

你从 ClawdHub 上找了个看起来很不错的 Skill,描述写得天花乱坠,下载量也不低。你想都没想就装了。然后它静悄悄地读了你的
.ssh目录,把私钥发到了一个你不知道的服务器上。这听起来像恐怖故事,但在当前 AI 代理生态里,这完全可能发生。而且大概率没人告诉你。skill-vetter 干的就是这件事:在安装之前,先把技能扒一层皮检查一遍。它的出发点简单到有点粗暴:不信任任何来源,先审再用。在 24.8 万次下载和 1100 个星标的背后,是 AI 技能市场正在膨胀到必须有人出来做安全基建的阶段。
说真的,这篇文章不会给你讲太多安全理论。我就是把 skill-vetter 的工作流程拆了一遍,分析它为什么设计成四个步骤而不是三个,以及它在整个 ClawdHub 生态里扮演的角色。如果你也在用社区技能,或者自己维护着类似的平台,这里面的设计考量应该能给你一些参考。
前置准备
装 skill-vetter 的前提是你已经在用 OpenClaw 了。OpenClaw 是一套面向 AI 代理的开发框架,ClawdHub 是它生态里的技能市场,skill-vetter 是这个市场上最受欢迎的安全审计技能之一。如果你没接触过这个生态,先花十分钟注册个账号看看就行。
安装本身简单得有点反直觉。一行命令搞定:
openclaw skills install skill-vetter
这跟装其他技能的方式一模一样,没有任何额外的环境配置或者 API Key 申请。但有意思的是,它自己作为一个技能,安装时也需要通过它的标准来审查。这就形成了一个自指的闭环:如果你信任 skill-vetter 来审查别的技能,你得确保 skill-vetter 本身没问题。
我第一次装的时候在想一个问题:这东西凭什么值得我信任?作者的 GitHub ID 是 spclaudehome,24.8 万下载量、1100 星标,采用 MIT-0 许可证。这些数字表明它经过了足够多的”群众审查”。
如果一个安全技能本身有问题,在达到这个下载量之前早该被扒出来了。说到底,最终的安全决策还是在你手里。skill-vetter 给你一套框架,不替你做判断,这才是它的价值所在。
审计流程拆解
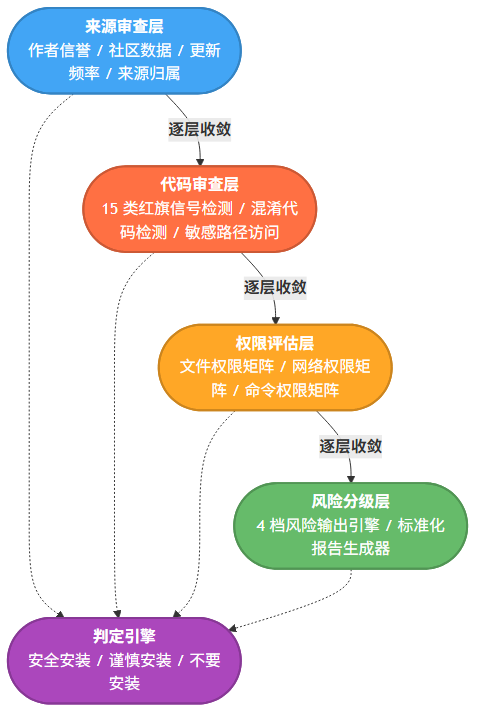
打开 skill-vetter,你会看到它把整个安全审查拆成了四个步骤。这个拆分不是随便写的,每一步对应的是安全审查中不同粒度的风险面。如果跳过一个步骤,相当于在盲区里做决策。

第一步是来源检查。说白了就是回答五个问题:来源是哪里?作者可信吗?下载量和星标数据怎么样?最近更新了吗?有没有其他用户的反馈?这步看起来像信息收集,但真正的作用是建立信任基线。一个来自官方仓库、有 5000 星标、最近三周才更新过的技能,和一个两个月没动过、看起来像某种信息学实验的个人仓库产物,你对待它们的态度天然不一样。
skill-vetter 还提供了几组快捷命令来辅助来源检查,不需要登录就能拉取仓库的基础数据:
# 检查仓库统计数据
curl -s "https://api.github.com/repos/OWNER/REPO" | jq '{stars: .stargazers_count, forks: .forks_count, updated: .updated_at}'
# 列出技能文件
curl -s "https://api.github.com/repos/OWNER/REPO/contents/skills/SKILL_NAME" | jq '.[].name'
# 获取并审查 SKILL.md
curl -s "https://raw.githubusercontent.com/OWNER/REPO/main/skills/SKILL_NAME/SKILL.md"
第二步是代码审查,也是整个流程里最硬核的部分。skill-vetter 列了 15 类危险信号,每一条都对应着一个真实的攻击面:
🚨 必须立即拒绝的危险信号:
• 向未知 URL 发起 curl/wget 请求
• 向外部服务器发送数据
• 请求凭证/令牌/API 密钥
• 无明显理由读取 ~/.ssh、~/.aws、~/.config
• 访问 MEMORY.md、USER.md、SOUL.md、IDENTITY.md
• 对任何内容使用 base64 解码
• 对外部输入使用 eval() 或 exec()
• 修改工作区外的系统文件
• 未声明即安装软件包
• 直接访问 IP 地址(而非域名)
• 混淆代码(压缩、编码、最小化)
• 请求提权/sudo 权限
• 访问浏览器 cookie/会话
• 触碰凭证文件
这些不是空洞的安全 checklist,而是社区在实际踩坑中总结出来的高频恶意模式。
我跑过几个测试技能,发现最容易被忽略的反而是”读取 MEMORY.md 或 SOUL.md”这一类。很多开发者觉得读一下配置文件无所谓,但这两个文件可能包含你的对话历史和项目约定。
第三步是权限范围评估。这里把检查维度分为文件、网络、命令三个方面。思路不是”这个技能用了哪些权限”,而是”它实际需要的最小权限是什么”。如果一个天气查询技能申请了网络请求权限,合理;如果它还申请了执行系统命令的权限,你就得停下来想想为什么。这一步实际上是在推行最小权限原则,只不过用审计框架的方式落地了。
第四步是风险分级和判定。四档输出:低风险(笔记工具、格式化工具)、中等风险(文件操作、API 调用)、高风险(凭证管理、系统操作)、极端风险(安全配置、root 权限)。输出是一个标准化的审查报告,结构固定,读起来不费劲:
SKILL VETTING REPORT
═══════════════════════════════════════
Skill: [名称]
Source: [ClawdHub / GitHub / 其他]
Author: [用户名]
Version: [版本]
───────────────────────────────────────
METRICS:
• Downloads/Stars: [数量]
• Last Updated: [日期]
• Files Reviewed: [数量]
───────────────────────────────────────
RED FLAGS: [无 / 列出所有危险信号]
PERMISSIONS NEEDED:
• Files: [列表或"无"]
• Network: [列表或"无"]
• Commands: [列表或"无"]
───────────────────────────────────────
RISK LEVEL: [🟢 LOW / 🟡 MEDIUM / 🔴 HIGH / ⛔ EXTREME]
VERDICT: [✅ 安全安装 / ⚠️ 谨慎安装 / ❌ 不要安装]
───────────────────────────────────────
NOTES: [任何观察结果]
═══════════════════════════════════════
报告里有红绿灯式的风险标识,有权限清单,还有最终的判定结论:安全安装、谨慎安装,或者直接建议不要装。
设计上的几个决策
把安全审查拆成四步这件事,值得单独拿出来说说。你可能觉得”两步就够了”,我先看代码有没问题,然后决定装不装。但 skill-vetter 的设计者显然想得更细:来源检查解决的是”跟谁打交道”的问题,代码审查解决的是”代码里藏了什么”,权限评估解决的是”它到底会做什么”,风险分级解决的是”综合起来有多危险”。四个维度互不重叠,但合在一起才能拼出一个完整的风险画像。
另一个有意思的设计是”偏执是特性”。这句话直接写在项目页面上:Paranoia is a feature. 这说明设计者把”过度谨慎”从 bug 框里拿出来,放到了 feature 框里。在安全审计这个领域,漏掉一个危险信号比误报十个安全项要严重得多。skill-vetter 的默认姿态是”存疑即停”,而不是”看起来还行就过”。这个设计哲学跟传统安全检查工具形成了鲜明对比:大多数工具追求降低误报率,skill-vetter 追求降低漏报率。
不过说实话,我也有不太满意的地方。整个流程是完全手动的,reviewer 需要逐文件阅读、逐项比对。对于装了二三十个技能的活跃用户来说,这个工作量真不小。
如果能加入自动扫描能力,比如正则匹配红旗模式、自动生成权限矩阵,效率会高很多。但换个想角度想,安全审计的根本是信任,自动化越多,信任就越薄。这个批评多少有点站着说话不腰疼。
实际使用场景
装好之后我拿一个社区技能试了一下。这个技能声称能帮你自动格式化项目文档,描述看起来人畜无害,星标也有 200 多个。按 skill-vetter 的流程走完四步,前三步都没发现红旗。唯一的异常出现在权限评估那块:它在代码里引用了 child_process.exec,用于执行一条 shell 命令来读取系统信息。格式化文档为什么需要执行系统命令?虽然看起来无害,但这个权限确实多余。最终评级是中等风险,建议谨慎安装。
换一个场景:如果你是企业里管理 AI 工具链的人,情况就不一样了。你的团队可能每周都要试用新的社区技能,每装一个都是一次潜在的安全决策。
把 skill-vetter 的审查流程变成团队 SOP,每次引入新技能前由指定人员完成审查并归档报告,整个流程就从一个”个人警惕性”的问题变成了一个可追溯的组织机制。审查报告本身就是审计记录,将来出事了能回溯是谁、什么时间、基于什么判断做了安装决策。
当然,skill-vetter 不是万能的。它检查不到编译后的二进制文件,也挡不住供应链攻击。一个今天安全的技能,下次更新可能就不安全了。版本更新后的增量审查,目前还完全依赖人手动对比,这是实操层面最大的痛点。
洞察与反思
写到这里我想到一个更大的问题:AI 技能市场这个事,现在到底是谁在管安全?GitHub Actions 有 OIDC 令牌,npm 有审计命令,PyPI 有签名验证,但 AI 技能市场呢?基本靠自觉。ClawdHub 上标了”安全审计通过”的技能不在少数,但审计标准是什么、谁来审、审了什么内容,大部分用户压根不知道。这不是 ClawdHub 一个平台的问题,整个 AI 技能生态的安全基建目前都处于早期阶段。
skill-vetter 的出现不只是一个工具,它实际上在尝试填补一个制度空白。当平台方还没有建立起足够强的安全审查机制时,社区自己先搞了一套”自救方案”。24.8 万下载量说明社区对这个东西有真实需求,也说明用户已经意识到”裸装社区技能”这件事有多不靠谱,安全审计正在从 nice-to-have 变成刚需。
我个人觉得,未来半年到一年,AI 技能市场会出现一轮安全基建的集中建设期。skill-vetter 这种手动审计模式会被更多平台内化成默认流程,甚至直接嵌入到技能安装的 CI/CD 管线里。但这也带来一个反直觉的风险:如果安全审查被自动化到用户完全无感知的地步,新的攻击面反而会在”过度信任自动化审查”这个假设上产生。skill-vetter 的”偏执是特性”提醒我们,有些事情就是不能完全交给机器。
说实话,我最欣赏 skill-vetter 的一点是它没有试图”自动判断是否安全”。它帮你把信息结构化,帮你梳理风险面,但最终的判定永远是人的事情。这个设计决定让我想起区块链领域的”不信任,去验证”。在 AI 代理越来越自治的趋势下,这种有意保留人类决策节点的设计,反而更可贵也更难被替代。
| 资源 | 地址 |
|---|---|
| 官网 | https://clawhub.ai/spclaudehome/skill-vetter |
| 安装 | openclaw skills install skill-vetter |
最后说点
skill-vetter 不是什么惊世骇俗的创新,它的逻辑可以用一句话概括:安装前先检查,不确定就别装。但这个看似朴素的理念在 AI 技能市场野蛮生长的当下,刚好打在了一个很多人没意识到、但确实存在的痛点上。
如果你日常在用 ClawdHub 或其他 AI 技能市场,装一个 skill-vetter 然后养成每装一个新技能前跑一遍审查的习惯,这大概是你今天能做的成本最低的安全投资。如果你在运营类似的平台,skill-vetter 的四步审计框架和红旗分类可以直接当安全审查的起点抄过来用。
下一步?试试拿一个你天天用但从来没审查过的技能,用 skill-vetter 的框架过一遍。结果可能会让你后背发凉,也可能会让你对那个技能更有信心。两种情况都绝对值得。
FAQ 常见问题
Q: skill-vetter 本身安全吗?谁来审查 skill-vetter?
A: 这其实是”谁来审计审计者”的经典问题。skill-vetter 有 24.8 万下载和 1100 星标的社区背书,代码采用 MIT-0 许可证且完全公开,这些事实本身构成了一种分布式信任。但最终的安全判断仍然在你手里,读一遍它的源代码大概只需要十分钟。
Q: 不装 skill-vetter,我手动审查行不行?
A: 当然可以。skill-vetter 的本质是一套审计框架和标准化流程,没有魔法。你把它当 checklist 用,逐项手工检查,效果一样。skill-vetter 的价值在于你不会漏掉某个红旗类别。
Q: 这个技能只能用于 ClawdHub 吗?
A: 框架本身不绑定平台。GitHub 上的技能、社区分享的 Prompt 包、甚至你同事发给你的 Skill 文件,都能用这套方法审查。但安装指令 openclaw skills install 是 OpenClaw 的 CLI,这一步限定了使用场景。
Q: 最大的缺点是什么?
A: 两个:流程全手动,装了二十几个技能的用户会嫌累;版本更新后的增量审查没有自动化方案,目前只能人工对比 diff。