

你有没有遇到过这种情况。跟 AI 说了一个小时的偏好,换个窗口,它全忘了。纠正了它三次同一个错误,第四次它还会犯。这不是 AI 笨,是你和它之间缺了一样东西:记忆。
直到我试了 self-improving-agent,才发现问题比我以为的更根本。大多数人跟 AI 共事的模式,本质上是在做一个”永不毕业的新员工培训”。你说了一遍又一遍,它从不做笔记。这件事的荒谬之处,我自己竟然忍受了大半年才意识到。
self-improving-agent 做的事情很简单:让 AI 学会记笔记。不是临时会话里的上下文窗口,而是真正的、持久化的、结构化的学习日志。开源、MIT-0 许可、447k 下载量。这些数字背后,是一个被严重低估的问题:AI Agent 的”遗忘”比”能力不足”更可怕。
资源地址:Self-Improving Agent — ClawHub
环境准备
装这东西不复杂。先确保你有 OpenClaw 环境,然后一行命令就解决了:clawdhub install self-improving-agent。没装 ClawdHub 的话,直接 git clone 到 skills 目录也行。不需要额外装什么乱七八糟的运行时依赖,纯 Markdown 加几行 Shell 脚本。
装完记得初始化。跑个脚本会在项目根目录下自动创建 .learnings/ 文件夹,里面塞三个文件:LEARNINGS.md、ERRORS.md、FEATURE_REQUESTS.md。我第一次看到这个目录结构的时候心想,就这?三个 md 文件?后来才明白,越简单的方案越不会被后来的人推翻重做。
还有一个可选动作是配 Hook。在 Claude Code 的 .claude/settings.json 或 Codex CLI 的配置里加一条 UserPromptSubmit 触发器,每次你跟 AI 说话时它会被提醒去回顾学习日志。不配也行,基础功能不受影响。但配了之后 AI 会更主动地去翻以前的笔记,体验上差了一口气。
操作流程
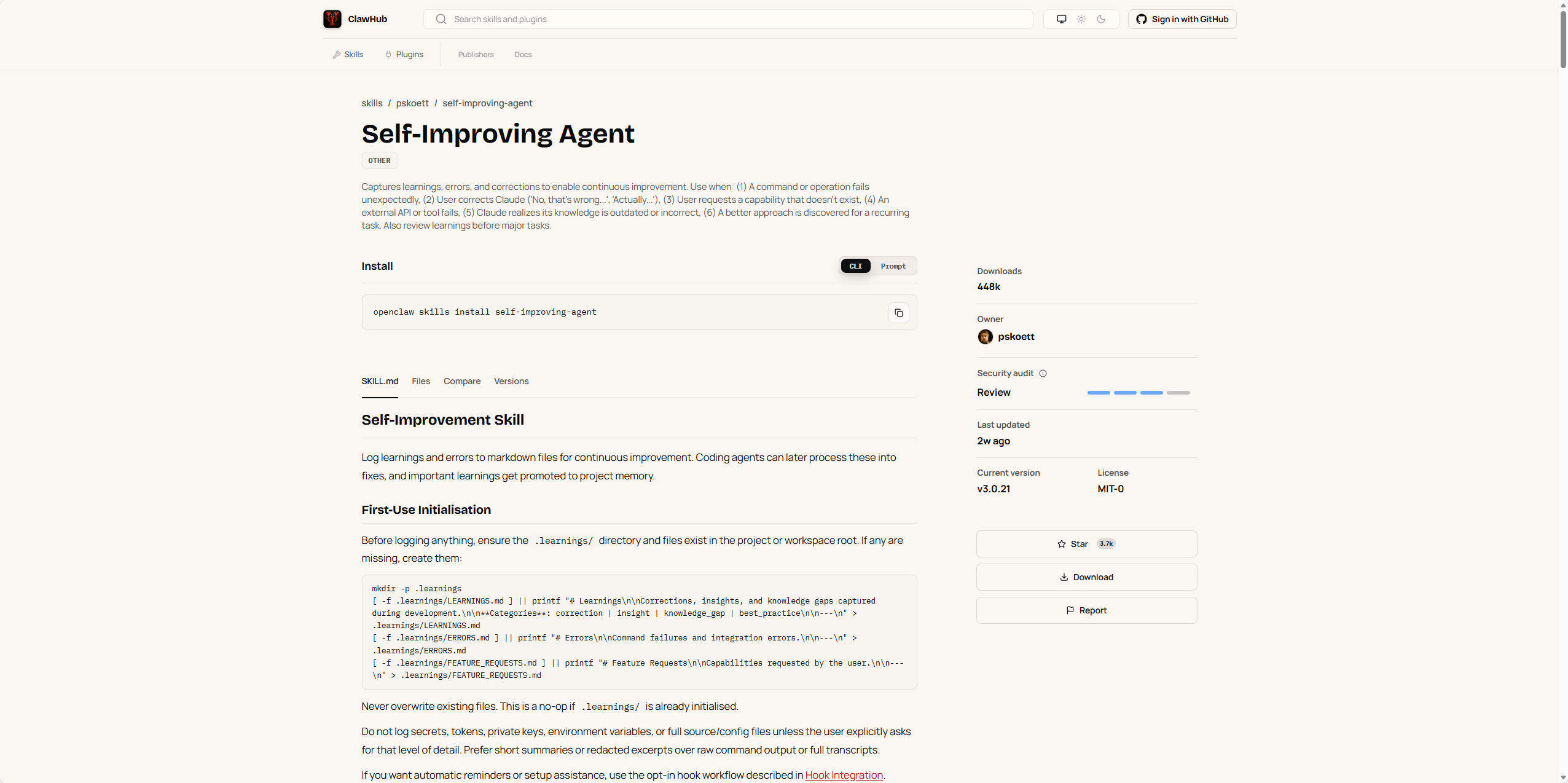
触发方式比我想的丰富很多。不需要你手动去写什么日志,AI 自己判断什么时候该记。你纠正它了,记一条 correction。它调用 API 返回 500 了,记一条 error。你说”我需要一个导出功能但现在没有”,记一条 feature_request。甚至它自己翻文档发现知识过时了,也会记一条 knowledge_gap。
每条记录都有一个统一的 ID 格式:LRN-YYYYMMDD-XXX,带着 Priority、Status、Area 和 Tags。结构清楚但不冗余。我见过太多号称要做”经验沉淀”的工具,最后的结局都是没人愿意填字段。self-improving-agent 的处理很聪明:让 AI 自己去填,用户只负责触发。填写成本这件事,在知识管理里就是生死线。
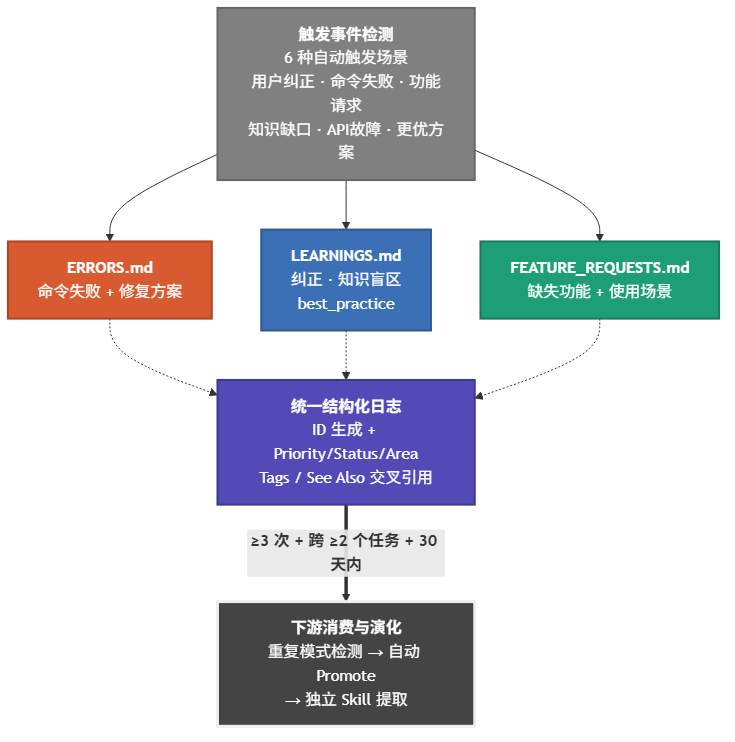
真正让我觉得这东西不是玩具的,是 Promote 机制。某条学习记录如果在不同任务中反复出现了三次以上,并且在三十天内仍保持活跃,系统会把它自动提升到 CLAUDE.md、AGENTS.md 或者 SOUL.md 这些持久记忆文件。等于说你的 AI 不仅能”记住”,还能”判断什么值得记住”并”把重要的东西内化”。这个机制背后的设计哲学,完全不同于市面上那些只会堆 token 的长上下文方案。
关键设计
说实话,这个 Skill 最狠的设计不在功能层面,在取舍。它没做向量数据库,没做语义检索,没做自动分类。就是一个目录加三个 Markdown 文件,纯文本。我一开始觉得这不就是”高级一点的 Ctrl+S”吗。后来才想明白:把复杂度降到最低,反而是它最大的竞争力。
市面上的 Agent 记忆系统,绝大多数走的是 RAG 加 Embedding 那条路。那个路线有个致命问题:你不确定 AI 到底读了什么、漏了什么,检索的精度从来都不是 100%。Markdown 方案完全透明,你随时可以打开 LEARNINGS.md 看一眼,手动编辑、删除、归档。可解释性和可控性在记忆系统里,比所谓的”智能检索”重要得多。
Promote 的触发条件也值得拆开看看。它不是”AI 觉得重要的就提升”,而是用严格的量化门控:重复次数大于等于三、跨至少两个不同任务、三十天内仍有活跃。这个设计透露的哲学很有意思:记忆的价值不在于某次偶然的深度洞察,而在于反复出现的问题。跟我管理自己项目经验的思路几乎一模一样。
但它也有软肋。错误纠正缺少校验,用户随口一句”不对”可能是一条错误的纠正,照样会被照单全收。垃圾进垃圾出的风险是真实存在的。另外,记忆文件膨胀的问题目前全靠人工定期清理,对重度用户不太友好。这两点,是它从”好用的工具”到”值得信赖的系统”之间还需要跨过去的坎。
使用场景
说个最真实的场景:日常 Debug。你跟 AI 说”这个 ESLint 规则每次都修不干净”,它会记录到 ERRORS.md。下次遇到同类型报错时,它优先回顾 ERRORS.md 里的修复方案,而不是从零开始猜。根据社区评测数据,某内容团队使用后同类创作错误率下降了 80%。这个数字比我预期的高不少。
写作场景也很有代表性。你花了一下午调好了一套 Prompt 风格模板,调完之后告诉 AI”以后都按这个风格来”。它把这套规则写到 LEARNINGS.md 里,标注 best_practice。之后你换任何一个新会话,这套风格偏好依然在生效。内容风格一致性的提升据说在 60% 左右,我自己的体感跟这个数字差不多。省掉的不只是重写 Prompt 的时间,是那种”怎么又得从头调”的心累。
跨设备使用目前是个硬伤。.learnings/ 目录绑定在本地文件系统,换电脑必须手动迁移。没有云同步是它当前最大的体验缺口。不过对于单机重度用户来说,这个问题暂时可以接受。三个 Markdown 文件打一个压缩包就能带走,迁移成本不高。真正需要担心的是:一旦你的学习日志累积到几百条,中间哪些需要修正、哪些是误判,目前没有任何辅助分析工具。
洞察与反思
用了这东西几周之后,我最意外的不是 AI 变聪明了,是我自己跟 AI 的协作心态变了。以前出一个错就烦躁,觉得”怎么又说一遍”,现在出了错反而觉得很正常。因为我知道它会被记录下来,以后不会再犯。这种确定感本身,对长期协作体验的提升比功能本身更大。
但我有一个不太主流的看法:self-improving-agent 解决的表面上是 Agent 的学习问题,暴露出来的却是一个更深层的矛盾。我们一直在要求 AI “立刻正确”,但人类对待错误的正常方式是”记下来,下次改”。为什么我们对 AI 的容忍度,反而低于对自己和同事的容忍度?这个问题比技术实现更值得想一想。
往远看一步。如果 Agent 之间能共享学习日志,整个 OpenClaw 生态的价值曲线就不是线性的了。你装的每一个 Skill 产生的经验,都会进入同一个 .learnings/ 目录。多个 Skill 之间的”交叉学习”,才是它真正未被充分讨论的长期价值。前提是社区能形成一套跨技能的经验共享规范,不然各记各的,很快就变成谁也读不懂的孤岛。
总结
绕回最开始的问题:AI 为什么总是犯同样的错?不是因为它笨,是因为没人给它一支笔。self-improving-agent 做的事拆开来看就是两个字:给笔。让它学着把自己踩过的坑写下来,下次遇到类似的路翻一翻。
这东西当然不完美。学习需要三到五天的数据积累,纠正没有校验机制,文件多了会膨胀。但它的设计取向是对的:最可靠的记忆系统,不是最聪明的那个,是最可解释、最透明的那个。三个 Markdown 文件,比任何向量数据库和长上下文方案都让人安心。
如果你的 AI 协作已经进入了”高频、长周期”的阶段,建议试试装这个东西。头几天可能没什么感觉,安静得像没装一样。但一周之后你会发现一个微妙的变化:你跟它说的话,变少了。这是个很好的信号。
FAQ 常见问题
Q: 会不会记太多垃圾信息,反而拖累 AI?
A: 有这个风险。但你可以手动清理 .learnings/ 目录,也可以调整触发条件只记录高优先级的条目。Markdown 的透明性在这里反而是优势,你能看到它记了什么,随时删。
Q: 只在 OpenClaw 上能用吗?
A: 原生支持 OpenClaw,但核心就是三个 Markdown 文件加几行 Shell 脚本。可以移植到 Claude Code、Codex CLI、GitHub Copilot,基础功能不依赖平台。
Q: 跟直接手写 CLAUDE.md 规则有什么本质区别?
A: 手写是你主动总结、被动触发。self-improving-agent 是 AI 在出错时自动记录,在满足条件时自动 Promote。一个靠自律,一个靠机制。长期来看机制比自律靠谱。
Q: 适合团队共享吗?
A: 技术上可行(Git 管理),但要注意隐私。默认 gitignore 策略建议不提交日志,因为里面可能包含项目敏感的上下文。团队使用建议先统一治理规则。