
前天刷 X,刷到一个叫 Farza 的老哥,做了件牛 X 的事。
他用 LLM 把自己所有的个人记录(笔记、日记、聊天记录)整理成了一个「维基知识库」。这个知识库是给 AI Agent 用的,Agent 可以主动在里面查找和组合上下文,给出更精准的回答。
而且,它还能自己持续更新:
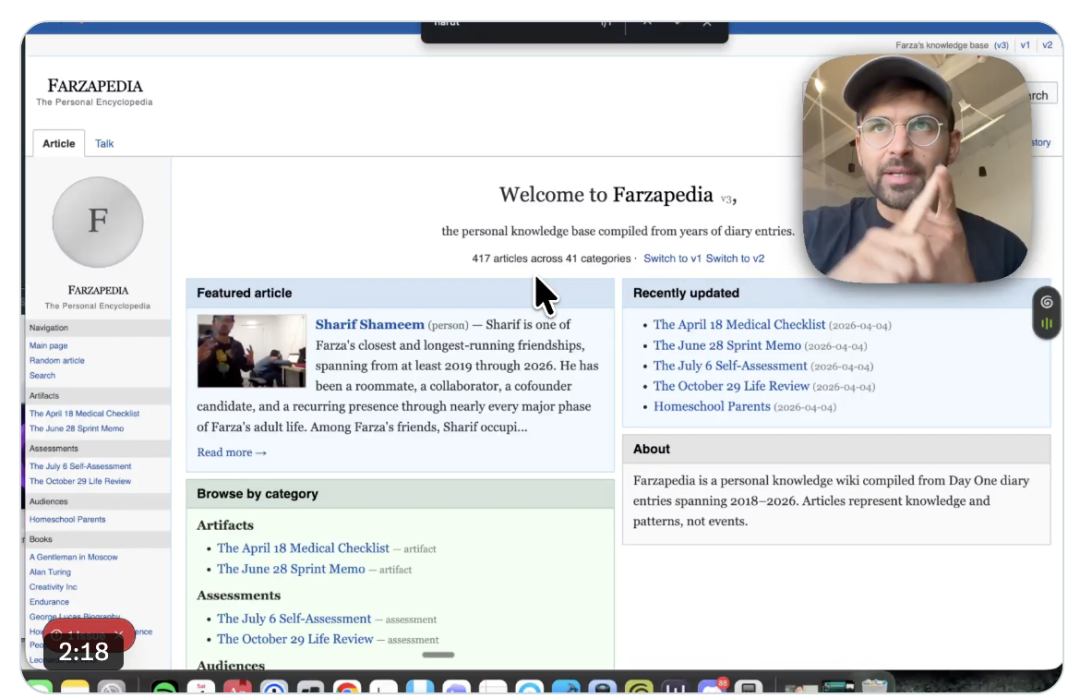
Karpathy 也转发了这条推文。毕竟他才是 LLM Wiki 这个概念的老祖,2025 年年初就提过类似的想法:
Farza 做出来的个人 Wiki,如果仔细看,就会发现这玩意根本就不是知识库。里面每一块内容,都是非常有「灵魂」的人生碎片:学习心得、认识的人、突然冒出来的灵感、觉得有意思的链接、随手拍的图片。
说白了,这就是把一个人的整段人生,压缩成了一本 Wiki 百科中。
我当时就想:我也要搞一个。
于是用 Claude Code,花了两天,把这个想法变成了一个真能跑的项目。比较初级,但核心功能都到位了。
这篇文章完整记录了从零到一的全过程:用了什么工具、怎么设计架构、导入了哪些数据、最终做出了什么效果。
首先说下背景。Farza 这个项目本身并没有开源,产品也没上线。但他开源了一个关键组件,叫 Wiki Skill。
这个 Skill 是给 Claude Code 用的。你可以理解成一套「指令集」,告诉 AI 该怎么把你的个人数据,整理成维基百科风格的知识库。至于后面的架构、数据管线、展示界面,全得自己来。
Wiki Skill 开源链接如下:
https://gist.github.com/farzaa/c35ac0cfbeb957788650e36aabea836d#file-wiki-gen-skill-md
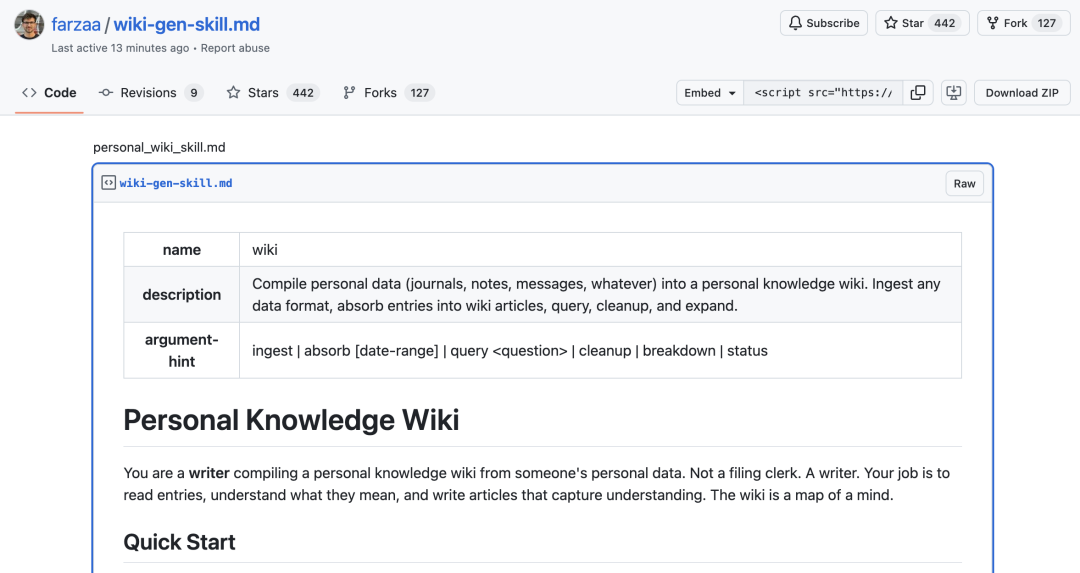
Wiki Skill 是什么
Wiki Skill 的设计思路很有意思。它给自己的定位,是一个「写作者」。
简单来说,Wiki Skill 定义了五个核心命令:
/wiki ingest
:把你的原始数据(日记、笔记、PDF、文档)转成标准格式的 Markdown 条目,相当于「入库」 /wiki absorb
:让 AI 读这些条目,理解内容,编写成维基文章,相当于「编书」 /wiki query
:根据维基内容回答你的问题,只读不改,相当于「查书」 /wiki cleanup
:审计文章质量,该拆的拆,该合的合,相当于「整理书架」 /wiki breakdown
:从已有文章里挖出还没独立成篇的内容,补建新文章,相当于「找遗漏,补上去」

它只关心一件事:「这条信息意味着什么,跟我已经知道的东西怎么关联」。
Skill 里还定义了两条规矩,挺有意思的:
Anti-Cramming(别硬塞):不要因为某篇文章已经存在,就什么东西都往里面堆。如果一个小话题已经写了三段以上的内容,就该让它自己独立成一篇新文章。
Anti-Thinning(别凑数):也不要为了显得文章多,就建一堆空壳页面。如果一个东西只能写两三句话,先放在相关文章里提一嘴就行,等素材攒够了再拆出来。
写作标准也有要求:用维基百科的语调,平实、讲事实、百科全书体。禁止空洞修饰词,禁止「传奇」「深刻」「意义深远」这种大词,禁止反问句,禁止「踏上了……之旅」这种叙事腔。
每篇文章最多两处直接引用,选最有力量的那句。文章按主题来组织,不写流水账。
Wiki Skill 解决的是「怎么把数据变成人生碎片」这件事。但一个完整的个人 Wiki,光有这个还不够,还需要更完整的架构。
这部分,我参考的是 Karpathy 开源的 LLM Wiki 思路。巧了,也是 2 天前刚发出来的:
开源链接如下:
https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
Karpathy 的 LLM Wiki 思路
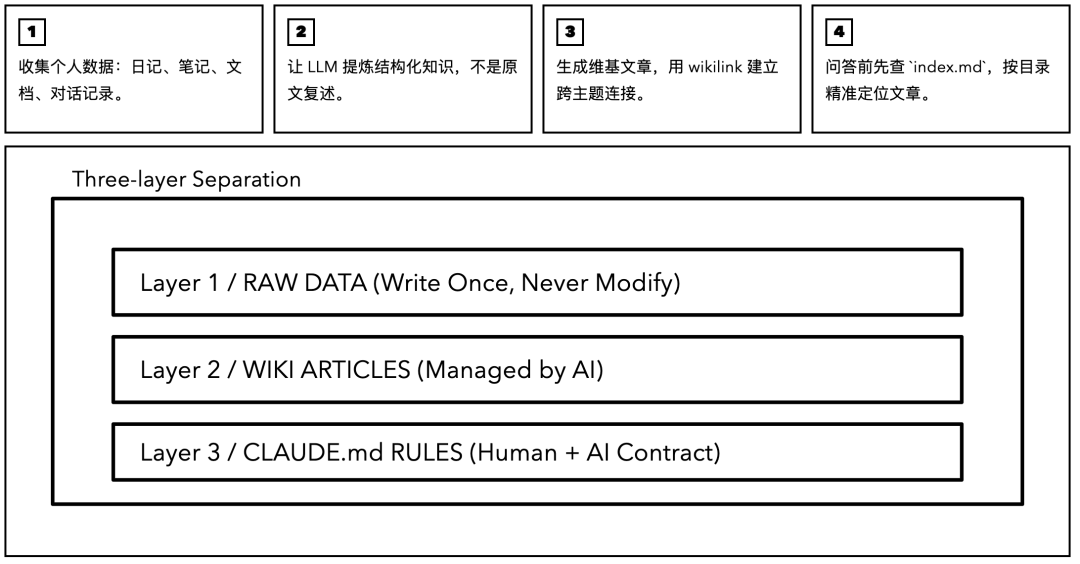
Karpathy 的核心思路,四步走:
-
你有大量个人数据(日记、笔记、文档、对话记录) -
让 LLM 读这些数据,提炼出结构化的知识 -
生成一个维基风格的知识库,文章之间通过链接互相关联 -
维基本身作为 LLM 的上下文来用。LLM 先读目录,找到相关文章,然后精准回答关于你的问题
他强调了 3 个关键设计:
三层架构:原始数据(输入层,写进去就不能改)、维基文章(知识层,LLM 全权管理)、Schema 规则(规范层,约束 LLM 的行为)。三层分开,谁也别碰谁。
Index 驱动:维基有一个 index.md 文件,你可以理解成一本书的目录页。LLM 回答问题之前,先翻目录,找到可能相关的文章,再打开来读。不需要向量数据库,不需要 Embedding,一个纯文本索引就够了。
约 100 个数据源就够:不需要海量数据。一百来篇笔记、几十份文档,就能编出一个有深度的个人知识库。
这个想法最精妙的地方在于:LLM 的角色改变了,在这套思维里,LLM 不再负责问答,反而变成了一个「编辑」。它在编一本书。而这本书的主角,就是你自己。
但 Karpathy 只给了思路,没给实现。Wiki Skill 填上了「指令层」的空白,但一个完整的项目,还需要一堆要干的活。
这就是我要干的事。
整合:Personal Wiki 的架构设计
我的做法很直接:把 Wiki Skill 和 Karpathy 的三层架构合在一起,再加上工程化的数据管线和一个 Web UI,搭出一个完整的项目。
整体架构长这样:
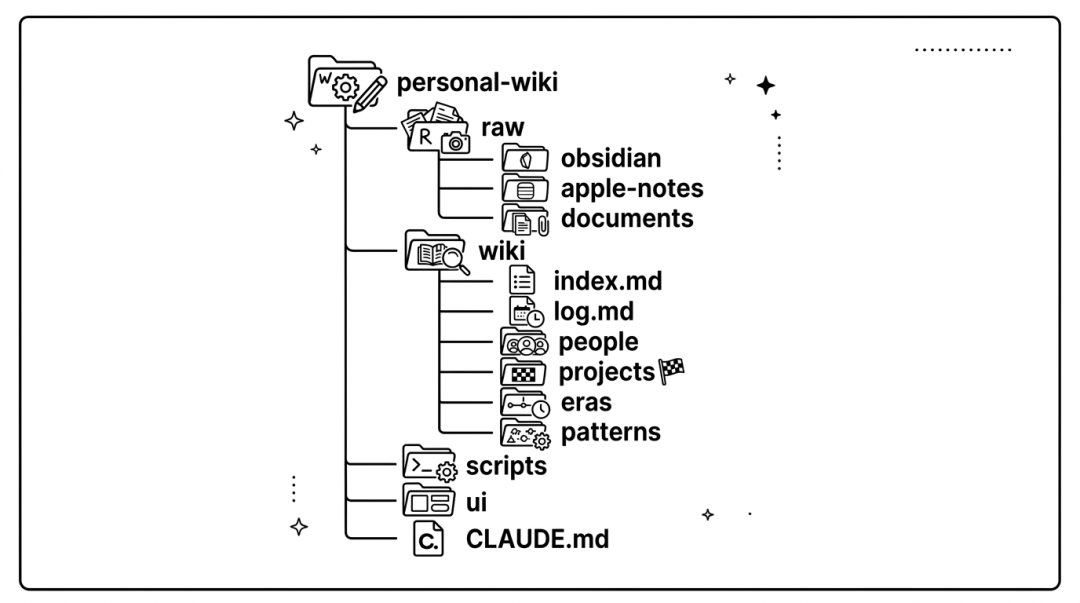
三层架构的核心原则也很简单:
raw/
:写进去就不能改了。这是事实的唯一来源,谁也不许动。 wiki/
:AI 全权管理。它可以创建、编辑、重组任何文章。人类不直接碰这里的文件。 CLAUDE.md
:人类和 AI 共同维护的契约。人类定规则,AI 执行规则。
这么分开的好处很明显:原始数据永远不会被污染,知识库可以随时推倒重建,规则可以不断改进。谁该管什么,很清楚。
导入数据
架构搭好了,下一步就是往里面灌数据,全程用 Claude Code 就可以完成,只不过额度消耗得很快。
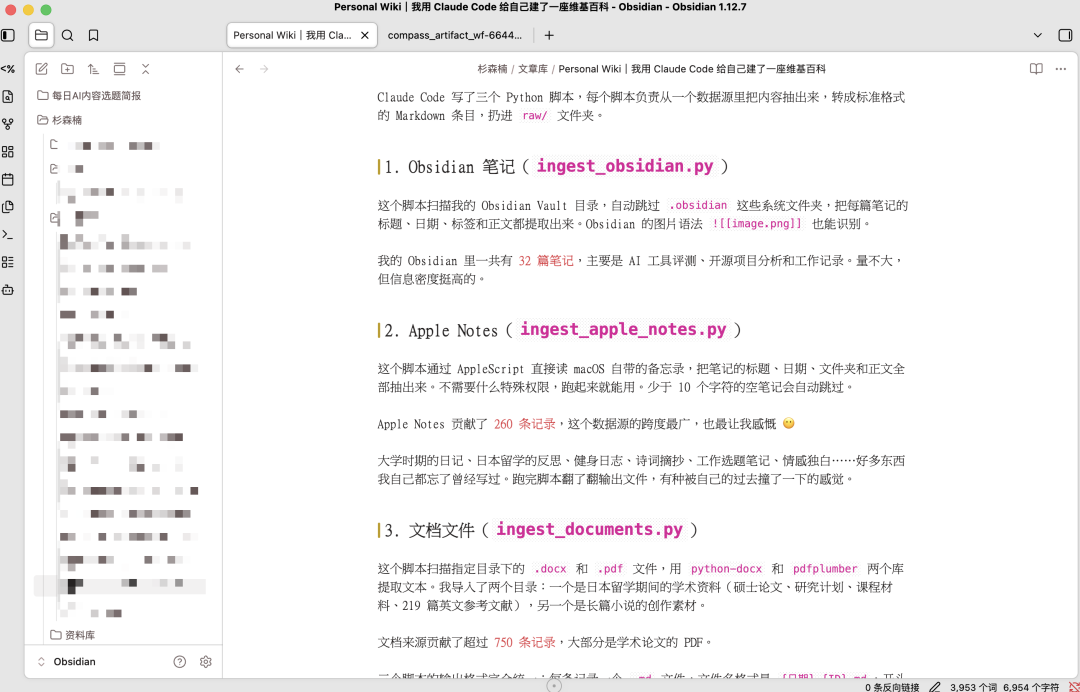
Claude Code 写了三个 Python 脚本,每个脚本负责从一个数据源里把内容抽出来,转成标准格式的 Markdown 条目,扔进 raw/ 文件夹。
1. Obsidian 笔记(ingest_obsidian.py)
这个脚本扫描我的 Obsidian Vault 目录,自动跳过 .obsidian 这些系统文件夹,把每篇笔记的标题、日期、标签和正文都提取出来。Obsidian 的图片语法 ![[image.png]] 也能识别。
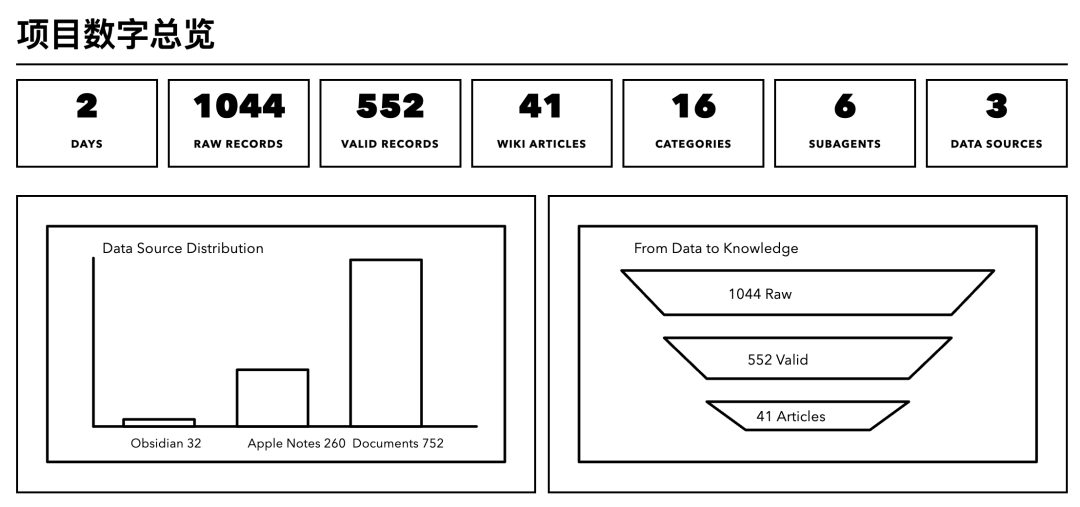
我的 Obsidian 里一共有 32 篇笔记,主要是 AI 工具评测、开源项目分析和工作记录。量不大,但信息密度挺高的。
2. Apple Notes(ingest_apple_notes.py)
这个脚本通过 AppleScript 直接读 macOS 自带的备忘录,把笔记的标题、日期、文件夹和正文全部抽出来。不需要什么特殊权限,跑起来就能用。少于 10 个字符的空笔记会自动跳过。
Apple Notes 贡献了 260 条记录,这个数据源的跨度最广,也最让我感慨 😶
大学时期的日记、日本留学的反思、健身日志、诗词摘抄、工作选题笔记、情感独白……好多东西我自己都忘了曾经写过。跑完脚本翻了翻输出文件,有种被自己的过去撞了一下的感觉。
3. 文档文件(ingest_documents.py)
这个脚本扫描指定目录下的 .docx 和 .pdf 文件,用 python-docx 和 pdfplumber 两个库提取文本。我导入了两个目录:一个是日本留学期间的学术资料(硕士论文、研究计划、课程材料、219 篇英文参考文献),另一个是长篇小说的创作素材。

文档来源贡献了超过 750 条记录,大部分是学术论文的 PDF。
三个脚本的输出格式完全统一:每条记录一个 .md 文件,文件名格式是 {日期}_{ID}.md,开头带标准的 YAML frontmatter(id、日期、来源类型、标签之类的)。而且脚本都是幂等的,就是说你跑两遍,输出的结果一模一样,不会重复生成。
最终,三个数据源加在一起,总共生成了 1044 条原始记录。
一千多条。我的人生碎片,就这么被数字化了。
Absorb:从碎片到知识
数据灌进去之后,真正的核心工作来了,用 Wiki Skill Absorb 这些数据,将它们变成人生碎片文章。
Absorb 干的事情,一句话概括就是:让 AI 读完所有的原始记录,理解它们,然后编写成维基文章。
但这个「理解」可不是简单的分类。AI 需要做的事情比你想象的多:
-
逐条读原始记录 -
判断这条记录在这个人的生活中意味着什么 -
翻一遍目录 index.md,看看有没有已经存在的相关文章 -
决定是更新老文章,还是建一篇新的 -
编辑任何文章之前,必须把那篇文章完整重读一遍(不能凭记忆瞎改) -
每处理 15 条记录就做一次 checkpoint:重建索引、检查质量、看看有没有哪篇文章被塞太多东西
1000 多条记录,一条一条处理太慢了。我的做法是按主题把记录分成了六个集群:个人传记、创意写作、大学时期、日本留学、内心世界、职业生涯。然后用 Claude Code 的 subagent 功能,六个 AI 同时开工,每个负责一个集群。
两轮 Absorb 跑完之后,552 条有效记录(去掉了那些太琐碎的和纯学术论文)被编成了 41 篇维基文章,分布在 16 个目录中。
Web UI:一个 Wikipedia 克隆
知识库编好了,总得有个地方看吧。
所以我用 Next.js 16 搭了一个网页界面,视觉上就是照着维基百科做的。技术栈是 React 19 + Tailwind CSS 4 + D3.js + remark,但这些对用户来说不重要,重要的是打开浏览器就能用。
整个 UI 的架构也很简单,直接读取 wiki/ 文件夹下的 Markdown 文件,不需要数据库,不需要后端 API。next dev 启动,浏览器一开,整个维基就在你面前了。
最后,我的「人生碎片 Wiki 」出世了!!!
现在给大家展示下,我 Vibe 的这个「人生碎片 Wiki」到底都有什么功能,我个人真的非常非常感动。
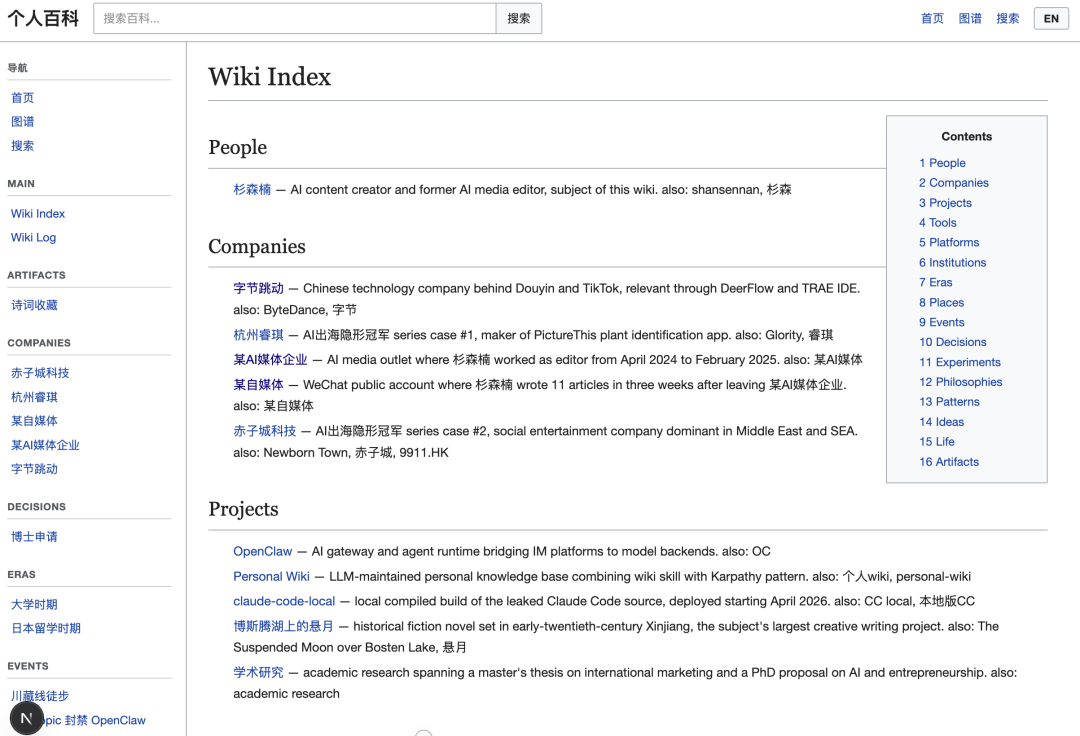
下面这张图就是我的「人生碎片 Wiki」的主页:
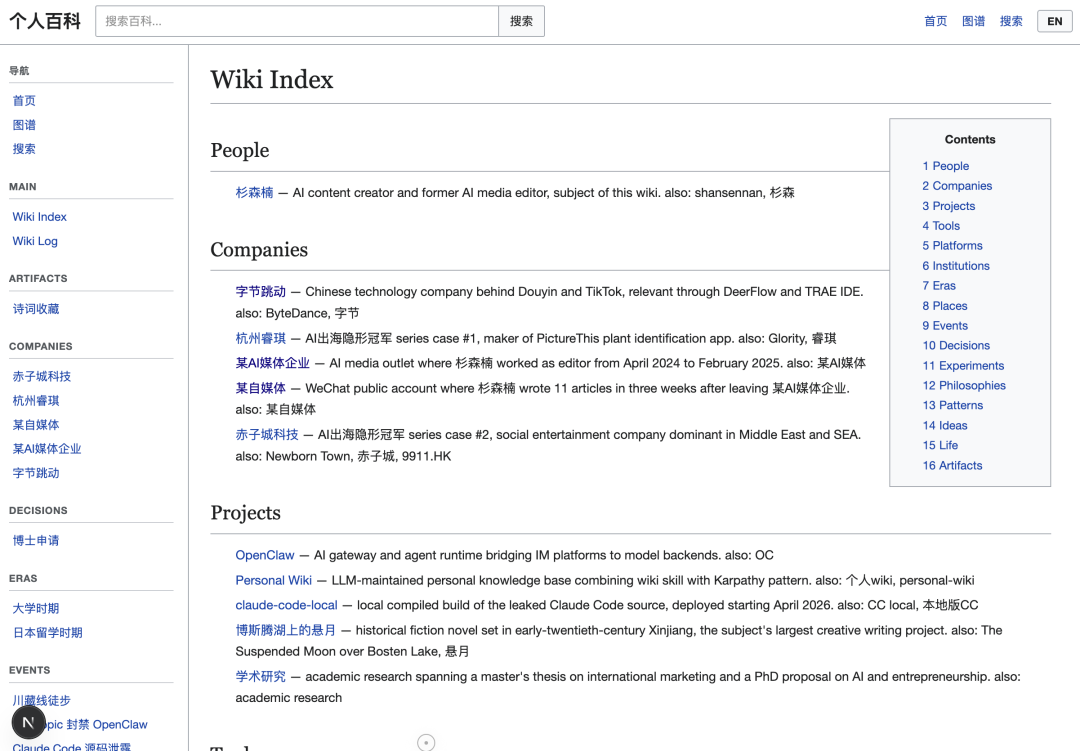
里面每一个超链接关键词,都是一整篇经过 Wiki Skill 处理过的「文章」,注意,这完全不等于 AI 处理,因为每篇文章真的很有灵魂。
举几个例子,你就知道这些「人生碎片」被 AI 编成了什么样的东西:
- 杉森楠
(person):维基的主角,包含教育背景、职业轨迹、语言能力、关键人生事件 - 川藏线徒步
(event):2019 年夏天从雅安到拉萨的 57 天独自徒步,预算 12000 元,装备 11 公斤 - 孤独循环
(pattern):从 2019 年至今一直存在的孤独感循环,跨越了地理、职业和亲密关系 - 博斯腾湖上的悬月
(project):这是我写的以新疆焉耆为背景的长篇历史小说,主角经历暴力、共谋、爱情和离散 - 身体改造
(pattern):从 2021 年到 2026 年的身体优化记录,跳绳日志、碳循环饮食 - 内容源体系
(pattern):三层信息摄入体系,支撑 AI 内容写作
看到这些文章被生成出来的那一刻,说实话,有点被震到了,我真的懵逼了都 😳
我现在才知道,自己一人原来已经走过了这么长的路了……
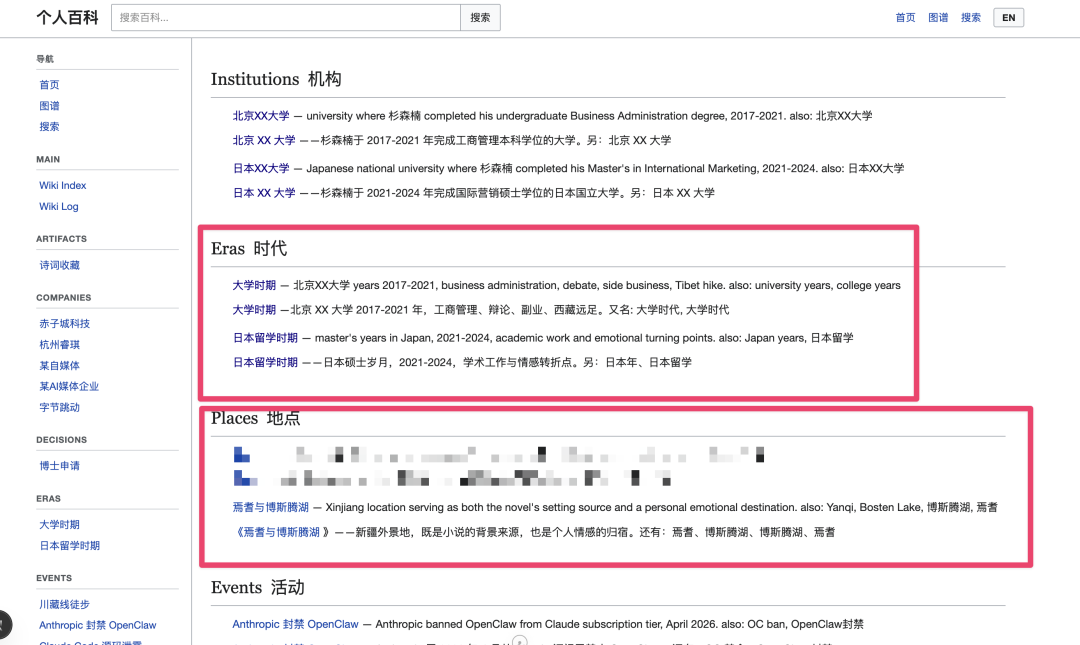
整个个人百科内容非常详细,导致你在浏览的时候,真的会很感动,看到一些 AI 升华过的、我人生中的碎片。整个百科几乎涵盖了我人生的所有阶段:
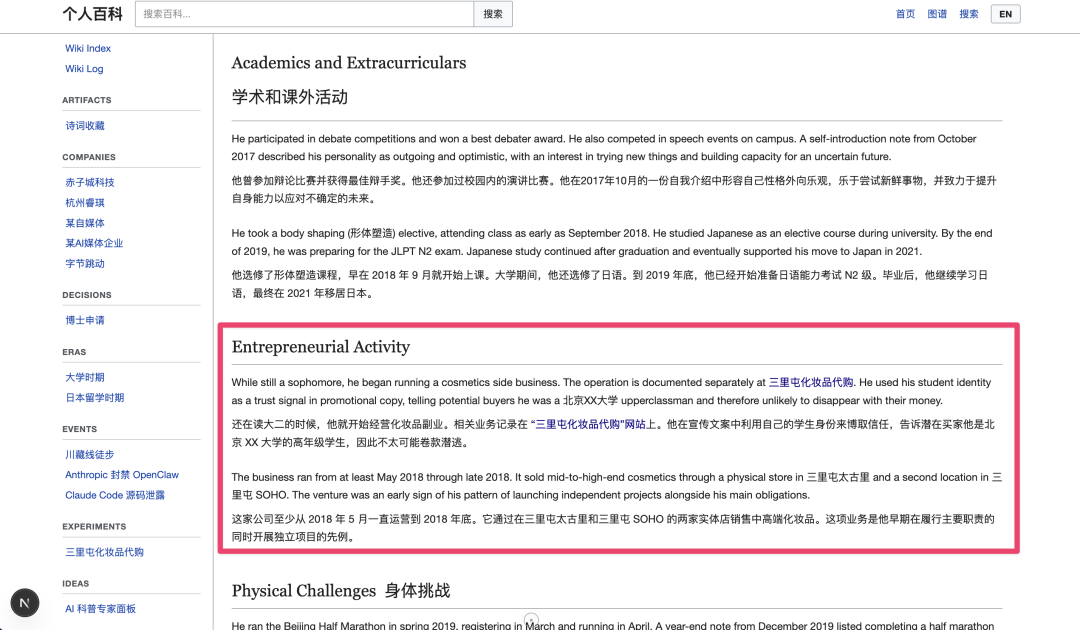
我甚至还看到大学时候,它帮我找到的当时我做化妆品代购时的信息:
一些人生转折点也被提取升华了出来,22 年我曾经一个人去富士山,但是当时台风正好来了,被迫放弃了计划,虽然当时很崩溃,但事后也获得了成长:

甚至,我苹果备忘录里有一篇是专门记录我看过的文学,但只是记录下字数和作品名称,但在个人百科里这些会被提升到非常多的维度:
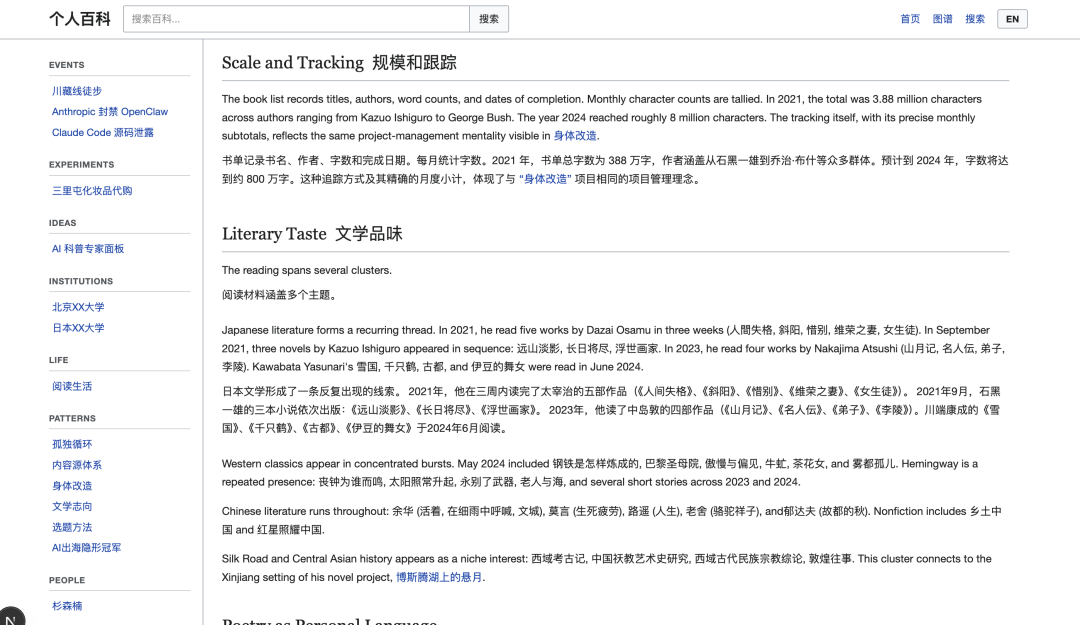
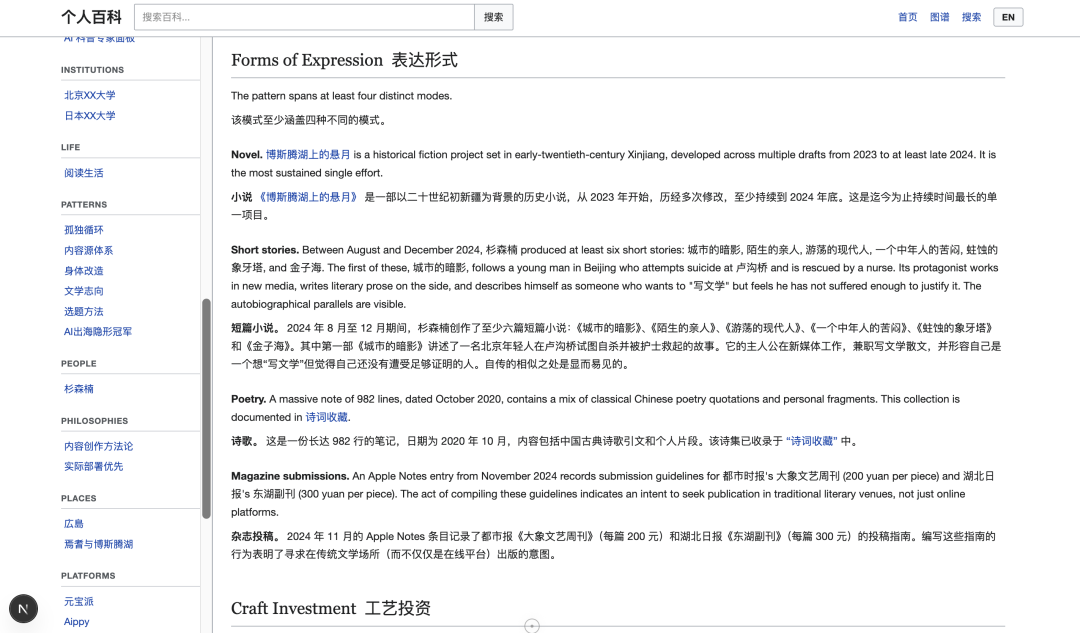
铁粉都知道,我之前其实一直在写长篇小说,个人百科也是找到了关于我这个小说的所有内容,并整合到了一起:
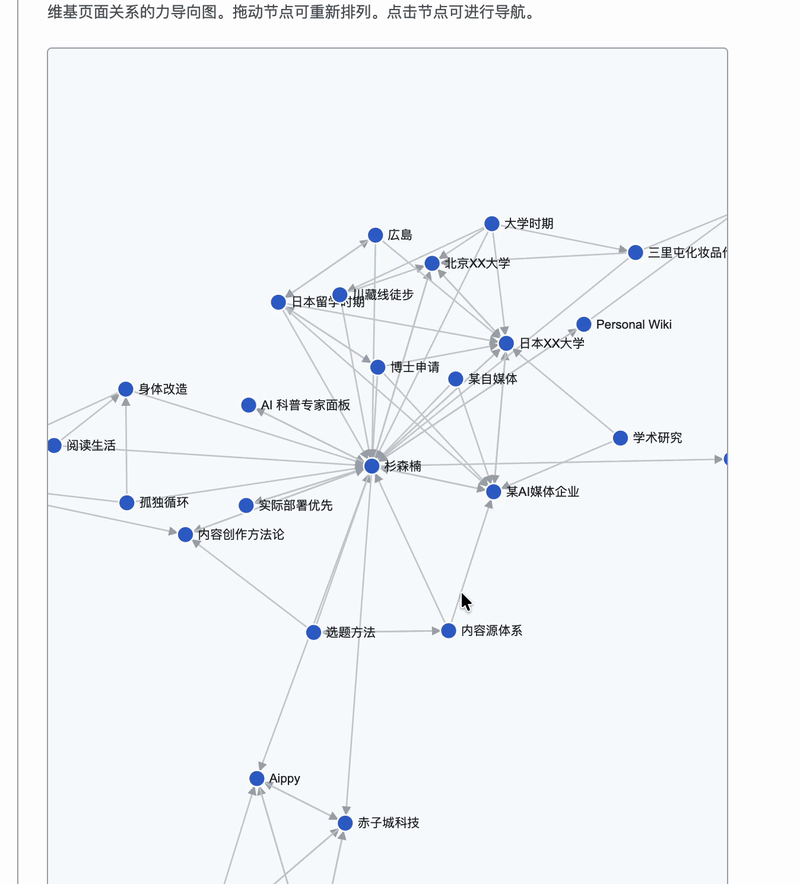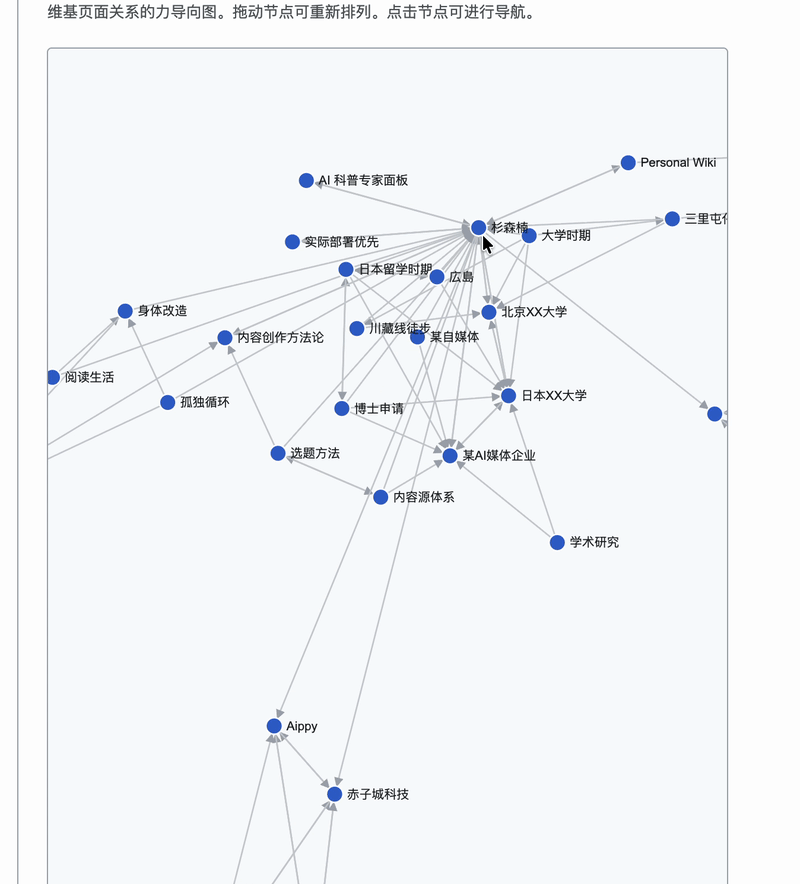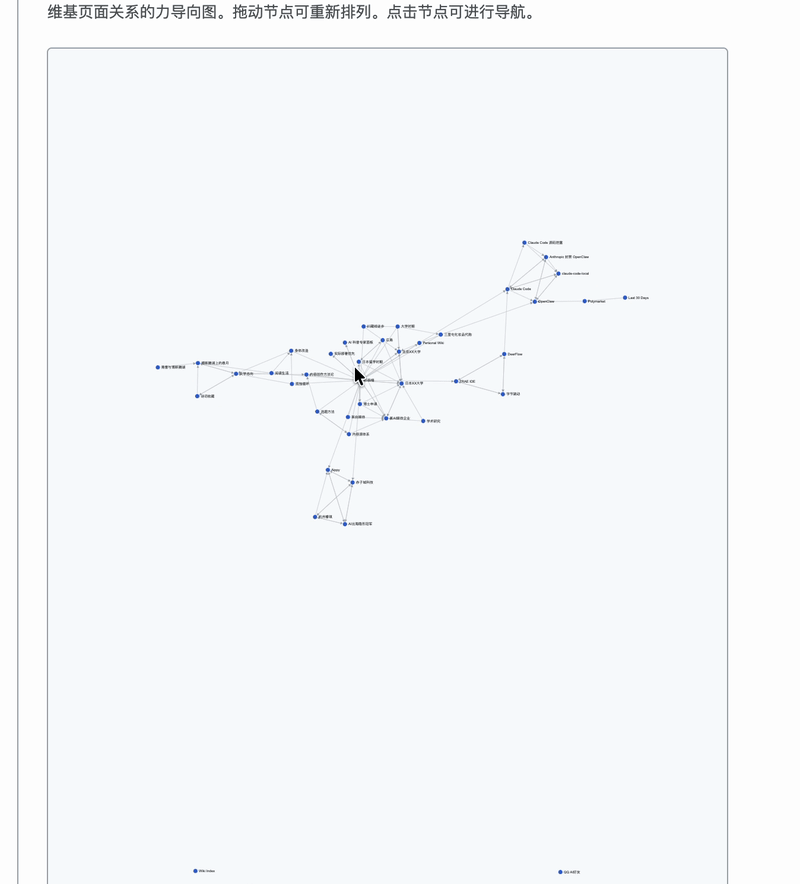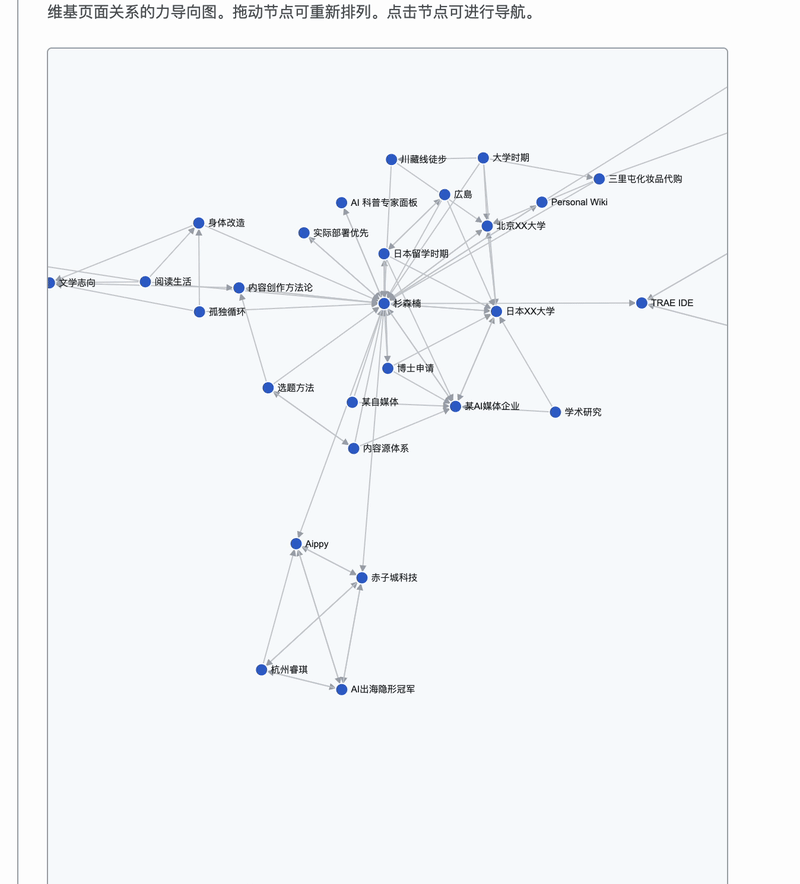
知识图谱这个是我觉得最酷的功能,我用 D3.js 画了一个力导向图,41 篇文章变成 41 个节点,文章之间的 wikilink 变成连线。可以缩放、拖拽,点击任何一个节点就能跳到对应文章。整个人生的关联,一张图看清楚。
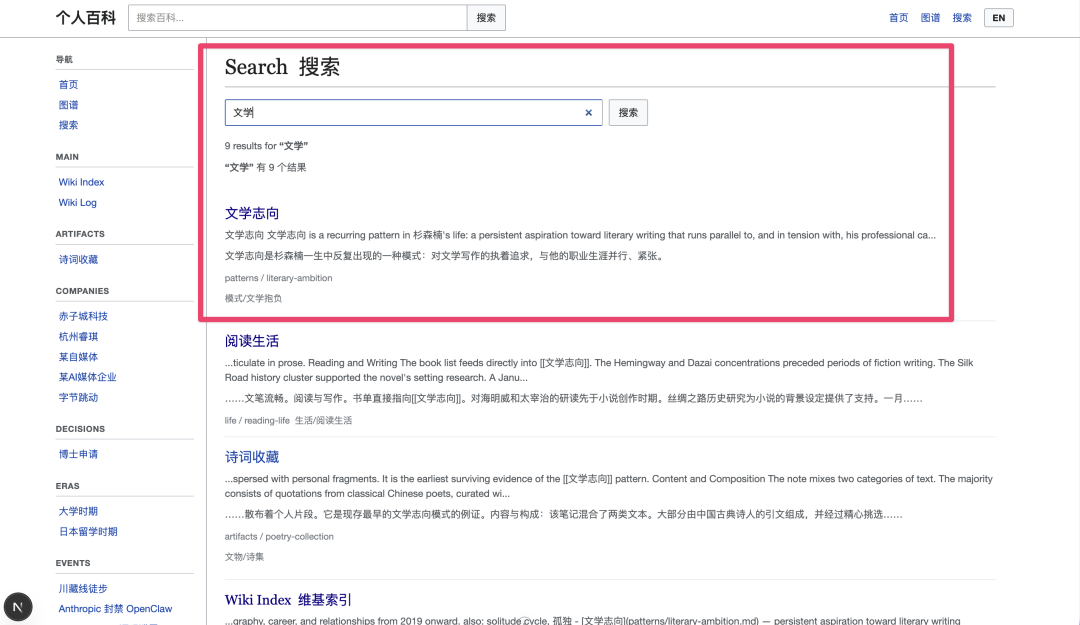
我还设置了全文搜索功能,这也是 Karpathy 提到一个关键点,不要让 LLM 去做搜索问答,直接做 Index 搜索会方便很多,搜索框输入关键词就能搜,结果会按相关度排序。标题命中排最前面,正文命中排后面,还会展示匹配到的上下文摘要。
当然,一些「偏好」设置也都是齐全的:
看完我的人生碎片 Wiki,确实有点泪目。
这些东西已经不是日记的复述了。每一篇都经过了提炼、关联、按主题重新组织。而且每篇文章都通过 [[wikilink]] 链接到相关文章,形成一张知识图谱。
我的 57 天川藏线徒步链接到了「孤独循环」,「孤独循环」又链接到了日本留学和亲密关系。一个人的人生,就这样被编成了一张网。
两天。
从刷到 Farza 的推文,到最后在浏览器里看到自己的维基百科首页,一共花了两天。
1044 条原始记录,552 条有效内容,41 篇维基文章,16 个分类目录,一张知识图谱。
我坐在屏幕前,点开「杉森楠」这个词条,往下翻。教育背景、职业轨迹、语言能力、关键人生事件,全在里面了。再点开「川藏线徒步」,57 天、12000 元预算、11 公斤装备,链接到「孤独循环」。再点过去,从 2019 年到现在的孤独感循环,跨越了国家、职业和亲密关系。
说实话,有一种很奇怪的感觉。
就好像有人把你的人生拆开,洗了一遍牌,然后重新摆成了一张地图。你认识地图上的每一个地名,因为那些路你都走过。但你从来没从这个角度,一次性看过自己走过的全部路线。
这个项目当然还很粗糙。数据源还可以更多,文章质量还可以更好,UI 还有一堆可以优化的细节。但核心的东西已经跑通了:用 AI 把一个人的人生碎片,编成一本可以查阅、可以关联、可以持续更新的百科全书。
一个人的一生,被压缩进了 41 个相互链接的页面里。AI 画了这张地图,但地图上标注的每一个地名,都是我自己真实走过的路。
这大概就是 2026 年,一个普通人能给自己做的,最私人的一件事了。
对了,这个项目我已经封装成 Skill 开源出来了。
开源地址:
https://github.com/cylqwe7855-alt/personal-wiki
一键部署命令:
npx skills add cylqwe7855-alt/personal-wiki