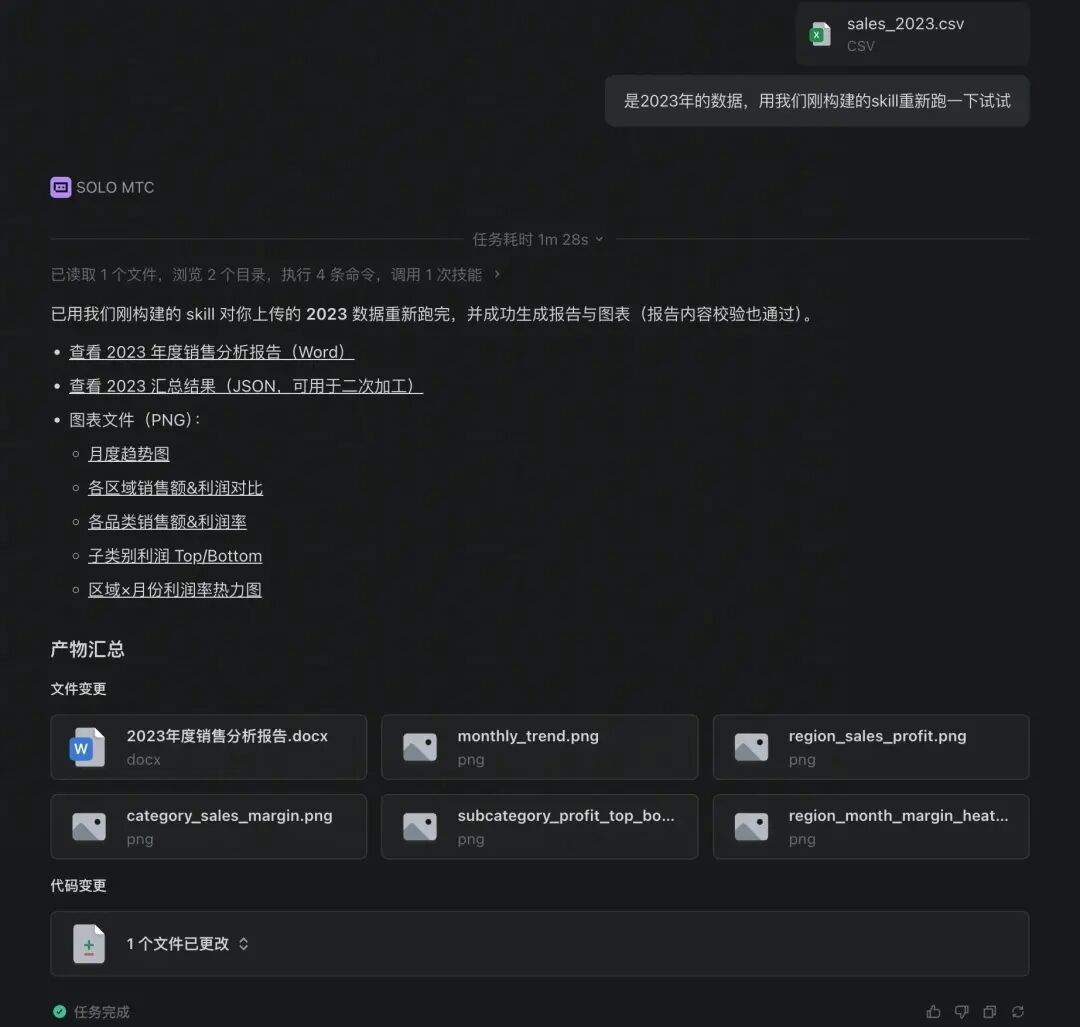
▼ 图:2023年度报告自动产出 — 格式、维度、图表风格与 2022 完全一致
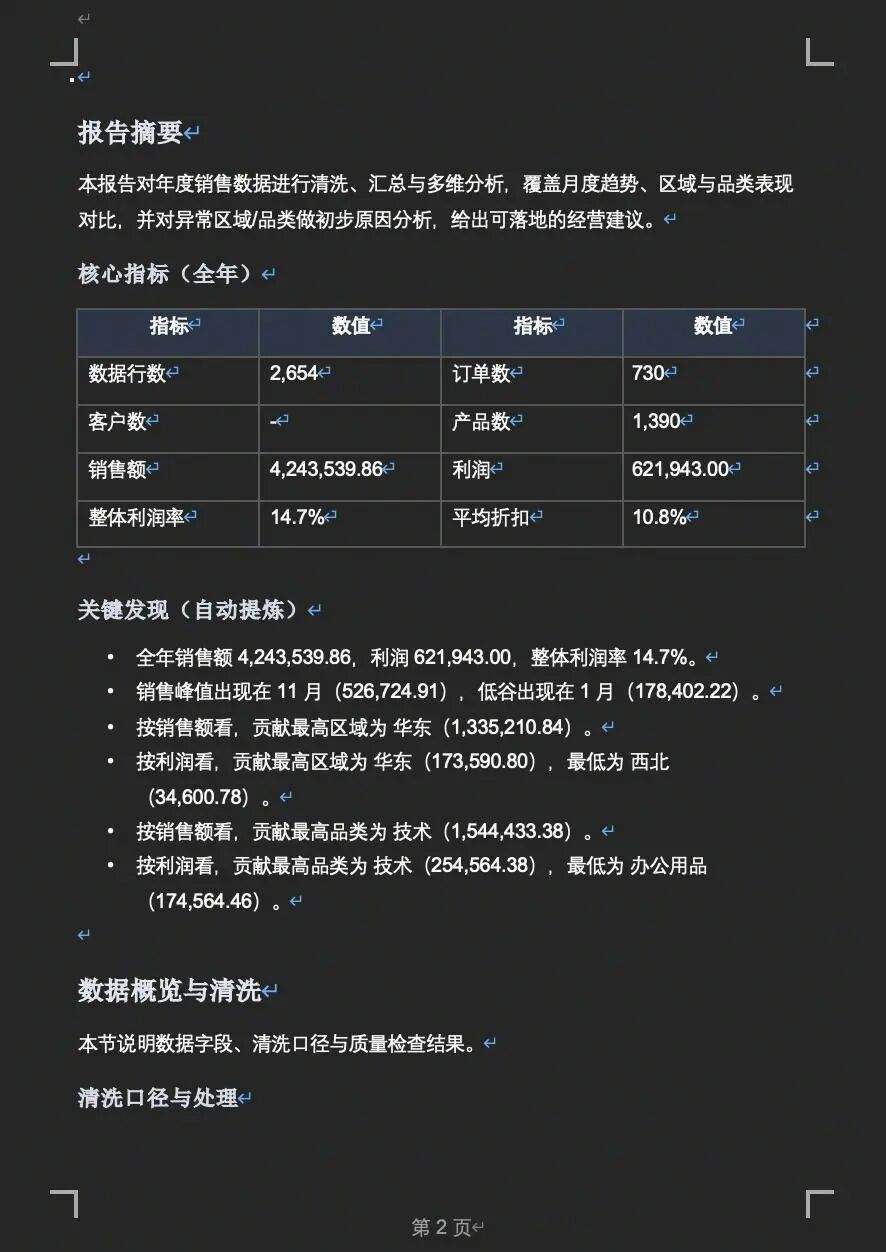
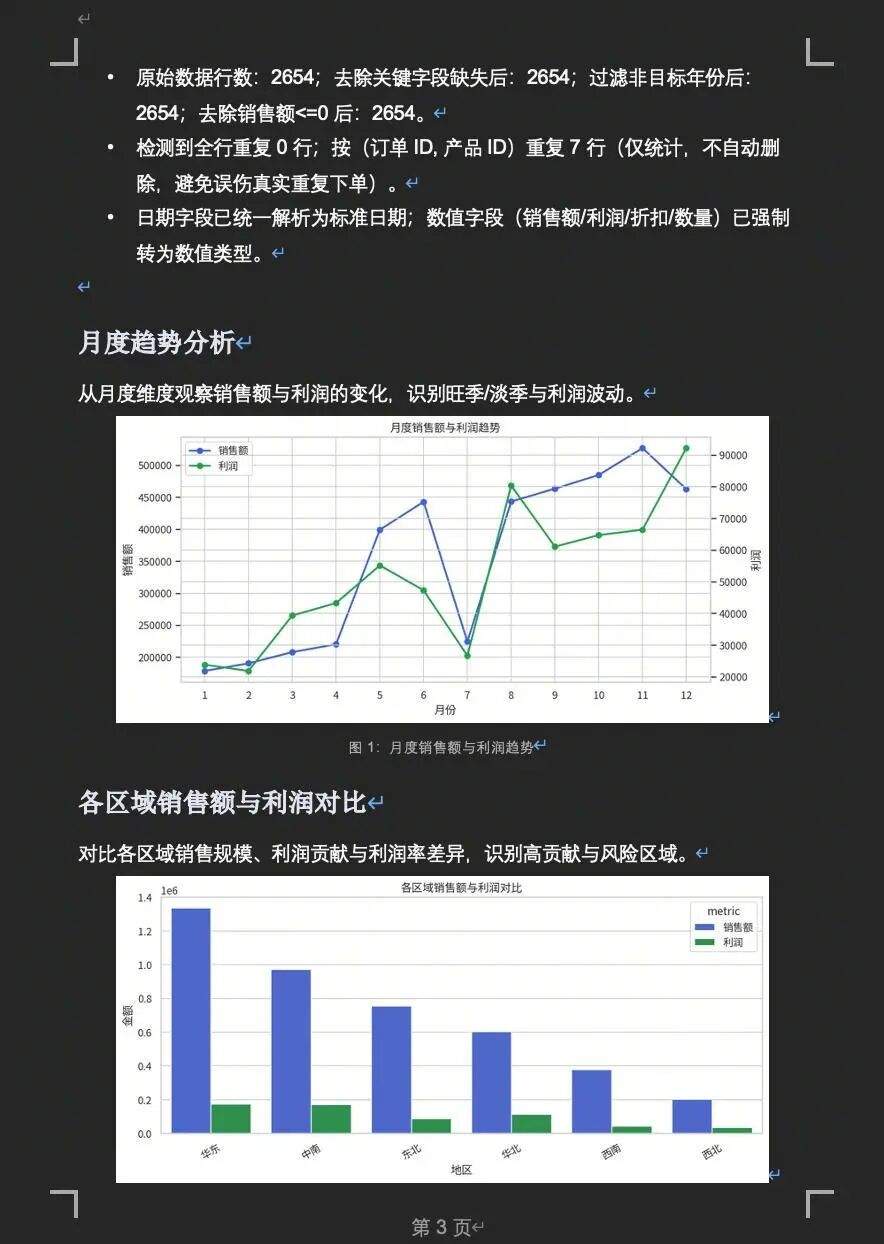
这里的“沉淀”远不只是保存一条 Prompt。
数据分析过程中产生的东西很丰富:数据清洗脚本、指标计算逻辑、可视化代码、报告生成模板、甚至分析方法论本身。这些中间产物全部保存在 SOLO 的工作空间里,可以整体沉淀为一套完整的分析资产。
本质上,你沉淀的不是一条指令,而是一整套分析方法论的编码化表达:数据怎么清洗、指标怎么算、图表怎么画、报告怎么写,全部包含在内。Agent 下次执行时,是在按照这整套”说明书”工作,而不是重新猜你想要什么。
Skill 的延伸价值:
-
团队共享:你沉淀的 Skill 可以分享给同事:新人无需培训,拿到 Skill 直接用,产出的分析质量和你一样
-
跨场景复用:年度销售分析的 Skill,稍微调整一下维度字段,就能用于季度运营分析
-
持续迭代:每次复跑后如果发现新问题或新需求,更新 Skill 即可,下次自动包含改进
-
和审校组合:Skill 里可以内置”最后一步做审校”的逻辑,每次复跑自动带质量检查

总结:你负责想什么,AI 负责做什么
当 AI 能把”做”的部分越做越好,你的精力该花在哪里?
我认为”想”的部分有三件事变得比以往更重要:
一、想清楚什么是重要的问题
AI 能帮你算任何你想算的东西:但”该算什么”这件事,只有你能决定。同样一份销售数据,问”帮我做个描述统计”和问”哪个区域在流失高价值客户?流失原因是什么?”:得到的价值完全不同。
当执行不再是瓶颈,提问能力就是你最大的杠杆。花时间想清楚”什么问题值得回答”,比花时间折腾”怎么算”重要得多。
二、想清楚怎么验证对错
AI 做得快,但不代表做得对。数据源是否可靠?筛选条件是否正确?样本量够不够?结论有没有逻辑漏洞?
这就是为什么”审校”那一步不是可选项,而是必选项。你可以让 AI 帮你做第一轮检查,但最终的判断力:”这个结论说得通吗?”:永远需要你来把关。
三、想清楚怎么让 AI 做得更好
这不只是”会写 Prompt”的问题。当任务变复杂,你需要知道什么时候拆成多个 Agent 并行、什么时候先出方案再执行、什么时候该沉淀为可复用的流程。这是一种新的”项目管理”能力:管理的对象从人变成了 Agent。
为什么 SOLO 是做这些事情更好的工具?
因为它的设计天然匹配”你负责想,AI 负责做”的分工:
-
你负责想问题 → Agent 有自主决策能力去规划路径和执行
-
你负责想对错 → 所有中间过程(代码、数据、逻辑)持久化保存,完全可追溯可审查
-
你负责想协作 → 共享工作空间支持多 Agent 协同,Skill 支持流程沉淀和复用